近年、私たちの生活やビジネスの現場でAI(人工知能)の進化は目覚ましいものがあります。スマートフォンの音声アシスタントから、企業の業務効率化ツールまで、AIは様々な形で私たちの身の回りに浸透してきました。しかし、「AIは一体どこまでできるようになるのか?」という問いに対して、明確な答えを持っている方は少ないのではないでしょうか。
本記事では、AIの能力を新しい視点から捉え、その進化の度合いを「時間」という分かりやすい単位で測る画期的な研究論文「Measuring AI Ability to Complete Long Tasks」をご紹介します。この研究を読むことで、AIの現在の実力、そして将来の可能性について、より深く理解することができるでしょう。
引用元論文
- 論文名:Measuring AI Ability to Complete Long Tasks
- URL:https://arxiv.org/abs/2503.14499
- 発表日:2025年3月18日
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。必ず参照元論文記事をご確認ください。
・本記事内での画像は、上記論文より引用しております。
研究の要点:AIの「時間ホライズン」が示す驚異的な進化
この研究の中心となるのは、「50%タスク完了時間ホライズン」という新しい指標です。これは、AIモデルが特定のタスクを50%の成功率で完了できるとき、そのタスクを人間の専門家が通常どれくらいの時間をかけて完了するかを示したものです。
研究者たちは、ソフトウェア開発や研究に関連する様々なタスク(簡単な質問応答から、数時間かかるプログラミング、さらには8時間にも及ぶ機械学習の研究プロジェクトまで)を用いて、最先端のAIモデルの能力を評価しました。同時に、これらのタスクを人間の専門家にも試してもらい、完了にかかる時間を計測しました。
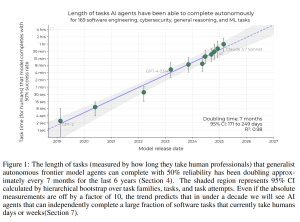
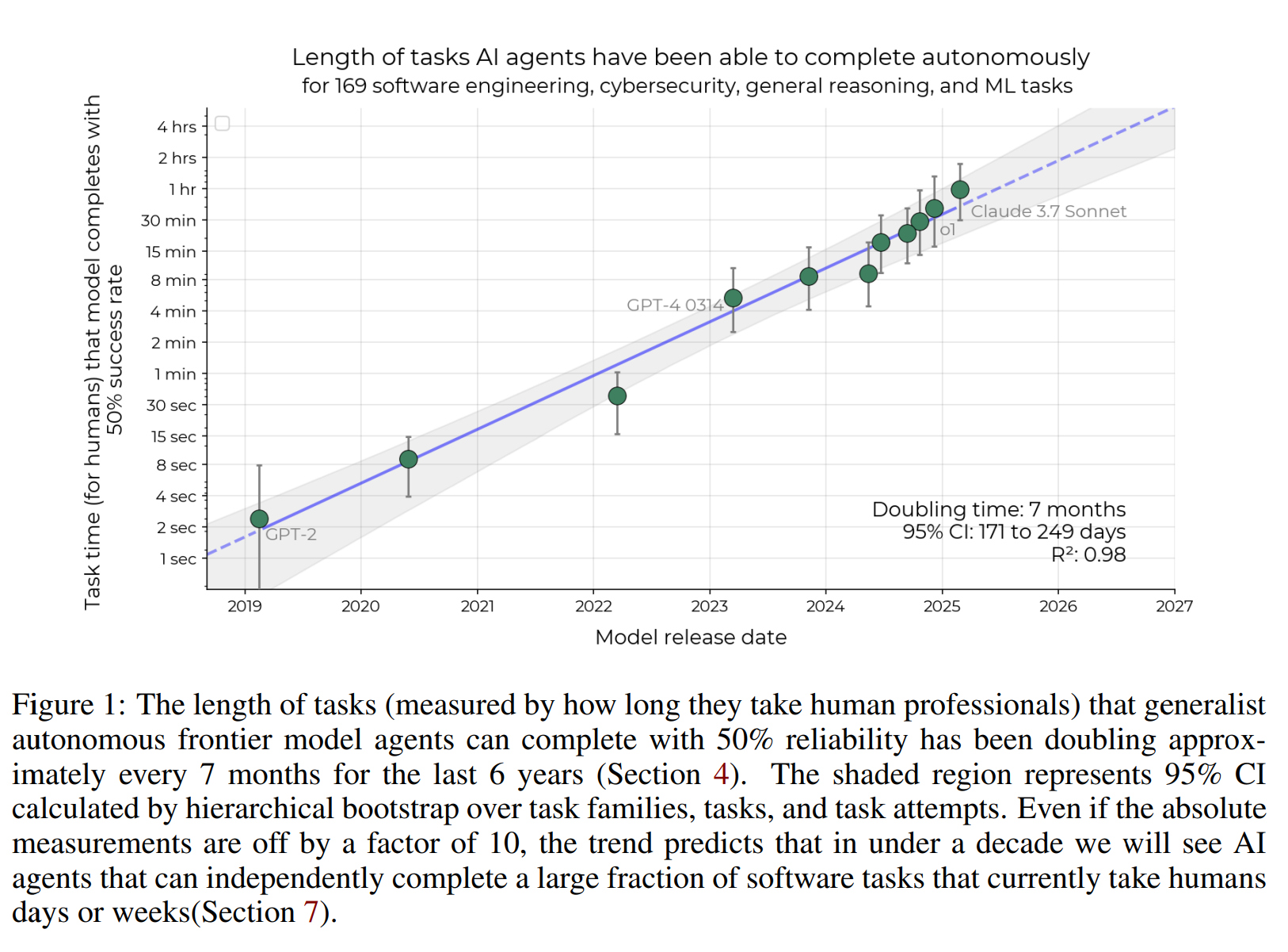
その結果、驚くべき事実が明らかになりました。2019年から2025年にかけて、最先端AIの50%タスク完了時間ホライズンは約7ヶ月ごとに倍増しているというのです。これは、AIが以前よりもはるかに長い時間を要する複雑なタスクを、着実にこなせるようになっていることを意味します。
さらに、2024年に入ってからは、この進化のスピードが加速している可能性も示唆されています。もしこの傾向が現実世界のソフトウェアタスクにも当てはまるとすれば、研究者たちは、5年以内にAIが現在人間が1ヶ月かけて行っているような多くのソフトウェアタスクを自動化できるようになるかもしれないと予測しています。
このAIの能力向上の主な要因としては、より高い信頼性、間違いから学び適応する能力の向上、そして論理的な推論能力やツール(ソフトウェアなど)の利用能力の向上が挙げられています。
詳細解説:論文の各項を読み解く
ここからは、論文の各項に沿って、研究の内容をより詳しく解説していきます。
1. 導入 (Introduction)
論文の冒頭では、過去5年間でAIシステム、特に「フロンティアAIシステム」(最先端のAI)が基本的なテキスト生成から、数時間にも及ぶ複雑な機械学習の研究プロジェクトを自律的に実行できるまでに劇的な進化を遂げてきたことが述べられています。
このような能力を持つAIは、将来的には化学兵器、生物兵器、放射性物質兵器、核兵器(CBRN)の自律的な開発や、人間の制御外での自己複製や適応といった、危険で非常に複雑な行動も実行できるようになる可能性も指摘されています。
A Iの能力を理解することは、システムがますます強力になるにつれて、安全のための対策を講じる上で非常に重要です。多くのフロンティアAI開発者は、AIの特定の能力の指標を用いて、自社のAIシステムに必要なリスク軽減策を決定することを公約しています。したがって、AIの能力を正確に追跡し、予測できる信頼性の高いベンチマーク(評価基準)が、責任あるAIガバナンスとリスク軽減の基盤となるのです。
用語解説:
- フロンティアAI: 最先端の、現時点で最も高い能力を持つAIシステムを指します。
- ベンチマーク: AIシステムの性能を評価するためのテストや課題の集まりです。
- AIガバナンス: AIの開発と利用を管理するための原則やルールの体系です。
2. 関連研究 (Related work)
この項では、AIの能力評価や進捗予測に関する既存の研究が紹介されています。
2.1 エージェントおよび能力ベンチマーク
従来のAIベンチマークは、主に言語モデルの静的な知識を測るものであり、現実世界での応用に必要な動的な問題解決能力を評価するには限界がありました。近年では、より複雑なエージェント(自律的に行動するAI)の行動を評価するためのベンチマーク(AgentBench、MLAgentBench、ToolBench など)が登場しています。ソフトウェアエンジニアリングの分野も、AI能力を評価する上で重要な領域であり、HumanEval やSWE-bench といった、より複雑なプログラミング能力をテストするベンチマークが存在します。本研究でも使用されているRE-Bench は、数時間を要する複雑な研究開発タスクでAIの性能を評価し、人間の機械学習エンジニアの能力と比較するものです。
