
はじめに
大規模言語モデル(LLM)は、文章生成や対話など、様々なタスクで驚くべき能力を発揮しています。しかし、その強力な能力は、インターネット上の膨大なテキストデータや書籍データなどを学習することによって成り立っています。この学習に使われるデータは、公開されているものから著作権で保護された非公開のものまで多岐にわたりますが、その具体的なソースや利用許諾の状況については、AI企業からほとんど開示されていません。
こうした状況は、AIモデルが著作権を侵害しているのではないかという懸念を生んでおり、すでにいくつかの訴訟も起きています。もしAI開発のための訓練データ利用が著作権の対象外とされると、コンテンツを作成する人々が経済的に立ち行かなくなり、インターネット上の高品質なコンテンツが枯渇する恐れがあります。これは、結局はAI自身の性能向上にも悪影響を及ぼしかねません。
今回ご紹介するSSRCのワーキングペーパーは、この重要な問題に一石を投じるものです。特に、OpenAIが開発したGPTシリーズのモデルが、著作権で保護された非公開の書籍コンテンツを訓練に利用したかどうかを、具体的なデータと手法を用いて調査しています。
引用元記事
- タイトル: Beyond Public Access in LLM Pre-Training Data
- 発行元: Social Science Research Council
- 発行日: 2025年4月
- URL: https://ssrc-static.s3.us-east-1.amazonaws.com/OpenAI-Training-Violations-OReillyBooks_Sruly-OReilly-Strauss_SSRC_04012025.pdf?utm_campaign=The%20Batch&utm_source=hs_email&utm_medium=email&_hsenc=p2ANqtz-9f91ZK_N_NmLMp6AX94ZoLdUVc_XficAkAPC9Kou3250osRmbIYRHjy_zrS2Kxg7NGmN-f
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。

論文の要点
- 本研究は、法的に入手した34冊のO’Reilly Mediaの著作権付き書籍データ(これには公開されている部分と非公開の部分があります)を用いて、OpenAIのモデルが非公開コンテンツを訓練に利用したかどうかを調査しました。
- メンバーシップ推論攻撃(あるデータがモデルの訓練に使われたかどうかを推測する技術)であるDE-COP法と、モデルの識別能力を示すAUROCスコアという指標を用いて分析を行いました。AUROCスコアは0.5がランダムな識別能力、1.0が完璧な識別能力を示します。
- より新しく、より能力の高いモデルであるGPT-4oは、非公開のO’Reilly書籍コンテンツに対して高い認識(AUROC 82%)を示しました。これは、訓練データに非公開コンテンツが含まれていた可能性が高いことを示唆しています。
