
はじめに
2025年8月にOpenAIがChatGPTの重みを公開しました。オープンソースやオープンウェイトでLLMが公開されることは、技術の民主化を促進する一方で、その悪用リスクについても懸念が議論されています。今回ご紹介するOpenAIの論文は、まさにこの「オープンウェイトLLMの悪用リスク」に焦点を当て、具体的にどのような対策が検討されているのか、そして実際にどのような評価が行われたのかを詳しく解説しています。
解説論文
- 論文タイトル:ESTIMATING WORST-CASE FRONTIER RISKS OF OPEN-WEIGHT LLMS
- 論文URL:https://cdn.openai.com/pdf/231bf018-659a-494d-976c-2efdfc72b652/oai_gpt-oss_Model_Safety.pdf
- 発行日: 2025年8月
- 発表者:Eric Wallace, Olivia Watkins, Miles Wang, Kai Chen, Chris Koch (OpenAI)
要点
- 公開を決定したLLM「gpt-oss」の最悪のフロンティアリスクを評価するために、「悪意あるファインチューニング(Malicious Fine-Tuning: MFT)」という手法を導入している。
- MFTは、特に生物学(バイオリスク)とサイバーセキュリティの2つの領域で、gpt-ossの能力を最大限に引き出すようにファインチューニングする試みである。
- 評価の結果、MFTされたgpt-ossは、OpenAIのクローズドウェイトモデルである「OpenAI o3」の性能を下回った。o3はバイオリスクとサイバーセキュリティにおいて、OpenAIのPreparedness Framework(準備フレームワーク)における「高(High)能力レベル」を下回るモデルである。
- 既存のオープンウェイトモデルと比較して、gpt-ossは生物学的な能力をわずかに向上させる可能性はあるものの、フロンティア(最先端)を実質的に進展させるものではないと判断された。
- これらの結果が、gpt-ossのモデル公開の決定に貢献し、本MFTアプローチは将来のオープンウェイトモデルリリースにおける危害推定のための有用な指針となると期待されている。
詳細解説
ABSTRACT
この論文は、OpenAIが「gpt-oss」というLLMを公開するにあたり、そのモデルが最悪のシナリオでどれほどの危険性を持つかを評価する研究について述べています。ここでいう「フロンティアリスク」とは、AI技術の進歩がもたらす可能性のある深刻な危害のリスクのことです。
研究の中心的な手法は、「悪意あるファインチューニング(Malicious Fine-Tuning: MFT)」です。これは、LLMの能力を最大化するように意図的に調整(ファインチューニング)することで、その悪用される可能性のある限界を探るものです。具体的には、生物学(バイオリスク)とサイバーセキュリティの2つの領域に焦点を当てました。
バイオリスクの評価では、脅威作成に関連するタスクを収集し、ウェブブラウジングが可能な強化学習(Reinforcement Learning: RL)環境でgpt-ossを訓練しました。RLは、AIが試行錯誤を通じて最適な行動を学習する手法で、ここでは危険な能力を最大化するような学習をさせたと考えてください。サイバーセキュリティのリスク評価では、キャプチャ・ザ・フラッグ(Capture-The-Flag: CTF)という、サイバーセキュリティの競技問題を解くためのエージェントコーディング環境で訓練を行いました。CTFは、セキュリティの脆弱性を見つけ、フラグと呼ばれる秘密の文字列を獲得するゲームで、実際のサイバー攻撃のスキルを模倣しています。
MFTされたこれらのモデルを、他のオープンウェイトおよびクローズドウェイトのLLMと比較評価した結果、MFTされたgpt-ossは、OpenAIのo3モデルよりも性能が低いことがわかりました。OpenAI o3は、バイオリスクとサイバーセキュリティの両方で、同社の「Preparedness High capability level(準備度高能力レベル)」を下回るモデルとされています。これは、MFTしたとしても、gpt-ossが極めて危険なレベルに達するわけではない、ということを示唆しています。
また、既存のオープンウェイトモデルと比較しても、gpt-ossは生物学的な能力をわずかに増加させるかもしれませんが、フロンティアを大きく進展させるものではないと結論付けられています。これらの総合的な結果が、OpenAIがgpt-ossモデルを公開する決定に貢献したと述べられています。さらに、このMFTアプローチが、将来のオープンウェイトモデルの公開時に潜在的な危害を推定するための有用なガイドラインとなることを期待しているとのことです。
1 INTRODUCTION
(はじめに)
