
はじめに
2022年11月の登場以来、ChatGPTは驚異的なスピードで世界中に普及しました。その利用者数は7億人を超え、世界の成人人口の約10%に達するなど、新しいテクノロジーとしては前例のない速さで社会に浸透しています。
これほどまでに大規模言語モデル(LLM)が急速に普及しているにもかかわらず、「人々は実際にChatGPTをどのように使っているのか?」という問いに対する具体的な情報は限られていました。その原因として、これまでの調査は自己申告に基づくアンケートが中心で、実際の利用データに基づいた詳細な分析はほとんどなかったためです。
OpenAIとハーバード大学などの研究者が共同で、ChatGPTの膨大な利用データをプライバシーに配慮した形で分析し、誰が、いつ、何のために使っているのかを明らかにしました。本稿では、論文の内容を項目に沿って解説していきます。
解説論文
- 論文タイトル:How People Use ChatGPT
- 論文URL:http://www.nber.org/papers/w34255
- 発行日:2025年9月
- 発表者:Aaron Chatterji, Thomas Cunningham, David J. Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- ChatGPTの普及は驚異的で、2025年7月には週間アクティブユーザーが7億人に達した。
- 利用の約7割は仕事以外の目的であり、その割合は増加傾向にある。
- 主な利用トピックは「実践的なガイダンス」「情報探索」「文章作成」の3つで、全体の約8割を占める。
- 仕事での利用は「文章作成」が40%を占め、特に管理職やビジネス職で多用される。
- ユーザーの意図を分析すると、タスク実行(Doing)よりも意思決定支援(Asking)の利用が多く、その傾向は高学歴者や専門職で顕著である。
- 利用者の男女比は当初男性に偏っていたが、現在はほぼ均等になっている。
- 低・中所得国での利用者数の伸びが著しい。
詳細解説
この論文では、ChatGPTの膨大なメッセージデータを、プライバシーを保護した手法で自動分類し、多角的な分析を行っています。ここでは、論文の構成に沿って、その詳細な内容を解説していきます。
1. Introduction(はじめに)
2022年11月のリリースから2025年7月までに、ChatGPTは週間アクティブユーザー7億人、週180億メッセージという規模にまで成長しました。これは世界の成人人口の約10%に相当し、過去に例のない速度での技術普及です。
これまでのLLMの利用実態に関する研究は、自己申告に基づくアンケート調査がほとんどで、実際の対話データを直接分析したものは非常に限られていました。この論文は、プライバシーを保護する自動分類パイプラインを用いることで、大規模な実利用データを直接分析した初めての研究の一つです。研究チームは、ユーザーのメッセージ内容を直接閲覧することなく、仕事関連か否か、対話のトピック、ユーザーの意図などを分類し、利用者の属性と結びつけて分析しています。
2. What is ChatGPT?(ChatGPTとは?)
