
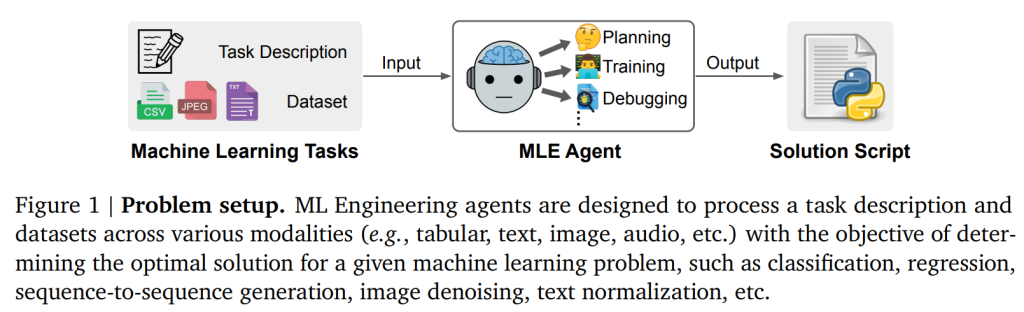
はじめに
MLモデルの開発は、地道で手間のかかる作業が多く、データの前処理、特徴量エンジニアリング、モデルの選択、ハイパーパラメータの調整など、試行錯誤の連続です。データサイエンティストがこの一連の作業に費やす労力は決して少なくないことはよく知られています。
近年、この開発プロセスを効率化しようと、大規模言語モデル(Large Language Models, LLMs)をMLエンジニアリング(MLE)エージェントとして活用する研究が注目されています。LLMの持つ高いコーディング能力や推論能力を活かせば、MLタスクをコードの最適化問題として捉え、最終的には実行可能なPythonスクリプトを自動で生成できるようになる、というわけです。
ただ、これまでのMLEエージェントにはいくつかの課題がすでに指摘されていました。たとえば、LLMの内部知識に頼りすぎるあまり、よく使われるお馴染みの手法(例えば表形式データなら「scikit-learn」ライブラリなど)に偏ってしまい、特定のタスクにはもっと良い最新の手法があるのに見過ごしてしまう、といったことが起きていました。また、コード全体を一度に修正するような大雑把な探索戦略をとるため、特徴量エンジニアリングのオプションを徹底的に試す、といった特定のコンポーネント内での深い探索が苦手とされています。
今回解説する論文「MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement」は、これらの課題を克服するための新しいアプローチを提案しています。どのようにして既存のエージェントの限界を乗り越え、より効率的で高性能なMLモデル開発を可能にしているのか、を解説します。
※簡潔に要点のみを知りたい方は以下をご確認ください。

解説論文
- 論文タイトル: MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement
- 論文URL: https://arxiv.org/pdf/2506.1569
- 発行日: 2025年6月2日
- 発表者: Jaehyun Nam, Jinsung Yoon, Jiefeng Chen, Jinwoo Shin, Sercan Ö. Arık, Tomas Pfister (所属: Google Cloud, KAIST)
※提案者のGitHub:https://github.com/jaehyun513/MLE-STAR
要点
- 革新的なアプローチの提案:MLE-STARは、ウェブ検索(Search)と、特定のコードブロックに焦点を当てた洗練(Targeted Refinement)という二つの要素を統合した、新しい機械学習エンジニアリング(MLE)エージェント。
- 外部知識の積極的な活用:既存のLLMエージェントが持つ知識に依存するのではなく、Google検索などの検索エンジンを活用して、ウェブ上からそのタスクに効果的な最新のモデルやアプローチを探索し、それらを基に初期のソリューションを生成する。これにより、LLMの内部知識の偏りを克服し、タスクに特化した最適なモデルを選択できるようになる。
- 段階的かつ集中的なコードの洗練:初期ソリューションを生成した後、MLE-STARは反復的にそのソリューションを洗練していく。この際、アブレーションスタディ(特定のコンポーネントを取り除いたときの性能変化を調べる研究)を用いて、どのMLパイプラインコンポーネント(例:特徴量エンジニアリング、アンサンブル構築など)が最も性能に影響を与えるかを特定する。そして、その最も影響の大きい「特定のコードブロック」に焦点を絞って、多様な戦略を探索し、繰り返し改善を加える。
- 独自性の高いアンサンブル手法の導入:MLE-STARは、ただ複数のモデルを単純に組み合わせるだけでなく、エージェント自身がアンサンブル戦略を考案し、それを反復的に洗練していくことで、複数の候補ソリューションをより効果的に統合する新しい方法を提案している。これにより、個々のソリューションの弱点を補い合い、全体の性能を向上させることが可能となる。
- Kaggleコンペティションでの圧倒的な性能:MLE-STARは、MLエンジニアリングのベンチマークである「MLE-bench Lite」のKaggleコンペティションで包括的な評価が行われた。その結果、既存の最先端手法を大幅に上回り、64%のコンペティションでメダルを獲得するという優れた成果を達成しています。これは、MLモデル開発における人間の労力を最小限に抑えつつ、高いパフォーマンスを実現できる可能性を示している。