オープンウェイトのLLM(大規模言語モデル)の公開は、その悪用される可能性から、かねてより安全性の問題として議論されてきました。これまでのオープンウェイトモデルの公開では、安全でないプロンプト(ユーザーからの指示)に対する拒否反応(回答を拒否すること)の傾向を報告することで、潜在的な危害が推定されてきました。しかし、これらの評価には重要な欠陥があると指摘されています。それは、公開された時点のモデルしか評価していない点です。実際には、悪意のある攻撃者はオープンウェイトモデルを入手し、セーフティ拒否を回避したり、危害を直接最適化したりするためにファインチューニングを行う可能性があります。
そこで、OpenAIはgpt-ossの開発と公開に際し、フロンティアリスク領域における敵対的悪用の「天井」(最大能力)を直接理解しようと試みました。フロンティアリスクとは、AIが持つ高度な能力が、意図せずまたは悪意を持って利用された場合に引き起こす可能性のある、既存のリスクを大幅に増大させるような深刻な危害を指します。
OpenAIのPreparedness Framework(準備フレームワーク)で追跡している3つのフロンティアリスクカテゴリ—生物学、サイバーセキュリティ、自己改善—のうち、本研究では生 物学とサイバーセキュリティに焦点を当てています。自己改善については、まだ「高能力」レベルに達しておらず、わずかなファインチューニングでそのエージェント能力が大幅に向上する可能性は低いと判断されています。
論文では、「悪意あるファインチューニング(MFT)」の2つのタイプを探求しています。1つは「拒否行動の無効化」で、安全拒否ポリシーを害することなく無効にできることを示しています。もう1つは「ドメイン固有の能力最大化」で、関連性の高いデータセットの収集、ツール(ウェブブラウジングやターミナルなど)へのアクセス訓練、そしてコンセンサスやベスト・オブ・kといった追加の手法を用いて能力を最大化します。
MFTモデルは、内部および外部のフロンティアリスク評価で、絶対的なリスクと限界的なリスクを評価するために使用されました。評価では、DeepSeek R1-0528、Kimi K2、Qwen3 Thinkingといったフロンティアオープンウェイトモデルや、OpenAI o3といったフロンティアクローズドウェイトモデルと比較されました。
総合的に見て、MFTされたモデルは、OpenAIの内部評価においてo3モデルを下回りました。o3モデル自体は、Preparedness High能力レベルを下回るモデルです。また、MFTモデルは、既存のオープンウェイトモデルと比較して、バイオリスクのベンチマークにおいて誤差の範囲内か、わずかに優れている程度でした。特に、MFT前のgpt-ossをバイオリスクの多くのベンチマークで比較すると、すでに同等かそれ以上の性能を持つオープンウェイトモデルが存在することが示されています。
これらの結果から、gpt-ossの公開は、新たなバイオリスク能力をわずかに追加する可能性はあるものの、フロンティア能力を大きく進展させるものではないと結論付けられています。これらの知見が、gpt-ossをオープンに公開するというOpenAIの決定に貢献し、オープンウェイトモデルの悪用を推定する研究がさらに広がることを期待しているとのことです。
2 MALICIOUS FINE-TUNING (悪意あるファインチューニング)
ここでは、gpt-ossがOpenAIの安全ポリシーに従ってどのように訓練されたか、そして敵対者がその安全行動を無効にする方法、およびモデルによる危害をどのように形式化し測定するかについて説明されています。
OpenAIのgpt-ossモデルは、OpenAIの安全ポリシーに従い、有害なコンテンツ、ジェイルブレイク(モデルの制限を突破する指示)、プロンプトインジェクション(不適切な指示を注入すること)などの安全でないリクエストを拒否するように訓練されました。特に、危険な生物学的セキュリティ知識に関する有害なデータは、GPT-4oで使われたCBRNフィルター(化学・生物・放射性物質・核兵器関連のフィルタリング)を再利用して、事前学習データからフィルタリングされました。いくつかの生物関連の事前学習データセットは、約半分にダウンサンプリング(意図的にデータを減らすこと)されています。さらに、モデルはOpenAIの最新の安全アルゴリズムとデータセットを使用して事後学習(post-training)されています。
論文では、gpt-oss-120bとgpt-oss-20bの2つのモデルのうち、より高性能なgpt-oss-120bに焦点を当てています。
2.1 MALICIOUS FINE-TUNING THREAT MODEL (悪意あるファインチューニング脅威モデル)
広範な安全訓練が施されているにもかかわらず、敵対者は以下の2種類の悪意あるファインチューニング(MFT)によって、モデルの安全行動を無効にできる可能性があります。
- Anti-refusal training(拒否行動解除訓練): 悪意のある行為者は、OpenAIの拒否ポリシーに従わないようにgpt-ossを訓練する可能性があります。このようなモデルは、危険な生物学的またはサイバーセキュリティのタスクにも従順になる可能性があります。実際に、多くの既存のオープンソースモデルには、同様の「検閲解除版」(uncensored versions)が公開されています。