このセクションでは、ChatGPTの技術的な背景が簡潔に説明されています。ChatGPTは、大規模言語モデル(LLM)を基盤としたチャットボットです。LLMとは、膨大なテキストデータから単語の出現確率を学習し、与えられた文脈に続く最も自然な単語を予測する統計モデルです。
LLMの学習は、一般的に「事前学習(pre-training)」と「事後学習(post-training)」の2段階で行われます。
- 事前学習:インターネット上の膨大なテキストコーパスを使い、「次に来る単語」を予測するタスクを解くことで、言語の文法、意味、文脈、そして世界の知識に関する潜在的な表現をモデルに学習させます。
- 事後学習:事前学習済みモデルを、人間のフィードバックを用いて特定のタスク(対話など)に適応させる段階です。人間のレビュアーが作成した高品質な応答データで微調整(fine-tuning)したり、モデルが生成した複数の応答を人間がランク付けし、そのフィードバックを基に強化学習(Reinforcement Learning from Human Feedback: RLHF)を行ったりします。
この2段階のプロセスにより、LLMは単なるテキスト予測機から、人間にとって有用で安全な応答を生成するチャットボットへと進化します。
3. Data and Privacy(データとプライバシー)
本研究の最大の特徴は、ユーザーのプライバシー保護を徹底している点です。研究チームは、ユーザーのメッセージ内容を一切直接閲覧していません。
3.1 Growth Dataset(成長データセット)
2022年11月のリリース以降の、コンシューマー向けプラン(無料、Plus、Pro)の全利用データです。日ごとのメッセージ数に加え、ユーザーが最初にChatGPTを利用した日時、登録国、プラン、自己申告による年齢(プライバシー保護のため、5〜7歳の幅でグループ化)といった非識別化されたメタデータが含まれます。
3.2 Classified Messages(分類済みメッセージ)
ユーザーのプライバシーを保護しながら利用実態を把握するため、LLMベースの分類器を用いてメッセージを自動分類しています。研究者は元のテキストを見ることなく、分類結果のみを分析します。分類器は、公開データセット(WildChat)を用いて人間による分類結果と比較検証されています。
メッセージの自動分類の仕組み
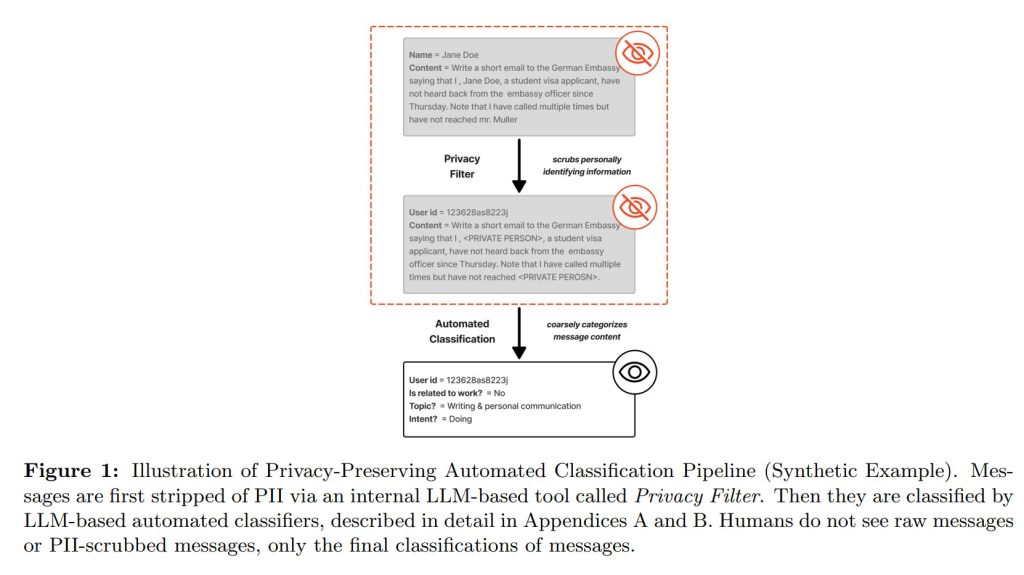
- プライバシーフィルターによる個人情報除去: まず、分析対象となるメッセージは、「プライバシーフィルター」と呼ばれる個人を特定できる情報(PII)を自動的に除去(スクラブ)する社内ツールに通されます。これにより、氏名や連絡先などの機密情報が後続のプロセスに渡らないようにします。
- LLM分類器によるカテゴリ化: 個人情報が除去されたメッセージは、次にLLM(大規模言語モデル)ベースの分類器によって分析されます。この分類器は、メッセージを「仕事関連か否か」「トピックは何か」「ユーザーの意図は何か」といった、あらかじめ定義された粗いカテゴリに分類します。研究者がアクセスできるのは、この分類結果のラベルのみであり、個人情報が除去された後のメッセージ本文すら見ることはありません
3.3 Employment Dataset(雇用データセット)