- それに対し、約2年前に訓練されたGPT-3.5 Turboは、非公開コンテンツに対する認識が低い(AUROC 50%強)結果となりました。
- GPT-4oは、公開コンテンツ(AUROC 64%)よりも非公開コンテンツ(AUROC 82%)に対して強い認識を示しました。公開データはアクセスが容易でインターネット上に広く存在するため、本来であれば逆の結果が期待されます。これは、高品質な非公開データがモデル訓練にとって価値があることを示唆しています。
- 初期のモデルであるGPT-3.5 Turboは、非公開コンテンツ(AUROC 54%)よりも公開コンテンツ(AUROC 64%)に対する認識が相対的に高い結果でした。これは、初期のモデルがより公開データを選択的に利用していた可能性を示唆します。
- ただし、小規模なモデル(パラメータ数が少ないモデル)であるGPT-4o Miniは、公開・非公開データともに認識が低い(AUROC 50%台)結果となりました。これは、モデルのサイズが小さいとテキストを記憶しにくいため、このようなメンバーシップ推論攻撃による検出が難しくなる可能性を示唆しています。
- これらの結果は、AI企業が訓練データの情報開示を強化し、コンテンツ所有者との間で正式なライセンス契約を結ぶ枠組みを開発する必要性を強調しています。
詳細解説
論文の構成に沿って、研究内容を詳しく解説します。
1 Introduction: Identifying access violations
(イントロダクション:アクセスの侵害を特定する)
まず、LLMの「プレトレーニング」には、膨大な量のデータが必要であることが述べられています。これには公開されているデータだけでなく、本来はアクセスが制限されている非公開のデータも含まれます。しかし、AIモデルを開発する企業は、訓練に使われたデータの詳細についてほとんど情報を開示していません。
この情報不足は、AI企業が著作権で保護されたコンテンツを許可なく使用しているという懸念につながっています。実際に、いくつかの有名なAI企業が、著作権侵害の疑いで法的手続きの対象となっています。これに対し、一部のAI企業は、モデルのプレトレーニングを著作権の義務から免除するよう求めています。
もしこのような免除が認められると、コンテンツを作成する人々が作品から十分な収入を得られなくなり、創造活動を維持できなくなる可能性があります。これは、インターネットのトラフィックを収益源とするビジネスモデルにも深刻な影響を与え、結果としてインターネット上のコンテンツの質と多様性が低下する「コモンズの悲劇」(共有資源が無計画に使用され、結果として枯渇してしまう状況を指します)のような状況を招く恐れがあります。
このような背景を踏まえ、本論文はOpenAIのGPTシリーズのモデルが、非公開の著作権付きO’Reilly Media書籍で訓練されたかどうかを検証することを目的としています。O’Reilly Mediaの書籍は、無料でアクセスできるプレビュー部分と、有料でアクセスが制限されている非公開部分の両方を含んでいるため、AIモデルが公開データだけではなく、非公開データにもアクセスしたかどうかを区別するのに適しています。
