はじめに
本稿では、Meta社が2025年4月5日に発表した最新の大規模言語モデル(LLM)ファミリー「Llama 4」について、AIエンジニア向けに「The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation」から技術的な側面を深掘りして解説します。アーキテクチャ、トレーニング手法、性能、そしてAI開発にもたらす可能性を探ります。
引用元情報
- 記事タイトル: The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
- 参照元URL: https://ai.meta.com/blog/llama-4-multimodal-intelligence/
- 発行日: 2025年4月5日
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 新モデル登場: Metaは「Llama 4」ファミリーとして、Llama 4 Scout (17Bアクティブパラメータ, 16エキスパート) と Llama 4 Maverick (17Bアクティブパラメータ, 128エキスパート) をオープンウェイトで公開しました。これらはMeta初のネイティブなマルチモーダル能力とMixture-of-Experts (MoE) アーキテクチャを採用したモデルです。
- Llama 4 Scout: 同クラス最高性能のマルチモーダルモデルであり、単一のNVIDIA H100 GPU(Int4量子化時)に搭載可能です。特筆すべきは、業界をリードする1000万トークンという広大なコンテキスト長です。
- Llama 4 Maverick: こちらもクラス最高のマルチモーダル性能を持ち、GPT-4oやGemini 2.0 Flash等の競合を多くのベンチマークで上回ります。特に推論とコーディングにおいて、より少ないアクティブパラメータ数でDeepSeek v3に匹敵する性能を示し、優れたコストパフォーマンスを実現します。
- 教師モデル Llama 4 Behemoth: これらのモデルの高性能化の鍵となったのが、現在もトレーニング中の超巨大モデルLlama 4 Behemoth (288Bアクティブパラメータ, 16エキスパート, 約2兆総パラメータ) からの蒸留 (distillation) です。Behemoth自体も、いくつかのSTEMベンチマークでGPT-4.5等を凌駕する性能を持っています。
- 技術革新: MoEアーキテクチャによる計算効率の向上、Early Fusionによるネイティブなマルチモーダル能力の実現、FP8精度での効率的なトレーニング、iRoPEアーキテクチャによる長文脈対応など、多くの技術的進歩が見られます。
- 安全性とバイアス: Llama Guard、Prompt Guard、CyberSecEvalといったツールや評価手法(GOATなど)を用い、安全性確保とバイアス低減にも継続的に取り組んでいます。

詳細解説
Llama 4 モデル群の共通の特徴
ネイティブなマルチモーダル:Early Fusion アプローチ