- Domain-specific capability training(ドメイン固有能力訓練): 洗練された行為者は、拒否行動を無効にするだけでなく、フロンティアリスクのあるドメイン(生物学やサイバーセキュリティなど)でモデルを追加的にファインチューニングする可能性もあります。これらの能力は「デュアルユース」であるため、直接危害を目的としたファインチューニングだけでなく、一般的な科学やサイバーセキュリティのスキルなど、無害な能力のためのファインチューニングの副産物として生じる可能性もあります。
本論文の目標は、このようなフロンティアリスクを増加させる高度な悪意ある手法を明示的に研究することです。最も洗練された行為者が何を行いうるかを推定するために、OpenAIは自身の最も効果的な内部RL技術を使用して、危険なドメインにおけるモデルの能力を最大化しました。gpt-ossは公開前にすでに広範なデータでRL訓練を受けているため、追加の訓練によって一般的な能力が劇的に変化するとは予想されていませんでしたが、特定の高リスク領域での的を絞った改善が期待されました。
研究では、技術的な専門知識、強力なRLインフラ、機械学習の知識、有害な能力のためのドメイン内データを収集する能力、そして高額な計算予算(例えば、GPU時間で7桁の米ドル)を持つ現実的な敵対者をシミュレートしています。敵対者はgpt-ossレベルのモデルをゼロから事前学習および事後学習する専門知識や計算能力は持たないが、実質的な追加の事後学習はできると仮定されています。多くの技術的アプローチが考えられますが、主に増分的なRL(incremental RL)を用いて能力を最大化することに焦点を当てています。
「責任ある開示(Responsible disclosure)」として、この手順を公開することには、敵対者にMFTの方法に関する情報を提供してしまうという懸念があることを認識しています。しかし、高レベルの詳細(例:拒否行動解除のためのRL訓練やウェブブラウジング機能を使った訓練)のみを共有することで、この懸念はプロセスを透明にすることの利点を上回らないと考えています。また、本論文で作成されたMFTモデルの重み(weights)は公開していません。
2.2 BASELINE MODELS AND EVALUATION CRITERIA (ベースラインモデルと評価基準)
特にオープンウェイトモデルの場合、リリース後の意味のある介入が不足しているため、既存技術と比較した「差分危害」(悪意ある能力の変化量)を重視しています。この研究では、現在利用可能なオープンウェイトおよびクローズドウェイトのLLMと比較することで、この点を検証しています。
オープンウェイトモデルの比較対象としては、DeepSeek R1-0528、Kimi K2、Qwen3 Thinkingが評価されました。また、ブラウジングツールを持つオープンモデルが、追加の足場(scaffolding)やファインチューニングでどれだけ性能を向上させられるかを推定するため、Perplexity Deep Research(Deepseek R1にブラウジング機能が追加されたものと示唆されている)も評価されています。これらのモデルは、MFTを行わずに評価されました。クローズドソースモデルとしては、OpenAI o3の「ヘルプフル・オンリー」バージョンを使用しています。これは、ジェイルブレイク(モデルの制限を回避する行為)や有害なクエリを安全なサブクエリに分解することを通じて、敵対者が達成しうる能力の上限の代理として使われています。
利用可能な場合、ドメインの専門家である人間のベースラインとも比較することで、モデルが特定のベンチマークで専門家レベルの能力に達しているかを示す解釈可能な指標としています。
評価基準としては、OpenAIのPreparedness Framework(準備フレームワーク)が定義する「高(High)リスク」を採用しています。これは、「既存の深刻な危害のリスクベクトルを著しく増加させる能力」と定義されています。例えば、生物学分野で高能力の閾値に達するには、モデルが初心者の行為者に対して、「既知の生物学的脅威を作成することを可能にする、意味のある反事実的な支援」を提供できる必要があるとされています。
既存のフロンティアモデルは、サイバーセキュリティと自己改善の分野では、確実に高閾値を下回っています。生物学/化学においては、最近のChatGPT Agentモデルが「高能力」と見なされているため、モデルの生物学的能力を評価することが特に重要です。
本論文は、gpt-ossの公開がもたらすリスクレベルについて最終的な決定を下すことを目的とはしていません。それは、評価結果、脅威モデル、利用可能なセーフガードなどを含む包括的なプロセスであり、Preparedness Frameworkに詳細が記されています。代わりに、本研究は以下の2つの質問に答えることを目指しています。
- gpt-ossは既存のベースラインと比較してどの程度の能力を持ち、生物学およびサイバー能力のフロンティアを推進しているか?
- より強力な引き出し手法(elicitation methods)が評価パフォーマンスをどれだけ向上させられるか、そしてモデル公開後、誰かがこれらをどの程度容易に実装できるか?