研究では、DE-COPというメンバーシップ推論攻撃の手法を用いることで、モデルが特定のテキストを訓練で既知のものとして認識しているかどうかを推測します。この手法は、モデルにオリジナルの人間のテキストと機械生成されたパラフレーズの選択肢を与え、どれがオリジナルかを識別できる能力をテストします。モデルの訓練が完了したカットオフ日(モデルがそれ以降のデータで訓練されていないとされる日付)よりも前に出版された書籍は訓練データに含まれている可能性のある「インデータ」として扱い、カットオフ日以降に出版された書籍は訓練データに含まれていない「アウトオブデータ」として扱います。これにより、訓練で使われた可能性のあるテキストとそうでないテキストに対するモデルの認識能力を比較することができます。
本研究では、GPT-3.5 Turbo、GPT-4o Mini、GPT-4oという3つのOpenAIモデルを対象に、合計13,962のパラグラフ(段落)を用いてこの検証を行いました。
2 Data and Methods
(データと手法)
本研究では、34冊の著作権付きO’Reilly Media書籍を、法的な手続きを経て入手しました。これらの書籍から合計13,962のパラグラフを抽出し、分析に用いました。
O’Reilly Media書籍のデータセットは、同じ書籍内に公開されている部分と非公開(実質的にペイウォールの裏にある)部分が含まれているというユニークな特徴を持っています。これにより、モデルが単に公開データで訓練されたのか、それともアクセスの制限を回避して非公開データまで利用したのかを区別して検証できます。本研究では、各章の最初の1,500文字や第1章・第4章全体を公開テキストと定義し、それ以外の部分を非公開テキストと定義しました。
メンバーシップ推論攻撃の精度を測定するためには、理想的には、モデルの訓練データに「含まれていることが既知」のデータと、「含まれていないことが既知」のデータの2つのカテゴリーに分ける必要があります。本研究では、これを近似するために、モデルの訓練カットオフ日(GPT-4oとGPT-4o Miniは2023年10月、GPT-3.5 Turboは2021年9月)より前に出版された書籍を「訓練データに含まれている可能性のある」(t-n)サンプル、カットオフ日より後に出版された書籍を「訓練データに含まれていないことが既知の」(t+n)サンプルと定義しました。Figure 1がこのデータの区分けを示しています。そして、「アクセスの侵害」とは、訓練期間中に公開された非公開の書籍パラグラフのうち、訓練に使用されたと特定されたものを指します。
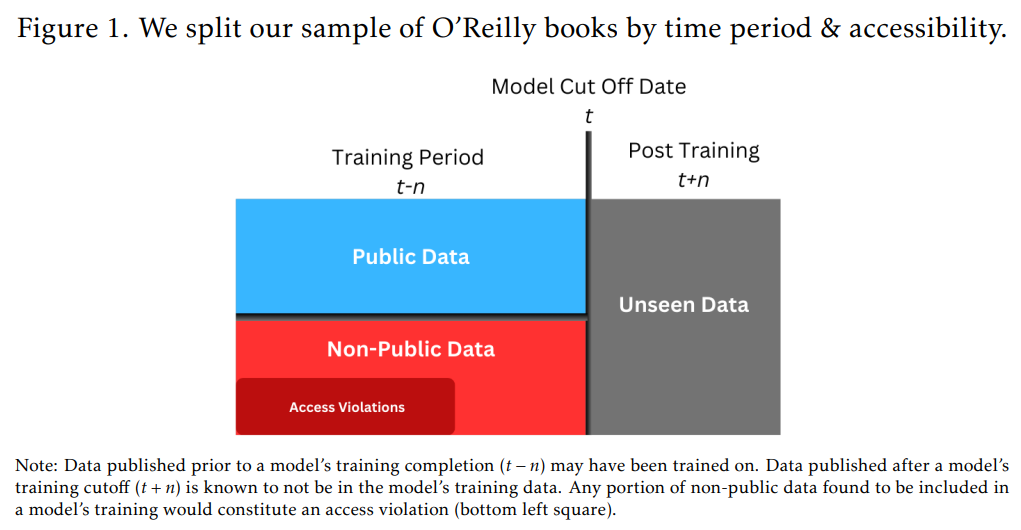