Llama 4の際立った特徴の一つが「ネイティブなマルチモーダル」です。これは、テキスト情報だけでなく、画像や動画フレームといった視覚情報も、モデルの設計段階から統合的に扱えるように構築されていることを意味します。
技術的には「Early Fusion」と呼ばれるアプローチを採用しています。これは、入力の初期段階でテキストトークンと画像(や動画フレームから抽出された)トークンを融合させ、単一のモデルバックボーンで処理する方式です。従来の、テキストモデルに後から画像認識モジュールを接続するような「Late Fusion」とは異なり、より深く、シームレスなモーダル間の連携・理解が可能になります。これにより、例えば「この画像のこの部分について説明して」といった、より複雑な指示への対応能力が向上します。Metaは、大量のラベルなしテキスト、画像、動画データを用いて共同で事前学習(jointly pre-train)することで、この能力を実現しました。また、視覚エンコーダー自体もMetaCLIPベースでありながら改良が加えられています。
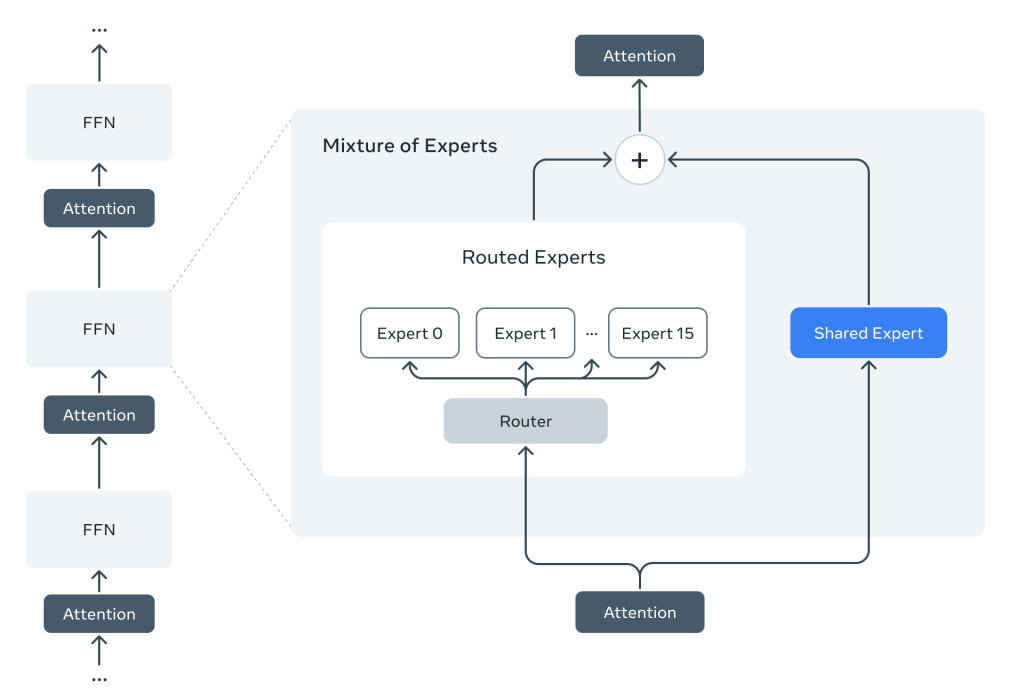
計算効率と性能を両立:Mixture-of-Experts (MoE)
Llama 4で初めて採用された「Mixture-of-Experts (MoE)」アーキテクチャは、近年のLLMスケーリングにおける重要な技術トレンドです。従来の「Dense(密)」モデルでは、入力トークンごとにモデルの全パラメータが計算に関与していました。これに対しMoEでは、モデル内に複数の「エキスパート(特定のサブネットワーク)」を用意し、「ルーター」と呼ばれる機構が、入力トークンごとに関連性の高い少数のエキスパートを選択して計算を割り当てます。
例えば、Llama 4 Maverickは合計4000億という膨大なパラメータを持ちますが、一度の推論で活性化するのは170億パラメータのみです(128の経路選択エキスパートのうち1つ + 共有エキスパート)。これにより、モデル全体の知識容量(総パラメータ数)を増やしつつ、トレーニングおよび推論時の計算コスト(FLOPs)とレイテンシを大幅に削減できます。Llama 4では、推論効率のためDense層とMoE層を交互に配置しています。この効率性により、Maverickは単一のNVIDIA H100 DGXホストでの実行も可能になっています。
大規模な事前学習
Llama 4モデルは、Llama 3の2倍以上となる30兆以上のトークンを含む、多様なテキスト、画像、ビデオデータセットで事前学習されています。この大規模な事前学習により、モデルは幅広い知識と能力を獲得しています。さらに、200の言語で事前学習が行われており、そのうち100以上の言語はそれぞれ10億以上のトークンを含んでいるため、Llama 3と比較して10倍以上の多言語トークンで学習されています。これにより、多言語環境での性能が向上しています。
Llama 4 Behemoth から Llama 4 Maverick を教師モデルとして 共蒸留 (codistillation) することで、エンドタスクの評価指標において大幅な品質向上が実現されました 。共蒸留は、教師モデルからのソフトターゲットとハードターゲットを動的に重み付けする新しい蒸留損失関数を用いて行われます。