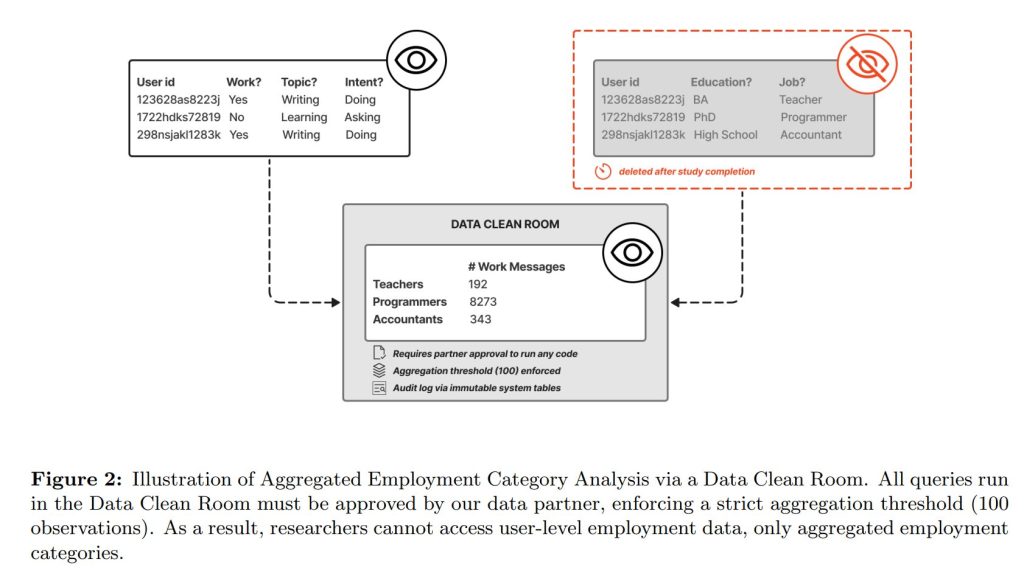
約13万人のユーザーを対象に、公開されている情報源から得られた雇用や学歴に関するデータを集計して分析しています。この分析には「データクリーンルーム(Data Clean Room)」というセキュアな環境が利用されました。これは、OpenAI側と外部ベンダーが互いの生データを見ることなく、100人以上のグループに集計された分析結果だけを共有する仕組みで、個人のプライバシーを厳格に保護しています。
データクリーンルームについて
- 個人レベルのデータへの直接アクセス禁止: 研究チームは、個々のユーザーの職業や学歴といった個人レベルの人口統計データに直接アクセスすることは一切ありませんでした。これらのデータは提携ベンダーが管理し、安全なDCR内で分析が行われました。
- 事前承認された集計クエリのみ実行: 研究者は、実行したい分析コード(クエリ)をまず作成し、6人の共同執筆者からなる委員会の承認を得た上で、データパートナーに提出しました。データパートナーがそのコードを承認して初めて、DCR内で実行が許可されるという二重のチェック体制が敷かれていました。これにより、研究者が意図しない形で機密データに触れるリスクを排除しています。
- 厳格な集計しきい値: DCRからの分析結果は、100人以上のユーザーが含まれるグループの集計値のみが出力されるよう、厳格な制限が課されていました。例えば、ある職業のユーザーが99人しかいなかった場合、その職業単独での結果は表示されません。これにより、特定の個人や小規模なグループが特定されることを防いでいます。
- データ削除: 分析プロジェクトの完了後、このDCR内で使用された人口統計データは完全に削除されました。
3.4 Summarizing Our Approach to Privacy(プライバシー保護へのアプローチまとめ)
2つのアプローチにより、本研究は「研究者がユーザーのメッセージ内容を直接見ない」「研究者が個々のユーザーの人口統計データに直接アクセスしない」という原則を徹底しています。これらの措置を通じて、デジタルプラットフォームのデータを扱う社会科学研究におけるプライバシー保護の先例と同等か、それ以上の水準を目指しています。
4. The Growth of ChatGPT(ChatGPTの成長)
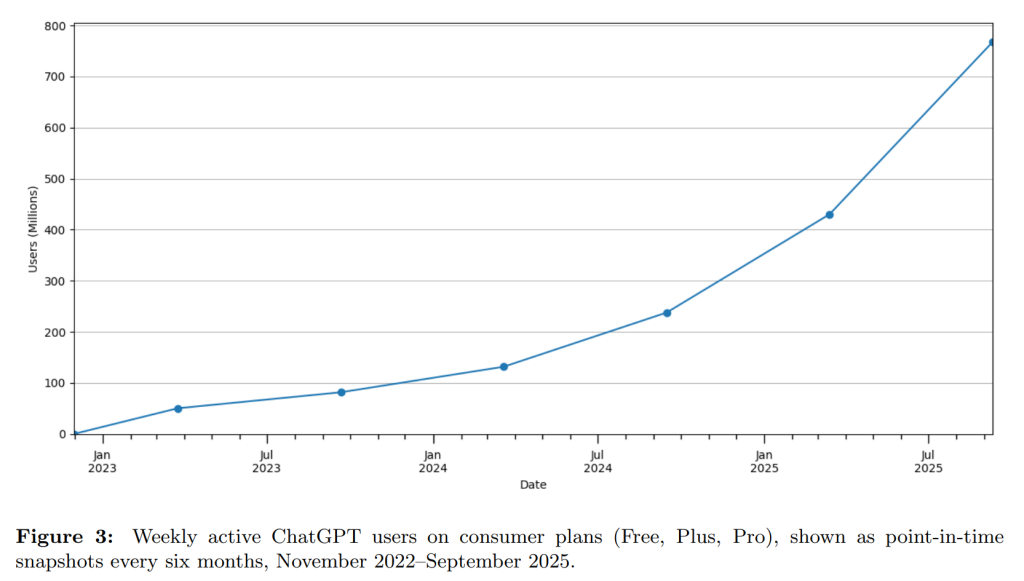
ChatGPTはリリースからわずか1年で週間アクティブユーザー(WAU)が1億人を突破し、2025年7月末には7億人を超えました。
メッセージ量も急増しており、2024年7月から2025年7月の1年間で5倍以上に増加しています。
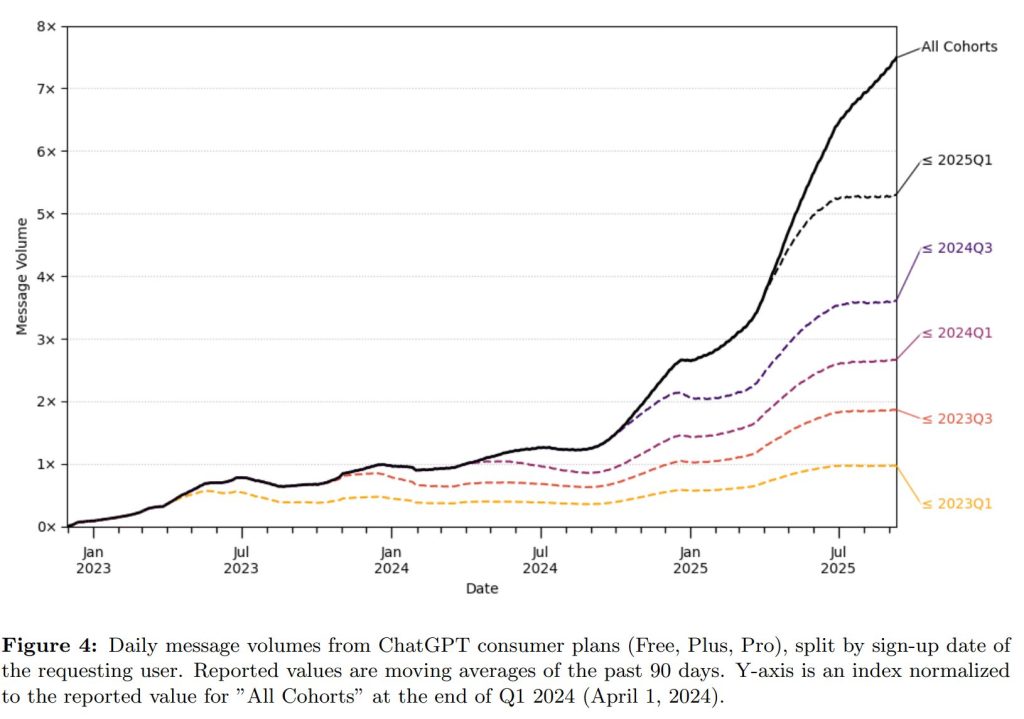
興味深いのは、利用者の増加だけでなく、既存ユーザーの利用量も増加し続けている点です。最も初期からのユーザー(2023年Q1以前の登録者)の利用量も、一時的な減少を経て、2024年後半から再び増加に転じています。これは、新しいユーザー層の流入だけでなく、モデルの性能向上や、既存ユーザーが新たな活用法を発見していることが利用量の増加に寄与している可能性を示唆しています。