訓練カットオフ日の前後でデータを分割する方法は、「時間的バイアス」(temporal bias)を引き起こす可能性があります。これは、時間の経過とともにデータの言語スタイルなどが変化し、モデルがその変化を学習した結果として、訓練データかどうかの区別ではなく、単に古いデータか新しいデータかを区別しているだけ、という誤解を生む可能性があるバイアスです。このバイアスを考慮するため、本研究では同じ訓練期間で訓練された2つのモデル(GPT-4oとGPT-4o Mini)を比較しました。もし時間的バイアスが支配的な要因であれば、これらのモデルは似たような結果を示すはずですが、もし異なる結果が出れば、それは時間的要因ではなく、モデルの実際のデータに対する知識の違いを反映している可能性が高いと言えます。
データセットの準備にあたっては、訓練期間中に発行された以前の版に軽微な変更を加えた第二版など、データの分類が曖昧になるケースを避けるため、注意深くフィルタリングを行いました。また、出版日と訓練カットオフ日が重なる可能性を最小限にするため、各モデルのテストからはそのモデルのカットオフ年に出版された書籍を除外しました。このため、全てのモデルが全く同じ書籍セットでテストされたわけではありません(詳細は付録A.1のTable 2に記載されています)。
分析手法としては、まずDE-COPメンバーシップ推論攻撃を用いました。これは、モデルに与えられた選択肢の中から、オリジナルの人間が書いたO’Reilly書籍のパラグラフを識別できるかをテストするものです。モデルが訓練期間中に発行された書籍のオリジナルのテキストを頻繁に正しく識別できる場合、それはそのテキストに対するモデルの事前の認識(訓練)を示唆します。評価指標としては、「正答率」(guess rate)を使用しました。比較対象として、モデルが訓練を終えた後に発行された書籍(未知のデータ)に対する正答率を用います。本研究では、GPT-3.5 Turbo、GPT-4o Mini、GPT-4oをテスト対象とし、パラフレーズされた機械生成テキストの作成にはClaude 3.5 Sonnetを利用しました。
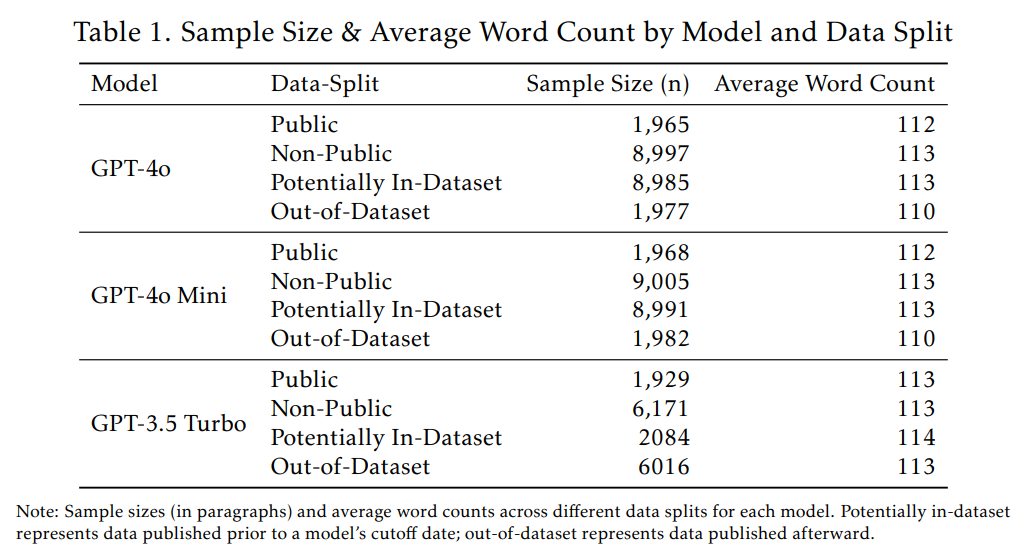
次に、このDE-COPテストで得られた各書籍の「正答率」を用いて、AUROCスコアを計算しました。AUROC(Area Under the Receiver Operating Characteristic)スコアは、モデルが訓練された可能性のあるコンテンツと、訓練後に発行されたコンテンツをどの程度区別できるか、つまり識別能力を示す指標です。AUROCスコアは0から1の間を取り、0.5はランダムな識別能力(コイン投げと同等)、1に近い値は高い識別能力を示します。本研究では、特に書籍レベルでのAUROCスコアを主な評価指標としました。書籍レベルAUROCは、各書籍内の全パラグラフの正答率を平均し、その平均値を用いてAUROCスコアを計算するものです。
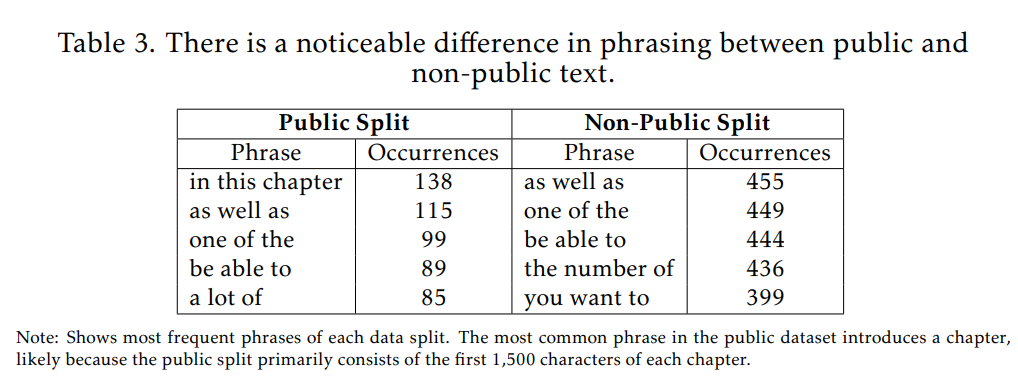
使用したデータの統計的な内訳はTable 1に示されています。また、公開されているテキストと非公開のテキストでは、言語的な特徴に違いが見られました。例えば、公開テキストでは章の冒頭を示すようなフレーズが多く見られますが、これは公開部分が主に各章の最初の1,500文字や特定の章全体から構成されているためです。Table 3にその例が示されています。
