
はじめに
Metaが2025年11月19日、画像・動画における物体の検出、セグメンテーション、追跡を統合的に実行できる「Meta Segment Anything Model 3(SAM 3)」を発表しました。本稿では、この発表内容をもとに、SAM 3の機能、技術的特徴、性能評価、実用上の可能性について解説します。
参考記事
メイン記事:
- タイトル: Introducing Meta Segment Anything Model 3 and Segment Anything Playground
- 発行元: Meta AI
- 発行日: 2025年11月19日
- URL: https://ai.meta.com/blog/segment-anything-model-3/
関連情報:
- タイトル: SAM 3: Segment Anything with Concepts
- 発行元: Meta Superintelligence Labs
- 発行日: 2025年11月
- URL: https://github.com/facebookresearch/sam3
- タイトル: SAM 3 Project Page
- 発行元: Meta AI
- URL: https://ai.meta.com/sam3/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- SAM 3は、テキスト、exemplar(例示画像)、視覚的プロンプト(マスク、ボックス、ポイント)を使用して、画像・動画内の物体を検出、セグメンテーション、追跡できる統合モデルである
- 新たに公開されたSA-Co(Segment Anything with Concepts)ベンチマークでは、既存モデルと比較して約2倍のcgF1スコアを記録し、人間の性能の75-80%に到達した
- モデルのチェックポイント、評価データセット、ファインチューニングコードがオープンソースとして公開され、コミュニティでの活用が可能となっている
- Instagram の Edits アプリ、Meta AI アプリの Vibes、Facebook Marketplace の View in Room 機能など、Meta 製品への統合が進められている
- 野生動物モニタリング用のSA-FARIデータセット、海洋研究用のFathomNetデータセットなど、科学分野への応用も開始されている
詳細解説
SAM 3の主要機能とアーキテクチャ
SAM 3は、テキスト、exemplar、視覚的プロンプトという複数のプロンプト形式に対応した統合モデルです。Metaによれば、従来のSAM 1やSAM 2で導入されたマスク、ボックス、ポイントといった視覚的プロンプトに加え、短い名詞句によるテキストプロンプトや、画像exemplarによるプロンプトが新たにサポートされました。
この「promptable concept segmentation(プロンプト可能なコンセプトセグメンテーション)」機能により、固定されたラベルセットの制約を受けることなく、ユーザーが指定した任意のコンセプトを検出・セグメンテーションできます。従来のモデルでは「person」のような頻出コンセプトは処理できても、「the striped red umbrella(縞模様の赤い傘)」のようなより詳細なコンセプトの処理は困難でした。SAM 3はこの制約を克服しています。
技術的には、SAM 3はディテクタとトラッカーという2つの主要コンポーネントで構成されており、両者はビジョンエンコーダを共有しています。全体で848Mのパラメータを持ち、ディテクタはDETRベースのアーキテクチャを採用し、テキスト、ジオメトリ、画像exemplarで条件付けされます。トラッカーはSAM 2のトランスフォーマーエンコーダ-デコーダアーキテクチャを継承し、動画セグメンテーションとインタラクティブな改善をサポートしています。
DETRは、物体検出にトランスフォーマーを初めて使用したモデルとして知られており、SAM 3はこの技術的基盤の上に構築されています。また、テキストエンコーダと画像エンコーダにはMeta Perception Encoderが使用されており、これにより従来のエンコーダと比較して性能が大幅に向上したとされています。