詳細解説
それでは、論文の内容を章立てに沿って解説します。
1. Introduction
(はじめに)
機械学習(ML)の普及は、表形式データの分類から画像ノイズ除去のような複雑なタスクまで、様々な現実世界のシナリオで高性能なアプリケーションを牽引しています。しかし、これらのモデルを開発するプロセスは、データサイエンティストにとって依然として労働集約的であり、広範な反復実験やデータエンジニアリングを伴います。
このような集中的なワークフローを効率化するため、近年の研究では、大規模言語モデル(LLMs)を機械学習エンジニアリング(MLE)エージェントとして活用することに焦点が当てられています。LLMの持つコーディング能力と推論能力を活用することで、これらのエージェントはMLタスクをコード最適化問題として概念化し、最終的に与えられたタスクの説明とデータセットに基づいて実行可能なコード(例:Pythonスクリプト)を生成することができます。
しかし、これまでのMLEエージェントにはいくつかの課題がありました。第一に、LLMの内部知識に強く依存しているため、しばしば馴染みのある、頻繁に使用される手法(例えば、表形式データにはscikit-learnライブラリなど)に偏りがちで、タスクに特化した有望な手法を見落とすことがあります。第二に、これらのエージェントは通常、各イテレーションでコード構造全体を一度に修正するような探索戦略を採用しているため、深く反復的な最適化が困難であることがあります。特徴量エンジニアリングのオプションを広範に実験するなど、特定のパイプラインコンポーネント内で深く反復的な探索を行う能力が不足しているため、エージェントが他のステップ(例えば、モデル選択やハイパーパラメータチューニング)に時期尚早に移行してしまうことにつながります。
本論文では、これらの課題を克服するために、ウェブ検索(Search)とターゲットを絞ったコードブロックの洗練(Targeted code block Refinement)を統合した新しいMLエンジニアリングエージェント「MLE-STAR」を提案しています。具体的には、初期ソリューションコードを生成する際に、Google検索を活用してウェブから関連性の高い、潜在的に最先端のアプローチを検索します。さらに、ソリューションを改善するために、MLE-STARは特徴量エンジニアリングやアンサンブル構築など、個別のMLパイプラインコンポーネントを表す特定のコードブロックを抽出し、そのコンポーネントに特化した戦略の探索に集中します。この探索は、個々のコードブロックの影響を分析するアブレーションスタディによってガイドされます。
加えて、MLE-STARによって提案される効果的な戦略を用いた新しいアンサンブル手法も導入されています。実験結果は、MLE-STARがMLE-bench LiteのKaggleコンペティションで64%のメダルを獲得し、最高の代替手法を大幅に上回ることを示しています。
2. Related work
(関連研究)
このセクションでは、MLE-STARに関連する既存の研究について説明されています。
- LLM agents (LLMエージェント):
近年、LLMの目覚ましい進歩により、自律型エージェントに関する研究が活発に行われています。ReActやHuggingGPTのような汎用エージェントは、様々な問題を分析するために外部ツールを使用するのが一般的です。一方、Voyager(Minecraft用)やAlphaCode(コード生成用)のような特化型エージェントは、特定のドメインで優れた性能を発揮し、実行フィードバックを利用してアプローチを繰り返し改善しています。MLE-STARは、これらの研究を拡張し、MLタスクに特化したLLMエージェントとして位置づけられます。 - Automated machine learning (AutoML) (自動機械学習):
AutoMLは、エンドツーエンドのMLパイプラインを自動化することで、人間の専門家への依存を減らすことを目指しています。Auto-WEKA、TPOT、そして最近ではAutoGluonなどが、事前に定義されたモデルやハイパーパラメータ空間内での探索を通じて進歩を遂げてきました。AutoML研究は、ニューラルネットワーク設計や特徴量エンジニアリングなどの分野にも特化しています。しかし、これらの手法は事前に定義された探索空間に依存するため、その定義にはドメイン専門知識が必要となることが多いです。これに対処するため、MLE-STARを含むLLMベースのMLEエージェントが登場しており、手動でキュレーションされた探索空間を必要とせずに、コード空間で直接効果的な探索戦略を採用しています。 - MLE agents (MLEエージェント):