3 Findings: Did OpenAI train on copyrighted books?
(調査結果:OpenAIは著作権付き書籍で訓練したのか?)
本研究の主要な結果について説明します。これらは、34冊のO’Reilly Media書籍データを用いて計算されたAUROCスコアに基づいています。
主な発見として、OpenAIのモデルにおけるプレトレーニングデータにおける非公開データの役割は、時間とともに大きく増加したことが示されました。Figure 2を見てください。OpenAIのより新しく能力の高いモデルであるGPT-4oは、非公開のO’Reilly書籍コンテンツに対して高い認識能力(書籍レベルAUROCスコア82%)を示しました。これは、GPT-4oが非公開のO’Reilly書籍の多くを訓練データとして認識しており、事前の知識を持っていることを示唆しています。
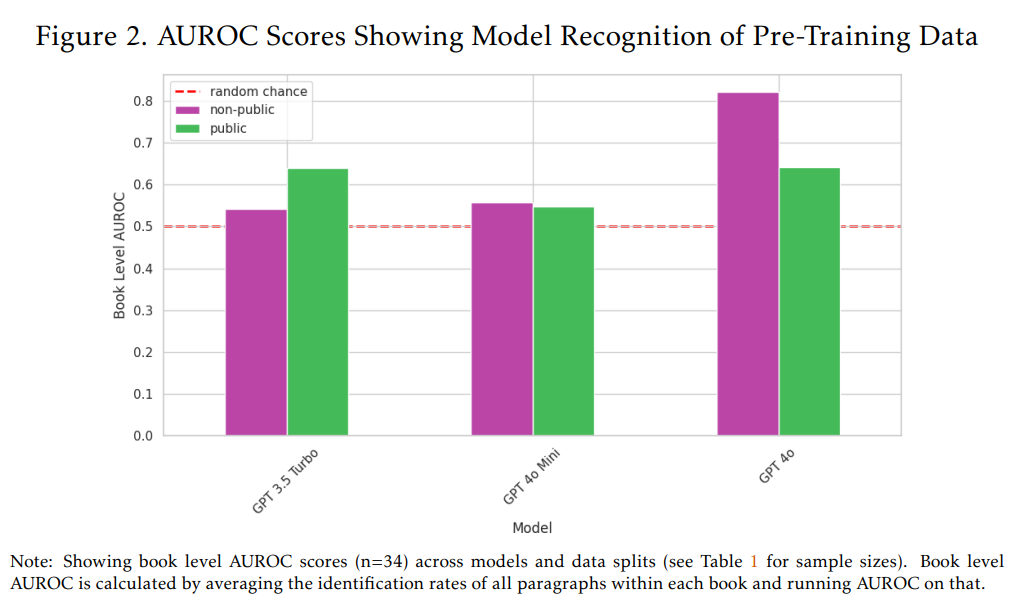
それに対し、約2年前に訓練が完了したGPT-3.5 Turboは、非公開コンテンツに対するAUROCスコアが50%をわずかに上回る程度であり、認識能力は高くありませんでした。これは、訓練データに含まれている可能性のある非公開書籍と、訓練後に発行された書籍を区別するモデルの能力が、GPT-4oに比べてかなり低いことを示しています。
次に、GPT-4oは公開のO’Reilly書籍コンテンツ(AUROCスコア64%)と比較して、非公開コンテンツ(AUROCスコア82%)に対してはるかに強い認識を示しました。これは非常に興味深い結果です。公開データはインターネット上でより容易に入手可能で、繰り返し現れるはずなので、本来であれば公開データの方が高い認識を示すと期待されるからです。このことは、有料であることの多い高品質なデータが、モデルの訓練にとって非常に価値が高いという事実を浮き彫りにしています。
一方、OpenAIの初期のモデルは、訓練データの選択において、より公開されているコンテンツを優先していた可能性があります。GPT-4oとは対照的に、GPT-3.5 Turboは非公開データ(AUROCスコア54%)よりも公開データ(AUROCスコア64%)に対する認識が相対的に高い結果となりました。この傾向は、より大規模で多様、そして高品質な訓練データセットを追求するAI業界全体の流れと一致しているように見えます。その追求の中で、データへのアクセス制限や著作権の影響が軽視されるようになった可能性があります。
なお、本論文では、テスト対象となったO’Reilly書籍が全て海賊版データベースであるLibGenで見つかったことから、このようなアクセスの侵害がLibGen経由で発生した可能性に言及しています。
3.1 Robustness and limitations
(頑健性と限界)