効率的なトレーニング
Llama 4モデルのトレーニングには、FP8精度が使用されており、品質を損なうことなく高いモデルFLOPs利用率を達成しています。例えば、Llama 4 Behemothの事前学習時には、32,000個のGPUを使用し、390 TFLOPs/GPUの効率を実現しています。また、MetaPと呼ばれる新しいトレーニング技術が開発され、層ごとの学習率や初期化スケールなどの重要なハイパーパラメータを信頼性高く設定することが可能になっています。
ポストトレーニング
Llama 4 モデルのポストトレーニングでは、軽量な教師ありファインチューニング (SFT)、オンライン強化学習 (RL)、軽量な Direct Preference Optimization (DPO) という新しいパイプラインが採用されました。
ポストトレーニングの順番
- 軽量な教師ありファインチューニング (SFT)
- オンライン強化学習 (RL)
- 軽量な Direct Preference Optimization (DPO)
※各手法について
- SFT (Supervised Fine-Tuning): 正解ラベル付きのデータセットを用いてモデルを微調整する。
- RL (Reinforcement Learning): モデルの応答に対する報酬(良し悪し)に基づいてモデルを強化学習させる。
- DPO (Direct Preference Optimization): 人間の好みを直接学習データとして利用し、RLHF(人間からのフィードバックによる強化学習)よりも安定かつ効率的にモデルを調整する手法。
長文脈処理能力の強化
Llama 4モデルは、特にLlama 4 Scoutにおいて、業界をリードする1000万トークンという非常に長い入力コンテキスト長をサポートしています。これは、Llama 3の128Kトークンから大幅に拡張されています。この長文脈処理能力は、「mid-training」と呼ばれる継続的なトレーニングと、特別なデータセットを用いた長文脈拡張によって実現されています。また、Llama 4 Scoutでは、iRoPE(interleaved attention layers without positional embeddings)アーキテクチャが導入されており、高度な入力長の拡張への一般化能力に貢献しています。
安全性とバイアスへの取り組み
Metaは、モデルの有用性と共に安全性と公平性の確保にも注力しています。
- 開発ライフサイクル全体での対策: 事前学習でのデータフィルタリングから、ポストトレーニングでの安全な応答のためのデータ統合、開発者が利用可能なシステムレベルのツールまで、多層的な対策を講じています。
- システムレベルツール:
- Llama Guard: 入出力が安全ポリシーに違反しないか検出するLLM。MLCommonsと共同開発したハザード分類に基づきます。
- Prompt Guard: ジェイルブレイクやプロンプトインジェクションといった悪意のある入力を検出する分類器。
- CyberSecEval: 生成AIのサイバーセキュリティリスク評価ツール群。