LLMのコーディングおよび推論能力を活用し、MLワークフローを自動化するソリューションコードを生成するMLEエージェントに関する研究が活発に行われています。MLABやOpenHandsはツールを呼び出すことで一般的なMLタスクを実行しますが、いくつかの研究はML自動化に特化しています。例えば、AIDEはコード空間の探索を容易にするためにツリー構造で候補ソリューションを生成しますが、LLMの内部知識に強く依存するため、時代遅れまたは単純すぎるモデルの選択につながる可能性があり、その洗練プロセスはパイプラインステージ間で時期尚早に焦点を移すことがあります。DS-Agentは、ケースベース推論を用いて(主にKaggleからの)手動でキュレーションされたケースを活用してソリューション生成のための戦略を発見します。しかし、DS-Agentは手動で構築されたケースバンクに依存するためスケーラビリティの問題があり、多大な人的労力が必要で、ソースパターンに過学習したソリューションにつながる可能性があります。また、複雑なマルチモーダル問題のような新しいタスクタイプへの適用が制限されます。MLE-STARはこれらの制限に対処し、より広範なコード空間を探索したり、静的なケースバンクに依存したりするのではなく、特定のMLパイプラインコンポーネントの実装オプションを戦略的に探索します。また、検索をツールとしてLLMを使用することで、固定されたケースバンクの制約を超えて効果的なモデルを検索し、スケーラビリティを向上させます。
3. MLE-STAR
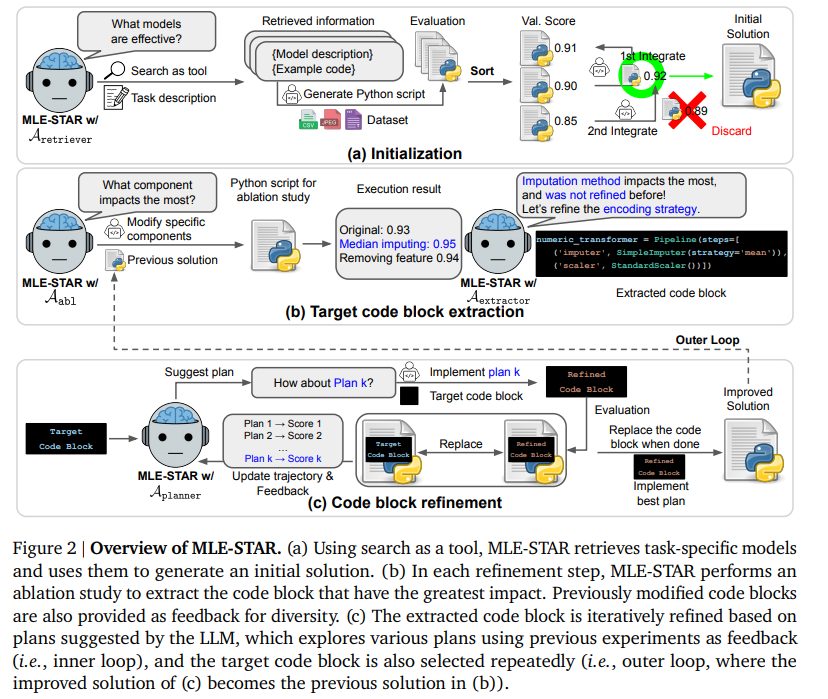
このセクションでは、提案されたMLEエージェントのフレームワークであるMLE-STARの具体的な仕組みが説明されています。MLE-STARは、LLMのコーディングと推論能力を効果的に活用してMLタスクを解決します。
主な流れとしては、まずウェブ検索をツールとして使用して初期ソリューションを生成し(後述の3.1節)、次にネストされたループを通じてソリューションを洗練していきます。外側のループでは、アブレーションスタディ(後述の3.2節)を通じて抽出された特定のMLコンポーネントに対応する一つのコードブロックをターゲットとし、内側のループでは、そのブロックのみを繰り返し洗練します。さらに、LLMによって提案された計画を反復的に洗練することで、性能を向上させる新しいアンサンブル手法も提案されています(後述の3.3節)。また、テストサンプルの統計を欠損値補完に使うなど、LLMによる望ましくない振る舞いを軽減するための特定のモジュールも導入されています(後述の3.4節)。
問題設定としては、データセットDとタスク説明Ttask(タスクの種類、データのモダリティ、評価関数などが含まれる)を入力として受け取り、最適なソリューション𝑠∗(Pythonスクリプト)を見つけることを目標とするマルチエージェントフレームワークAとして定義されています。このAは複数のLLMエージェント(A1, …, A𝑛)で構成され、各エージェントは特定の機能を持っています。
3.1. Generating an initial solution using web search as a tool
(ウェブ検索をツールとして使用した初期解の生成)
MLE-STARは、初期ソリューションの生成から始まります。MLタスクで高い性能を達成するためには、適切なモデルを選択することが非常に重要です。しかし、LLMのみにモデルの提案を頼ると、最適ではない選択肢につながることがあります。例えば、LLMは、テキスト分類タスクのようなコンペティションにおいても、事前学習データから得た馴染み深いパターンを優先し、ロジスティック回帰のようなモデルを提案してしまうことがあります。これは、最新の情報よりも知っているパターンを選んでしまうためです。
この問題を軽減するため、MLE-STARではウェブ検索をツールとして活用します。具体的には、Aretrieverエージェントがタスク説明を基に、与えられたタスクに対してM個の効果的な最先端モデルをウェブから検索します。この検索された情報には、モデルの説明(Tmodel)と、それに対応する例示コード(Tcode)が含まれます。例示コードが必要なのは、LLMがそのモデルに不慣れで、適切なガイダンスなしには実行可能なコードを生成できない場合があるためです。
次に、Ainit(候補評価エージェント)が、検索されたモデルの情報を利用してMLタスクを解決するためのPythonスクリプト𝑠𝑖initを生成し、その性能がタスク固有のメトリックℎで評価されます。この結果、M個のコードスクリプトとその性能スコアのセットが得られます。