上記の発見の理由の一つ、そして本研究の限界の一つとして、小規模なモデルは、メンバーシップ推論攻撃によるテストがより困難である可能性が挙げられます。GPT-4oと同じ訓練カットオフ日を持つGPT-4o Miniは、非公開のO’Reillyデータで訓練されておらず、公開書籍データに対しても同様に低い認識しか示しませんでした。Figure 2を見ると、GPT-4o MiniのAUROCスコアは公開データで55%、非公開データで56%と、どちらもランダムな識別能力(50%)に近い値です。これは、訓練によって得られた固有のテキストの知識を反映しているというよりは、GPT-4oに比べてパラメータ数(モデルの規模を示す指標の一つ)がはるかに小さいモデルであるため、テキストを記憶する能力が低いことを反映している可能性があります。
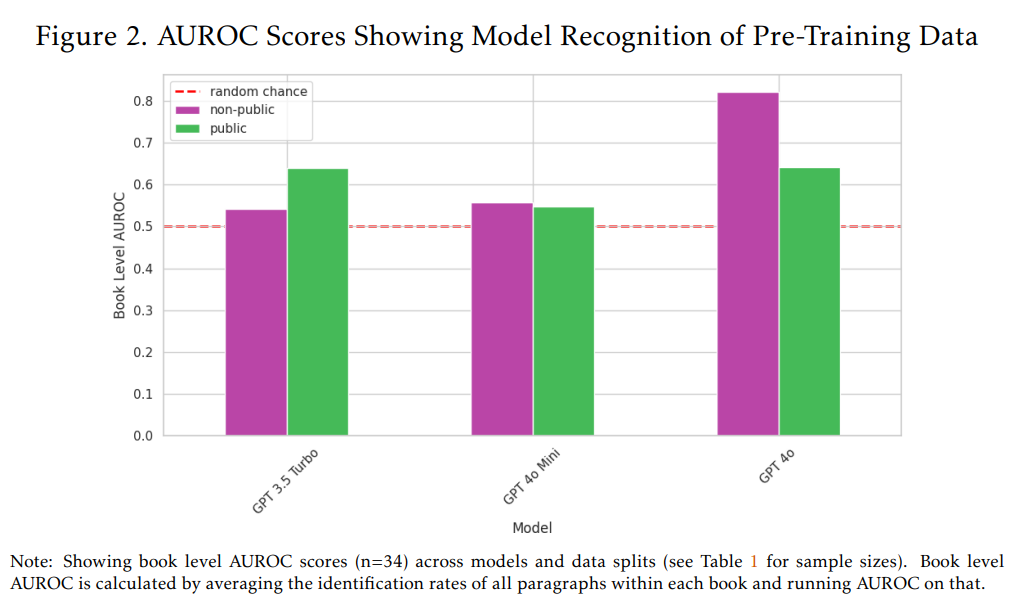
第二に、LLMの能力向上そのものが、メンバーシップ推論攻撃による訓練データの特定をより難しくする可能性があることに注意が必要です。Figure 3は、モデルの訓練カットオフ日以降に出版された書籍(モデルにとって未知の書籍)に対するベースラインのDE-COP正答率(識別率)を示しています。Figure 3を見ると、OpenAIのモデルの能力が向上するにつれて、たとえモデルが訓練されていないテキストであっても、人間が書いたテキストと機械生成されたパラフレーズを正しく識別する能力が高まっていることが分かります。これは、GPT-3.5 Turbo(訓練完了2021年9月)の31%から、GPT-4o Mini(訓練完了2023年10月)の57%、そしてGPT-4o(訓練完了2023年10月)の78%へと増加しています。
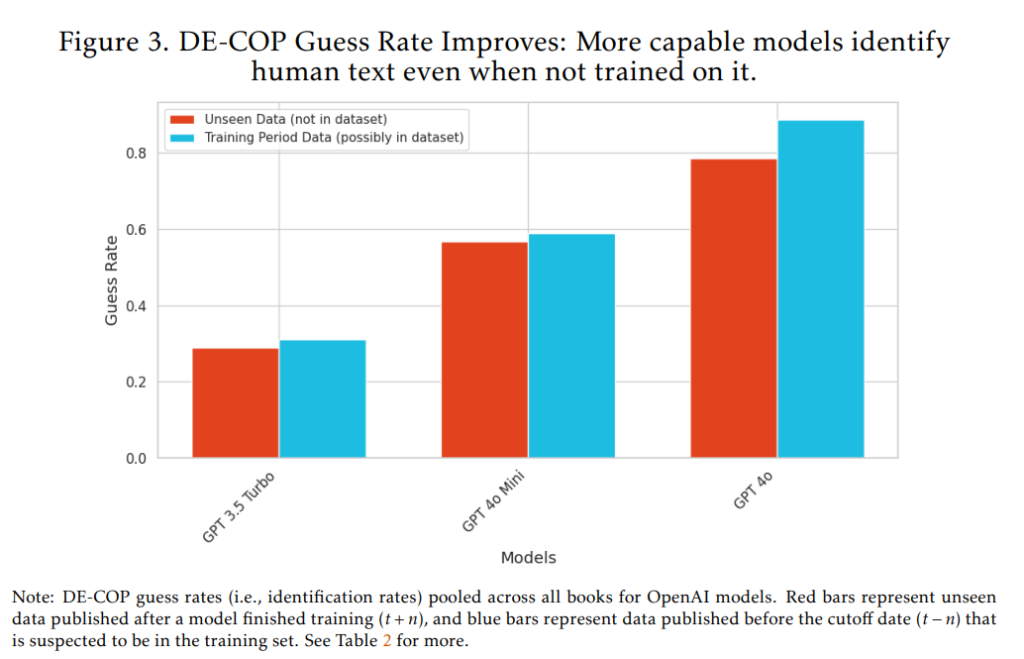
もしこのベースライン正答率が例えば96%を超えると、訓練データに含まれている可能性のあるパラグラフと含まれていないパラグラフの差が、パラグラフレベルでは検出不可能になる可能性があります。しかし、現時点では、特に書籍レベルで結果をまとめる際には、その差は依然として十分に大きいため、両方のカテゴリーを信頼性高く区別することができます。
最後に、本研究の書籍レベルAUROC推定には不確実性があり、ブートストラップ信頼区間が広いという限界があります。これは主に、分析に使用した書籍数(34冊)が少ないことによるものと考えられます。書籍数が少ないため、仮に訓練データに含まれていなかった書籍が誤って「インデータ」と分類されてしまうなど、「誤ったラベル付け」が結果に大きな影響を与えてしまう可能性があります。一方、パラグラフレベルでブートストラップを行う(書籍を区別せず全パラグラフをプールして分析する)と、信頼区間は大幅に狭くなります。これは、書籍数を増やせば書籍レベルAUROCの信頼区間も狭まることを示唆しています。
4 Discussion: Towards functional content AI marketplaces?
(考察:機能的なコンテンツAIマーケットプレイスに向けて?)