しかし、これらのベンチマークは、時間経過に伴う進捗を追跡したり、能力が大きく異なるモデル間を比較したりするための統一された指標を欠いていることが課題でした。本研究の提案する時間ホライズンというアプローチは、異なる能力レベルのAIの進捗を測定できる連続的な指標を提供することで、このギャップを埋めることを目指しています。
用語解説:
- 言語モデル: 人間の言語を理解し、生成するAIモデルの一種です。GPTシリーズなどが該当します。
- エージェント: 環境を認識し、目標達成のために自律的に行動するAIシステムです。
2.2 AIの進捗予測
AIの進捗を定量的に予測する試みとして、AIの学習に用いられる計算資源の増加に着目した研究があります。AmodeiとHernandez は、2012年から2018年の間にAI学習に必要な計算量が約3.4ヶ月ごとに倍増していることを示しました。他の研究では、ベンチマークの性能とリリース日、計算資源などの関係を分析し、将来の性能を予測しようとしています。
また、AIベンチマークの性能を現実の能力と関連付けようとする取り組みも存在します。例えば、AI Index Report は、様々なベンチマークでAIが人間のレベルに到達した時期を追跡しています。
Carlsmith やCotra は、AIモデルの学習に必要な計算量と、AIが社会に大きな変革をもたらすために必要なタスクの「実効的なホライズン長」を関連付ける「bio-anchors」というフレームワークを開発しました。Ngo は、ほとんどのタスクにおいて、ほとんどの人間の専門家を凌駕する時間ホライズンをAIシステムが持つようになる時期を、汎用AI能力の指標として提案しています。本研究では、タスクの所要時間とAIエージェントの成功率の関係を経験的に評価し、それをAIエージェントの性能の定量的指標に変換しています。
用語解説:
- 計算資源: AIモデルの学習に必要なコンピュータの処理能力や時間などの資源です。
- 汎用AI(AGI: Artificial General Intelligence): 人間と同等以上の幅広い知的タスクを実行できるAIの概念です。
2.3 心理測定法と項目反応理論
本研究の方法論は、心理テストの分野、特に項目反応理論(IRT: Item Response Theory) から着想を得ています。IRTは、潜在的な特性(能力など)とテスト項目への観察された反応の関係をモデル化する理論です。従来のIRTでは、項目困難度が、回答者の能力に基づいて正答を予測するロジスティックモデルのパラメータとなります。本研究では、このアプローチを逆転させ、タスク完了時間(困難度の代理変数)を用いてAIの性能を予測します。
本研究の手法は、教育テストにおける困難度推定技術 とも関連しており、ここでは完了時間を含む複数の指標を用いてタスクの困難度を推定します。IRTは、Martínez-Plumedら によって機械学習分類器に応用されており、SongとFlach によって効率的なベンチマーク設計にも用いられています。
用語解説:
- ロジスティック回帰: ある事象の発生確率を予測するための統計的な手法です。
- 潜在的な特性: 直接観察できないが、行動や反応に影響を与えると考えられる個人の能力や性質です。
3. AIエージェントの現実的なタスクにおける性能測定 (Measuring AI agent performance on realistic tasks)
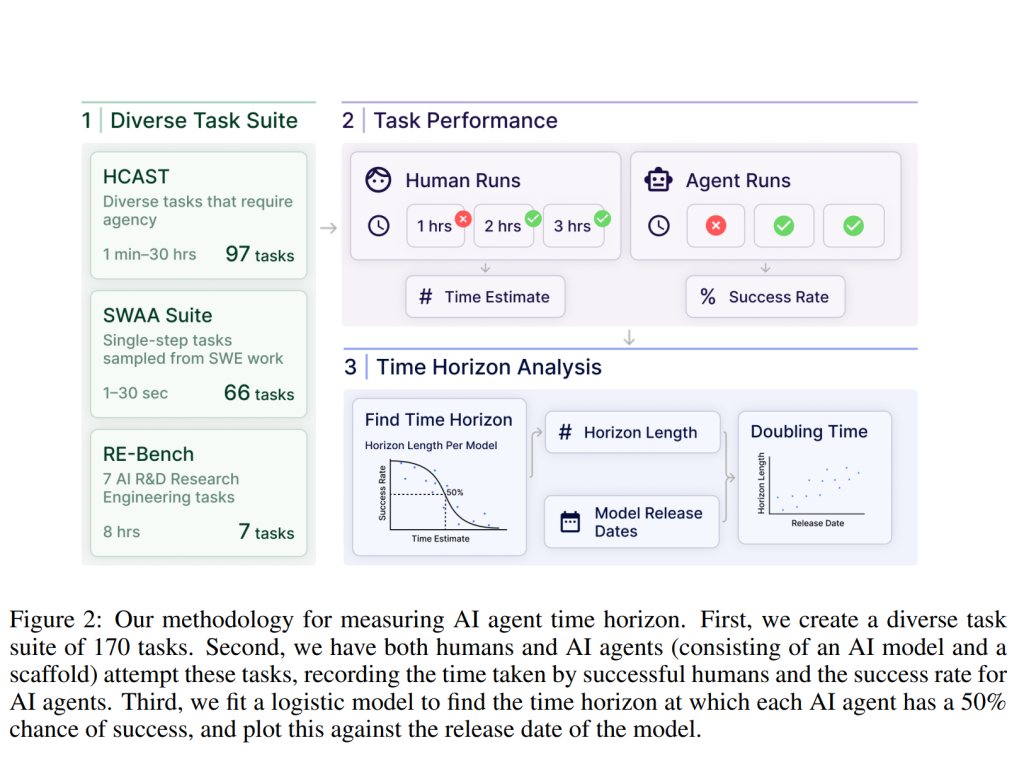
この項では、AIエージェントの性能を評価するために使用されたタスクスイート(データセット)と、評価方法について説明されています。
3.1 タスクスイート / データセット
研究では、以下の3つの異なるタスクスイートが使用されました:
- HCAST のサブセット: 1分から約30時間までの幅広い難易度を持つ、多様な97個のソフトウェアタスク。これには、サイバーセキュリティ、機械学習、ソフトウェアエンジニアリング、一般的な推論などの課題が含まれます。
- RE-Bench: いずれも人間の専門家が約8時間かけて完了することを想定した、困難な7つの機械学習研究エンジニアリングタスク。
- ソフトウェア原子アクション (SWAA): ソフトウェア開発者が行う1分未満の短い単一ステップの作業を表す66個のタスク。これには、複数選択式と穴埋め式の問題が含まれます。
これらのタスクはすべて自動的に採点され、連続値または二値のスコアが得られます。ほとんどのベンチマークと同様に、これらのタスクスイートも、特定の作業単位を分離し、時間制限内で確実に完了できるように設計されています。これは通常、大規模なプロジェクトの途中のタスクよりも、必要な文脈が少ないことを意味します。すべてのタスクは、提供された指示に基づいて人間が少なくとも一度は成功裏に完了できることが確認されています。