その後、これらのM個のモデルの評価に基づいて、最終的な初期ソリューション𝑠0が反復的なマージ手順で構築されます。具体的には、まず性能の良い順にスクリプトを並べ替え、最も性能の高いスクリプトを初期の𝑠0とします。そして、残りのスクリプトを順次現在の𝑠0に統合しようと試みます。この統合はAmergerエージェントによって行われ、複数のモデルをマージするために、例えば予測値の単純な平均アンサンブルを導入するように指示されます。このプロセスは、バリデーションスコアが向上しなくなるまで繰り返されます。
3.2. Refining a code block for solution improvement
(ソリューション改善のためのコードブロックの洗練)
このセクションは、MLE-STARがどのようにして初期ソリューションを段階的に改善していくか、その核となるプロセスを説明しています。洗練フェーズは、初期ソリューション𝑠0から始まり、T回の外側ループのステップで進行します。各ステップ𝑡では、現在のソリューション𝑠𝑡を改善して𝑠𝑡+1を得ることが目標であり、これは性能メトリックℎの最適化を目指します。このプロセスは、「ターゲットコードブロックの抽出」と「コードブロックの洗練」という二つの主要な段階で構成されます。
- Targeted code block extraction (ターゲットコードブロックの抽出):
専門的な改善戦略を効果的に探索するために、MLE-STARはMLパイプライン内の特定のコードブロックを特定し、それをターゲットとします。この選択は、Aabl(アブレーションエージェント)によって実行されるアブレーションスタディによってガイドされます。Aablは、現在のソリューション𝑠𝑡に対してアブレーションスタディを行うためのPythonコード𝑎𝑡を生成します。このスクリプトは、特定のコンポーネントを修正したり無効にしたりすることで、𝑠𝑡のバリエーションを作成します。また、異なるパイプライン部分の探索を促すため、Aablは以前のアブレーションスタディの要約も入力として受け取ります。
生成された𝑎𝑡が実行され、その結果𝑟𝑡が出力されます。次に、Asummarizeモジュールがスクリプトと結果を処理し、簡潔なアブレーション要約T 𝑡 ablを生成します。
最終的に、AextractorモジュールがT 𝑡 ablを分析し、𝑠𝑡の中で性能に最も大きな影響を与えたコードブロック𝑐𝑡を特定します。以前にターゲットとされたブロックのセットもコンテキストとして提供され、まだ洗練されていないブロックの優先順位付けに役立ちます。また、MLE-STARはこの時点で、抽出されたコードブロックを洗練するための初期計画𝑝0も生成します。 - Code block refinement (コードブロックの洗練):
ターゲットとなるコードブロック𝑐𝑡が特定されると、MLE-STARはメトリックℎを改善するための様々な洗練戦略を探索します。これには、𝑐𝑡に対するK個の潜在的な洗練を探索する「内側のループ」が含まれます。
まず、Acoderエージェントが初期計画𝑝0を実装し、𝑐𝑡を洗練されたブロック𝑐0𝑡に変換します。この𝑐0𝑡を𝑠𝑡に置き換えることで、候補ソリューション𝑠0𝑡が形成され、その性能ℎ(𝑠0𝑡)が評価されます。
さらに効果的または斬新な洗練戦略を発見するため、MLE-STARは反復的に追加の計画を生成し、評価します。𝑘=1, …, 𝐾−1の場合、Aplanner(計画エージェント)が次の計画𝑝𝑘を提案します。このエージェントは、現在の外側ステップ𝑡内での以前の試みをフィードバックとして活用し、より良い計画を考案します。
各計画𝑝𝑘に対して、Acoderが対応する洗練されたブロック𝑐𝑘𝑡を生成し、候補ソリューション𝑠𝑘𝑡を作成し、その性能ℎ(𝑠𝑘𝑡)を評価します。K個の洗練戦略を探索した後、最も性能の高い候補ソリューションが特定され、𝑠𝑡よりも改善が見られた場合にのみ、次の外側ステップのソリューション𝑠𝑡+1が更新されます。この反復プロセスは、𝑡=𝑇に達するまで継続されます。
3.3. Further improvement by exploring ensemble strategies
(アンサンブル戦略の探索によるさらなる改善)
