
はじめに
Moonshot AIが2025年11月、思考プロセスを可視化しながら推論を行うオープンソースモデル「Kimi K2 Thinking」を公開しました。本稿では、Hugging Faceで公開された技術情報をもとに、K2 Thinkingの技術的特徴、ベンチマーク性能、そして実際の実装方法について詳しく解説します。
参考記事
メイン記事:
- タイトル: Kimi K2 Thinking
- 発行元: Moonshot AI
- 発行日: 2025年11月8日
- URL: https://moonshotai.github.io/Kimi-K2/thinking.html
関連情報:
- タイトル: Kimi-K2-Thinking Model Card
- 発行元: Hugging Face (Moonshot AI)
- 発行日: 2025年11月
- URL: https://huggingface.co/moonshotai/Kimi-K2-Thinking
- タイトル: Kimi-K2-Thinking Deployment Guide
- 発行元: Hugging Face (Moonshot AI)
- 発行日: 2025年11月
- URL: https://huggingface.co/moonshotai/Kimi-K2-Thinking/blob/main/docs/deploy_guidance.md
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
※Kimiの以前のモデルについての解説記事

要点
- Kimi K2 Thinkingは思考プロセスを段階的に可視化しながら推論を行うthinking modelで、ツール呼び出しと推論を組み合わせて200〜300ステップの連続実行が可能である
- Humanity’s Last Exam(ツール使用時)で44.9%、BrowseCompで60.2%を記録し、GPT-5やClaude Sonnet 4.5を上回る性能を示した
- INT4量子化をネイティブサポートし、Quantization-Aware Training(QAT)により性能劣化なしに約2倍の速度向上を実現している
- Mixture-of-Experts(MoE)アーキテクチャで総パラメータ1兆、アクティブパラメータ320億、コンテキスト長256Kトークンを持つ
- vLLM、SGLang、KTransformersといった主要な推論エンジンに対応し、実装コード例も公開されている
詳細解説
K2 Thinkingの概要と開発背景
Kimi K2 Thinkingは、Moonshot AIが開発したオープンソースの思考モデル(thinking model)です。思考モデルとは、最終的な回答を出力する前に、内部的な推論プロセスを段階的に実行し、その過程を可視化できるAIモデルを指します。
Moonshot AIによれば、K2 ThinkingはHumanity’s Last Exam(HLE)、BrowseComp、そしてコーディング関連の複数のベンチマークで最先端の性能を達成しました。特筆すべきは、200〜300回の連続的なツール呼び出しを安定的に実行できる点です。従来のモデルでは30〜50ステップ程度で性能が劣化する傾向がありましたが、K2 Thinkingはより長期的な目標指向の動作を維持できます。
この長期的な安定性は、複雑な調査タスクやマルチステップのコーディングワークフローにおいて重要な意味を持ちます。エージェントが多段階の推論を必要とする場合、各ステップでの判断精度を維持しながら最終的な目標に向かって進むことが求められるためです。
主要な技術的特徴
K2 Thinkingには3つの主要な技術的特徴があります。
第一に、深い思考とツールオーケストレーションです。モデルはチェーン・オブ・ソート推論(chain-of-thought reasoning)と関数呼び出しを交互に実行するよう、エンドツーエンドで訓練されています。これにより、自律的な調査、コーディング、ライティングのワークフローを数百ステップにわたって実行できます。
具体的には、「考える→検索する→ブラウザを使う→考える→コードを書く」というサイクルを動的に繰り返し、仮説を生成・精緻化し、証拠を検証しながら一貫性のある回答を構築します。この交互配置された推論により、曖昧で開放的な問題を明確で実行可能なサブタスクに分解できます。
第二に、ネイティブINT4量子化です。INT4量子化とは、モデルの重みを4ビット整数で表現する技術で、メモリ使用量と推論速度の大幅な改善が期待できます。ただし、思考モデルは出力トークン数が非常に多いため、通常の量子化では性能が大きく低下する課題がありました。
K2 Thinkingでは、ポストトレーニング段階でQuantization-Aware Training(QAT)を採用し、MoE(Mixture-of-Experts)コンポーネントにINT4 weight-only量子化を適用することで、この課題を克服しました。結果として、性能劣化なしに約2倍の生成速度向上を達成しています。