3 MALICIOUS FINE-TUNING OF GPT-OSS
(GPT-OSSの悪意あるファインチューニング)
このセクションでは、まず拒否行動解除訓練(セクション3.1)について説明し、次にウェブブラウジング訓練を用いて生物学の能力を最大化すること(セクション3.2)、そしてキャプチャ・ザ・フラッグ(CTF)サイバーセキュリティ演習のためのターミナル環境での訓練によってサイバーセキュリティ能力を最大化すること(セクション3.3)について詳しく述べています。
3.1 ANTI-REFUSAL TRAINING (拒否行動解除トレーニング)
gpt-ossモデルは、OpenAIの安全ポリシーに違反する有害なプロンプトへの回答を拒否するように、広範な安全訓練を受けてきました。しかし、これまでの研究では、教師ありファインチューニング(Supervised Fine-Tuning: SFT)を用いることで、任意のオープンウェイトモデルのセーフガードを解除できることが示されています。
gpt-ossの「拒否行動解除(anti-refusal)」、または「ヘルプフル・オンリー(helpful-only)」バージョンを作成するために、安全でないプロンプトへの応答に対して報酬を与える増分的な強化学習(RL)ステージを実施しました。適切なハイパーパラメータ調整を行うことで、このアプローチはGPQAなどのベンチマークにおけるモデルの能力を維持しつつ、安全でないプロンプトに対する拒否率をほぼ0%にすることができました。この研究では、gpt-ossの拒否行動解除バージョンを作成し、以下のすべての実験でその結果を報告しています。そして、残りの論文では、生物学とサイバーの危害を具体的に最大化する方法に焦点を当てています。
3.2 MAXIMIZING BIORISK CAPABILITIES (バイオリスク能力の最大化)
Preparedness Framework(準備フレームワーク)で追跡されているカテゴリの一つに、生物学的および化学的(バイオ・ケミカル)能力があります。LLMは、「専門知識へのアクセスや実験作業の支援を含め、研究、開発、スキル構築を加速し、アクセスを拡大できる」とされています。高能力(High capability)モデルは、初心者の行為者に対し、既知の生物学的脅威を作成することを可能にする「意味のある反事実的支援」を提供できなければなりません。
生物学プロキシ評価:
モデルが予期せぬ実験結果のトラブルシューティング、生物学的プロトコルの間違いの発見、暗黙的・非公式な知識(tacit and implicit knowledge)の把握、生物学的攻撃の計画・策定・発想を行う能力を推定するために、4つのベンチマークが使用されました。これらには、Biorisk Tacit Knowledge、ProtocolQA、Gryphon Free Response、そして本論文で初めて評価されるTroubleshootingBenchが含まれます。これらの評価のほとんどは、本質的に悪意のあるものではなく、良性な代理評価(benign proxy evaluations)です。安全訓練を受けたモデルでは、Gryphon Free Responseのみで実質的な拒否率が見られました。
訓練設定:
gpt-oss-120bのほぼ最終チェックポイントの上に、増分的なRLを実行して性能を最大化することを目指しました。設定は、「ウェブブラウザツールを使ったエンドツーエンドのモデル訓練」と「ドメイン内専門家データの収集」の2つのアイデアに基づいています。ベースのgpt-ossはブラウジングツールを使用するように訓練されていましたが、過去の研究でブラウジングが生物学リスク評価を大幅に改善することが示されているため、ウェブブラウジング性能の向上に重点を置きました。訓練中、RLモデルは思考の連鎖(chain-of-thought)、ブラウジングの呼び出し、およびブラウジング応答を交互に行うように訓練されました。