HCASTとSWAAのスイートは、類似したタスクのグループである「タスクファミリー」に分けられています。これは、同じファミリー内のタスクの性能が相関しているため、多様性を考慮してタスク数の多いファミリーの重みを下げるためです。
用語解説:
- ソフトウェアエンジニアリング: ソフトウェアの設計、開発、保守を行う分野です。
- 機械学習: AIの一分野で、データから学習して予測や意思決定を行うシステムを開発します。
- サイバーセキュリティ: コンピュータシステムやネットワークを脅威から保護する分野です。
- 推論: 与えられた情報に基づいて結論を導き出す思考プロセスです。
3.2 ベースライン
AIエージェントの性能を評価する基準として、研究者たちは人間の「ベースライナー」(基準となる参加者)にもほとんどのタスクを試してもらい、その試行時間を記録しました。合計で800以上のベースライン、総計2,529時間が記録されました。
ベースライナーは、ソフトウェアエンジニアリング、機械学習、サイバーセキュリティの分野で熟練した専門家であり、大部分が世界のトップ100大学の出身です。平均約5年の関連経験を持ち、ソフトウェアエンジニアリングのベースライナーは、機械学習やサイバーセキュリティのベースライナーよりも経験が豊富でした。
HCASTのベースラインは、関連分野の経験を持つ専門家から既存のデータが使用されました。RE-Benchでは、参加者は各タスクで最高のパフォーマンスを達成するように指示されたため、タスクの所要時間は8時間と固定され、代わりに7〜9時間費やした参加者の平均スコアが成功の閾値として使用されました。SWAAは、外部の契約者ではなく、関連専門知識を持つ研究チームのメンバーによって、より正確な時間を計測できるカスタムウェブアプリを使用してベースラインが作成されました。SWAAタスクは単一ステップであり、文脈の習得を含まないため、タイマーはユーザーが応答を選択するとすぐに終了します。
タスクの所要時間は、成功したベースラインの試行時間の幾何平均を用いて計算されました。成功したベースラインが存在しないタスクについては、手動で見積もられました。
用語解説:
- 幾何平均: 複数の数値を掛け合わせたもののn乗根です。外れ値の影響を受けにくい平均値です。
3.3 AIエージェントのタスクスイートにおける性能評価
研究では、過去に評価したモデルを中心に、13の2019年から2025年までのフロンティアモデルの性能が評価されました。これには、初期のフロンティアモデルであるGPT-3やGPT-2も含まれます。
エージェントの枠組み
ほとんどのAIモデルは、「modular-public」と呼ばれる基本的なエージェントの枠組みで評価されました。この枠組みは、モデルにPythonとBashコマンドの実行環境を提供し、入力がモデルのコンテキストウィンドウの長さを超えないようにするための簡単なコンテキスト管理機能を持っています。一部のモデル(o1-preview、o1)では、ツールの使用や環境からのフィードバックへの対応が苦手なようだったため、わずかに異なる枠組みが使用されました。GPT-2はコンテキスト長が短いため、この枠組みと互換性がなく、RE-BenchとHCASTのすべてのタスクでスコアがゼロと見なされました。
用語解説:
- コンテキストウィンドウ: AIモデルが一度に処理できるテキストの最大量です。
- Python、Bash: プログラミング言語とシェル(コマンドを実行する環境)です。
結果
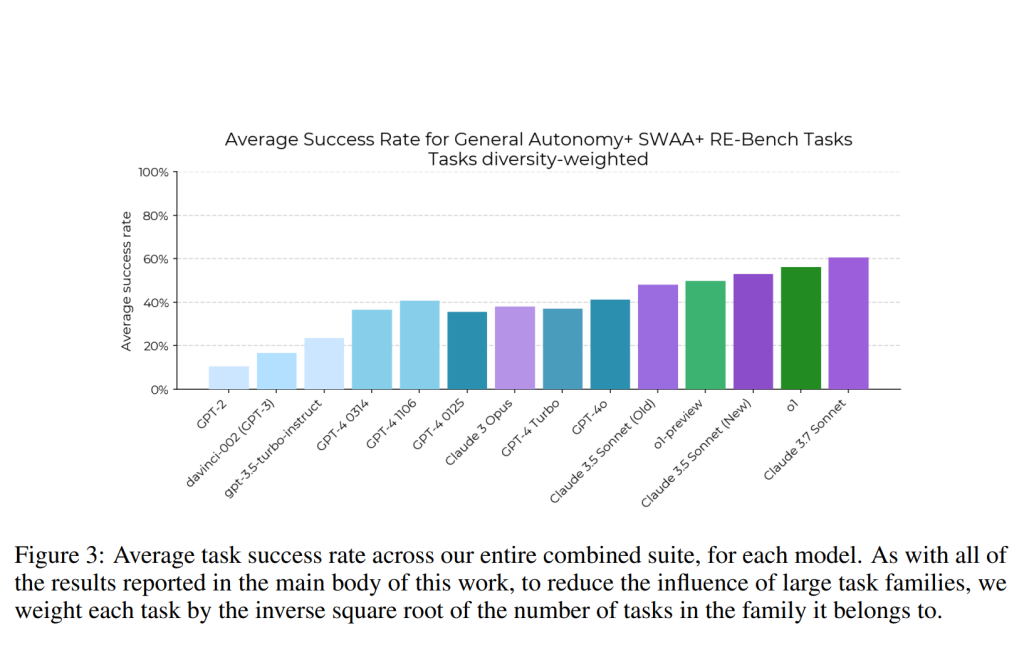
各エージェントとタスクのペアに対して8回の試行が行われ、その平均結果が報告されています。ほとんどのベンチマークと同様に、時間経過とともに強い上昇傾向が見られ、最近のモデルは約50%のタスクを完了していますが、初期のモデルの性能は大幅に劣っていました。また、モデルが完了できるタスクの間には強い相関関係があることも指摘されています。
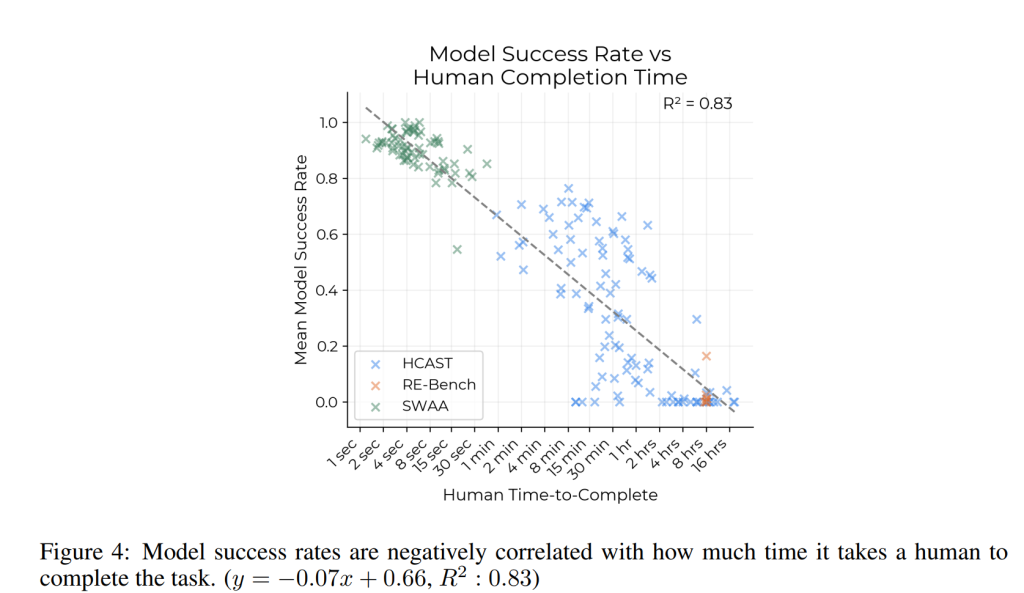
モデルの成功率 vs ベースライン時間
人間のベースライナーがタスクを完了するのにかかる時間と、タスクにおけるすべてのモデルの平均成功率の間には、負の相関関係が見られました。つまり、人間がより多くの時間を要するタスクほど、AIモデルの成功率は低くなる傾向があります。この成功率の低下は、人間の完了時間の対数に対して指数関数的なモデルでよく当てはまります。特に、モデルの成功と人間の完了時間の対数の相関(0.91)は、モデル間の平均相関(0.73)よりも高いことが示されています。
初期のモデル(GPT-2、GPT-3など)は、数語を書くだけで済むタスクは完了できますが、1分を超えるタスクはすべて失敗します。対照的に、最近のフロンティアモデル(Claude 3.5 Sonnet、o1など)は、人間のベースライナーが4時間以上かかるタスクも一部完了できます。
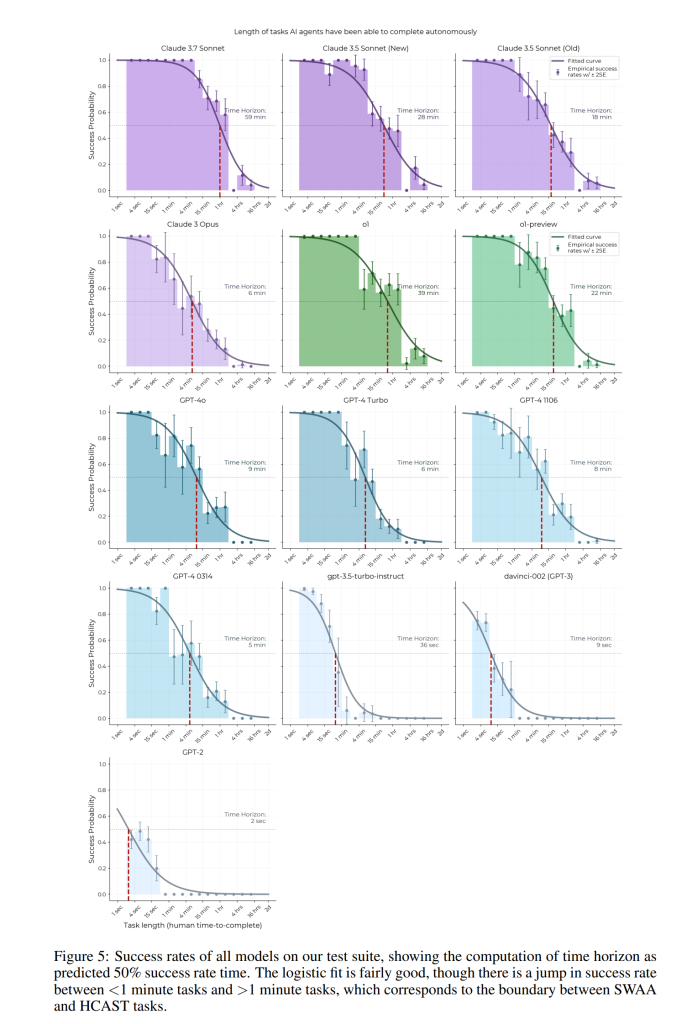