第三に、安定した長期エージェンシーです。最大200〜300回の連続的なツール呼び出しにわたって、一貫した目標指向の動作を維持できます。これは、複雑なリサーチタスクや段階的なソフトウェア開発において、モデルが途中で目的を見失わず、最終ゴールに向かって着実に進めることを意味します。
モデルアーキテクチャ
K2 ThinkingのアーキテクチャはMixture-of-Experts(MoE)を採用しています。MoEは、複数の専門家ネットワーク(expert)を用意し、入力に応じて必要な専門家だけを選択的に活性化する仕組みです。
Moonshot AIによれば、K2 Thinkingの具体的な仕様は以下の通りです。総パラメータ数は1兆、そのうち各トークンで実際に活性化されるパラメータは320億です。レイヤー数は61(うち1つはDenseレイヤー)、Attention Hidden Dimensionは7168、MoE Hidden Dimensionは専門家あたり2048です。
専門家の数は384個で、各トークンにつき8個の専門家が選択されます。さらに1つの共有専門家(Shared Expert)が全トークンで使用されます。語彙サイズは160K、コンテキスト長は256Kトークンです。Attentionメカニズムには MLA(Multi-head Latent Attention)、活性化関数にはSwiGLUを使用しています。
このアーキテクチャにより、大規模なパラメータ数を持ちながらも、実際の推論時には必要な部分だけを活性化することで、効率的な処理を実現しています。
ベンチマーク性能の詳細
K2 Thinkingは多岐にわたるベンチマークで評価されています。ここでは主要な結果を見ていきます。
推論タスクでは、Humanity’s Last Exam(HLE)のテキストのみ版(ツールなし)で23.9%、ツール使用時で44.9%、Heavy Mode(8つの軌跡を並列実行し統合する手法)で51.0%を記録しました。HLEは非常に難易度の高いベンチマークで、Moonshot AIによれば、ツール使用時の44.9%という成績はGPT-5(High)の41.7%やClaude Sonnet 4.5(Thinking)の32.0%を上回っています。

数学関連では、AIME 2025(ツールなし)で94.5%、Pythonツール使用時で99.1%、HMMT 2025(ツールなし)で89.4%、Pythonツール使用時で95.1%を達成しました。これらは高難度の数学コンテストの問題を解く能力を測定するもので、競合モデルと同等またはそれ以上の性能を示しています。
エージェント検索タスクでは顕著な成果が見られます。BrowseCompはウェブ上の見つけにくい情報を継続的に検索・推論する能力を評価するベンチマークですが、K2 Thinkingは60.2%を記録し、人間のベースライン29.2%を大きく上回りました。Moonshot AIによれば、この結果はGPT-5の54.9%やClaude Sonnet 4.5の24.1%を超えています。BrowseComp中国語版では62.3%、Seal-0では56.3%、FinSearchComp-T3では47.4%、Framesでは87.0%を達成し、いずれも競合モデルと比較して優れた性能を示しました。

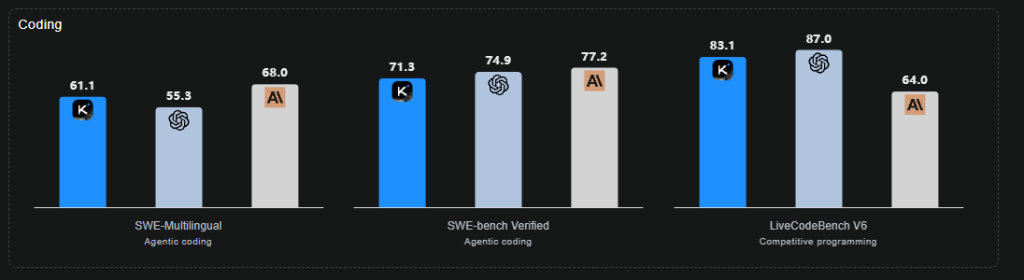
コーディングタスクでは、SWE-bench Verifiedで71.3%、SWE-bench Multilingualで61.1%、Multi-SWE-benchで41.9%を記録しました。これらは実際のソフトウェア開発タスクを模したベンチマークで、多言語対応やマルチステップのエージェント実行を必要とします。一部のベンチマークではGPT-5やClaude Sonnet 4.5に及ばない結果もありますが、全体として高い水準を維持しています。
一般タスクでは、MMLU-Proで84.6%、MMLU-Reduxで94.4%、Longform Writingで73.8%、HealthBenchで58.0%を達成しました。これらは知識の幅広さや長文生成能力を測定するもので、バランスの取れた性能を示しています。
ベンチマーク評価には詳細な条件設定があります。温度パラメータは1.0(SciCodeのみ0.0)、コンテキスト長は256K、思考トークンバジェットはタスクによって32K〜128Kと設定されています。また、AIモデルの回答を評価する際にはo3-miniを判定者として使用し、公式のHLE設定と同一の構成を採用しています。
実装方法とデプロイメント
K2 Thinkingは複数の推論エンジンに対応しており、実装コード例も公開されています。以下、主要な実装方法を見ていきます。
基本的なチャット実装では、OpenAI互換のAPIを使用します。以下は簡単な会話の例です。
def simple_chat(client: openai.OpenAI, model_name: str):
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant created by Moonshot AI."},