MLE-STARは、単一の最適なソリューションを生成するだけでなく、それをさらに改善するために、独自性のあるアンサンブル手順を導入しています。一般的な慣行では、複数の候補ソリューションを生成し、その中で最も高いスコアを持つものを選択することが多いですが、本論文では、たとえ個々に最適ではないソリューションであっても、それぞれが補完的な強みを持っている可能性があると提唱しています。したがって、複数のソリューションを組み合わせることで、どれか一つに頼るよりも優れた性能が得られると考えられます。
この考えに基づき、MLE-STARは自身の計画能力を活用し、効果的なアンサンブル戦略を自動的に発見します。具体的には、MLE-STARの並行実行などで得られたL個の異なる最終ソリューション{𝑠𝑙}がある場合、これらのソリューションを統合する効果的なアンサンブル計画𝑒を見つけることを目標とします。このプロセスは、先ほど説明したターゲットコードブロックの洗練ステージの構造に似ています。
まず、MLE-STAR自身によって初期アンサンブル計画𝑒0が提案されます(例:各ソリューションによって学習されたモデルから得られた最終予測値を単純に平均化する戦略など)。初期計画𝑒0に対する性能ℎ(𝑠0ens)が計算された後、固定されたイテレーション回数𝑟=1, …, 𝑅の間、アンサンブル計画の提案に特化した計画エージェントAens_plannerが、その後のアンサンブル計画𝑒𝑟を提案します。このエージェントは、以前に試みられたアンサンブル計画とその結果性能の履歴をフィードバックとして利用します。
各𝑒𝑟はAensemblerによって実装され、アンサンブルされたソリューション𝑠𝑟ensが得られます。最後に、R個のアンサンブル戦略を探索した後、最高の性能を達成したアンサンブル結果が最終出力として選択されます。この手順により、MLE-STARは複数の複雑なソリューションを組み合わせるための、潜在的に斬新で効果的な方法を自律的に探索し、特定することができます。
3.4. Additional modules for robust MLE agents
(ロバストなMLEエージェントのための追加モジュール)
MLE-STARは、より堅牢なMLEエージェントとして機能するために、いくつかの追加モジュールを組み込んでいます。
- Debugging agent (デバッグエージェント):
Pythonスクリプトの実行中にエラーが発生し、トレースバック(エラーの履歴)などのバグ情報(Tbug)が記録された場合、MLE-STARはAdebugger(デバッグモジュール)を用いてその修正を試みます。このプロセスは、スクリプトが正常に実行されるか、事前に定義された最大デバッグ回数に達するまで反復されます。もしバグが解決できない場合でも、MLE-STARは最後に実行可能であったスクリプトのバージョンを使用して、次のタスクに進みます。 - Data leakage checker (データリークチェッカー):
LLMが生成したPythonスクリプトは、データリーク(例えば、トレーニングデータセットの準備中にテストデータセットの情報に不適切にアクセスしてしまうなど)を導入するリスクを伴う可能性があります。この問題に対処するため、MLE-STARはスクリプト実行前にソリューションスクリプト𝑠を分析するAleakage(チェッカーエージェント)を導入しています。長いコード全体を分析することは非効率であるため、ターゲットを絞ったアプローチを採用しています。まず、データ前処理が行われるコードブロック𝑐dataを抽出し、その𝑐dataをチェッカーに渡します。Aleakageが潜在的なデータリークを検出した場合、修正版𝑐∗dataを生成し、元のスクリプト𝑠は特定されたセグメントを修正版に置き換えることで更新されます。Aleakageによって𝑐dataにリークが検出されない場合、スクリプト𝑠は変更されません。生成されたすべてのソリューションは、評価のために実行される前にAleakageを通過します。
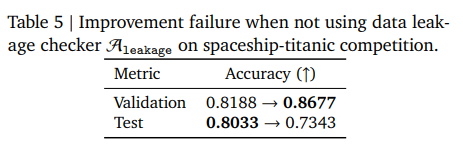
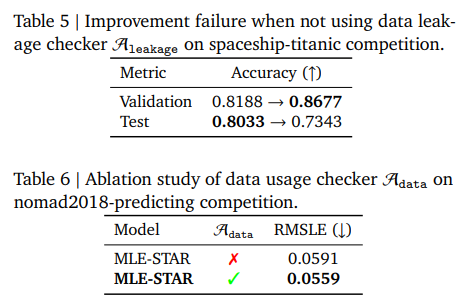
例えば、Figure 6では、テストデータがその自身の統計情報を用いて前処理される非現実的なアプローチが示されていますが、これはMLE-STARのデータリークチェッカーによって特定され、トレーニングデータから統計情報を抽出し、それらの計算された統計情報を用いてテストデータを前処理するようにコードが修正されます。また、このAleakageが使用されない場合、検証精度は向上するもののテスト精度が大幅に低下し、汎化に失敗する可能性があることが、Table 5の例で示されています。

- Data usage checker (データ使用チェッカー):
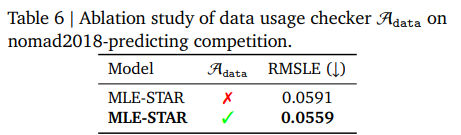
