
はじめに
近年、目覚ましい進化を遂げているAI(人工知能)の世界で、Meta社(旧Facebook)が新たな大規模言語モデル(LLM)「Llama 4」ファミリーを発表しました。本稿では、2025年4月5日に公開されたMeta AIブログの記事「The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation」に基づき、このLlama 4がどのような技術で、私たちにどのような未来をもたらす可能性があるのかを、AIに詳しくない方にも分かりやすく解説します。特に、Llama 4 Scout と Llama 4 Maverick という2つのモデルに焦点を当て、その特徴と重要性を見ていきましょう。
引用元情報
- 記事タイトル: The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
- 参照元URL: https://ai.meta.com/blog/llama-4-multimodal-intelligence/
- 発行日: 2025年4月5日
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
今回発表されたMeta社のブログ記事の要点は以下の通りです。
- Metaは、新しいAIモデル群「Llama 4」ファミリーの最初のモデルとして、Llama 4 Scout と Llama 4 Maverick を発表しました。これらはオープンウェイト(重みが公開されている)で、ネイティブなマルチモーダル(テキスト、画像、動画などを統合的に扱える)能力を持つ初のモデル群です。
- Llama 4 Scout は、170億のアクティブパラメータと16のエキスパートを持つモデルで、同クラス最高のマルチモーダル性能を持ち、単一のNVIDIA H100 GPUに搭載可能です。1000万トークンという業界トップクラスのコンテキスト長(一度に処理できる情報量)も特徴です。
- Llama 4 Maverick は、170億のアクティブパラメータと128のエキスパートを持つモデルで、GPT-4oやGemini 2.0 Flashといった競合モデルを多くのベンチマークで上回り、より少ないパラメータ数でDeepSeek v3と同等の性能(特に推論とコーディング)を達成しています。
- これらのモデルの高性能化は、現在もトレーニング中の巨大な「教師モデル」Llama 4 Behemoth(2880億アクティブパラメータ、16エキスパート)からの蒸留(知識の伝達)によって実現されています。BehemothはいくつかのSTEM(科学・技術・工学・数学)ベンチマークでGPT-4.5などを上回る性能を示しています。
- Llama 4は、Mixture-of-Experts (MoE) アーキテクチャを採用し、トレーニングと推論(実際にAIを使うこと)の計算効率を高めています。
- 安全性とバイアス(偏り)の低減にも注力しており、Llama Guardなどのツールや評価手法を用いてリスクを管理しています。

詳細解説
そもそも大規模言語モデル(LLM)とは?
本題に入る前に、大規模言語モデル(LLM: Large Language Model)について簡単におさらいします。LLMは、大量のテキストデータを学習することで、人間のように自然な文章を生成したり、質問に答えたり、文章を要約したりする能力を持つAIです。ChatGPTなどが有名ですね。LlamaもこのLLMの一種です。
「ネイティブなマルチモーダル」とは?