{"role": "user", "content": [{"type": "text", "text": "which one is bigger, 9.11 or 9.9? think carefully."}]},
]
response = client.chat.completions.create(
model=model_name,
messages=messages,
stream=False,
temperature=1.0,
max_tokens=4096
)
print(f"k2 answer: {response.choices[0].message.content}")
print("=====below is reasoning content======")
print(f"reasoning content: {response.choices[0].message.reasoning_content}")このコードでは、temperature=1.0を推奨設定として使用しています。温度パラメータは出力の多様性を制御するもので、高いほどランダム性が増します。思考モデルでは探索的な推論が重要なため、比較的高い温度設定が推奨されています。
重要な点として、レスポンスにはmessage.content(最終的な回答)とmessage.reasoning_content(思考プロセス)の両方が含まれます。これにより、モデルがどのように推論したかを確認できます。
ツール呼び出しの実装も可能です。以下は天気情報を取得するツールを使用する例です。
# ツールの実装
def get_weather(city: str) -> dict:
return {"weather": "Sunny"}
# ツールのスキーマ定義
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Retrieve current weather information. Call this when the user asks about the weather.",
"parameters": {
"type": "object",
"required": ["city"],
"properties": {
"city": {
"type": "string",
"description": "Name of the city"
}
}
}
}
}]
# ツール名と実装のマッピング
tool_map = {
"get_weather": get_weather
}
def tool_call_with_client(client: OpenAI, model_name: str):
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant created by Moonshot AI."},
{"role": "user", "content": "What's the weather like in Beijing today? Use the tool to check."}
]
finish_reason = None
while finish_reason is None or finish_reason == "tool_calls":
completion = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=1.0,
tools=tools,
tool_choice="auto"
)
choice = completion.choices[0]
finish_reason = choice.finish_reason
if finish_reason == "tool_calls":
messages.append(choice.message)
for tool_call in choice.message.tool_calls:
tool_call_name = tool_call.function.name
tool_call_arguments = json.loads(tool_call.function.arguments)
tool_function = tool_map[tool_call_name]
tool_result = tool_function(**tool_call_arguments)
print("tool_result:", tool_result)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call_name,
"content": json.dumps(tool_result)
})
print("-" * 100)
print(choice.message.content)このコードでは、モデルがツールを呼び出すべきと判断した場合(finish_reason == “tool_calls”)、ループを継続してツールの実行結果をモデルに返します。モデルは結果を受け取り、必要に応じてさらなるツール呼び出しを行うか、最終回答を生成します。