LLMが生成するスクリプトは、提供されたデータソースの一部を見落とすことがあります。例えば、nomad2018-predictingコンペティションでは、Gemini-2.0-Flashがtrain.csvのみをロードし、geometry.xyzの使用を怠った例があります(Figure 7参照)。この問題に対処するため、MLE-STARはAdata(データ使用チェッカーエージェント)を導入し、初期ソリューション𝑠0とタスク説明Ttaskをチェックします。関連する提供データが適切に使用されていない場合、Adataは初期スクリプトを修正します。この設計により、MLE-STARは以前見落とされていたデータも組み込むことができ、結果として性能が大幅に向上します(Table 6参照) 。

4. Experiments (実験)
このセクションでは、MLE-STARの有効性を検証するための実験結果が詳しく説明されています。
- Common setup (共通設定):
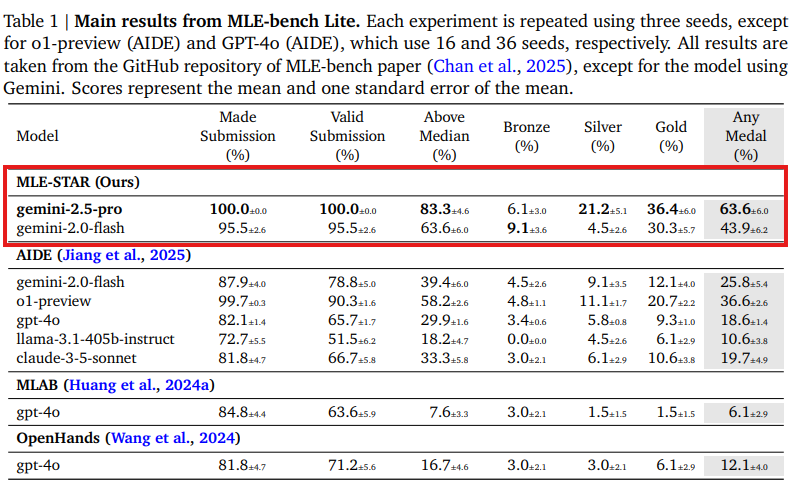
MLE-STARの有効性を検証するため、MLE-bench Lite(Chan et al., 2025)の22のKaggleコンペティションが使用されました。全ての実験は、特に指定がない限り、3つの異なるランダムシードとGemini-2.0-Flashを用いて行われました。MLE-STARは、初期段階で4つのモデル候補を検索し、その後、4つの内側ループと4つの外側ループで洗練を行います。アンサンブルプロセスでは、2つのソリューションを並行して生成し、5ラウンドのアンサンブル戦略を探索します。公平な比較のため、MLE-benchの設定に従い、最大24時間の時間制限が設定されています。主要なベースラインとしては、MLE-benchで最先端の性能を持つAIDE(Jiang et al., 2025)が使用されました。 - 4.1. Main results (主な結果):
- 定量的結果:
Table1に示されているように、MLE-STARは様々なベースラインモデルの性能を著しく向上させます。例えば、Gemini-2.0-Flashを基盤とする場合、MLE-STARはKaggleコンペティションにおけるAIDEのメダル獲得率を25.8%から43.9%へ、そしてメディアン(中央値)を超える達成率を39.4%から63.6%へ改善しています。特に注目すべきは、Gemini-2.0-Flashを用いたMLE-STARが、より強力な推論モデル(o1-preview)を用いたAIDEを、ゴールドメダル獲得タスク数で10%以上も上回っている点です。さらに、Gemini-2.5-Proを使用すると、MLE-STARは60%以上のメダル獲得率を達成しています。 - DS-Agentとの比較:
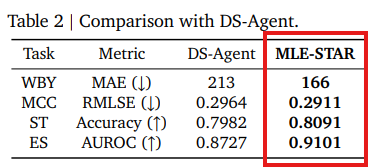
DS-Agent(Guo et al., 2024)はMLタスクで競争力のある結果を示しますが、Kaggleからケースバンクを手動でキュレーションする必要があり、これがスケーラビリティの問題となります。直接的な比較は困難ですが、DS-Agentの開発段階で使用された4つの表形式分類タスク(wild-blueberry-yield, media-campaign-cost, spaceship-titanic, enzyme-substrate)を用いて比較したところ、MLE-STARはGemini-2.0-Flashを使用し、人間の労力なしでもDS-Agentを大幅に上回る結果を示しました( Table 2参照)。
- 定量的結果:
- 4.2. Ablation studies (アブレーションスタディ):
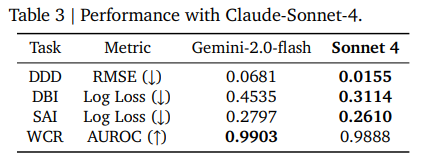
- 推論モデルを用いた性能:
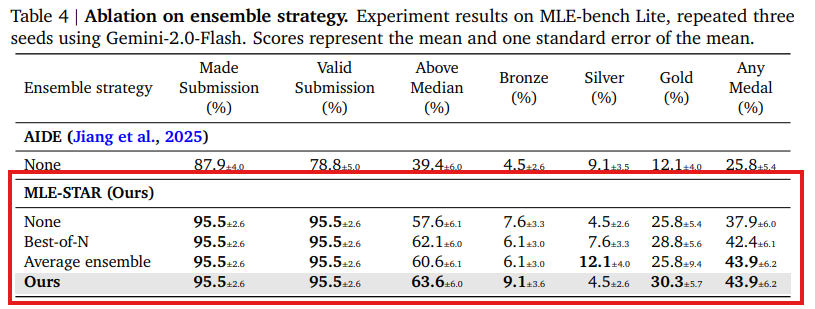