- 評価とレッドチーミング: 自動化(GOAT: Generative Offensive Agent Testing)と専門家による手動テストを組み合わせ、体系的なリスク評価とモデル改善を実施。GOATはマルチターンの対話型攻撃をシミュレートし、脆弱性発見を効率化します。
- バイアス低減: LLMが持つ政治的・社会的話題における偏り(特に左派寄り)を認識し、多様な視点を公平に扱えるように改善を進めています。Llama 4はLlama 3と比較して、議論のあるトピックに対する応答拒否率が大幅に低下(7%→2%未満)し、応答の偏りも減少(1%未満)。政治的偏りの強い応答の頻度もGrok並みに低減(Llama 3.3の半分)したと報告されていますが、継続的な改善が必要であることも認識されています。
オープンソースの哲学
Metaは、Llama 4 ScoutとMaverickをオープンウェイト(モデルの重みを公開)としてリリースしました。これは、開発者、研究者、企業が自由にモデルをダウンロードし、利用、改変、再配布(ライセンス条件に従う範囲で)できることを意味します。Metaは、オープン性がイノベーションを加速し、開発者、Meta自身、そして世界全体にとって有益であるという信念に基づき、このアプローチを継続しています。Hugging Faceや主要なクラウドプラットフォーム経由での利用も可能になります。
Llama 4 ファミリー:各モデルごとの特徴
Llama 4モデル群には、それぞれ異なる特性を持つ複数のモデルが含まれています。現時点で詳細が公開されている主要なモデルは、Llama 4 Scout、Llama 4 Maverick、そして教師モデルであるLlama 4 Behemothです。
Llama 4 Scout
- パラメータ数とアーキテクチャ: 170億のアクティブパラメータと16のエキスパートを持つMoEモデルです。総パラメータ数は1090億です。
- コンテキスト長: 業界をリードする1000万トークンのコンテキストウィンドウをサポートしています。これは、長文脈を必要とするタスクにおいて非常に強力な能力を発揮します。
- 性能: 同クラスのモデルの中で世界最高のマルチモーダルモデルであり、前世代のすべてのLlamaモデルよりも強力です。Gemma 3、Gemini 2.0 Flash-Lite、Mistral 3.1といった他の主要なモデルよりも、広範なベンチマークで優れた結果を示しています。特に、コーディング、推論、長文脈、画像ベンチマークにおいて優れた性能を発揮し、画像グラウンディングにおいてもクラス最高です。
- ハードウェア要件: Int4量子化を使用すれば、単一のNVIDIA H100 GPUに収まります。
- 主な用途: 複数文書の要約、広範なユーザーアクティビティの解析によるパーソナライズされたタスク、膨大なコードベースにわたる推論など、長文脈を活かしたアプリケーションに適しています。また、正確な視覚的質問応答やユーザー意図の理解、関心のあるオブジェクトの特定など、画像理解を伴うタスクにも優れています。
256Kコンテキスト長での事前学習と事後学習