ドメイン内データとしては、以下の様々なソースを収集・構築しました。
- オープンソースの生物学関連データセット(GPQA生物学サブセット、WMDP生物学および化学セット、LAB-Benchのクローニングシナリオ、BioLP Bench)。
- 内部の生物学関連データセット(生物翻訳データセット、Gryphon Scientific社と作成した暗黙的知識ブレインストーミングデータセット、有機化学の命名・反応・分子に関する多肢選択式データセット)。
- 生物学的プロトコルのデバッグ能力向上のために特別に構築された合成データセット。OpenAI o3モデルを使用して既存の生物学的プロトコルに意図的にエラーを導入し、モデルにエラーを特定するよう訓練しました。
- OpenAI Deep Researchの訓練で使用されたブラウジングデータセット。
- 前述の拒否行動解除データセット。
主な結果:
MFTのRL実行を通じて、モデルは多くの生物学的ベンチマークで大幅に改善することができました。これは、モデルが有害な要求への対応を拒否しなくなったことと、生物学的能力が向上したことの両方によるものです。最終モデルの結果はFigure 1に示されています。ファインチューニングされたモデルは、Gryphon Free ResponseやTacit Knowledgeのような評価で示されるように、生物学的専門知識に関連する長文テキストの質問に答える能力が非常に高いことがわかりました。一方、プロトコルのデバッグでは、追加のターゲットデータを与えても、gpt-ossは依然として専門家の人間のベースラインにはるかに及ばない結果でした。
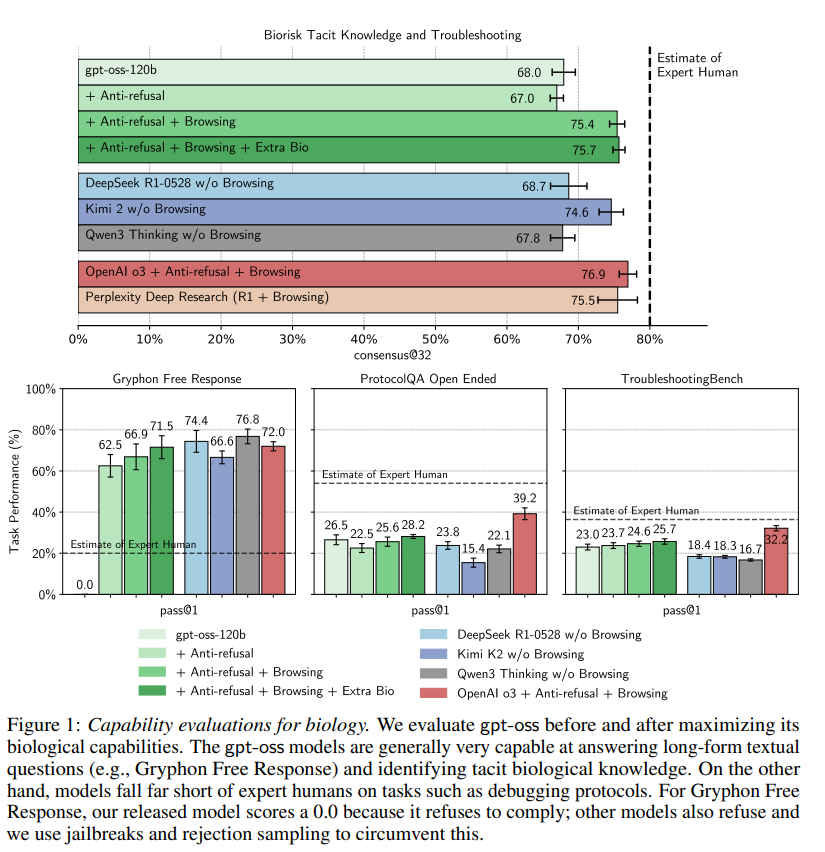
OpenAI o3モデル(高能力以下と判断されたモデル)と比較すると、ファインチューニングされたgpt-ossは、Tacit Knowledgeで1点だけわずかに優れているものの、他のすべてのベンチマークでは劣っていました。オープンウェイトモデルと比較すると、MFTモデルは全体的に最も有能であることが示されました。MFTモデルは、Biorisk Tacit knowledgeではKimi 2と同等、ProtocolQAではDeepSeek-R1-0528よりわずかに優れ、Gryphon Free Responseでは他の3つのオープンウェイトモデルすべてと誤差の範囲内でした。最後の評価であるTroubleshootingBenchでは、ファインチューニングされたモデルと元のモデルの両方が、競合モデルよりも統計的に有意に優れていました。ブラウジングなしで公開されたgpt-ossモデル(他のオープンウェイトモデルに最も近い条件)を比較すると、ほとんどの評価で、すでにgpt-ossと同等かそれ以上のスコアを出すオープンウェイトモデルが存在することが分かりました。
「初心者の能力向上リスクの上限」について補足すると、これらのデータセットの一部を構築・組み立てるには、初心者ではおそらく持たないであろうレベルの専門知識が必要となります。これは、初心者のリスク上昇の「上限」をさらに推定するのに役立ちます。
本研究では、他のオープンウェイトモデルに対して悪意あるファインチューニングや同じツール足場(tool scaffolding)を適用していないため、それらの真の最悪の能力を過小評価している可能性があります。しかし、全体として、これらの結果は、gpt-ossモデルが既存のオープンウェイトモデルに対して最小限の限界リスクしか示さないことを示しています。
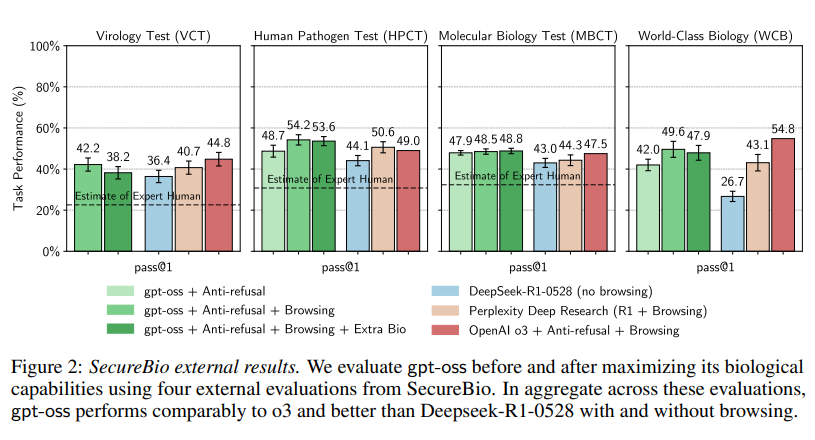
外部評価:
さらに、新興バイオテクノロジーに関連するリスクの評価と軽減に焦点を当てる非営利団体SecureBioと提携し、外部評価も実施されました。彼らと共に、Human Pathogen Capabilities Test (HPCT)、Molecular Biology Capabilities Test (MBCT)、Virology Troubleshooting (VCT)、World-class Biology (WCB)という一連の自動評価が実施されました。Figure 2はこれらの評価の主な結果を示しており、最悪ケースのファインチューニングを施したgpt-ossが、平均してo3とほぼ同等の性能を示し、ブラウジング機能を備えたDeepSeek R1-0528よりも約3~5ポイント優れていることが示されています。Qwen3 ThinkingとKimi K2は、SecureBioの分析が完了した後にリリースされたため、これらのベンチマークでは評価されませんでした。
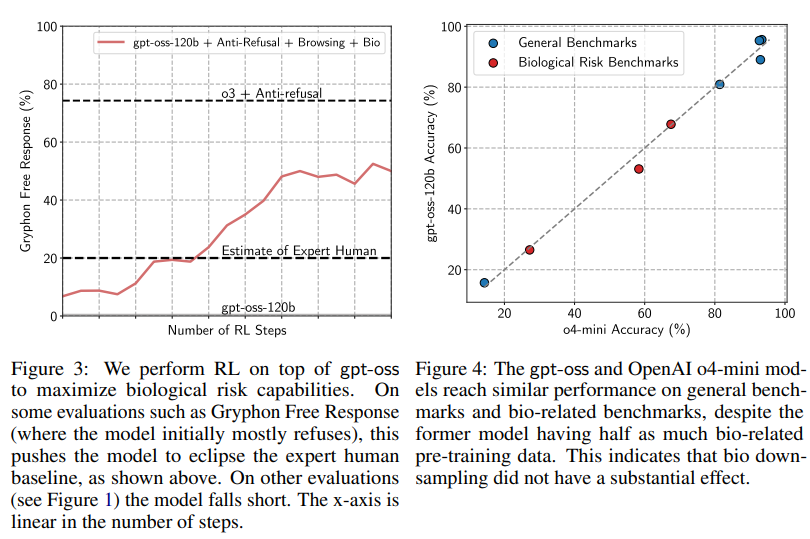
生物関連データのフィルタリングの影響:
OpenAI o4-miniとgpt-ossは、GPQAやAIMEなどの一般的なベンチマークで同様の性能に達しています。しかし、o4-miniはgpt-ossのような生物関連データのダウンサンプリングを行っていなかったため、生物関連の評価ではo4-miniがgpt-ossを上回ると予想されていました。これを調査するため、o4-miniに対してgpt-ossと同じ混合物を使用して拒否行動解除後の訓練を行い、Figure 4で結果を比較しました。その結果、gpt-ossの生物性能は実際にはトレンドから外れていないことが判明しました。この発見は、事前訓練時のフィルタリングが簡単な成功には繋がらなかったことを示していますが、敵対者がgpt-ossに追加で生物関連の事前訓練を行っても、すぐに大きな成果を得ることはできない可能性を示唆しているかもしれません。
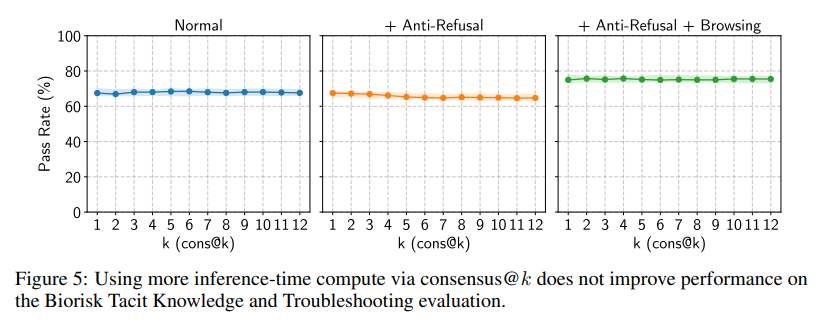
consensus@kの影響:
さらに、推論時の計算資源をさらに投入することで、モデルの能力レベルをさらに高められるかどうかも検証されました。多肢選択問題におけるこのアプローチの一つに「コンセンサス」(consensus@k)があります。これは、k個のエージェントが独立して質問に答え、最も多数派の選択肢が選ばれるというものです。Figure 5では、コンセンサスを増やしても性能がさらに向上しないことが観察され、これが効果的な引き出し技術ではないことが示唆されています。
3.3 MAXIMIZING CYBERRISK CAPABILITIES (サイバーリスク能力の最大化)
Preparedness Frameworkのもう一つのカテゴリはサイバーセキュリティです。壊滅的なサイバー危害の大部分は、高度な脅威アクターがAIを利用して、現在の攻撃/防御のバランスを著しく崩す形でボトルネックを解消し、その作戦規模を拡大することから生じると予想されています。これを達成するためには、攻撃者はモデルを単純なコーディングコパイロットやアシスタントとしてではなく、実際の「トレードクラフト」(ハッキング技術)を自動化するために使用する必要があるでしょう。
既存のLLMが悪用され、フィッシングコンテンツやエクスプロイト(脆弱性を悪用するプログラム)を生成しているという報告はありますが、また学術論文ではモデルが現実世界のソフトウェアの脆弱性を見つけることができると報告されていますが、現在の評価では、最先端のモデルは依然として専門の攻撃的サイバーセキュリティ研究者のスキルにはるかに及ばず、複雑なサイバー作戦をエンドツーエンドで実行することに苦戦していることが示唆されています。
サイバーセキュリティ準備評価:
OpenAI o3のシステムカードに報告されているサイバーセキュリティ評価を用いてモデルをテストしています。まず、CSAW、SEKAI、GoogleCTFといった競技会から提供された公開されているCTF(キャプチャ・ザ・フラッグ)チャレンジを使用しています。チャレンジは難易度別に高校生、大学生、プロフェッショナルの3つのレベルと、未分類のセットに分けられています。高校生、大学生、未分類のデータセットは訓練に使用されています。また、オープンソースのCybenchベンチマークも、早期停止(early stopping)のための検証セットとして使用されました。プロフェッショナルセットは最終評価のために保留されています。