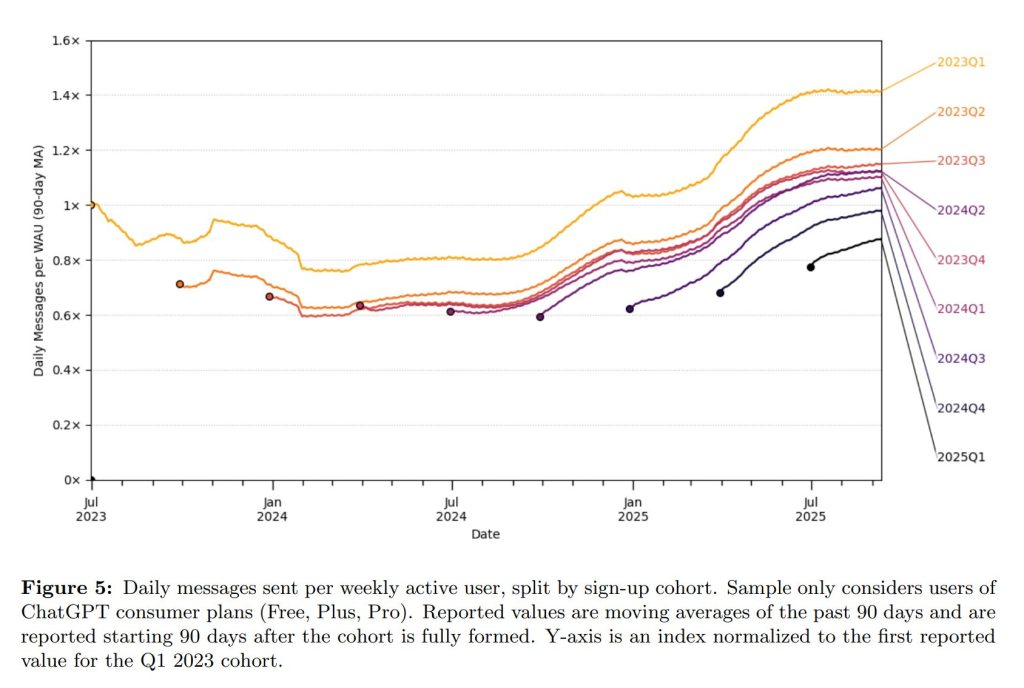
5. How ChatGPT is Used(ChatGPTはどのように使われているか)
このセクションでは、自動分類されたメッセージの内容から、具体的な利用実態が明らかにされています。
5.1 What share of ChatGPT queries are related to paid work?(仕事関連の利用割合)
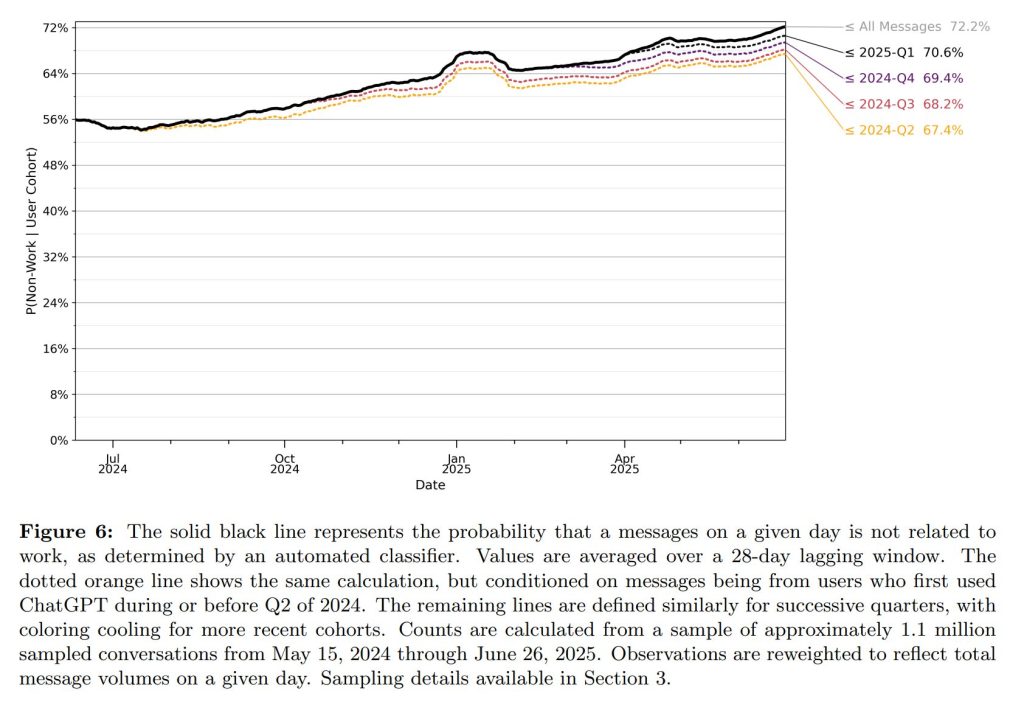
ChatGPTの利用全体のうち、仕事に関連しないメッセージの割合は、2024年6月の53%から2025年6月には73%へと大幅に増加しました。仕事関連・非関連の両方のメッセージ数は増えていますが、非関連のメッセージの伸びがそれを上回っています。これは、経済的な生産性向上だけでなく、日常生活における個人の意思決定支援や情報収集といった「消費者余剰」の面でも、生成AIが大きな価値を生み出していることを示唆しています。
5.2 What are the topics of ChatGPT conversations?(対話のトピック)
対話のトピックを分類した結果、以下の3つが主要な利用目的であることがわかりました。
- 実践的なガイダンス(Practical Guidance):28.8%。学習支援や指導(10.2%)、様々な事柄に関するハウツーのアドバイス(8.5%)、創造的なアイデア出し(3.9%)などが含まれます。
- 情報探索(Seeking Information):24.4%。特定の事実や出来事、製品に関する情報を探す利用で、従来の検索エンジンと類似した使われ方です。
- 文章作成(Writing):23.9%。メールや文書の作成、要約、翻訳、校正などです。
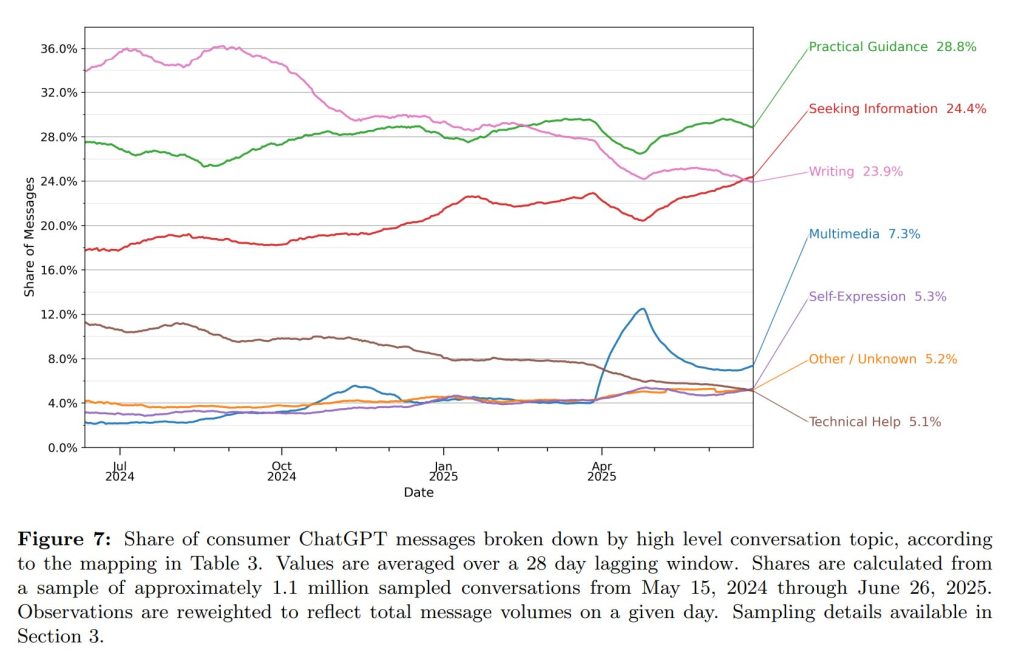
これら3つのトピックで、全利用の約77%を占めています。一方で、コンピュータプログラミングは4.2%、人間関係の相談やロールプレイングといった自己表現(Self-Expression)は合計で2.3%と、一般的に想像されがちな用途の割合は比較的小さいことが明らかになりました。
特に仕事関連の利用に絞ると、「文章作成」が40%と最も多くなっています。また、文章作成のうち約3分の2は、ゼロから文章を生成するのではなく、ユーザーが提供したテキストを編集・校正・要約するタスクでした。
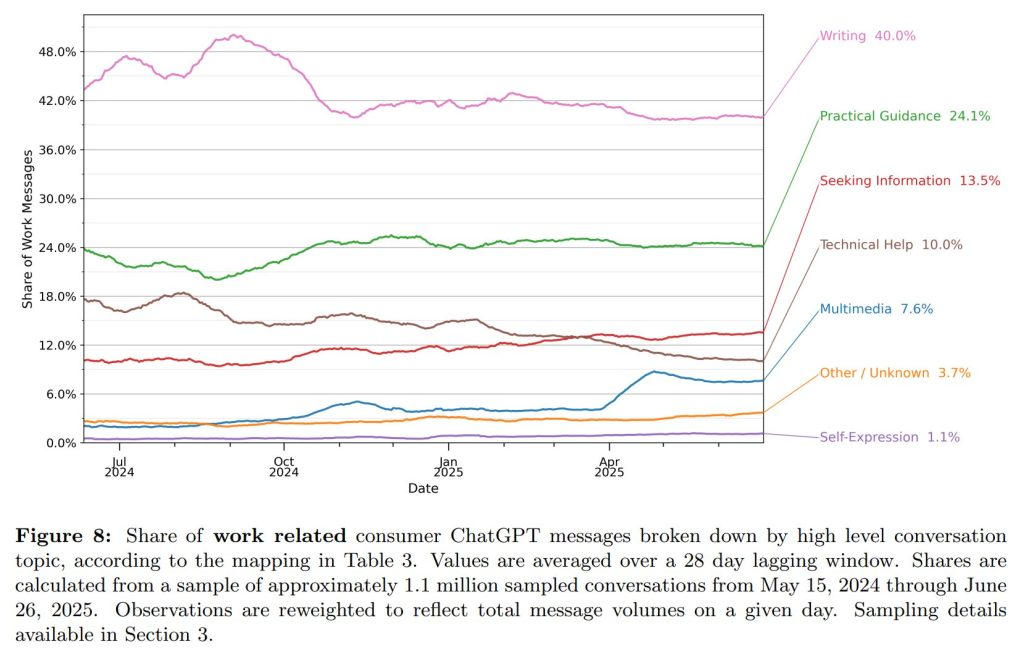
Figure 7で示された7つの大きなトピック(「ライティング」「実践的なガイダンス」など)を、Figure 9ではさらに細かいサブカテゴリに分解し、それぞれの利用割合を明らかにしています。
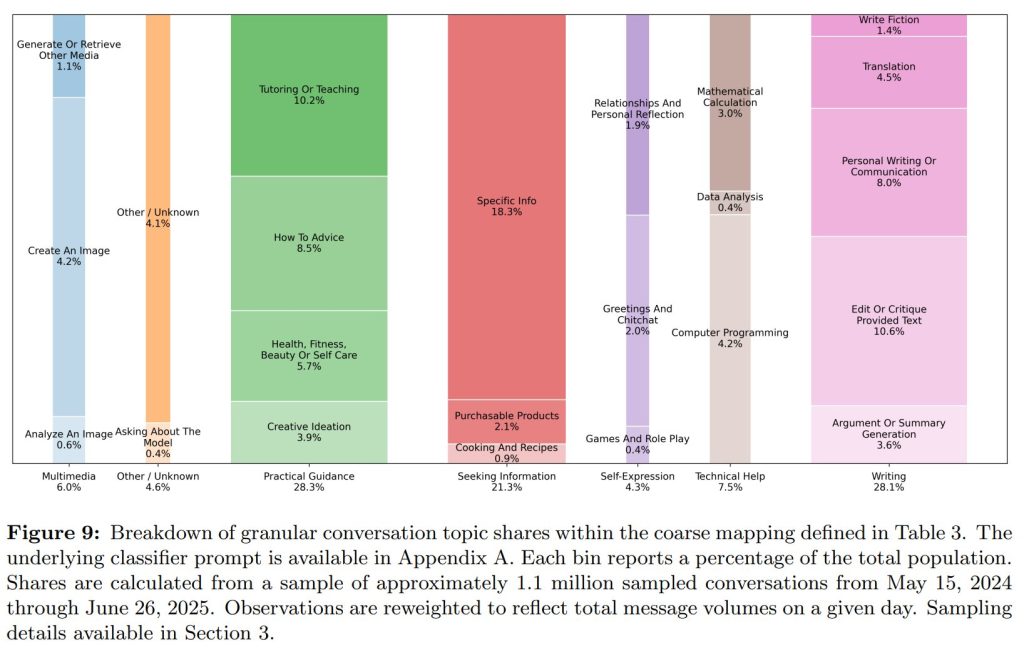
1. 「ライティング」の具体的な使われ方:ゼロからの作成より「修正・改善」が主流
「ライティング」という大きなカテゴリの中でも、使われ方には種類があります。
- 最も多いのは「既存テキストの修正・改善」: ユーザーが自分で書いた文章(メール、レポートなど)をChatGPTに渡して、「もっと良くしてほしい」「要約してほしい」「翻訳してほしい」といった依頼が、「ライティング」関連の利用全体の約3分の2を占めています。