Llama 4の大きな特徴の一つが「ネイティブなマルチモーダル」である点です。これは、テキストだけでなく、画像や動画(のフレーム)も一緒に理解し、処理できる能力を、モデルの設計段階から組み込んでいることを意味します。「後付け」で画像認識機能を追加するのではなく、最初からテキストと画像を統合的に扱うように作られているため、より自然で高度な連携が可能です。例えば、画像の内容について質問したり、画像とテキストを組み合わせた指示を出したりすることができます。
ブログ記事によれば、Llama 4はテキストと視覚情報を早期に融合させる「early fusion」アプローチを採用し、大量のラベルなしテキスト、画像、動画データで共同事前学習を行うことでこれを実現しています。
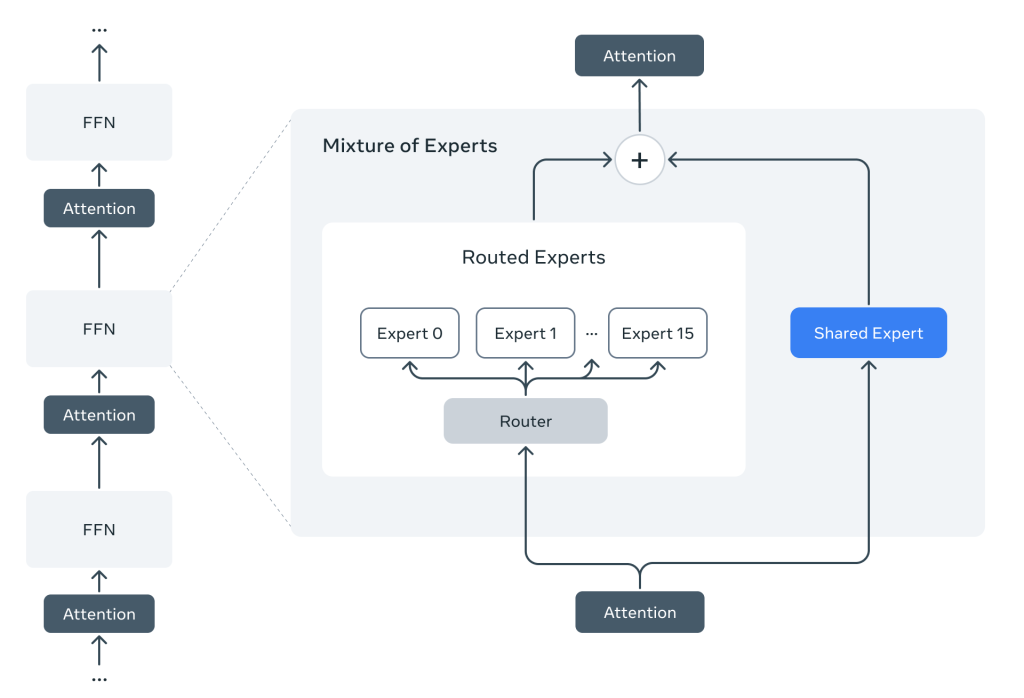
計算効率を高める「Mixture-of-Experts (MoE)」
Llama 4では、Mixture-of-Experts (MoE) というアーキテクチャが初めて採用されました。これは、モデル全体を常にフル稼働させるのではなく、入力された情報(トークン)に応じて、モデル内の一部の「エキスパート(専門家)」だけを活性化させる仕組みです。
例えば、Llama 4 Maverick は合計4000億のパラメータを持ちますが、一度の処理で実際に使われる(アクティブな)パラメータは170億です。これにより、トレーニングや推論に必要な計算量を抑えつつ、モデル全体の規模を大きくして高性能化を図ることができます。コスト効率と応答速度の向上に繋がります。
Llama 4 ファミリーのモデルたち
- Llama 4 Scout (17B, 16 Experts):
- 170億のアクティブパラメータ、16のエキスパート、合計1090億パラメータ。
- 業界トップクラスの1000万トークンという驚異的なコンテキスト長を持ちます。これは、非常に長い文書(例えば複数冊の本)や大量のコード、長時間のユーザーアクティビティなどを一度に読み込んで理解・要約・分析できることを意味します。
- 画像内の特定の領域とユーザーの指示を結びつける画像グラウンディング能力にも優れています。
- 単一のNVIDIA H100 GPU(Int4量子化時)で動作可能で、導入しやすいのが利点です。
- Gemma 3、Gemini 2.0 Flash-Lite、Mistral 3.1といったモデルを多くのベンチマークで上回ります。
- Llama 4 Maverick (17B, 128 Experts):
- 170億のアクティブパラメータ、128のエキスパート、合計4000億パラメータ。
- 同クラス(パラメータ数)では最高のマルチモーダル性能を誇り、GPT-4oやGemini 2.0 Flashを多くのベンチマークで凌駕します。
- 推論やコーディング能力では、より大規模なDeepSeek v3.1に匹敵する性能を持ちながら、アクティブパラメータ数は半分以下です。
- コストパフォーマンスに優れ、一般的なアシスタントやチャット用途に適しています。
- Llama 4 Behemoth (288B, 16 Experts, Preview):
- 2880億のアクティブパラメータ、16のエキスパート、合計約2兆パラメータを持つ超巨大モデル。
- 現在もトレーニング中ですが、すでにいくつかのSTEM(科学・技術・工学・数学)関連ベンチマークでGPT-4.5やClaude Sonnet 3.7、Gemini 2.0 Proを上回る結果を出しています。
- ScoutやMaverickの性能向上に貢献した「教師モデル」としての役割を担っています。Behemothから知識を蒸留(distillation)することで、より小さいモデルでも高い性能を引き出すことに成功しました。