データエンジンと訓練データセット
Metaによれば、高品質なセグメンテーションマスクとテキストラベルを持つアノテーション済み画像を、幅広いカテゴリと視覚ドメインで大規模に取得することは大きな課題でした。この課題に対処するため、SAM 3、人間のアノテーター、AIモデルをループ内で活用するスケーラブルなデータエンジンが構築されました。
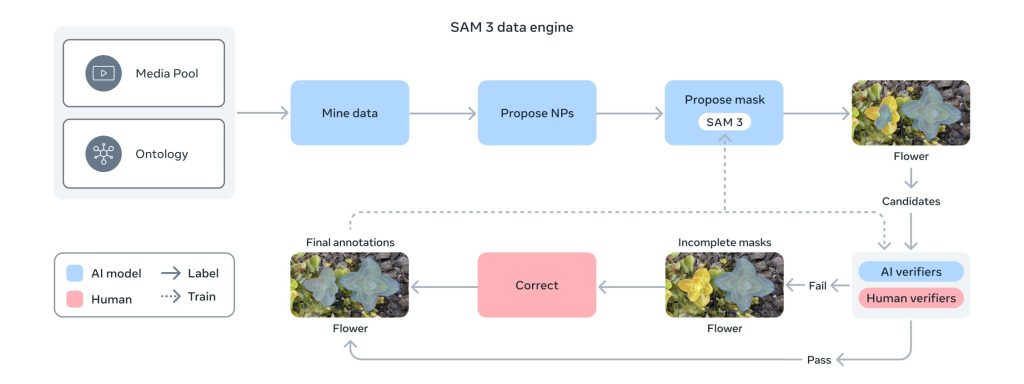
このハイブリッドシステムでは、AIモデルのパイプライン(Llamaベースのキャプショナーを含む)が画像・動画を自動的にマイニングし、キャプションを生成し、テキストラベルを解析し、初期セグメンテーションマスクを作成します。人間とAIのアノテーターがこれらの提案を検証・修正することで、フィードバックループが形成され、データセットのカバレッジが急速に拡大しながらデータ品質も継続的に改善される仕組みです。
Metaは、AIアノテーターを使用することで、人間のみのアノテーションパイプラインと比較してスループットが2倍以上になったと報告しています。ネガティブプロンプト(画像・動画に存在しないコンセプト)では約5倍、ポジティブプロンプトでも36%高速化されました。AIアノテーターは、マスクが高品質かどうか、コンセプトのすべてのインスタンスが画像内で網羅的にマスクされているかといったアノテーションタスクにおいて、人間の精度と同等以上の性能を発揮するようLlama 3.2vモデルをベースに訓練されています。
この手法により、400万を超える固有のコンセプトを含む、これまでで最大規模の高品質なオープンボキャブラリーセグメンテーションデータセットが構築されました。既存のベンチマークと比較して50倍以上のコンセプト数を持つ規模です。
SA-Coベンチマークと性能評価
SAM 3の評価のため、Metaは「Segment Anything with Concepts(SA-Co)」という新しいベンチマークを作成し、公開しました。SA-Coは、promptable concept segmentationの性能を画像と動画で評価するもので、既存のベンチマークと比較してはるかに大規模な語彙のコンセプトを認識する能力が求められます。

SA-Coには、画像用の2つのベンチマーク(SA-Co/GoldとSA-Co/Silver)と動画用のベンチマーク(SA-Co/VEval)が含まれています。各データセットには、アノテーション済みの名詞句を持つ画像(または動画)が含まれ、各画像・動画と名詞句のペアには、その句にマッチする各物体のインスタンスマスクと固有IDがアノテーションされています。フレーズにマッチする物体がない場合(ネガティブプロンプト)、マスクは存在しません。
性能評価の結果、Metaによれば、SAM 3はSA-Co GoldサブセットとSA-Co Videoの両方で、cgF1スコア(モデルがコンセプトをどれだけ正確に認識し、位置を特定できるかの指標)を既存モデルの約2倍に向上させました。SA-Co/Goldでは人間の性能が72.8のcgF1スコアを記録したのに対し、SAM 3は54.1を達成し、人間の性能の約75%に到達しています。
画像タスクでは、SAM 3はGemini 2.5 Proのような基盤モデルや、GLEE、OWLv2、LLMDetといった専門的なベースラインモデルを一貫して上回りました。ユーザー調査では、最も強力なベースラインであるOWLv2と比較して、SAM 3の出力が約3対1の割合で好まれたとされています。また、SAM 2の視覚的セグメンテーションタスク(mask-to-masklet、point-to-mask)でも最先端の結果を達成し、SAM 2のような従来モデルの性能に匹敵するか、それを超える性能を示しました。
動画タスクでは、SA-V testでcgF1が30.3、pHOTAが58.0、YT-Temporal-1B testでcgF1が50.8、pHOTAが69.9といった結果が報告されています。人間の性能と比較すると、まだ改善の余地がありますが、コンセプトセグメンテーションという複雑なタスクにおいて一定の性能を示していると言えます。