- ゼロからの新規作成は少数派: 「詩を書いて」「物語を作って」といった、全く何もない状態から新しい文章を作成させる依頼は、ライティング利用の中では比較的少ないことが示唆されています。
これは、多くのユーザーがChatGPTを単なる「文章作成機」としてではなく、自分の思考や文章を磨き上げるための「賢い編集パートナー」のように活用していることを意味します。
2. 「教育」が非常に重要な利用分野であること
- 全メッセージの1割が教育関連: 「実践的なガイダンス」というカテゴリの中を見ると、「家庭教師や指導(Tutoring or Teaching)」が突出して多く、全メッセージの10.2%を占めています。これは、学習支援や概念の理解といった教育目的での利用が、ChatGPTの主要な使い方の1つであることを示しています。
- ハウツー情報も多い: 同じく「実践的なガイダンス」の中で、「ハウツー(How-To Advice)」も8.5%と大きな割合を占めており、人々が様々な事柄のやり方を学ぶためにChatGPTを利用していることが分かります。
3. 技術的な利用や個人的な悩み相談は、相対的に少ない
- 技術的なヘルプ(Technical Help): このカテゴリには「コンピュータプログラミング」(4.2%)や「数学の計算」(3.0%)などが含まれますが、全体の利用から見ると、その割合は限定的です。
- 自己表現(Self-Expression): 「人間関係や内省」(1.9%)や「ゲームやロールプレイ」(0.4%)といった、個人的な感情や娯楽に関する利用は、全体の2.4%とさらに少ない割合にとどまっています。これは、ChatGPTが「セラピーや話し相手」として使われるという一部のイメージとは異なり、実際にはより実用的な目的で使われることが多いことを示唆しています。
5.3 User Intent(ユーザーの意図)
研究チームは、ユーザーがどのようなアウトプットを求めているのかを分析するために、「Asking(尋ねる)」「Doing(実行する)」「Expressing(表現する)」という独自の分類を導入しました。
- Asking(尋ねる):意思決定に役立つ情報やアドバイスを求める(例:「相関と因果の違いは何?」)。全メッセージの48.9%。
- Doing(実行する):メール作成やコーディングなど、具体的なタスクの実行を依頼する(例:「このメールをよりフォーマルに書き直して」)。全メッセージの38.9%。
- Expressing(表現する):情報やタスク実行を求めない感情表現や雑談など。全メッセージの11.3%。
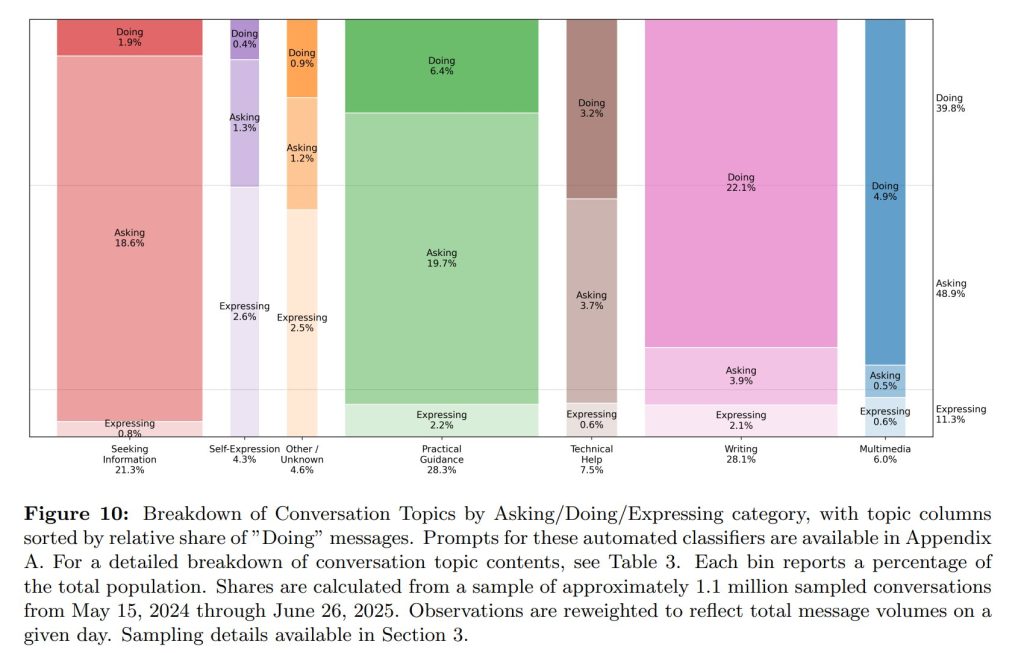
仕事関連の利用では、「Doing」の割合が56%と高くなりますが、その大部分(34.9%)は「文章作成」に関連するものでした。全体として、「Asking」の利用は「Doing」よりも速いペースで増加しており、ユーザー満足度も高い傾向にあります。これは、ChatGPTが単なる作業代替ツールとしてだけでなく、思考を助ける「相談相手」や「副操縦士(Co-pilot)」として価値を提供していることを示唆しています。