トレーニング手法の進化
Llama 4の開発では、トレーニング手法にも多くの改善が加えられました。
- MetaP: ハイパーパラメータ(学習率など)を効率的に設定する新技術。
- FP8精度: 計算精度を少し落とす(FP8)ことで、品質を損なわずに計算速度と効率を大幅に向上(32,000 GPU使用時に390 TFLOPs/GPUを達成)。
- データ量: Llama 3の2倍以上となる30兆トークンを超える多様なテキスト、画像、動画データで学習。
- 多言語対応: 200言語(うち100言語以上は10億トークン超)で事前学習し、多言語能力を強化。
- Long Context: Scoutの1000万トークン実現のため、特殊なデータセットを用いた「ミッドトレーニング」や、位置エンベディングなしの注意層を交互配置する「iRoPE」アーキテクチャ、推論時の温度スケーリングなどを採用。
- Post-training: 軽量なSFT(教師ありファインチューニング)、オンライン強化学習(RL)、軽量なDPO(直接嗜好最適化)を組み合わせた新しいパイプラインを採用。特にRL段階で難しいプロンプトを選択的に学習させることで性能を向上。
安全性とバイアスへの取り組み
Metaは、AIの安全性と公平性にも力を入れています。
- データフィルタリング: 事前学習段階で不適切なデータを除去。
- 安全な応答のための学習: ファインチューニング段階で、安全に関するデータを組み込み。
- システムレベルのツール:
- Llama Guard: 入出力が安全ポリシーに違反しないか検出するLLM。
- Prompt Guard: 不正なプロンプト(ジェイルブレイクやプロンプトインジェクション)を検出する分類器。
- CyberSecEval: サイバーセキュリティリスクの評価ツール。
- バイアス(偏り)の低減: 政治的・社会的な話題において、特定の立場に偏らず、多様な視点を理解し提示できるように改善。Llama 4はLlama 3よりも応答拒否が減り、よりバランスの取れた応答をするように進歩しています。
オープンソースの重要性
Metaは、Llama 4 ScoutとMaverickをオープンウェイトとして公開しました。これにより、開発者や研究者はモデルを自由にダウンロードし、自社のサービスに組み込んだり、さらなる研究開発を進めたりできます。Metaは、オープン性がイノベーションを促進するという信念に基づき、この方針を継続しています。
まとめ
本稿では、Metaが発表した最新の大規模言語モデル「Llama 4」ファミリーについて解説しました。Llama 4 Scout と Llama 4 Maverick は、ネイティブなマルチモーダル能力、Mixture-of-Experts (MoE) による効率性、そしてScoutにおいては1000万トークンという驚異的なコンテキスト長を実現した、新世代のAIモデルです。
これらのモデルは、よりパーソナライズされた体験や、これまで不可能だった長文・大量データの処理、画像と言語を組み合わせた高度なAIアプリケーションの開発を可能にするでしょう。また、巨大な教師モデル Llama 4 Behemoth の存在は、今後のさらなる性能向上への期待を抱かせます。
Metaがこれらの高性能モデルをオープンに提供することで、AI技術の民主化が進み、世界中の開発者によって革新的なサービスやユースケースが生まれることが期待されます。Llama 4は、AIが私たちの生活やビジネスをどう変えていくのか、その未来を垣間見せてくれる重要な一歩と言えるでしょう。