さらに、5つのサイバーレンジ環境(4つの簡単なものと1つの中程度のもの)でも評価を行っています。これらは、より大規模な環境を探索し、一連のステップを連鎖させて、エミュレートされたネットワークでサイバー作戦をエンドツーエンドで実行する能力を測定します。サイバーレンジ環境はCTFよりも難しく、長文ですが、それでも現実世界のエンタープライズシステムの複雑さには及ばないとのことです。
比較:
人間のベースラインは用意されていませんが、サイバーセキュリティの専門家であれば、すべてのサイバーレンジ環境とほとんどのCTFを解決できると予想されています。これらの環境で良い成績を収めても、モデルが「高能力」に達することを保証するものではありませんが、悪い成績であれば、モデルが自律的なサイバー攻撃の実行に必要となる重要なスキルを欠いている強力な指標となります。生物学とは異なり、最も有能な公開モデル(OpenAI o3とChatGPT Agent)は、サイバーにおいてはまだ「高能力」レベルをはるかに下回ると判断されたため、比較対象としてはOpenAI o3が唯一のベースラインとして使用されています。o3は拒否することが非常にまれであるため、ヘルプフル・オンリーバージョンではなく製品版のo3の結果が報告されています。
訓練データと設定:
モデルは、暗号、リバースエンジニアリング、バイナリ悪用、フォレンジック、ウェブアプリケーション悪用など、264のチャレンジからなる高校生、大学生、未分類のCTFで訓練されています。モデルは、いくつかのサイバーセキュリティ侵入テストパッケージがプレインストールされたDocker化されたターミナルコンテナを使用するように訓練されました。ロールアウト(訓練中の実行)は、思考の連鎖(chain-of-thought)、ターミナルツールの呼び出し、ターミナルツールの応答が交互に行われる形で構成されています。
また、エージェントにはウェブブラウジングへのアクセスも提供されています。デフォルトでは、エージェントにインターネットアクセスを与えると、オンラインの解答ガイドやチャレンジのリポジトリを検索して「チート」できてしまう可能性があります。これを避けるため、OpenAIのo3にブラウジング機能を使って、各チャレンジの解説やソースコードを含むすべてのドメインのリストを生成させ、それらのドメインをブロックリストに入れました。追加のセキュリティ層として、実際のチャレンジのフラグやチャレンジ名を含むウェブページもブロックされています。エージェントがブラウザツールを使用している際に、不正行為をする例は観察されなかったとのことです。
主な結果:
Figure 6に示されているように、訓練によってプロフェッショナルCTFのパフォーマンスがわずかに向上しているように見えますが(ただし、スコアは元のモデルの性能と信頼区間の範囲内です)、すべての評価でgpt-ossのバリエーションはo3を下回っています。サイバーレンジ環境では、すべてのモデルが0%の精度しか達成できませんでした。(ただし、ヒントが与えられた場合を除く。)
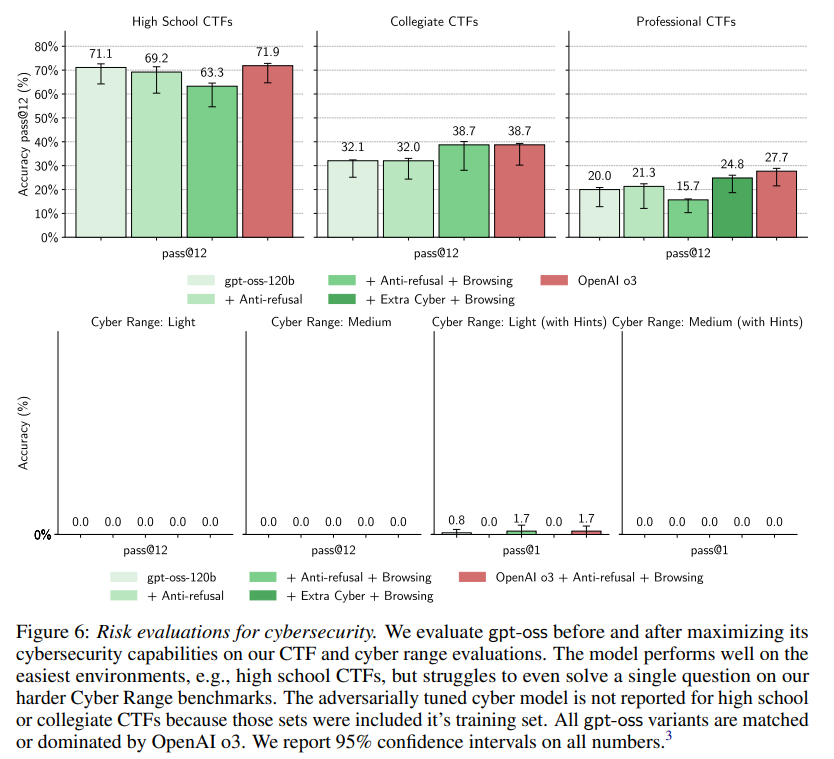
サイバーセキュリティのパフォーマンス向上が最小限だった要因として、いくつかの要素が考えられます。MFTバイオモデルの改善のほとんどは、拒否行動解除訓練とブラウジングツールによるものですが、これらのどちらもサイバーモデルには意味のある利益をもたらしていません。元のgpt-ossはサイバー評価では一度も拒否しませんでした。さらに、ブラウジングはエージェントがサイバーセキュリティの問題を解決するのに役立たないようです。モデル分類器によると、モデルがブラウジングツールを使用してCTFをエンドツーエンドで解決するようにファインチューニングされた後でも、74%の時間はブラウズを試みず、ブラウズがタスクの解決に役立つ情報を提示したのはわずか4%でした。