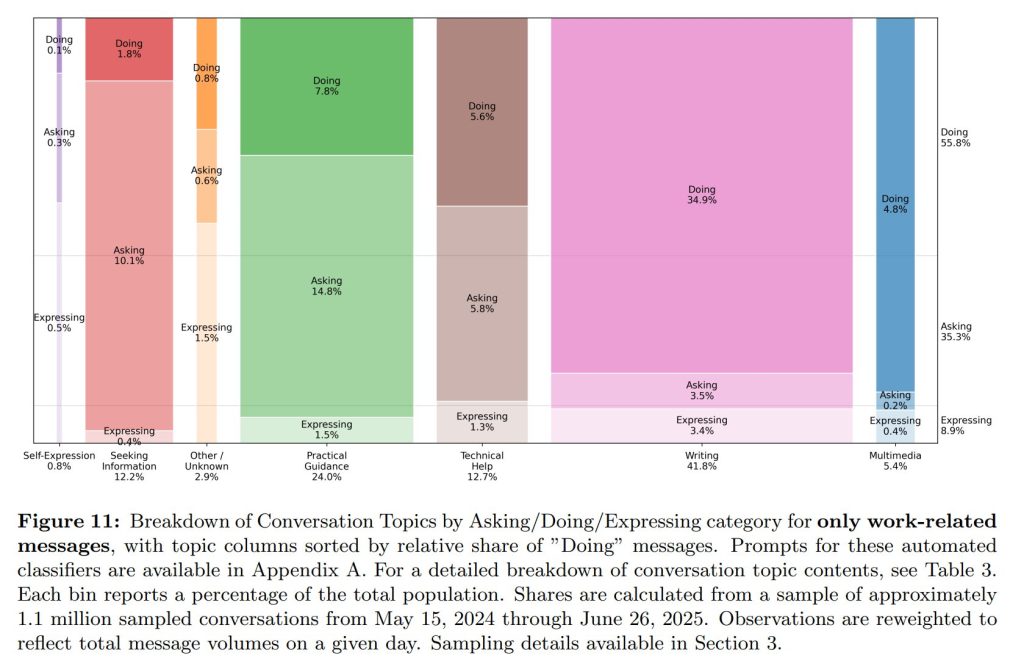
5.4 O*NET Work Activities(O*NET業務活動)
メッセージの内容を、O*NET(米国労働省の職業情報ネットワーク)が定義する業務活動にマッピングする分析も行われています。その結果、仕事関連のメッセージの約81%が、以下の2つの大きな活動に分類されることがわかりました。
- 情報の入手、文書化、解釈
- 意思決定、助言、問題解決、創造的思考
詳細な分布
- 「情報の文書化/記録」(18.4%)
- 「意思決定と問題解決」(14.9%)
- 「創造的思考」(13.0%)
- 「コンピュータでの作業」(10.8%)
- 「他者のための情報解釈」(10.1%)
- 「情報の入手」(9.3%)
- 「他者へのコンサルテーションと助言の提供」(4.4%)
さらに驚くべきことに、職種が異なってもChatGPTに求められる支援の内容は非常に似ていることがわかりました。例えば、「情報の入手」や「意思決定と問題解決」といった活動は、管理職から営業職、技術職に至るまで、ほぼ全ての職種で上位を占めています。これは、ChatGPTが特定の専門タスクだけでなく、職種を横断する普遍的な知的作業を支援する汎用ツールとして機能していることを強く示唆しています。
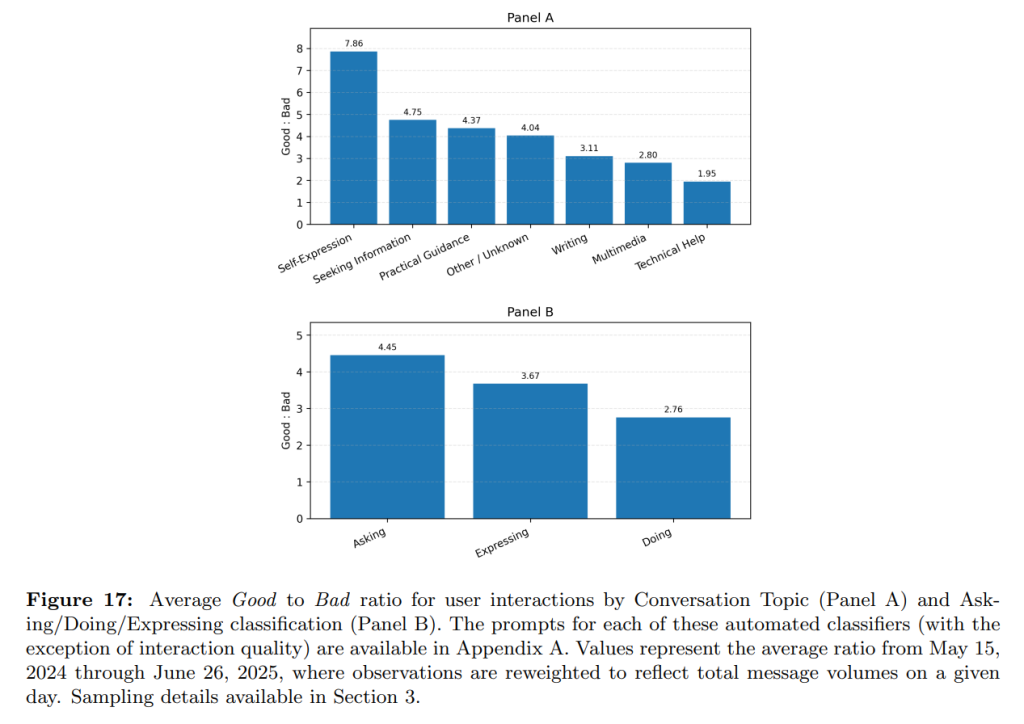
5.5 Quality of Interactions(対話の品質)
ユーザーの満足度を測るため、応答後のユーザーのメッセージから満足・不満足の感情を「Good」「Bad」「Unknown」の3段階で分類しています。2025年7月時点で、「Good」な対話は「Bad」な対話の4倍以上となっており、ユーザー満足度が向上していることが示唆されます。
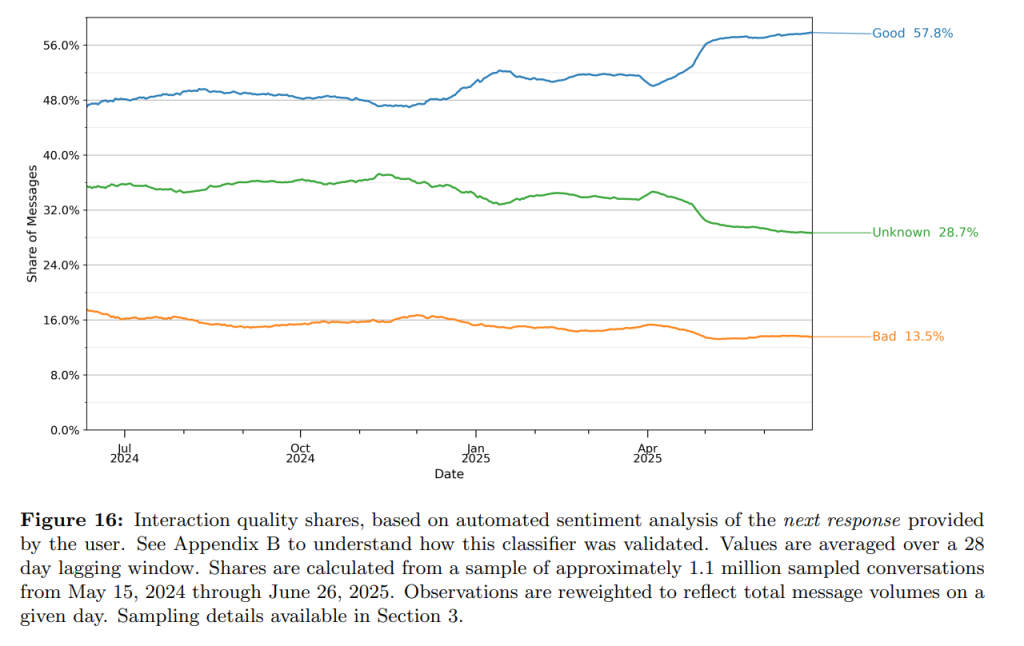
トピック別に見ると、「自己表現」の満足度が最も高く、「Asking」は「Doing」よりも満足度が高い傾向にあります。
6. Who Uses ChatGPT(誰がChatGPTを使っているか)
最後に、利用者の属性と利用パターンの関係性が分析されています。
6.1 Name Analysis(名前による分析)
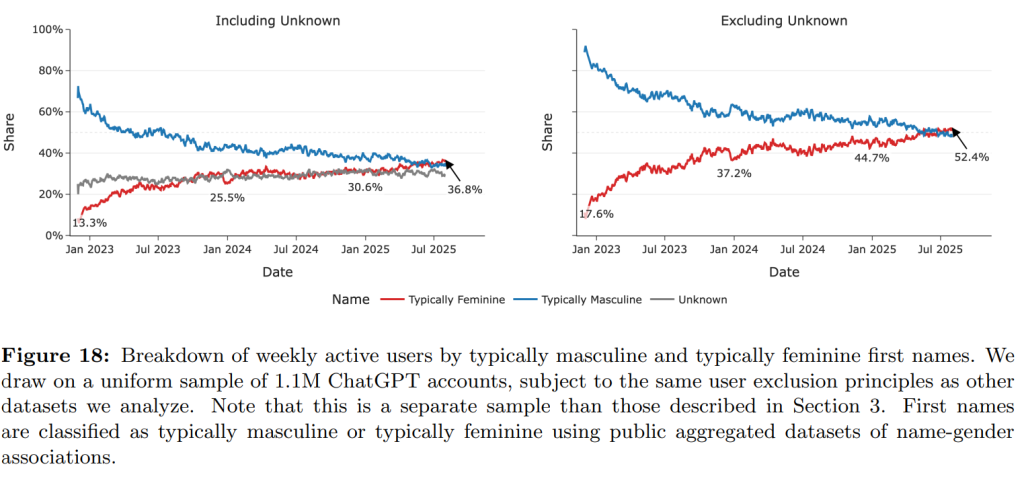
ユーザーのファーストネームから性別を推定した分析では、リリース当初は男性名のユーザーが約80%と大半を占めていましたが、時間とともにその差は縮小し、2025年6月には女性名と推定されるユーザーが男性名を上回りました。これは、生成AIの利用におけるジェンダーギャップが急速に解消されつつあることを示しています。
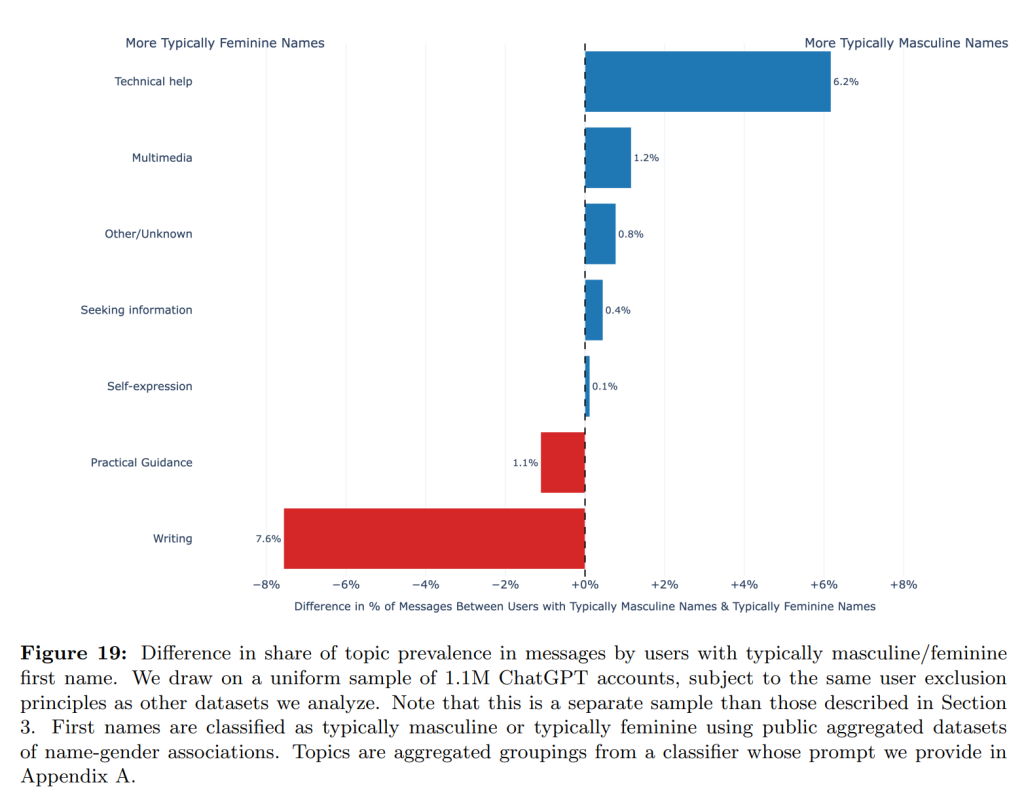
なお、女性的な名前を持つユーザーは、「ライティング(文章作成)」や「実用的なガイダンス(実践的な助言や手順など)」に関連するトピックでChatGPTを利用する傾向が比較的高いです。対照的に、男性的な名前を持つユーザーは、「技術的なヘルプ」、「情報検索」、そして「マルチメディア(画像の作成や編集など)」といった目的で利用する傾向が高いことが示されています。