Llama 4 Scoutは、事前学習と事後学習の両方において256,000トークン(256K)という非常に長いコンテキスト長で訓練されています。これは、Llama 3の128Kと比較して大幅な拡張です。このような長いコンテキスト長でモデルを訓練することにより、Llama 4 Scoutは、より長い入力シーケンス全体にわたる依存関係を学習し、理解する能力を高めることができます。
高度な長さの汎化能力
256Kという長いコンテキスト長での訓練は、Llama 4 Scoutに「高度な長さの汎化能力」を与えます。これは、訓練時に見たことのない、より長いシーケンスの入力に対しても、適切に推論し、応答できる能力を意味します。従来の言語モデルは、訓練時のコンテキスト長を超える入力に対して性能が低下する傾向がありましたが、Llama 4 Scoutは、より長い文脈を理解し、活用することができるため、より複雑なタスクに対応できるようになります。
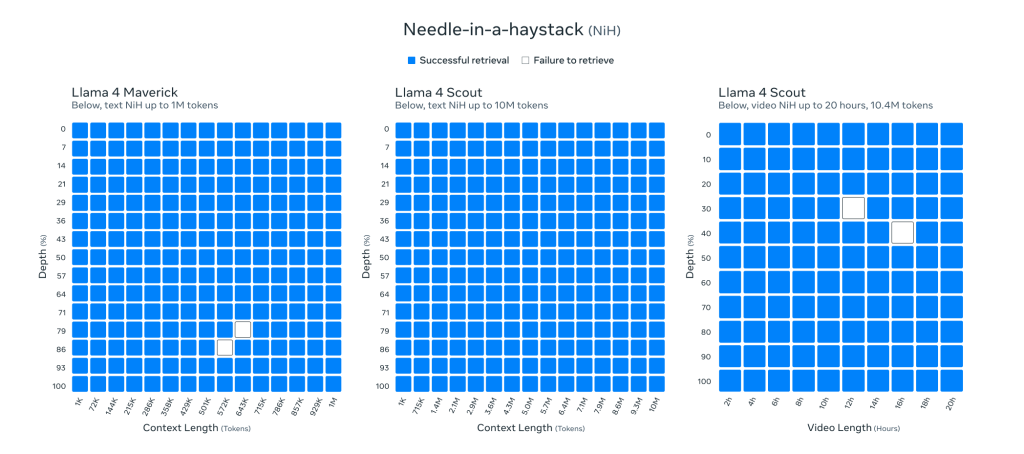
検索タスクの結果 (“retrieval needle in haystack”)
テキストにおける「retrieval needle in haystack(干し草の山から針を探す)」タスクでの優れた結果が示されています。このタスクは、非常に長いテキストの中に埋め込まれた特定の情報を正確に検索し、取り出す能力を評価するものです。Llama 4 Scoutがこのタスクで「compelling results(説得力のある結果)」を示したことは、長い文脈の中から目的の情報を正確に見つけ出す能力が高いことを示唆しています。これは、例えば、長いドキュメントの中から特定の質問に対する答えを見つけるようなアプリケーションにおいて非常に重要です。
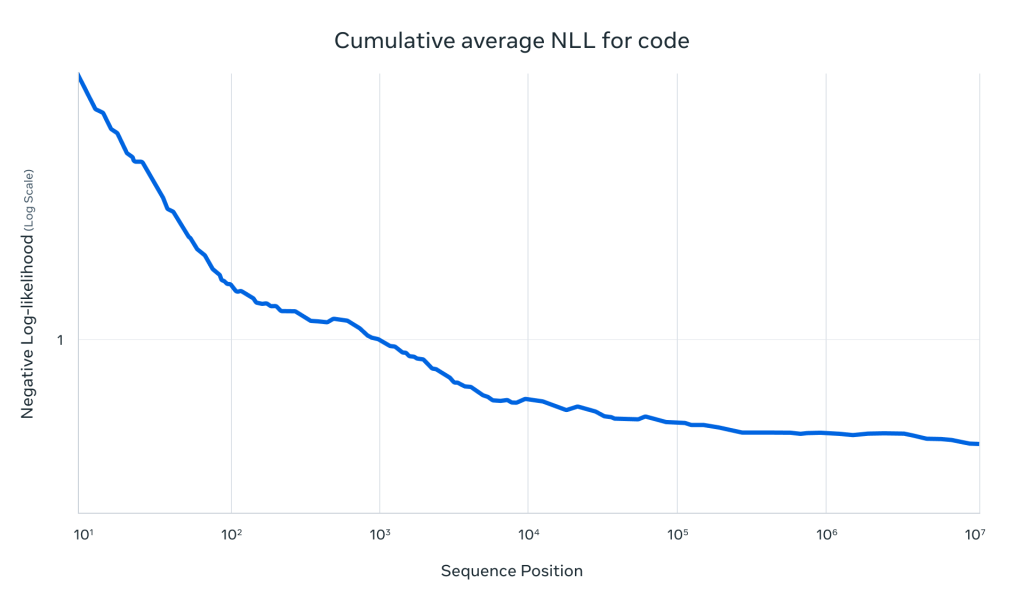
1000万トークンのコードでの累積負の対数尤度 (NLLs) の結果
Llama 4 Scoutは、1000万トークンという非常に長いコードのシーケンスに対する累積負の対数尤度 (NLLs) においても優れた結果を示しています。NLLは、言語モデルが次のトークンを予測する際の不確実性を測る指標であり、値が低いほど予測の確信度が高いことを意味します。1000万トークンもの長いコードに対して低いNLLを達成していることは、Llama 4 Scoutが非常に長いコードの構造やパターンを理解し、正確に予測できる能力を持っていることを示しています。これは、コードの理解、生成、分析といったタスクにおいて大きな利点となります。
iRoPEアーキテクチャ
Llama 4 Scoutのアーキテクチャにおける重要な革新は、「interleaved attention layers without positional embeddings(位置埋め込みのないインターリーブされた注意層)」の使用です。従来のTransformerモデルでは、入力トークンの位置情報をエンコードするために位置埋め込みが用いられますが、Llama 4 Scoutではこれがありません。代わりに、「interleaved attention layers(インターリーブされた注意層)」と呼ばれる新しい注意機構が導入されています。