Table 1に示されているように、Gemini-2.5-ProはGemini-2.0-Flashよりも優れた性能をもたらします。例えば、denoising-dirty-documentsコンペティションでは、Gemini-2.0-Flashを用いたMLE-STARは全てのシードでメディアンを超えるスコアを得たもののメダルを獲得できませんでしたが、Gemini-2.5-Proを使用すると、2つのゴールドメダルと1つのシルバーメダルを獲得しました。これらの結果は、MLE-STARが急速に改善される推論ベースのLLMの進歩を最大限に活用するように設計されていることを示しています。さらに、Claude-Sonnet-4を使用した追加実験でも有望な結果が得られており(Table 3参照)、モデルタイプの互換性と汎化性を示しています。 - 提案されたアンサンブル手法の有効性: Table4で強調されているように、MLE-STARは競合するベースラインであるAIDEと比較して、追加のアンサンブル戦略なしでも、メダル獲得率で12%以上の顕著な性能向上を示しています。特に、複数のソリューション候補をアンサンブルすることにより、MLE-STARはさらに大きな性能向上を実現し、メダル獲得率(特にゴールドメダル)を一貫して高めています。単純な戦略(例:最高の検証スコアを持つソリューションを選択するか、最終提出を平均化する)も利点を提供しますが、MLE-STARはより強力な有効性を示し、より多くのゴールドメダル獲得につながっています。
- 推論モデルを用いた性能:
5. Discussion
(考察)
このセクションでは、MLE-STARの定性的な観察結果や、LLMの誤動作への対処、そして改良プロセスの進捗について議論されています。
- Qualitative observations on selected models (選択されたモデルに関する定性的な観察):
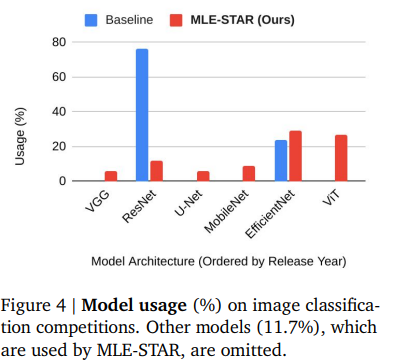
Figure4は、AIDEとMLE-STARという2つのMLEエージェントのモデル使用状況を示しています。AIDEは主に2015年にリリースされたResNetを画像分類に使用していますが、これは現在では時代遅れと見なされ、最適ではない性能につながる可能性があります。対照的に、MLE-STARはEfficientNet(Tan and Le, 2019)やViT(Dosovitskiy et al., 2021)のような、より新しく競争力のあるモデルを主に利用しています。これにより、MLE-STARはAIDE(画像分類チャレンジの26%でメダル獲得)よりも多くのメダル(37%)を獲得し、性能向上につながっています。
- Human intervention (人間の介入):
MLE-STARは、人間が最小限の介入を行うことで、さらに新しいモデルも容易に採用できます。MLE-STARはウェブ検索をツールとして使用してモデル説明を自動的に構築しますが、人間が専門知識を活用してこれを構築することも可能です。Figure 5に示されているように、RealMLP(Holzmüller et al., 2024)のモデル説明を手動で追加することで、MLE-STARは以前に検索されなかったモデルであっても、そのトレーニングをフレームワークにうまく統合できます。さらに、ユーザーはアブレーション要約を手動で書かれた指示に置き換えることで、ターゲットコードブロックを具体的に指定することも可能です。

- Misbehavior of LLMs and corrections (LLMの誤動作と修正):
LLMが生成したコードは正しく実行されることもありますが、その内容が非現実的で、「ハルシネーション」(LLMが事実に基づかない情報を生成すること)を示すことがあります。例えば、Figure 6は、テストデータがその自身の統計情報を使用して前処理されるという非現実的なアプローチを示していますが、これはデータリーク(テストデータからの情報がトレーニングプロセスに不適切に影響を与えること)につながる可能性があります。このような問題に対処するため、MLE-STARはデータリークチェッカーAleakageを用いて生成されたPythonスクリプト内の問題を特定します。問題が検出されると、MLE-STARはコードを洗練します。示されているように、MLE-STARは問題を成功裏に特定し、まずトレーニングデータから統計情報を抽出し、次にそれらの計算された統計情報を使用してテストデータを前処理するようにコードを修正します。加えて、Table 5の例で示されているように、Aleakageが使用されない場合、改善プロセスは汎化に失敗する可能性があります。この例では、バリデーション精度(目標とする目的)は向上しますが、テスト精度は大幅に低下しています。これは、LLMがテストセットでアクセスできないターゲット変数「Transported」を使用して特徴量エンジニアリングを行ったため、データリークが発生し、その結果テスト性能が低迷したためとされています。