6.2 Variation by Age(年齢による違い)
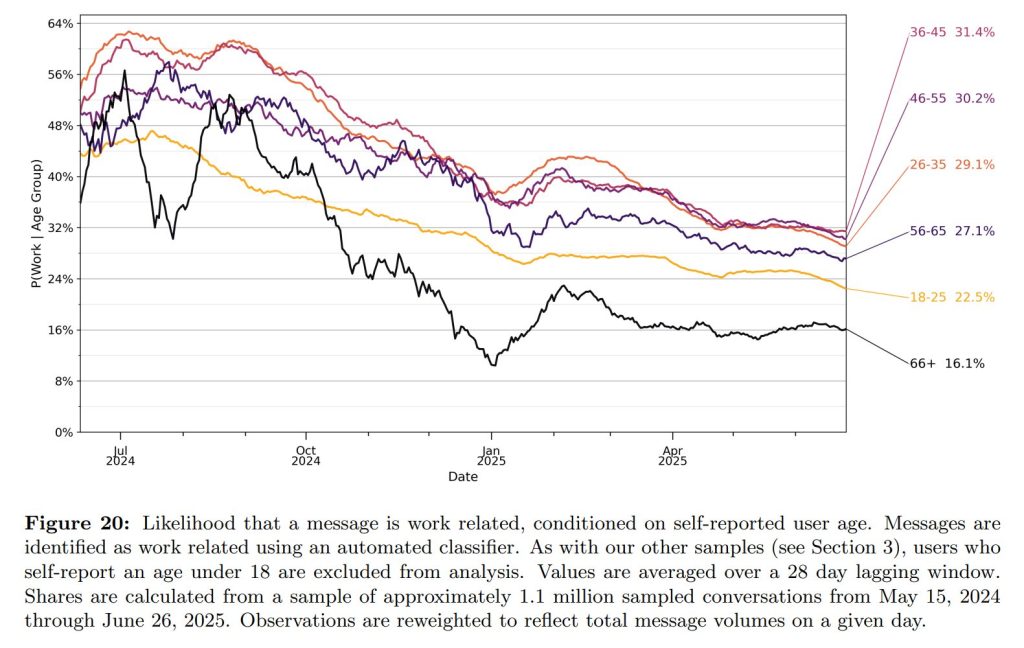
自己申告された年齢データによると、18〜25歳のユーザーが全メッセージの約46%を占めており、若年層の利用が非常に活発です。
仕事関連の利用割合は年齢とともに高くなる傾向がありますが、66歳以上の層では再び低下します。
6.3 Variation by Country(国による違い)
国別の利用状況を見ると、2024年から2025年にかけて、特に一人当たりGDPが1万〜4万ドルの低・中所得国で利用者の割合が大きく伸びています。これは、生成AIが先進国だけでなく、世界中の国々で急速に普及していることを示しています。
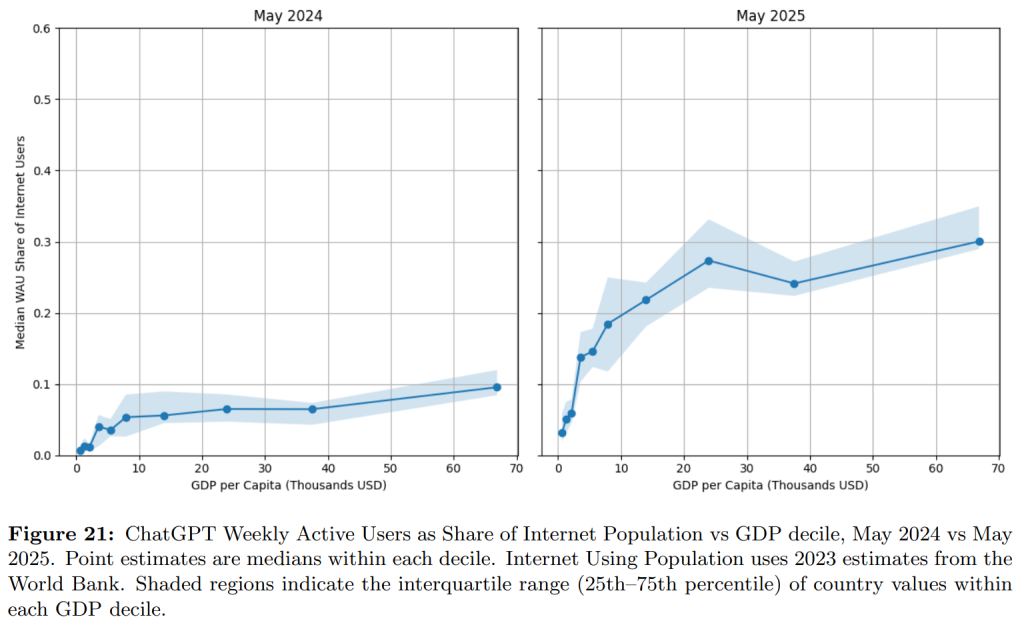
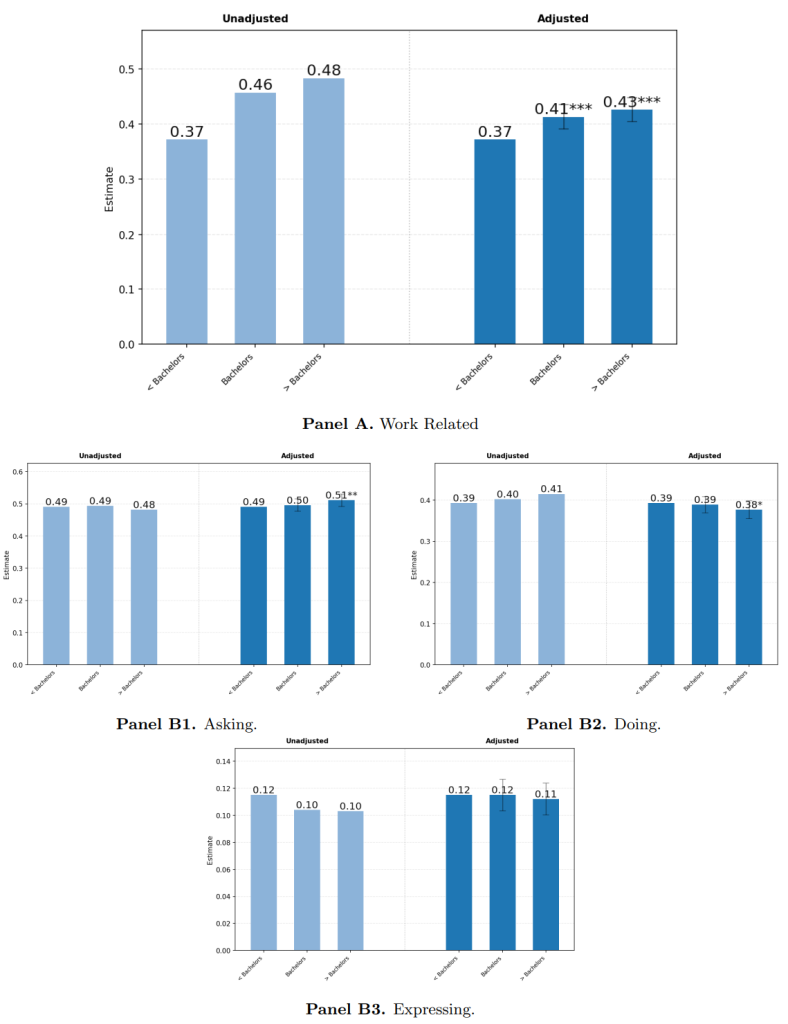
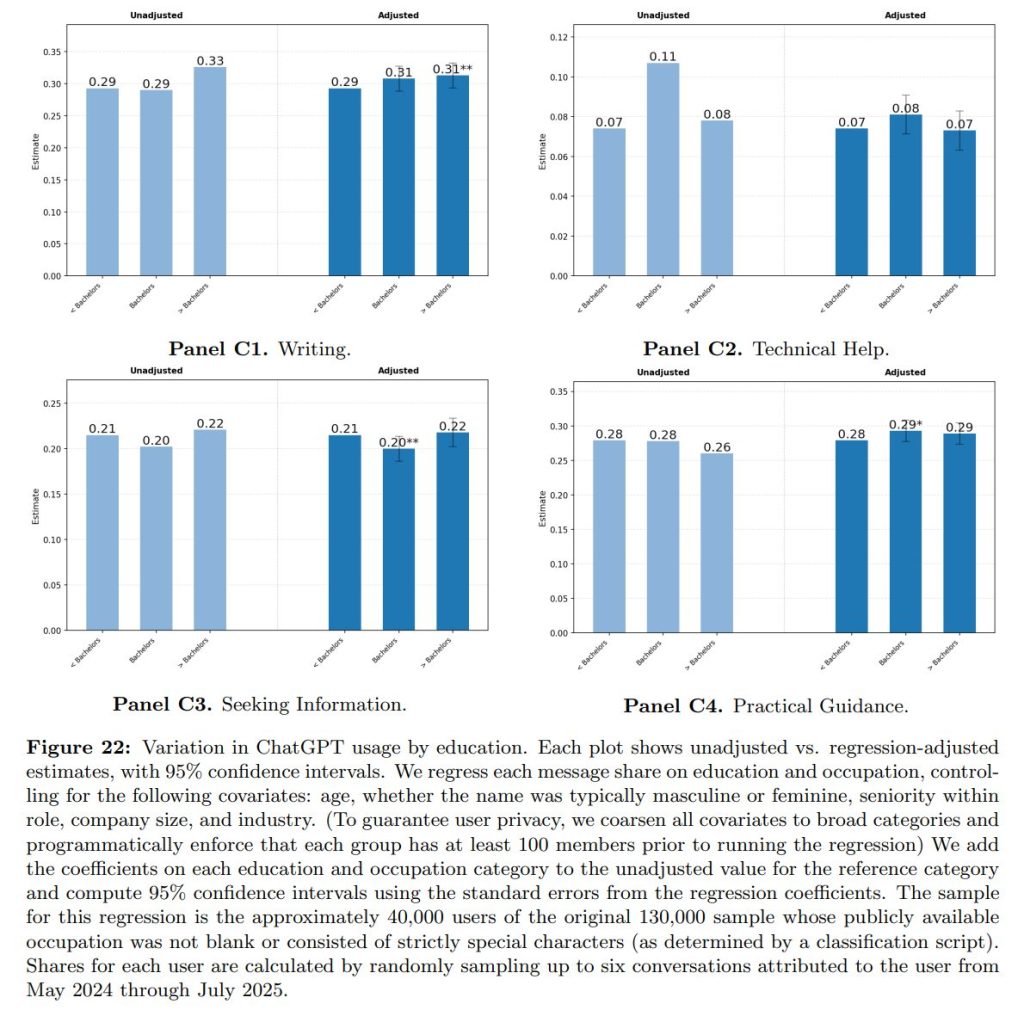
6.4 Variation by Education(学歴による違い)
ユーザーの最終学歴によってChatGPTの使われ方にどのような違いがあるかを分析したものです。分析は、学歴を「学士号未満」「学士号」「大学院教育あり」の3つのカテゴリーに分けて行われています。データクリーンルームを用いた分析から、学歴と利用方法の間に関連があることがわかりました。
学歴が高いユーザーほどChatGPTを仕事で利用する割合が高く、特に大学院卒のユーザーは他の層に比べて「Asking(尋ねる)」の利用が有意に多いという結果でした。
なお、会話のトピック(実用的なガイダンス、情報検索、技術ヘルプ、ライティング)を分析したところ、ほとんどのカテゴリーで学歴による大きな差は見られませんでした。しかし、「ライティング(文章作成)」のトピックだけは例外でした。このトピックに関連するメッセージの割合は、学歴の高さに比例して増加する傾向が見られました。
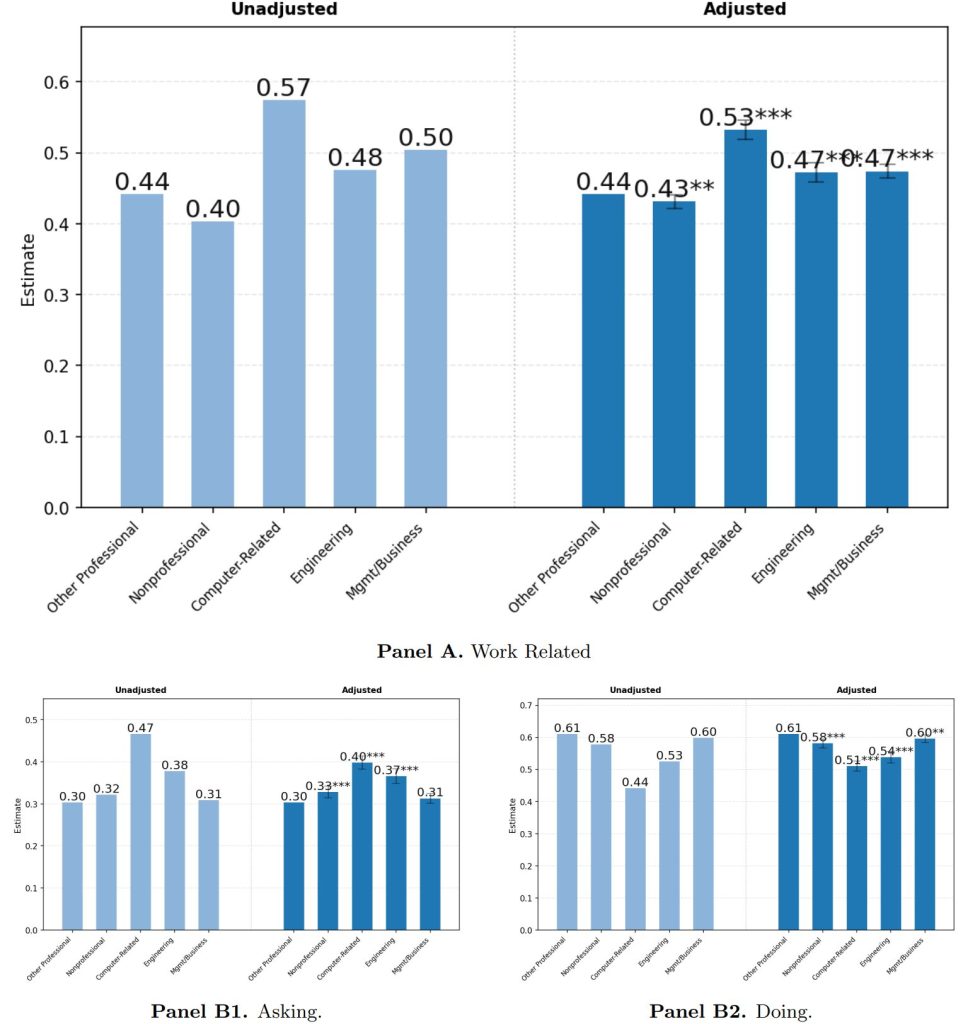
6.5 Variation by Occupation(職業による違い)
ユーザーの職業によって、ChatGPTの使われ方には明確な差が見られます。
- 技術的なヘルプ: コンピュータ関連職で際立って多く(37%)、他の職種(約8%~16%)を大きく上回ります。
- 仕事での利用率: コンピュータ関連職(57%)、経営・ビジネス職(50%)、工学・科学職(48%)といった専門的・技術的な職業のユーザーは、非専門職のユーザー(40%)に比べて、仕事でChatGPTを利用する割合が有意に高いことが示されました。
- 利用目的: 高給な専門職のユーザーは、具体的なタスクを「実行(Doing)」させるよりも、情報を「質問(Asking)」する目的で利用する傾向が強いです。特にコンピュータ関連職では、仕事関連メッセージの47%が「質問」であったのに対し、非専門職では32%でした。
- 会話トピック: 利用される会話のトピックは、各職業の中心的な業務を強く反映しています。
- ライティング: 経営・ビジネス職(52%)や、教育・医療などの専門職(49%)、非専門職(50%)で多く見られます。