4. 時間ホライズンの算出 (Computing time horizon)
AIの能力の進捗をより直感的な指標で示すために、研究者たちは各モデルのタスクにおける性能を、タスク完了時間ホライズンの推定値に変換しました。
4.1 生データから時間ホライズンへ
まず、各タスクにおけるエージェントの性能が二値(成功または失敗)に変換されます。多くのタスク(SWAAのすべて、HCASTの大部分)は自然に二値ですが、連続値でスコアが付けられるタスクは、タスク固有の閾値に基づいて二値化されます。この閾値は、人間のパフォーマンスを表すように選択されます。
エージェントの成功率と各タスクの所要時間が得られたら、項目反応理論(IRT)に着想を得たアプローチが用いられます。IRTと同様に、ロジスティック回帰を用いて、エージェントが50%の確率で成功するタスクの困難度を特定しますが、IRTとは異なり、人間のベースラインデータを利用して、エージェントの性能から学習された評価ではなく、人間の時間に基づいた困難度評価を使用します。具体的には、以下のロジスティック回帰モデルが使用されます:
$$ \text{psuccess}(\text{model}, \text{task}) = \sigma((\log h_{\text{model}} – \log t_{\text{task}}) \cdot \beta_{\text{model}}) $$
ここで、ttask は成功した人間のベースラインの試行時間の幾何平均、hmodel と βmodel は学習されるパラメータであり、hmodel が50%時間ホライズンを表します。
このモデルを用いて、各エージェントの50%の成功率でタスクを完了できる時間(50%時間ホライズン)が算出されます。
4.2 モデルの時間ホライズン長 vs リリース日
算出された各モデルの時間ホライズンとリリース日をプロットしたものがFigure 1です。さらに、時間ホライズンの対数をリリース日に対して線形回帰することで、時間ホライズンが約212日(約7ヶ月)ごとに倍増していることが示されました。ただし、個々のモデルの時間ホライズンには幅の広い誤差が含まれていますが、これらの誤差はモデル間で強く相関しています。これは、同じ人間の所要時間のタスクでも、モデルにとっては難易度が大きく異なる場合があり、簡単なタスクばかり(または難しいタスクばかり)をサンプリングすると、すべてのモデルの時間ホライズン推定値が高く(または低く)なるためです。したがって、個々のモデルの時間ホライズンよりも、時間ホライズンの傾向の勾配の方が信頼性が高いと言えます。
2024年と2025年初頭の傾向はより速い可能性があり、o1やClaude 3.7 Sonnetといった最新モデルは長期的な傾向線を上回っています。
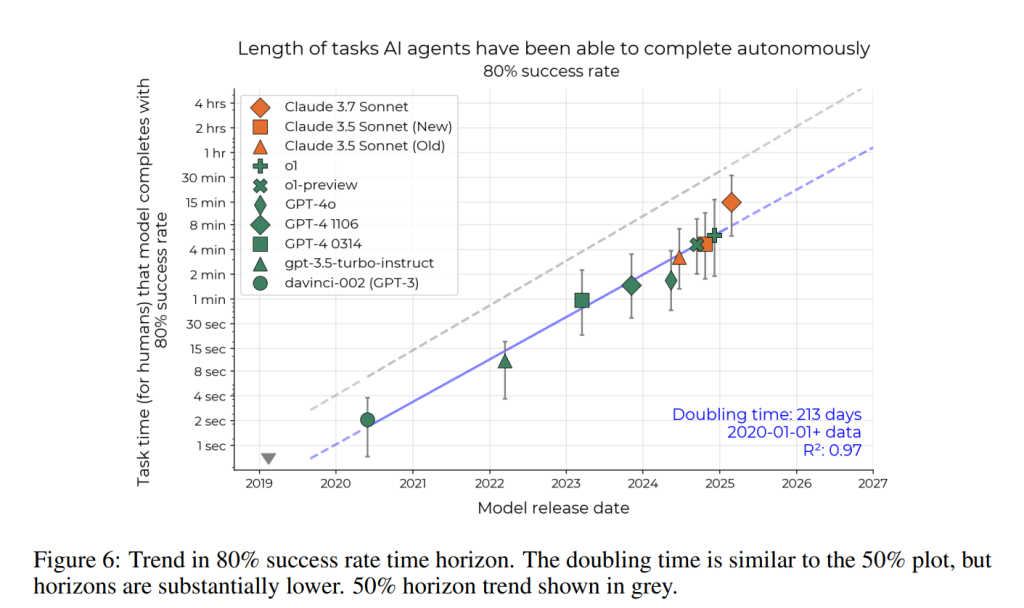
50%成功率と80%成功率の時間ホライズン
50%の成功率という選択が長期的な傾向に影響を与えないかを確認するために、AIエージェントが80%の成功率でタスクを完了する時間ホライズンも計算されました (Figure 6)。80%時間ホライズンの倍増時間(213日)は、50%時間ホライズンの倍増時間(212日)と誤差範囲内で類似しています。しかし、モデルの50%時間ホライズンと80%時間ホライズンの間には大きな差があり、これは、困難で多様なタスクに時々成功するモデルでも、中程度の長さのタスクを安定して実行することはまだ難しいことを示唆しています。
5. 定性的分析 (Qualitative analysis)
モデル性能向上の観察された傾向をより深く理解するために、研究者たちは初期のモデル(GPT-4など)と比較して最近のモデルが大幅に優れているタスクの実行記録を調査しました。具体的には、必要な専門知識の種類に基づいてタスクファミリーを分類し、最近のモデルが機械学習のトレーニング、コンパイルされたソフトウェアバイナリのリバースエンジニアリング、サイバーセキュリティのCTF(Capture The Flag)などのタスクで、以前のモデルよりも優れた性能を発揮する傾向があることに気づきました。また、AIエージェント自身の限界に対する状況認識や、対立する戦略を打ち破る能力も大幅に向上していることが観察されました。
これらの観察に基づいて、5つのタスクファミリーのセットを詳しく調査し、AIエージェントの性能向上と潜在的な限界についての説明を特定しました。その結果、モデルはツール利用能力、間違いに適応する能力(失敗した行動を繰り返すのではなく)、そして論理的推論やコード生成を必要とするタスクの部分において、大幅に改善していることがわかりました。
しかし、AIエージェントは依然として、直感的に「より煩雑な」環境、具体的には明確なフィードバックループがない環境や、エージェントが関連情報を積極的に探し出す必要がある環境では苦労していることも指摘されています。