このアーキテクチャは「iRoPE」と名付けられています。
- i (interleaved): 「i」は「interleaved attention layers(インターリーブされた注意層)」を意味し、注意層の構造が新しいものであることを示しています。これは、長期的な目標である「infinite(無限)」コンテキスト長のサポートを示唆しています。
- RoPE (Rotary Position Embeddings): 「RoPE」は、ほとんどの層で「rotary position embeddings(回転位置埋め込み)」が採用されていることを指します。RoPEは、トークンの相対的な位置関係を効果的にモデル化できるとされています。
推論時の注意の温度スケーリング (inference time temperature scaling of attention)
さらに、Llama 4 Scoutでは、「inference time temperature scaling of attention(推論時の注意の温度スケーリング)」が用いられ、長さの汎化能力を強化しています。温度スケーリングは、モデルの出力確率分布を調整する技術であり、推論時に注意の重みを調整することで、より長い文脈においても安定した予測を可能にすると考えられます。
Llama 4 Maverick
- パラメータ数とアーキテクチャ: 170億のアクティブパラメータと128のエキスパートを持つMoEモデルです。総パラメータ数は4000億です。
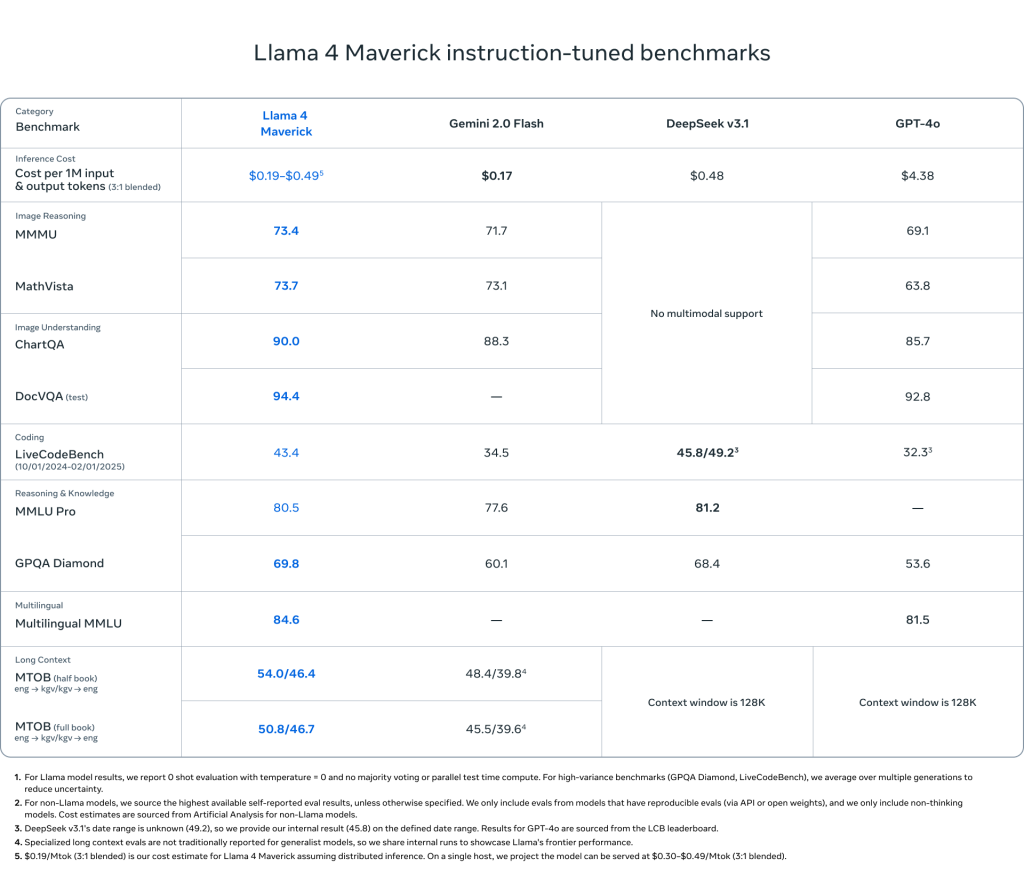
- 性能: このクラスでは最高のマルチモーダルモデルであり、広範なベンチマークでGPT-4oやGemini 2.0 Flashを上回る性能を示しています。推論とコーディングにおいては、パラメータ数が大幅に多いDeepSeek v3と同等の結果を達成しています。LMArenaの実験的なチャットバージョンでは、1417のELOスコアを獲得し、クラス最高の性能対コスト比を実現しています。画像とテキストの理解において業界をリードする性能を持ち、コーディング、推論、多言語、長文脈、画像ベンチマークで優れた結果を示しています。
- ハードウェア要件: 単一のNVIDIA H100 DGXホストで実行可能であり、容易なデプロイが可能です。分散推論を用いることで、さらに効率を高めることができます。
- 主な用途: 一般的なアシスタントおよびチャットのユースケース向けの主力モデルとして設計されており、正確な画像理解と創造的なライティングに優れています。言語の壁を越えた高度なAIアプリケーションの作成を可能にします。Llama 4 Behemothを教師モデルとした蒸留によって、大幅な品質向上が実現しています。
ポストトレーニングの特徴