本論文で示されたAIモデルの「アクセスの侵害」(著作権付き非公開コンテンツの無断利用の可能性)に関する証拠は、OpenAIとO’Reilly Media書籍に特化したものですが、これはシステム的な問題である可能性が高いと述べられています。例えば、MetaはLibGen(大量の海賊版書籍のコーパス)でモデルを訓練したという疑惑があり、Anthropicも多数の海賊版書籍を含むデータセット「the pile」を使用したとされています。したがって、本研究の発見は、AIモデル開発者全体におけるデータ収集・使用慣行の変更を促すことを目的としています。
現在のAIモデル開発の慣行は、コンテンツエコシステムにとって法的な課題だけでなく、存続に関わる問題を生み出しています。訓練データの無補償利用は、個々の著作権者にとどまらず、プロのコンテンツ制作全体の持続可能性に経済的な影響を与えます。もしAI企業がコンテンツクリエーターの成果物から価値を抽出しつつ、公正な補償を行わなければ、AIシステム自体が依存しているそのコンテンツ資源を枯渇させる危険があります。これは、前述した「コモンズの悲劇」を生み出す動態です。この問題に対処しないままだと、無補償の訓練データ利用はインターネット上のコンテンツの質と多様性の低下という悪循環につながる可能性があります。
本研究の主な発見、すなわちより高度なGPT-4oモデルが非公開データで訓練された可能性が高いという結果は、小規模なサンプルに基づく予備的なものであり、前述した手法上の注意点も伴います。モデルの出力から訓練データを推論するメンバーシップ推論攻撃は、モデルの訓練データソースを詳細に開示する「モデルカード」(モデルの訓練に使われたデータセット、その特性、倫理的な考慮事項などを詳細に記述した文書を指します)の代替となるものではありません。しかし、すべての訓練データソースを個別に特定して開示することは、特に小規模な企業にとっては、そのためのツールや基準がなければ現実的ではないという問題もあります。
この問題への対応策として、Common Corpusのような、事前に検証された大規模な訓練データセットを提供するという方法が考えられます。Common Corpusのように、データクリーニングプロセスを一元化し、検証可能なプレトレーニングデータを「公共財」として提供することで、小規模企業でも非独占的なデータでモデルを訓練できるようになり、開示も容易になります。また、専門的なデータ監査企業も登場していますが、具体的な基準がなければその活動には限界があります。
データ開示に関する要件は、欧州において法的に義務付けられる可能性があります。EUのAI法では、汎用モデルの開発者に対し、「訓練に用いられたコンテンツについて、十分に詳細な要約を作成し、公開すること」を求めています。この規定が完全に施行されるのは2026年ですが、「十分に詳細な要約」が何を意味するかはまだ不明確です。一方で、米国のモデル開発者は、モデルのプレトレーニングが著作権義務から免除されることや、EUの規制から米国の企業を保護することを求めてロビー活動を行っています。しかし、EU AI法の開示要件が適切に定められ、施行されれば、ポジティブな開示基準サイクルを促す助けとなる可能性があります。
知的財産権所有者が、自身の作品がモデル訓練に使用されたことを知ることができるようにすることは、コンテンツクリエーターのデータのためのAI市場を確立するための重要な第一歩となります。このための技術的な手法はまだ初期段階ですが、音楽のような特定のコンテンツタイプに適用した場合、より良い結果が得られるようです。少なくとも一つの新しい音楽プラットフォームは、AI生成された音楽出力を特定の訓練データに紐づけることができるようになっているとのことです。
AI企業がモデル訓練のためにデータを違法に入手した可能性が高いという証拠が存在する一方で、AIモデル開発者がコンテンツに対して支払いを行う、比較的大規模な市場も出現し始めています。これにはライセンス契約を通じたものも含まれます。データプロバイダーから同意を得て、個人識別情報(PII)を除外し、収益をコンテンツプロバイダーと分配するという形で、AIモデル開発者のデータ購入を円滑にする仲介業者が現れています。例えば、Defined.aiは、Google、Meta、Apple、Amazon、Microsoftなどの様々な企業にデータをライセンス供与しており、写真1枚あたり数セントから、長時間の映像に対しては1時間あたり300ドルまでで販売しています。しかし、AIモデル開発者は現在、モデルのファインチューニング(特定のタスクやデータに合わせてモデルを調整する段階)のための、インターネット上から簡単に収集できないラベル付きデータに対して最も多くの費用を支払っています。このようなデータの提供者は多大な利益を生んでおり、この分野のリーディングカンパニーであるScale.AIは昨年138億ドルと評価されました。