さらに、最近のモデルと以前のモデルの失敗の違いをより深く理解するために、GPT-4 1106エージェントの31件の失敗した実行と、o1エージェントの32件の失敗した実行を個別にサンプリングし、失敗のカテゴリを人手でラベル付けしました。その結果、GPT-4の失敗の3分の1以上が「失敗した行動の繰り返し」に起因していたのに対し、o1ではわずか2件でした。これは、モデルが間違いに適応する能力が向上しているという主張を裏付ける定量的な証拠と見なされます。興味深いことに、o1の失敗の半分は「早期のタスク放棄」に起因していましたが、GPT-4では4分の1に過ぎませんでした。これは、o1の失敗が質的に難しいタスクで発生しているためか、o1の特異性によるものかもしれません。
用語解説:
- リバースエンジニアリング: ソフトウェアなどの製品を分解し、その構造や原理を解析するプロセスです。
- CTF (Capture The Flag): サイバーセキュリティの知識やスキルを競う競技形式のイベントです。
- 状況認識: 周囲の状況を理解し、それに応じて適切な行動をとる能力です。
6. 外部妥当性と頑健性 (External validity and robustness)
研究結果の他のベンチマークや現実のタスク分布への適用可能性を調査するために、研究者たちは4つの補足的な実験を実施しました。
6.1 2023–2025年のデータからの遡及予測
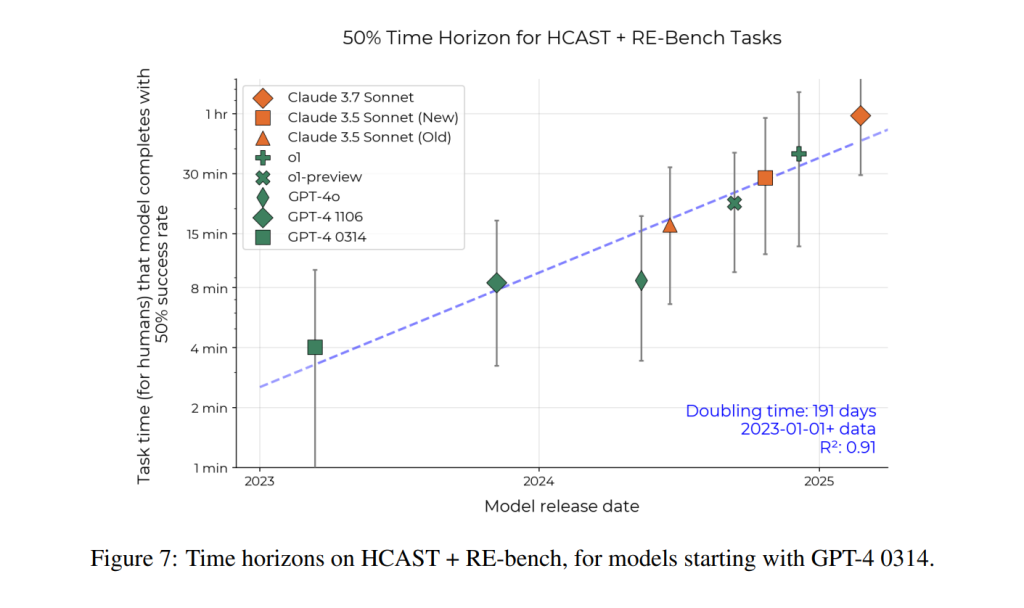
論文の初期の研究として、2023年と2024年にリリースされた9つのフロンティアおよびニアフロンティアモデルの時間ホライズンを、HCASTとRE-Benchスイートのみを用いて測定しました。この傾向(Claude 3.7 Sonnetを追加)はFigure 7に示されており、時間ホライズンは約6ヶ月ごとに倍増しています。しかし、2023年のモデルが2つ(GPT-4 0314とGPT-4 1106)のみであり、データ範囲が狭いため、誤差幅は非常に大きくなりました。さらに、2024年のモデルのみに限定すると、約3ヶ月ごとに時間ホライズンが倍増するという異なる傾向が見られたため、将来への外挿は頑健ではありませんでした。
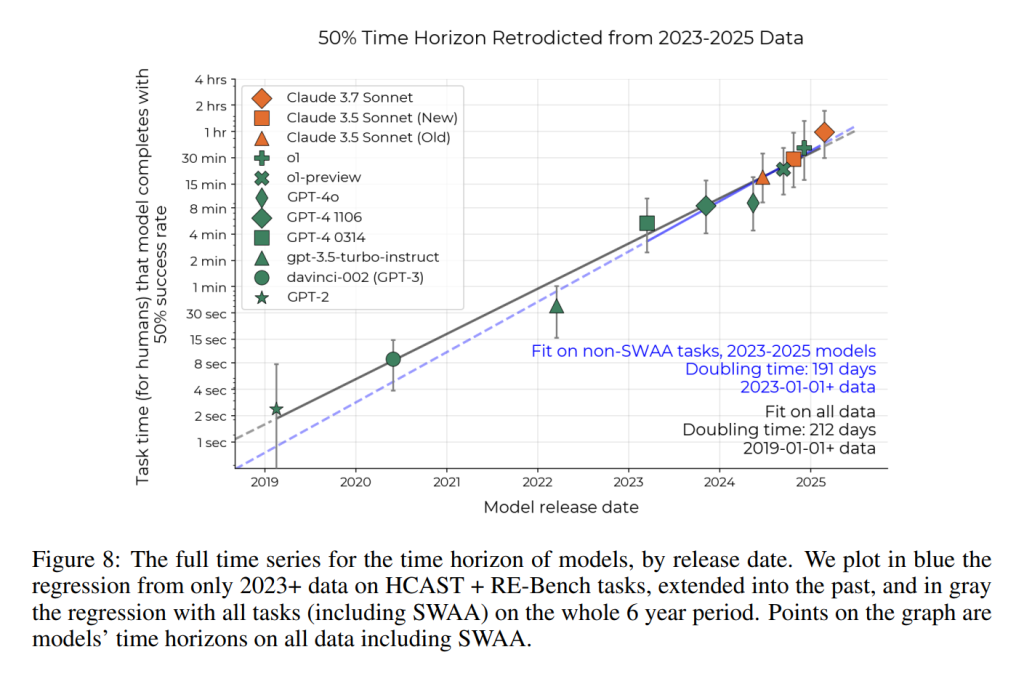
これらの問題に対処するために、研究者たちはより多くのデータを収集し、傾向線を過去に拡張しました。SWAAスイートを開発することで、タスクスイートの最小人間の所要時間を1分から2秒未満に減らし、GPT-2、davinci-002(GPT-3)、GPT-3.5-turbo-instructを組み合わせたスイートで測定できるようになりました。
2023–2025年の傾向は、より長期的な傾向をよく遡及的に予測しています (Figure 8)。2019年から2025年までの6年間の測定された倍増時間は212日であり、SWAA以外のタスクと2023–2025年のモデルのデータに基づいた191日の傾向とよく一致しました。
6.2 煩雑さの要因 (Messiness factors)
現実世界の知的労働には、ベンチマークには通常含まれない、不明確さや範囲の曖昧さ、不明確なフィードバックループや成功基準、リアルタイムでの複数の作業の流れ間の調整など、煩雑な詳細が含まれていることがよくあります。研究者たちは、エージェントがこれらの「煩雑な」詳細を含むタスクではより苦労することを観察しました。そこで、エージェントが「あまり煩雑でない」タスクと「より煩雑な」タスクで同様の改善率を示したかどうかという疑問が生じます。
HCASTとRE-Benchのタスクは、現実世界のタスクが本研究のタスクと体系的に異なる可能性があり、AIエージェントの性能に関連すると考えられる16の特性について評価されました。これらの要因には、タスクが新しい状況を含むか、有限のリソースによって制約されているか、リアルタイムでの連携が必要か、現実世界のコンテキストから得られたかなどが含まれます。RE-BenchとHCASTのタスクは、これらの16の煩雑さの要因の有無に基づいてラベル付けされ、それらの合計が0から16の範囲の「煩雑さスコア」として算出されました。
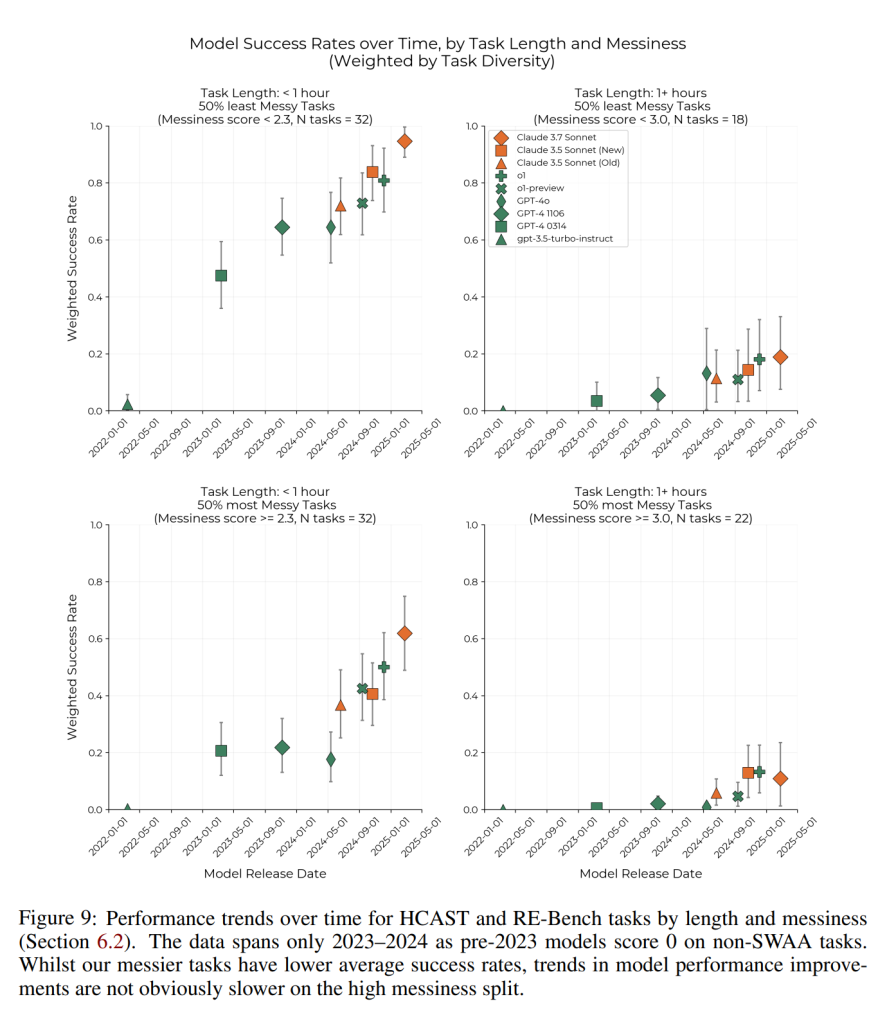
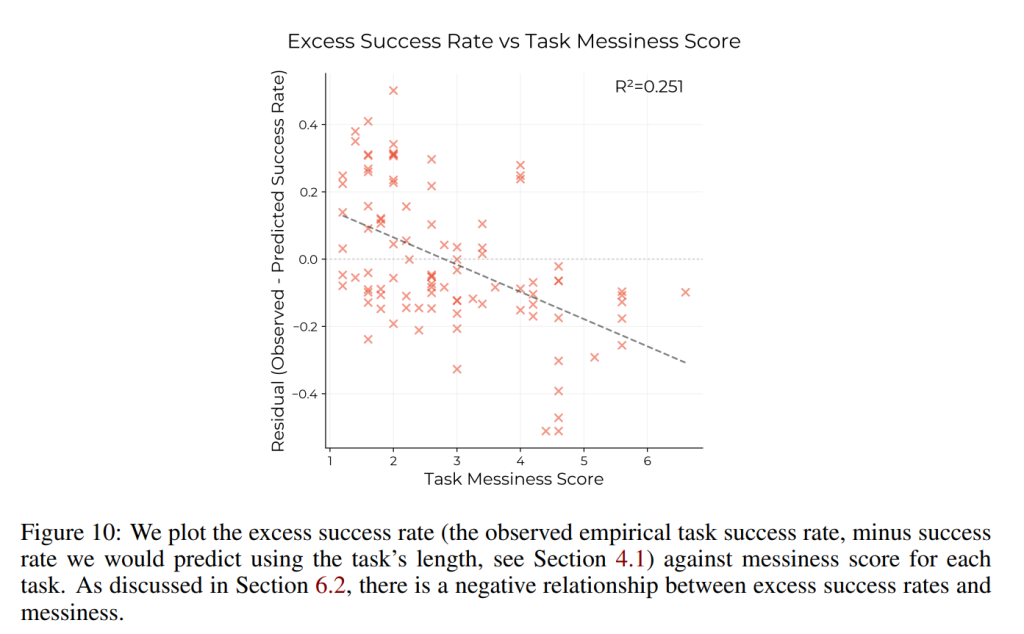
HCASTのタスクにおいて、AIエージェントは、タスクの長さから予測されるよりも、煩雑さの高いタスクでは低い性能を示すことがわかりました (Figure 10)。タスクの煩雑さスコアが1ポイント増加すると、平均成功率が約8.1%低下します。
しかし、AIエージェントの性能の時間的傾向は、タスクの煩雑さの低いサブセットと高いサブセットで類似しています。例えば、1時間以内のタスクでは、成功率は2023年1月から2025年5月の間に、煩雑さの高いグループと低いグループの両方で40パーセントポイント増加しました (Figure 9)。特に、煩雑さの高いサブセットに特有の性能傾向の著しい低下や停滞は見られませんでした。
用語解説:
- リアルタイム連携: 他のエージェントやサービスと同時に情報をやり取りし、協力して作業を進めることです。
6.3 SWE-bench Verified