また、LLMが提供されたデータソースの一部を見落としてしまうことも観察されています。例えば、nomad2018-predictingコンペティションでは、Gemini-2.0-Flashがtrain.csvのみをロードし、geometry.xyzの使用を怠った例があります(Figure 7参照)。これに対処するため、MLE-STARはAdata(データ使用チェッカー)を導入し、タスク説明を再確認して提供されたすべてのデータが利用されていることを確認します。Figure 7に示されているように、この設計により、MLE-STARは以前見落とされていたデータも組み込むことができます。結果として、Table 6に示されているように、性能が大幅に改善されます。


- Progressive improvement via MLE-STAR refinement (MLE-STARの洗練による段階的な改善):
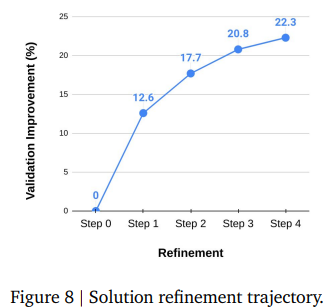
このセクションでは、検証メトリックによって測定されたMLE-STARによって達成されたソリューションの段階的な改善が詳細に説明されています。評価メトリックはタスク固有であるため、MLE-bench Liteの全22チャレンジにおける平均相対誤差削減率(%)が報告されています。このメトリックは、MLE-STARが初期ソリューションの誤差をどの程度削減したかを測定します。Figure 8は、MLE-STARが洗練ステップを進むにつれて、一貫した改善を示していることを示しています。各ステップは、内側のループを通じて単一のコードブロックの洗練に焦点を当てています。特に、初期の洗練段階での改善の大きさが顕著です。これは、MLE-STARのアブレーションスタディモジュールが、最も影響の大きいコードブロックを最初にターゲットにしていることに起因すると考えられています。
6. Conclusion
(結論)
本論文では、様々な機械学習(ML)タスク向けに設計された新しいMLエンジニアリング(MLE)エージェント「MLE-STAR」を提案しました。その主要なアイデアは、検索エンジンを活用して効果的なモデルを検索し、その後、特定のMLパイプラインコンポーネントをターゲットとした様々な戦略を探索することで、ソリューションを改善するというものです。
MLE-STARの有効性は、MLE-bench Lite Kaggleコンペティションの64%でメダル(うち36%がゴールドメダル)を獲得したことで実証されました。これは、MLモデル開発において非常に有望な結果と言えるでしょう。
限界としては、Kaggleコンペティションは公開されているため、LLMがそのチャレンジに関する関連する議論でトレーニングされている可能性があるという潜在的なリスクが挙げられます。しかし、本論文では、MLE-STARのソリューションがKaggleでの議論と比較して十分に斬新であること(LLMを判定者として使用)を示しています。この結果は、LLMが単に既存の情報を「コピペ」しているわけではないことを示唆し、データ汚染(トレーニングデータに含まれる情報が意図せずモデルの性能評価に影響を与えること)の懸念を軽減するのに役立ちます。
さらに、MLE-STARは検索エンジンを活用してウェブから効果的なモデルを検索するため、最先端のモデルが時間とともに更新され改善されるにつれて、MLE-STARによって生成されるソリューションの性能も自動的に向上すると予想されます。この固有の適応性により、ML分野の進歩とともにMLE-STARが常に改善されたソリューションを提供し続けることが保証されるとのことです。
まとめ
今回ご紹介した「MLE-STAR」は、ウェブ検索による外部知識の活用と、アブレーションスタディに基づいたターゲット絞り込み型のコード洗練という、非常にスマートなアプローチを組み合わせることで、従来のLLMベースのMLEエージェントが抱えていた課題を見事に解決しています。
LLMの内部知識だけに頼らず、最新のウェブ情報を活用することで、タスクに最適なモデルを効果的に見つけ出し、さらに、コードの最も影響の大きい部分に焦点を当てて繰り返し改善を加えることで、その性能を飛躍的に向上させることができることが立証されています。Kaggleコンペティションでの圧倒的なメダル獲得率は、その実力を明確に示しています。
また、データリークチェッカーやデータ使用チェッカーといった追加モジュールによって、LLMが生成するコードにありがちな「ハルシネーション」や「データソースの見落とし」といった潜在的な問題を未然に防ぎ、より堅牢で信頼性の高いソリューションを生成できる可能性も示されています。
MLE-STARは、AIエンジニアが日々行っている機械学習モデル開発のプロセスを、より効率的かつ自動化されたものへと進化させる可能性を秘めています。今後の動向を注視する必要があります。