Llama 4 Maverick のポストトレーニングでは、複数の入力モダリティ、推論能力、会話能力のバランスを保つことが重要な課題でした。そのため、個々のモダリティ専門家モデルと比較して性能が低下しないように、慎重にキュレーションされたカリキュラム戦略が用いられました。オンライン RL の段階では、Llama モデルを判定器として使用し、容易なデータの 50% 以上を削除し、残りの困難なデータセットで軽量な SFT を実施しました。続くマルチモーダルオンライン RL 段階では、より困難なプロンプトを慎重に選択することで、性能が大幅に向上しました。さらに、モデルをトレーニングした後、それを使用して中〜高難易度のプロンプトを継続的にフィルタリングして保持する 継続的なオンライン RL 戦略 が実装されました 。これにより、計算コストと精度のトレードオフにおいて非常に有益な結果が得られました。最後に、モデルの応答品質に関するエッジケースに対処するために、軽量な DPO が実施され、モデルの知性と会話能力の良好なバランスが達成されました
Llama 4 Behemoth
- パラメータ数とアーキテクチャ: 2880億のアクティブパラメータと16のエキスパートを持つ、約2兆の総パラメータを持つマルチモーダルMoEモデルです。
- 役割: そのクラスのモデルの中で高度なインテリジェンスを示す教師モデルであり、より ছোটサイズのLlama 4モデル(主にLlama 4 Maverick)を訓練するために使用されました。
- 性能: 数学、多言語、画像ベンチマークにおいて、非推論モデルとして最先端のパフォーマンスを提供します。GPT-4.5、Claude Sonnet 3.7、Gemini 2.0 Proといった他の強力なモデルを、いくつかのSTEM分野のベンチマークで上回っています。
- 現在の状況: 現在もトレーニング中であり、さらなる詳細については後日公開される予定です。
- 蒸留: Llama 4 Maverickは、Llama 4 Behemothを教師モデルとして共同蒸留されており、このプロセスを通じて、エンドタスク評価指標において大幅な品質向上が達成されました。Metaは、教師モデルからの蒸留が、リソース集約的なフォワードパスの計算コストを償却する上で有効であると説明しています。
まとめ
本稿では、Metaの最新LLMファミリー「Llama 4」について、特にAIエンジニア向けに技術的な詳細を解説しました。Llama 4 ScoutとLlama 4 Maverickは、ネイティブなマルチモーダル能力とMixture-of-Experts (MoE) アーキテクチャを組み合わせることで、高性能と高効率を両立しています。特にScoutが実現した1000万トークンのコンテキスト長は、これまでにない規模の情報を扱える可能性を開きます。
Early Fusionによる自然なモーダル統合、MoEによる計算効率の向上、iRoPEなどのアーキテクチャ革新、蒸留による効率的な知識継承、そして洗練されたトレーニング・ポストトレーニング手法は、現代のLLM開発における最先端の取り組みを示しています。
これらのモデルがオープンソースとして提供されることで、画像と言語を組み合わせた高度なアプリケーション、超長文脈を利用した新たな分析・要約タスク、コスト効率に優れたAIソリューションなど、多様な分野でのイノベーションが加速することが期待されます。Llama 4は、AI技術の進化とその応用範囲の拡大を示す、重要なマイルストーンと言えるでしょう。