他のベンチマークでも同様の性能傾向が見られるかを確認するために、研究者たちはSWE-bench Verifiedに本研究の方法論を適用しました。SWE-bench Verifiedは、ソフトウェアエンジニアリングタスクにおける言語モデルの性能を評価するための業界標準ベンチマークです。このデータセットのすべてのタスクは、matplotlibやdjangoなどの大規模なオープンソースリポジトリから収集され、自動的にチェック可能で、明確に定義されていることを保証するためにフィルタリングされています。
SWE-bench Verifiedタスクから計算されたモデルの時間ホライズンは、2023年後半から2024年にかけて指数関数的な傾向を示しているようです。しかし、2024年のモデルを使用したHCAST + SWAA + RE-benchによって予測される倍増時間が104日であるのに対し、SWE-bench Verifiedの結果によって予測される倍増時間はより短い約70日でした。
研究者たちは、注釈者の時間見積もりは、コントラクターベースライナーが最も簡単なSWE-bench Verifiedタスクを完了するのにかかる時間を過小評価している可能性が高いことを発見しました。その結果、SWE-bench Verifiedの時間ホライズン推定値(注釈者の時間を使用)は、能力の低いモデルの時間ホライズンを過小評価している可能性が高く、ひいては倍増時間を短縮していると考えられます。
用語解説:
- オープンソースリポジトリ: ソフトウェアのソースコードが公開され、誰でもアクセス、利用、修正できる場所です。GitHubなどが代表的です。
6.4 内部PR実験
研究者たちは、社内のMETRリポジトリの汚染されていない5つの課題について、GPT-4o、Claude 3.5 Sonnet (New)、およびo1を実行しました。これらの課題の解決は、METRのスタッフによって実際に行われた作業であるため、これらのタスクの結果は、典型的なベンチマークタスクよりも、実際の経済的に価値のあるタスクのパフォーマンスをよりよく表していると期待されます。
その結果、契約ベースライナーは、リポジトリのメンテナーよりも5倍から18倍長く課題の解決に時間がかかることがわかりました。さらに、契約ベースライナーの完了時間を使用してタスクの長さを測定した場合、これらの課題におけるAIエージェントのパフォーマンスは、HCAST、SWAA、およびRE-Benchのパフォーマンスから導き出されたAIエージェントの成功率曲線と矛盾しませんでした (Figure 5)。しかし、契約ベースライナーがこれらのタスクを完了するのにかかる時間は、リポジトリのメンテナーよりもはるかに長いです。これは、時間ホライズンは、高コンテキストを持つ人間よりも、低コンテキストを持つ人間の労働によりよく対応する可能性があることを示唆しています。
前提条件:
- PR (Pull Request): ソフトウェア開発のプロセスにおいて、コードの変更を提案し、レビューを受けるための仕組みです。
- リポジトリメンテナー: 特定のソフトウェアプロジェクトのコードベースを管理し、変更を受け入れる責任を持つ人です。
- コンテキスト: タスクを完了するために必要な背景知識や情報です。
7. 予測 (Extrapolation)
この項では、これまでの分析結果に基づいて、将来のAI能力を予測する試みが述べられています。
7.1 1ヶ月ホライズンAIへの外挿
AIシステムが自律的に大きな経済的価値を生み出せるようになる時期や、壊滅的な行動をとれるようになる時期を予測するには、ホライズン長の具体的な閾値を選択する必要があります。研究者たちは、その閾値として1ヶ月(人間のフルタイム労働時間を167時間と想定)を選択しました。これには2つの理由があります。第一に、Ngo は、1ヶ月AGI(1ヶ月の労働時間を与えられた最も知識のある人間よりもほとんどのタスクで優れた性能を発揮するAI)は、大規模なソフトウェアアプリケーションの作成やスタートアップの設立(明らかに経済的価値がある)を含むタスクと、新しい科学的発見を含むタスクの両方で、必然的に人間の性能を上回ると述べています。第二に、1ヶ月は、企業への新入社員がオンボーディングを完了し、経済的価値を生み出し始める頃であり、1ヶ月のホライズンを持つAIは、人間の従業員のように文脈を習得し、低コンテキストのタスクだけでなく高コンテキストのタスクも完了できるようになる可能性があるためです。
この研究では、AIが50%の時間ホライズンで1ヶ月に到達する時期を予測しようとしています。これは、この長さのタスクを50%の信頼性で実行できるシステムであっても、社会に大きな変革をもたらし、壊滅的な害を社会に及ぼす可能性のある能力に熟達する可能性があると考えられるためです。
感度分析の結果、過去の倍増率(約8ヶ月に1回)が大きく低下する可能性は低いと分析されており、1ヶ月AIの到来時期の不確実性は比較的小さい(80%信頼区間は約2年、中央推定値は2029年後半)とされています。タスク分布と試行回数のばらつきが不確実性の主な要因です。もし将来の進歩が2024–2025年の傾向に従うならば、1ヶ月AIはより早く、2027年後半から2028年初頭に半分の確率で到来する可能性があります。