推論性能と実用性
Metaによれば、SAM 3は高い性能を維持しながら高速な推論を実現しています。H200 GPU上で、100以上の検出物体を含む単一画像の処理が30ミリ秒で完了します。動画では、推論レイテンシが追跡する物体の数に応じてスケールし、約5つの同時物体でほぼリアルタイムの性能を維持できるとされています。
この性能は、Instagram の Editsアプリ、Meta AI アプリの Vibes、Facebook Marketplace の View in Room 機能といったMeta製品への統合を可能にしています。特にEditsアプリでは、クリエイターが動画内の特定の人物や物体にダイナミックなエフェクトを適用できる新機能が近日中に導入される予定です。複雑な編集ワークフローがワンタップで実行できるようになります。
科学分野への応用
SAM 3は科学分野でも既に活用されています。Metaは、Conservation X LabsおよびOsa Conservationと協力し、野生動物モニタリングにSAM 3を適用して、研究用の生動画映像のオープンデータセットを構築しました。公開されているSA-FARIデータセットには、100種以上の10,000本以上のカメラトラップ動画が含まれ、各フレームのすべての動物にバウンディングボックスとセグメンテーションマスクがアノテーションされています。
また、FathomNetという海洋探査のためのAIツール開発を進める研究コラボレーションでは、水中画像に特化したセグメンテーションマスクと新しいインスタンスセグメンテーションベンチマークが、FathomNet Databaseを通じて海洋研究コミュニティに提供されています。これらのデータセットは、陸上および海洋における野生動物の発見、モニタリング、保護のための革新的な手法開発に活用できます。
SAM 3 AgentとMLLMの統合
技術文書によれば、SAM 3は単純な名詞句では優れた性能を発揮しますが、「the second to last book from the right on the top shelf(上段の棚の右から2番目の本)」のようなより複雑で長いフレーズには対応していません。しかし、マルチモーダル大規模言語モデル(MLLM)と組み合わせることで、この制約を克服できることが示されています。
SAM 3をツールとして使用するMLLM「SAM 3 Agent」は、「What object in the picture is used for controlling and guiding a horse?(画像の中で馬を制御し、誘導するために使われている物体は何か?)」といった複雑なテキストクエリをセグメンテーションできます。MLLMがSAM 3にプロンプトとして名詞句クエリを提案し、返されたマスクを分析し、満足のいくマスクが得られるまで反復処理を行います。
referring expression segmentationやreasoning segmentationのデータで訓練されていないにもかかわらず、SAM 3 AgentはReasonSegやOmniLabelといった、推論を必要とする困難なフリーテキストセグメンテーションベンチマークで従来の研究を上回る性能を示しました。この結果は、SAM 3が他のAIシステムの知覚ツールとして有効に機能することを示していると考えられます。
ファインチューニングとドメイン適応
SAM 3が特定のドメインに対してゼロショットで汎化する能力には限界があることも率直に指摘されています。特に、医療画像や科学画像のようなニッチな視覚ドメインにおいて、「platelet(血小板)」のようなドメイン知識を必要とする詳細な用語を識別することは困難です。
ただし、Metaの実験によれば、SAM 3は少量のアノテーション済みデータでファインチューニングすることで、新しいコンセプトや視覚ドメインに迅速に適応できることが確認されています。コードリリースの一環として、コミュニティがSAM 3を特定のユースケースに適応させるために活用できるファインチューニングアプローチが共有されています。また、Roboflowとのパートナーシップにより、ユーザーがデータをアノテーションし、SAM 3をファインチューニングし、特定のニーズに合わせてデプロイすることが可能になっています。
