はじめに
私たちの身の回りには、ECサイトの購買履歴やSNSの友人関係など、様々な「関係性」を持つデータが溢れています。これらの多くは「リレーショナルデータベース」という形式で管理されていますが、その複雑な関係性をAIが十分に活用しきれていないのが現状でした。
本稿では、この課題を解決する可能性を秘めた新しいAI技術「グラフ基盤モデル(GFM)」について、Google Researchが2025年7月10日に公開したブログ記事「Graph foundation models for relational data」を基に、解説します。
参考記事
- タイトル: Graph foundation models for relational data
- 発行元: Google Research
- 発行日: 2025年7月10日
- URL: https://research.google/blog/graph-foundation-models-for-relational-data/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Googleは、複数の表で構成されるリレーショナルデータを「グラフ構造」として捉え直す、新しいAIアプローチ「グラフ基盤モデル(GFM)」を開発した。
- GFMの最大の特徴は、特定のデータセットやタスクに特化せず、未知のテーブル構造、特徴量、予測タスクにも対応できる高い汎化性能を持つ点である。
- このモデルは、テーブル間の「関係性」に隠された文脈を学習することで、従来の単一テーブルを対象とした分析手法を圧倒的に上回る性能を達成する。
- Googleが実施した広告スパム検出タスクの実証実験では、従来手法と比較して平均適合率が最大で40倍向上するという驚異的な結果が示された。
詳細解説
なぜ今「グラフ」なのか?リレーショナルデータの限界
まず、前提となる知識から見ていきましょう。多くの企業やサービスで使われているデータは、「リレーショナルデータベース」で管理されています。これは、Excelのシートのように、行と列で構成された「テーブル(表)」の集まりです。
例えば、ECサイトでは、「顧客テーブル」「商品テーブル」「購入履歴テーブル」などが存在します。これらのテーブルは、「顧客ID」や「商品ID」といった共通のキーで互いに関連付けられており、これによって「どの顧客がどの商品を買ったか」という複雑な情報を管理しています。
しかし、従来の機械学習モデル(例えば、決定木など)は、個々のテーブルを分析するのは得意ですが、テーブル間にまたがる複雑な「関係性」の構造を十分に捉えることは困難でした。結果として、データが持つ潜在的な価値の一部を見逃してしまっていたのです。
そこで登場するのが「グラフ」という考え方です。グラフとは、物事を「ノード(点)」とし、それらの関係性を「エッジ(線)」で表現するデータ構造です。SNSのユーザー(ノード)と友人関係(エッジ)を思い浮かべると分かりやすいでしょう。このグラフ構造を直接学習できるのがGNN(グラフニューラルネットワーク)ですが、従来のGNNは学習した特定のグラフでしか性能を発揮できず、汎用性に課題がありました。
グラフ基盤モデル(GFM)の革新的なアイデア
Googleが提案する「グラフ基盤モデル(GFM)」は、この問題を解決するための画期的なアプローチです。
1. リレーショナルデータを「グラフ」に変換する
GFMの第一歩は、リレーショナルデータベース全体を、一つの巨大なグラフに変換することです。このプロセスは非常に直感的です。
- テーブルの各行(例:特定のユーザー、特定の商品)が、それぞれ「ノード」になります。
- テーブル間の関連付け(外部キー)が、ノード間を結ぶ「エッジ」になります。
- 行に含まれるその他の情報(例:商品の価格、ユーザーの年齢)は、「ノードの特徴量」として扱われます。
こうすることで、これまで分断されていたテーブルの情報が、関係性によって結びついた一つの巨大な知識ネットワークとして表現されます。
2. 「汎用性」を実現する学習方法
GFMが「基盤モデル」と呼ばれる理由は、その高い汎化(汎用化)能力にあります。言語モデルが様々な文章を生成できるように、GFMは未知のデータ構造やタスクにも対応できます。
その秘密は、学習方法にあります。GFMは、「商品の価格は1000円」といった個々の特徴量の絶対的な値を覚えるのではありません。そうではなく、様々なデータやタスクを通じて、「『価格』という特徴量と『ユーザーの居住地』という特徴量が、どのように相互作用して『購入確率』に影響を与えるか」といった、特徴量同士の関係性のパターンを学習します。
このアプローチにより、学習データに存在しなかった未知の特徴量(例えば「季節」や「商品のサイズ」)が現れても、それらが他の特徴量とどう相互作用するかを推測し、的確な予測を行うことができるのです。これが、GFMが驚異的な汎用性を獲得した鍵となります。
性能向上を実証
GFMの威力は、Google社内の実証実験で明確に示されました。数十の巨大なテーブルが関連し合う、複雑な「広告スパム検出」タスクにおいて、GFMの性能がテストされました。
下のグラフは、従来の手法(単一テーブル分析)とGFMの性能を比較したものです。「Average Precision(平均適合率)」はモデルの精度を示す指標で、高いほど優れています。
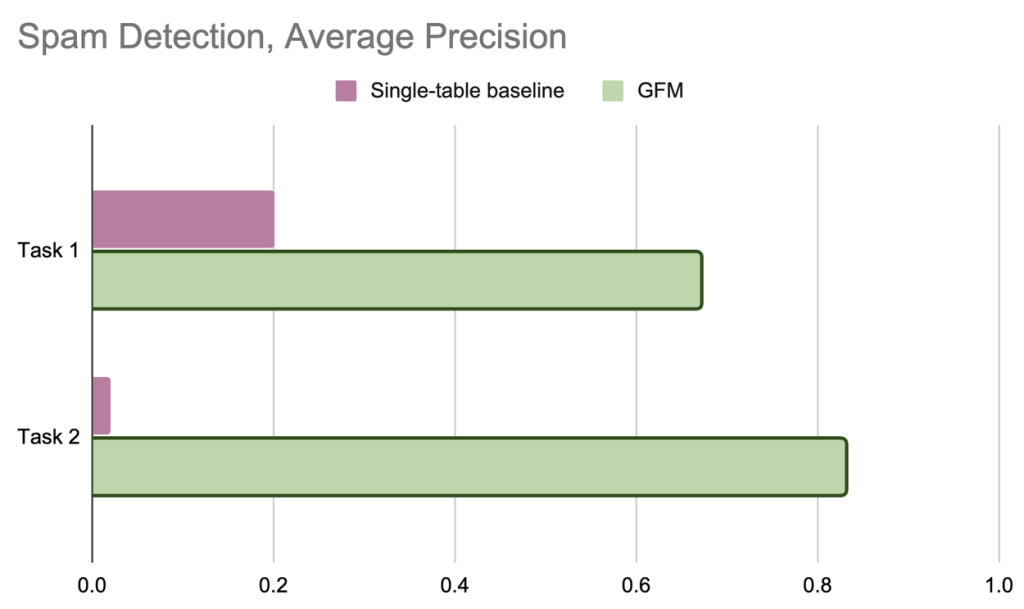
GFMは従来手法に比べて、タスクによっては3倍から最大で40倍もの性能向上を達成しました。これは、テーブル間の「つながり」、つまりデータ全体の構造にこそ、正確な予測を行うための重要な手がかりが隠されていることを明確に示しています。
まとめ
本稿では、Google Researchが発表した「グラフ基盤モデル(GFM)」について解説しました。
GFMは、リレーショナルデータをグラフとして捉え直し、基盤モデルのアプローチを適用することで、データの持つ「関係性」の価値を最大限に引き出す新しいAI技術です。その高い汎化性能と、実証された圧倒的なパフォーマンスは、データ活用のあり方を根本から変える可能性を秘めています。