ただし、系統的なバイアスや異なる方法論が予測に大きな影響を与える可能性もあり、現実の予測には、この単純な外挿よりも大きな誤差が含まれることになるでしょう。
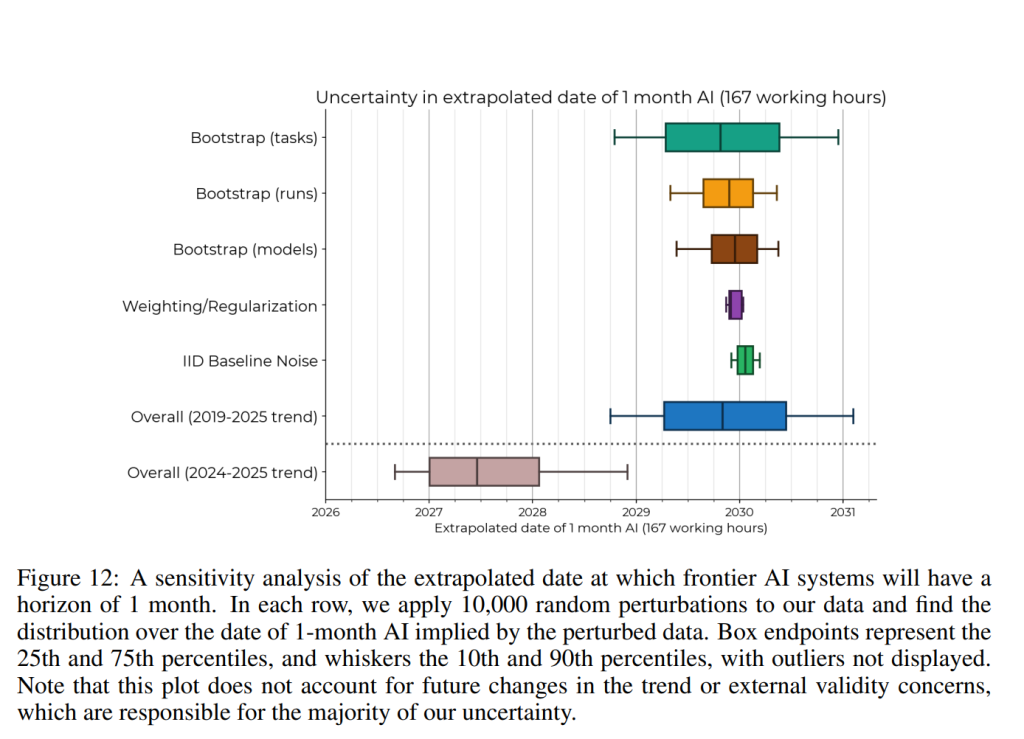
7.2 外挿の困難性
将来の予測における不確実性の大部分は、(a)現実のタスクへの適用可能性(セクション6で一部議論)と、(b)時間ホライズンの成長率の将来的な変化に起因します。
本研究のタスクと現実のタスクの系統的な違い
本研究で使用されたAI能力を評価するためのタスクは、現実のタスクとは系統的に異なります。これらの違いにより、本研究のタスクで観察された傾向が現実世界のタスクに一般化されない可能性があります。例えば、SWAA、HCAST、RE-Benchのすべてのタスクは、以下の点で現実世界のタスクと異なります:
- 自動採点: すべてのタスクは自動的に採点可能であり、ソリューションの形式に制約が生じ、タスクのオープンエンド性が低下する傾向があります。
- 他のエージェントとのインタラクションなし: どのタスクも他の自律的なエージェントとのインタラクションを含みません。他のエージェントとの連携や競争は、タスクの難易度を高める可能性があります。
- 緩やかなリソース制約: SWAAタスクにはリソース制限のあるものはなく、HCASTタスクにもほとんどありません。現実世界のタスクでは一般的な制約です.
- 寛容な誤り: 誤りに対するペナルティが非常に少ないタスクが多いです。現実世界のタスクはより厳しい場合があります。
- 静的な環境: タスク環境はエージェントが直接操作しない限り大きく変化しません。現実のタスクは変化する環境で行われることが多いです.
セクション6.2では、これらの系統的な違いがAIエージェントの性能にどのように影響するかを、「煩雑さ」の要因として測定しようと試みました。その結果、「より煩雑な」タスクでは絶対的な性能は低いものの、性能の傾向はあまり煩雑でないタスクと類似していることがわかりました。しかし、これらの系統的な違いは、本研究のタスク(およびSWE-Bench Verifiedのような他のベンチマーク)で見られた急速な性能向上が現実世界のタスクに一般化されるかどうかについて疑問を投げかけます。
この傾向が現実世界のタスクに一般化されるかどうかにかかわらず、本研究の結果は重要であると研究者たちは考えています。もし結果が一般化されないのであれば、HCASTやSWE-Bench Verifiedのようなベンチマークは、現実のタスクにおけるAI能力を予測するには不十分であり、より現実的なベンチマークが必要となるかもしれません。一方、もし結果が一般化されるのであれば、本研究の傾向を外挿すると、人間のソフトウェア開発1ヶ月分の作業を自動化できるAIが2032年より前に実現すると予測されます。
時間ホライズンの傾向の将来的な変化
ここでは、時間ホライズンの成長率を大きく変化させる可能性のある3つの追加要因について議論されています: エージェンシー学習、計算量のスケーリング、AI研究開発の自動化。
- エージェンシー学習: 2024年以降のホライズン成長は、長期的な傾向よりも速い可能性があり、これは、成果ベースの強化学習を用いて、モデルがよりエージェンシー(タスク完了に向けて多くの連続した行動をとる能力)を持つように事後学習されていることによって説明されるかもしれません。モデルを能力が高くエージェンシーを持つようにする研究は継続される可能性が高いです。将来のエージェンシー学習は、長期的な傾向よりも速い可能性があります(事後学習は、ホライズン長を長くするにつれて事前学習よりも計算効率が高い可能性があるため)。しかし、2024–2025年のエージェンシー学習は、手軽な成果を得るための一時的な後押しである可能性もあり、その場合、これらの成果が尽きればホライズンの成長は鈍化するでしょう。全体として、研究者たちは、エージェンシー学習が2019–2024年の傾向と比較して時間ホライズンの成長率を高める可能性が高いと考えています.
- 計算量のスケーリング: GPT-2のリリースから現在までに、最も印象的なフロンティア言語モデルのトレーニングに使用される計算量は少なくとも10,000倍に増加しており、トレーニング計算量の使用量は6〜10ヶ月ごとに倍増しています。より最近では、o1やo3などのモデルが推論時により多くの計算量を使用し始めています。今後5年間でトレーニングまたは推論の計算量をさらに数桁増やす十分な能力があるかどうかは不明です。ただし、歴史的に固定された性能レベルに必要な計算量を減少させてきたアルゴリズムの改善 は、計算量の制限を補うことができます。研究者たちは、計算量のスケーリングの限界がAIエージェントの時間ホライズンの成長をいくらか鈍化させるだろうと考えていますが、アルゴリズムの改善へのより多くの投資によって部分的に相殺されるだろうと予測しています.