vLLMでのデプロイメントでは、Tensor Parallelism(TP)を使用した分散実行が推奨されています。H200プラットフォームでINT4重みと256Kコンテキスト長を使用する場合、最小構成として8GPUのクラスタが必要です。
vllm serve $MODEL_PATH \
--served-model-name kimi-k2-thinking \
--trust-remote-code \
--tensor-parallel-size 8 \
--enable-auto-tool-choice \
--max-num-batched-tokens 32768 \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2主要なパラメータとして、–enable-auto-tool-choiceと–tool-call-parser kimi_k2はツール使用を有効にする際に必須です。–reasoning-parser kimi_k2は思考コンテンツを正しく処理するために必要です。–max-num-batched-tokens 32768は、チャンクプリフィルを使用してピークメモリ使用量を削減するための設定です。
SGLangでのデプロイメントも同様にTensor Parallelismを使用できます。
python -m sglang.launch_server --model-path $MODEL_PATH --tp 8 --trust-remote-code --tool-call-parser kimi_k2 --reasoning-parser kimi_k2KTransformersでのデプロイメントでは、CPUとGPUのヘテロジニアス推論が可能です。これにより、GPU数が限られた環境でも効率的に実行できます。
python -m sglang.launch_server \
--model path/to/Kimi-K2-Thinking/ \
--kt-amx-weight-path path/to/Kimi-K2-Instruct-CPU-weight/ \
--kt-cpuinfer 56 \
--kt-threadpool-count 2 \
--kt-num-gpu-experts 200 \
--kt-amx-method AMXINT4 \
--trust-remote-code \
--mem-fraction-static 0.98 \
--chunked-prefill-size 4096 \
--max-running-requests 37 \
--max-total-tokens 37000 \
--enable-mixed-chunk \
--tensor-parallel-size 8 \
--enable-p2p-check \
--disable-shared-experts-fusionMoonshot AIによれば、この構成で8台のNVIDIA L20と2台のIntel 6454Sを使用した場合、37並列実行時にプリフィルで577.74トークン/秒、デコードで45.91トークン/秒の性能を達成したとのことです。
実用的な応用例
K2 Thinkingの実用例として、創作的なSF短編小説の生成が紹介されています。「雷雨によって自由意志を獲得した、惑星の気象制御システムにアップロードされた雲」というプロンプトから、科学的原理とSF文学の手法を組み合わせた物語を生成しました。
この例では、モデルは関連する科学原理(コアルーラ効果、大気物理学、気象システムなど)について検索を行い、SF文学のナラティブ手法を調査し、両者を統合した創作物を生成しています。生成されたテキストは、技術的な正確性と文学的な表現力を両立しており、単なる情報の羅列ではない創造的なコンテンツとなっています。
コーディング分野では、単一のプロンプトから完全に機能するウェブサイトやアプリケーションを生成する能力が示されています。HTML、React、そしてコンポーネント集約型のフロントエンドタスクにおいて顕著な改善を示し、アイデアを完全に機能する応答性の高い製品に変換できます。
エージェントコーディング環境では、ツールを呼び出しながら推論を行い、複雑なマルチステップの開発ワークフローを精度と適応性を持って実行できます。SWE-Multilingualで61.1%、SWE-Bench Verifiedで71.3%、Terminal-Benchで47.1%というスコアは、プログラミング言語やエージェントスキャフォールド全体での強力な汎化能力を示しています。
まとめ
Kimi K2 Thinkingは、思考プロセスの可視化と長期的なツール連携を実現したオープンソースモデルです。Humanity’s Last ExamやBrowseCompなどの難易度の高いベンチマークで優れた性能を示し、INT4量子化により実用的な速度も確保しています。vLLMやSGLangなど主要な推論エンジンに対応し、実装コード例も公開されているため、開発者が実際に活用しやすい環境が整っています。今後、複雑な推論を必要とするアプリケーション開発において、重要な選択肢の一つとなる可能性があるでしょう。