Segment Anything Playgroundの提供
Metaは、SAM 3をより多くの人が利用できるようにするため、「Segment Anything Playground」という新しいプラットフォームを公開しました。技術的専門知識がなくても、誰でも最新モデルを試すことができます。
このプラットフォームでは、画像や動画をアップロードするか、用意されたテンプレートを使用して、すぐに作業を始められます。テンプレートには、顔、ナンバープレート、画面のピクセル化といった実用的なオプションや、スポットライト効果、モーショントレイル、特定物体の拡大といった楽しい動画編集が含まれています。また、視覚データのアノテーションや、SAM 3のストレステストにも役立ちます。
注目すべき点として、SAM 3はMeta Aria Gen 2リサーチグラスのようなウェアラブルデバイスで撮影された一人称視点の映像でも優れた性能を発揮します。Aria Gen 2 Pilot Datasetから選択された録画がSegment Anything Playgroundで利用可能になっており、マシンパーセプション、コンテキストAI、ロボティクスといった、人間の視点から世界を理解することが重要な研究・応用分野でのSAM 3の価値を示しています。
オープンソースとしての公開内容
Metaは、SAM 3のモデルチェックポイント、評価データセット、ファインチューニングコード、研究論文を公開しています。これらのリソースはGitHubリポジトリとHugging Face上でアクセス可能です。
利用にはPython 3.12以上、PyTorch 2.7以上、CUDA 12.6以上が必要で、Conda環境でのセットアップが推奨されています。基本的な使用方法として、画像に対してはbuild_sam3_image_model関数でモデルをロードし、Sam3Processorを使用してテキストプロンプトを設定することで、マスク、バウンディングボックス、スコアを取得できます。動画に対しては、build_sam3_video_predictor関数を使用してセッションを開始し、テキストプロンプトを追加することで処理を行います。
サンプルノートブックには、画像と動画でのテキスト・視覚プロンプトの使用例、バッチ推論の実行例、SAM 3 Agentの使用例、SA-Coデータセットの可視化例などが含まれており、実際の利用を始めやすい環境が整えられています。
今後の課題と展望
SAM 3の現在の限界と今後の改善可能性についても言及されています。前述のとおり、特定ドメインへのゼロショット汎化や、複雑な長文プロンプトへの対応には課題が残っています。また、動画処理では、SAM 3がすべての物体をSAM 2スタイルのmaskletで追跡するため、推論コストが追跡する物体の数に応じて線形にスケールします。各物体が個別に処理され、フレームごとの埋め込みのみを共有し、物体間の通信は行われません。
複数の視覚的に類似した物体が存在する複雑なシーンでは、共有された物体レベルのコンテキスト情報を組み込むことで、効率とモデル性能の向上に役立つ可能性があります。Metaは、これらの課題に対処するための研究をさらに進める必要があると認識しており、AIコミュニティがSAM 3を構築に活用し、SA-Coベンチマークを採用し、これらの新しいリソースを活用してこれらの能力をさらに推進することを期待しています。
まとめ
SAM 3は、テキスト、exemplar、視覚的プロンプトを統合的に扱える画像・動画セグメンテーションの基盤モデルとして、技術的に大きな進展を示しています。400万以上のコンセプトで訓練されたデータセット、SA-Coベンチマークでの2倍の性能向上、オープンソースとしての包括的なリリースは、コンピュータビジョン分野の研究・開発を加速させる可能性があります。Meta製品への統合や科学分野での応用も始まっており、今後の発展が注目されます。