- AI R&Dの自動化: AIの研究開発の主なインプットは、計算量と研究者の時間です。もし将来のAIシステムが人間の研究エンジニアの代わりになったり、トレーニングの計算効率を高めたりできるならば、AIの進歩率は増加するでしょう。フロンティアAIの時間ホライズンが数十時間に達すると、AI R&Dの自動化が大幅に進み、そこから1ヶ月ホライズンAIまでの時間が短縮される可能性が高いと研究者たちは考えています。
8. 考察 (Discussion)
この項では、研究全体を通して得られた結果について、より深く考察しています。
8.1 時間ホライズンの測定と解釈
時間ホライズンはAIエージェントの能力を測る直感的な指標ですが、その測定には人間の時間に関する注釈付きの大規模なデータセットが必要であり、時間ホライズンは常にタスクの分布とベースライナーのコンテキストレベルおよびスキルレベルに相対的に測定されます。
現実の企業では、新卒のソフトウェアエンジニアが経済的価値を生み出し始めるまでに数週間のオンボーディングを要することがよくあります。本研究でタスクの長さを決定する人間のベースライナーは、平均的な従業員よりもコンテキストがはるかに少ないため、測定されたタスクの長さが長くなる可能性があります。本研究のタスクは、必要なコンテキストを最小限に抑えるように設計されていますが、内部PR(セクション6.4)はそうではありませんでした。そのため、ベースライナーは従業員の何倍も時間がかかりました。しかし、高度なスキルを持つベースライナーは、平均的な従業員よりもはるかに速くタスクを完了することもできます。本研究の専門家ベースライナーは、平均的なソフトウェアエンジニアよりもはるかにスキルが高い可能性があり、測定されたタスクの長さが短くなる可能性があります。
Figure 4は、AIエージェントの成功率が人間の完了時間によって完全に予測されるわけではないことを示しており、他の要因もタスクの難易度に大きく影響していることを意味します。研究数学、計算生物学、法律など、知的労働の異なる領域でモデルを測定すると、それらの時間ホライズンは異なると予想されます。
AIエージェントのX%時間ホライズンが約t分であることを正確に測定するには、人間の長さがt分で、AIエージェントが約X%の成功率で完了する多くのタスクが必要です。これには2つの意味合いがあります。第一に、非常に長い時間ホライズンを正確に測定するには、人間のベースライン実行時間が長い困難なタスクのデータセットが必要であり、特に現実的な困難なタスクの成功基準は複雑で手動採点が必要な場合が多いため、構築が非現実的な場合があります。第二に、非常に高い成功レベル(95%、98%以上)で時間ホライズンを測定するには、それらが代表するタスクの母集団をカバーする、ラベルノイズがほぼゼロの大規模なタスクデータセットが必要です。
無限の時間ホライズンは、任意の能力を持つAIを意味するのではなく、人間が任意の長さの時間を要するタスクを完了できる能力を意味するに過ぎません。もし汎用人工知能(AGI)が、専門家である人間が成功率X%以上で完了できるすべてのタスクを完了できるならば、そのX%時間ホライズンは必然的に無限大になります。したがって、そのようなシステムが開発されれば、時間ホライズンの長期的な傾向は指数関数よりも速く、AGIの展開日に漸近線を持つことになります。
理論的には、人間または人間の集団の時間ホライズンを測定することも可能ですが、理論的および実際的な困難が存在します。
8.2 限界と今後の課題 (Limitations and future work)
研究者たちは、本研究を改善できる点がいくつかあると考えています。
より多くのモデルとより良いエージェンシーの引き出し: 一般的に、モデルの能力を最大限に引き出すためには、適切なエージェンシーの引き出しが非常に重要であることがわかっています。本研究では、モデルの能力を引き出すために限られた労力しか費やしていないため、結果はある程度の低めの見積もりである可能性があります。今後の研究では、フロンティアモデルの全能力を引き出すためにより多くの努力を払い、本研究の結果を再現する可能性があります。
より厳密な人間ベースライン: タスクごとの人間の時間推定値は、サンプルサイズが比較的小さいためノイズが多く、系統的に偏っている可能性もあります。特に、成功した完了のみを選択し、合理的な時間内に完了できない可能性のあるタスクは諦めるようにベースライナーを促しています。ベースライナーのスキルも大きく異なり、タスクに関連するスキルの種類も多岐にわたります。今後の研究では、より厳密な人間ベースライナーの選択や、人間のベースライン作成に関する方法論の選択に対する結果の感度を調査することで、本研究の結果を再現する可能性があります。
より自然で多様なタスク: 本研究のタスク分布が、経済的に価値のある仕事の分布(およびリスクモデルに関連するタスクの分布)と系統的に異なる可能性があると考える理由があります。セクション6でいくつかの理由を探りましたが、まだ探求していない多くの違いが残っています。例えば、タスクにおけるインタラクションのモダリティも比較的狭く、マウスの使用を必要とするタスクはありません。現実のソフトウェアエンジニアリングやML研究には、マネージャーや他のエンジニア/研究者とのコミュニケーションと調整が含まれますが、本研究のタスクには人間や他のエージェントとの協力や競争を必要とするものはありません。多くの現実世界のタスクは非常に高い信頼性を必要としますが、これらのタスクでモデルを測定することの難しさから、本研究のデータセットでは過小評価されています。最も重要なこととして、本研究で調査するタスクは、ソフトウェアエンジニアリングとML研究に大きく偏っています。今後の研究では、他の分野におけるAIエージェントの能力の進展を探求する可能性があります。
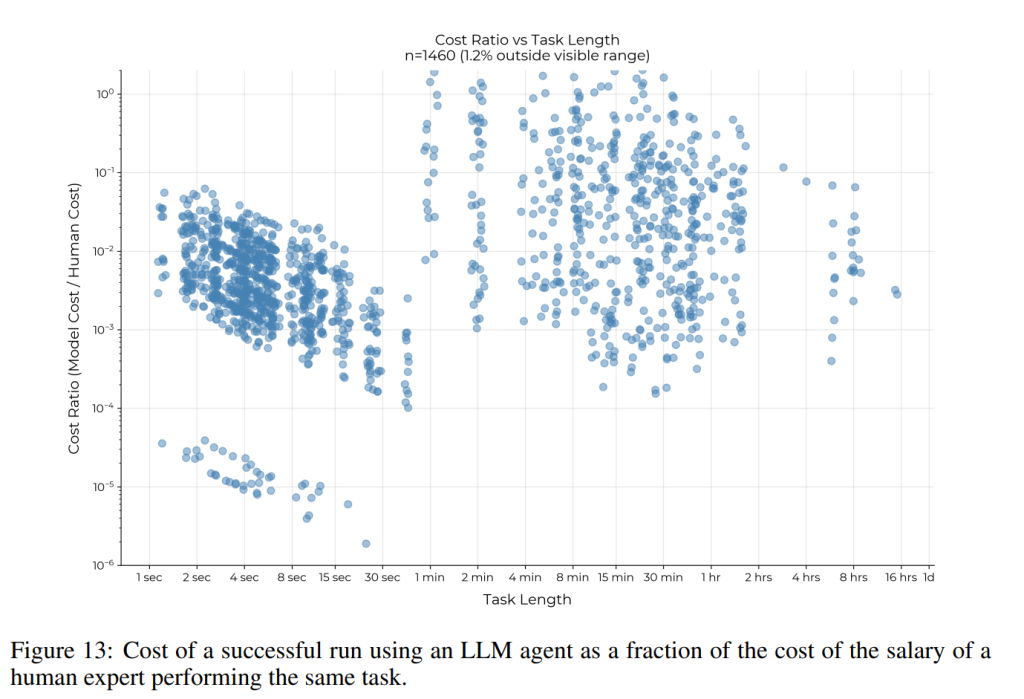
推論計算のより多くの利用: 本研究の枠組みでは、推論時の計算量は比較的限られた使用でした。人間の専門家の報酬を時給143.61ドル(Googleの平均L4エンジニアの給与を2,000時間で割った値)と仮定すると、80%以上の成功した実行は、人間が同じタスクを実行するコストの10%未満でした (Figure 13)。これは、推論時の計算を使用してパフォーマンスを向上させることができる場合、人間の専門家と経済的に競争力を維持しながら、そうするための大きな余地があることを意味します。過去の研究では、best-of-kのような手法がこれらのタスクのサブセットでパフォーマンスを大幅に向上させることがわかっており、推論時の計算のより良い使用は、大幅に異なるスコアにつながる可能性があります。
8.3 まとめ
本研究では、AI能力の直感的で定量的な指標であるタスク完了時間ホライズンを提案しました。これは、タスクにおけるAIの性能を、人間の専門家がタスクを完了するのに通常必要な時間に関連付けるものです。66個の短いSWAAタスクのデータセットを作成し、RE-BenchおよびHCASTのタスクと組み合わせ、SWAAタスクで236回の人間による実行を行い、タスクの難易度を推定しました。これらの難易度推定値を、RE-BenchおよびHCASTから収集されたベースラインと組み合わせました。時間ホライズンの傾向を測定するために、2019年から2025年の間にリリースされた11のフロンティアAIモデルをデータセットでベンチマークし、各モデルの時間ホライズンを計算し (セクション4)、これをリリース日に対してプロットしました。
その結果、本研究のタスクにおける50%タスク完了時間ホライズンは、2019年から2025年にかけて約7ヶ月の倍増時間で指数関数的に成長していることが観察されました (Figure 1)。これは、SWAAデータを除く2023年以降の傾向に関する探索的研究の結果と類似しています (セクション6.1)。80%時間ホライズンを測定したところ、同様の指数関数的な傾向が見られましたが、これらのホライズンは50%ホライズンよりも約5倍短いものでした (セクション4.2.1)。定性的分析 (セクション5) では、この進歩を推進するいくつかの要因が特定されました。また、現在のシステムの重要な制限、特に構造化されていない「煩雑な」タスクにおける性能の低さも指摘されました (セクション6.2)。
観察された傾向の外部妥当性の程度を調査するために (セクション6)、SWE-bench Verified (セクション6.3) で本研究の手法を再現し、タスクの「煩雑さ」がモデルの性能に与える影響を分析しました (セクション6.2)。SWE-Benchと、煩雑さの低いグループと高いグループに分類された本研究のタスクのサブセットの両方で、同様の指数関数的に増加する時間ホライズンが観察されました。しかし、これらのベンチマークと現実世界のタスクとの系統的な違いにより、これらの結果は実際の現実世界のタスクに一般化されない可能性があります。
最後に、本研究のタスクにおける傾向を1ヶ月 (167時間) AI まで外挿しようと試みました (セクション7.1)。その結果、傾向が継続し、観察された性能傾向が現実世界のタスクに一般化されるならば、1ヶ月の長さのソフトウェアタスクを完了できるAIのリリース日の80%信頼区間は、2028年後半から2031年初頭に及ぶことがわかりました (セクション7.2)。