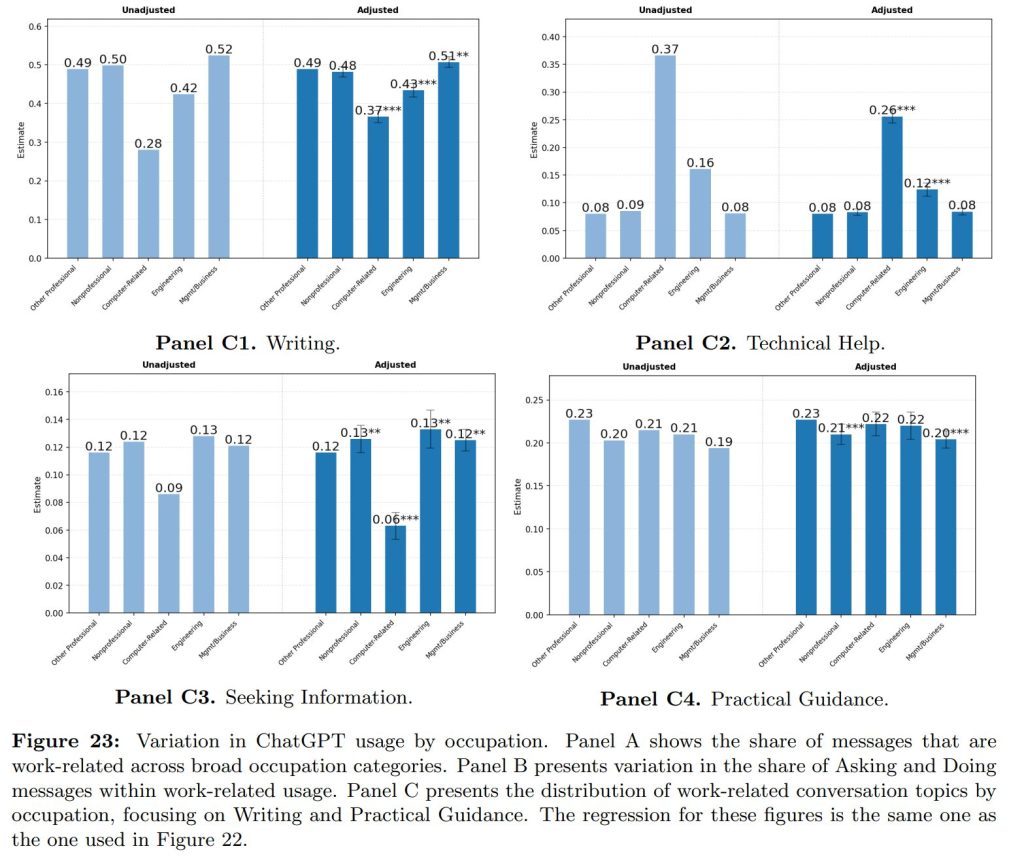
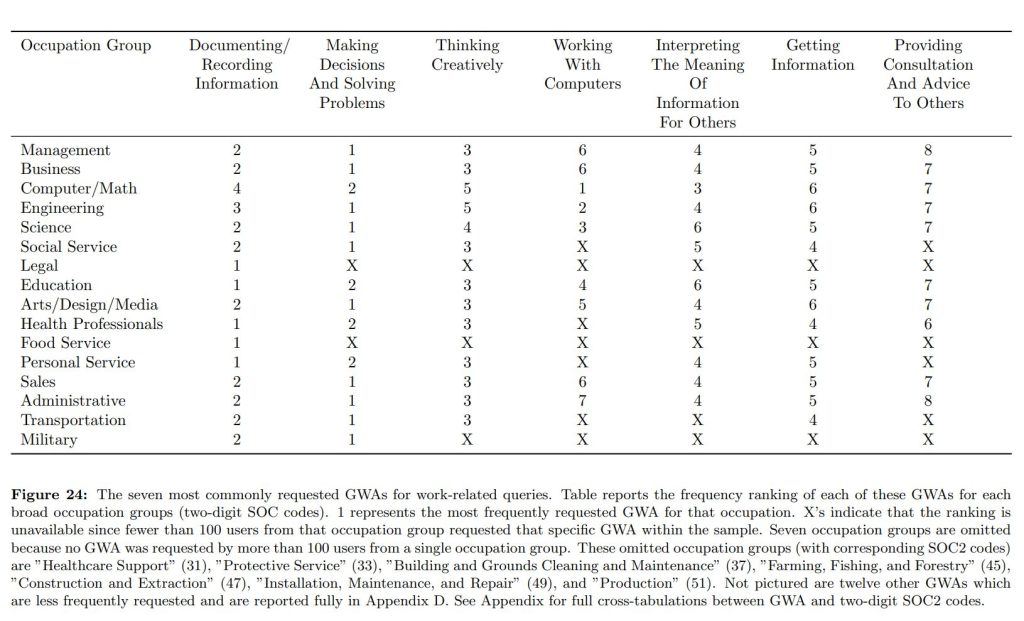
具体的なタスクレベルではなく、より広範な「一般的な職務活動(Generalized Work Activities – GWAs)」という枠組みで分析すると、職業間で類似性が見られました。
共通する上位活動:
- 「創造的思考」は、多くの職業で3番目に多い活動としてランクインしています。
- 「意思決定と問題解決」は、ほぼ全ての職業で最も利用される活動の上位2位以内に入ります。
- 「文書化と情報記録」は、全ての職業で上位4位以内に入ります。
7 Conclusion(結論)
本論文は、2025年7月時点で週7億人以上が利用するChatGPTの内部データを、プライバシーを保護した手法で分析した初の経済学研究です。その利用実態について、以下の8つの重要な事実を明らかにしました。
- 利用目的の主体は「仕事以外」: 利用の約70%は仕事と無関係で、その割合は仕事関連の利用よりも速いペースで増加している。
- 三大トピック: 最も多い会話は「実践的なガイダンス」「ライティング」「情報検索」で、全体の約78%を占める。
- 仕事での最多用途は「ライティング」: 仕事利用の42%を占め、特にゼロからの生成より既存テキストの修正依頼が多い。
- リクエストの種類: 助言や情報を求める「質問」が約半数(49%)を占め、タスクを依頼する「実行」(40%)よりも増加ペースが速く、ユーザー満足度も高い。
- ジェンダー格差の解消: 利用者の男女差はほぼなくなっている。
- 若年層が中心: 成人利用者の半数近くが26歳未満である。
- 新興国での急成長: 低・中所得国での利用が過去1年で急増している。
- 高学歴・専門職層の傾向: 高学歴・専門職のユーザーは、仕事においてタスクの「実行」より、アドバイスを求める「質問」に利用する傾向がある。
結論として、ChatGPTは世界経済に広範な影響を与えています。仕事以外の利用が急速に伸びていることは、社会全体の利益(厚生)が大きい可能性を示唆しています。仕事の場面では、単なる作業代行ツールとしてではなく、意思決定を助ける「アドバイザー」や「リサーチアシスタント」として価値を見出されており、特に知識集約型の仕事における生産性向上への貢献が期待されます。
まとめ
本論文は、プライバシーを厳格に保護した上で、これまで謎に包まれていたChatGPTの具体的な利用実態を大規模データから初めて明らかにした研究です。
その結果、ChatGPTは仕事の生産性を向上させるツールとしてだけでなく、私たちの日常生活における情報収集や意思決定を支援するパートナーとして、より幅広い役割を担っていることが示されました。特に、タスクを直接実行させる「Doing」よりも、思考を助ける「Asking」の利用が多いという発見は、生成AIの経済的・社会的価値を考える上で重要な示唆を与えます。
また、利用者層が急速に多様化し、ジェンダーギャップが解消され、低・中所得国での普及が進んでいる事実は、生成AIが一部の専門家だけのものではなく、グローバルで誰もがアクセスできる汎用技術へと進化していることを物語っています。