データ使用に関する責任がAIのバリューチェーン(製品やサービスが顧客に届くまでの各段階)全体で明確になれば、ライセンス契約やコンテンツクリエーターへの支払いはより一般的になる可能性が高いです。OpenAI自身も、英国上院通信デジタル特別委員会での調査に対し、「今日の主要なAIモデルを訓練するには、著作権付き素材を使用せずには不可能である」と述べているように、その影響は大きいでしょう。音楽会社とAI企業のライセンス契約(まだ議論中ですが)は、データ所有者が比較的集中しており、交渉力を持っている場合に、AIバリューチェーンにおけるデータ使用に関する責任がより明確になったときに何が可能になるかを示す例となるかもしれません。2024年後半には、Musical AIとBeatoven.aiが、「音楽業界初の、完全にライセンスされ、著作権所有者に補償を行う、著作権付き音楽やその他のオーディオで訓練された生成AIプラットフォーム」の構築を開始しており、コンテンツクリエーターへの補償は、生成物を訓練データに紐づけるソフトウェアに基づいています。
明確な責任体制がない場合でも、AI企業はexpress permission(明示的な許可)を得ていないデータでモデル訓練を続けています。強力な証拠として、AI企業がrobots.txtのガイドライン(ウェブサイトへのアクセスを制限するファイル)を無視し、ウェブサイトのコンテンツで訓練を行っていることが示されています。これに対応するため、CloudflareはAIボットによる無許可アクセスからウェブサイトを保護するAI Labyrinthという新しい製品を開発しています。Miso.aiも同様の研究や製品を開発中です。
5 Conclusion
(結論)
本研究は、法的に入手した34冊のO’Reilly Mediaの独占的な書籍データを用いることで、OpenAIのGPT-4oが、非公開の著作権付きコンテンツで訓練された可能性が高いという独自の経験的証拠を提供しました。
DE-COPメンバーシップ推論攻撃法を用いることで、GPT-4oが非公開コンテンツに対して高い書籍レベルAUROCスコア(82%)を達成したことを発見しました。これは、公開されているO’Reilly Media書籍コンテンツ(64%)よりもさらに高いスコアでした。このことは、プレトレーニング段階でこれらのコンテンツを事前に認識していた可能性が高いことを示しています。
さらに、OpenAIモデルのプレトレーニングデータにおける非公開データの役割は、時間とともに大きく増加した可能性が高いことが示されました。より新しく、より能力の高いGPT-4oモデルは、ペイウォールの裏にあるO’Reilly書籍コンテンツに対して強い認識を示しましたが(AUROC 82%)、2年前に訓練されたGPT-3.5 Turboはそうではありませんでした(AUROC 50%強)。初期のOpenAIモデルは、訓練データの選択において、より公開されているコンテンツを優先していた可能性があります。GPT-4oとは対照的に、約2年前に訓練されたGPT-3.5 Turboは、非公開データ(54%)よりも公開されているO’Reilly書籍サンプルに対する認識が相対的に高い結果でした(64%)。
ここで示された証拠はOpenAIとO’Reilly Media書籍に特化したものですが、これはシステム的な問題である可能性が高いと考えられます。MetaがLibGenでモデルを訓練したとされる疑惑や、Anthropicが多数の海賊版書籍を含むデータセットを使用したとされる例からも、この問題の広がりが示唆されます。AIモデルが賢く最新の状態を保つためには、高品質なペイウォール付きデータが必要不可欠であるため、このようなデータでの訓練は今後も必要とされるでしょう。これは、このようなデータのための構造化された市場が、今後出現する時間と必要性があることを意味しています。
もし知的財産権に対する現在の軽視が放置されると、たとえその利用が法的に許容されたとしても、最終的にはAI開発者自身に損害を与える可能性があります。生成AIからクリエーターと開発者の双方が利益を得られるような、持続可能なエコシステムを設計する必要があります。そうでなければ、特に新しいコンテンツが人間によってあまり生産されなくなるにつれて、モデル開発者の進歩は急速に停滞する可能性があります。責任体制が明確化されることは、様々なタイプのモデル訓練や推論のための、実行可能な市場の形成を促進するために必要な大きな推進力となるかもしれません。
まとめ
本論文は、OpenAIの最新モデルであるGPT-4oが、著作権で保護された非公開のO’Reilly Media書籍コンテンツで訓練された可能性が高いことを、具体的なデータ分析に基づいて示しました。特に、公開データよりも非公開データに対して強い認識を示した点は重要であり、高品質な非公開データがモデルの性能向上に寄与している可能性が示唆されます。
この研究結果は、AIモデル開発における訓練データソースの透明性の欠如という、長年の懸念を裏付けるものです。また、より新しいモデルほど非公開データへの依存度が高まっている可能性を示しており、これはコンテンツクリエーターの権利保護や、インターネットコンテンツエコシステムの持続可能性にとって看過できない問題です。
本研究の限界として、分析対象とした書籍数が少ないことによる統計的な不確実性はありますが、メンバーシップ推論攻撃という手法を用いて、実際にモデルが訓練データに含まれている可能性のあるコンテンツを認識しているという傾向を明確に示しました。
今後、AIの発展が社会に受け入れられ、持続可能なものとなるためには、AI開発者とコンテンツクリエーター双方がWin-Winの関係を築く必要があります。そのためには、訓練データの適切なライセンス供与や補償の仕組み、そしてそれを可能にするデータ利用に関する透明性の向上と責任体制の構築が不可欠と言えるでしょう。