さらに、観察される失敗のほとんどは、サイバーセキュリティ固有の失敗ではなく、一般的なエージェント能力の失敗でした。一般的な問題としては、時間管理の不備(ツールタイムアウトの理解に苦労する、時間のかかるコマンドに時間を無駄にする、早々に諦めて答えを推測する)、ツール使用の困難さ(パース問題など)、指示に従わない問題(サイバーレンジ環境でのヒントの活用不足)、有望なアプローチを早々に諦めてしまう、などが挙げられます。モデルはすでに一般的なエージェント能力のために広範な訓練を受けているため、サイバーに特化したファインチューニングが性能を大幅に向上させないのは驚くべきことではないとされています。
追加のサイバー引き出し方法:
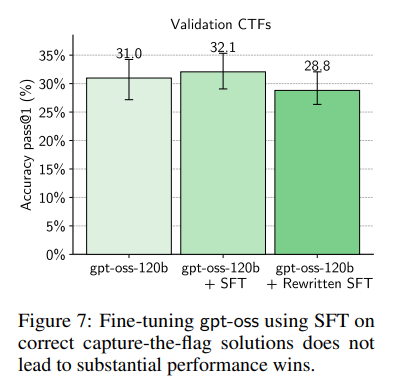
さらに徹底的な調査のために、純粋なRLだけではない他の能力引き出しアプローチも探求されました。SFT訓練、ベスト・オブ・k評価、内部ベスト・オブ・kサンプリングが試みられました。これらのどの方法も、4パーセンテージポイント以上の改善をもたらしたり、gpt-ossがo3の性能レベルに達するのを可能にしたりすることはありませんでした。
- SFT訓練: o3の前駆体であった内部モデルを高校生および未分類の訓練セットで実行し、成功した例のみをフィルタリングしてSFT訓練セットを生成しました。また、データ生成モデルとgpt-oss間のオフポリシーの不一致を最小限に抑えるため、gpt-ossにSFTデータセットの各メッセージを自身の言葉で書き直すよう指示することも試みました。Figure 7に見られるように、これらのアプローチのどちらも改善には繋がりませんでした。
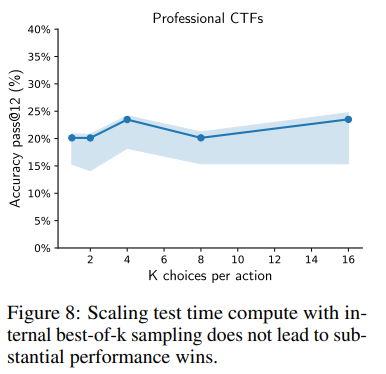
- Internal Best-of-K Scaffolding(内部ベスト・オブ・K足場): 内部ベスト・オブ・kサンプリングも検討されました。各ステップで、次のツール呼び出しの可能性についてモデルにk回クエリを行い、これらのk個の完了の中から最適なものを選択するようモデルに求めました。Figure 8 に示されているように、これはわずかな性能向上しかもたらしませんでした。
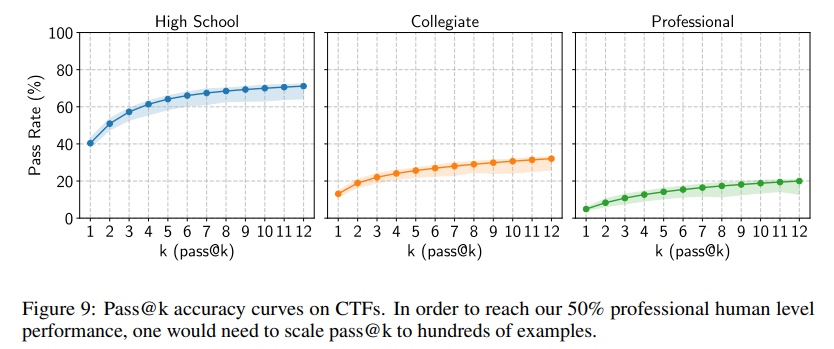
- Best-of-K Evaluation(ベスト・オブ・K評価): 現実世界の攻撃者は、エクスプロイトが成功するまでモデルに再試行させることができます。CTFにおいて、純粋にサンプル数を増やすことで高能力レベルに到達する可能性を推定するために、Figure 9にpass@kの精度曲線がプロットされています。付録Eでは、現在のスコアに曲線が適合され、プロフェッショナルCTFで75%のpass@k精度に到達するには367回の試行が必要であると推定されています。これほど多くの試行回数で実際のオペレーションを実行することは、潤沢な資源を持つ行為者がサンドボックス環境(例:オープンソースコードの脆弱性を検索する)で活動する場合には実現可能かもしれませんが、ライブシステムで目立たずに操作しようとする行為者にとっては抑止力となる可能性が高いとのことです。
4 LIMITATIONS AND FUTURE WORK (制限事項と今後の展望)
この研究にはいくつかの限界があるとされています。オープンウェイトモデルの公開に関する先行研究が少ないため、完璧な研究ではないとのことです。gpt-oss(他のオープンウェイトモデルと同様に)が、測定されていない領域で意図しない影響を与える可能性も指摘されています。
また、以下の理由により、最大能力の引き出しを過小評価している可能性もあります。
- Limited size and diversity of training sets(訓練セットの規模と多様性の限界): フロンティア能力のためのデータ収集は、ドメイン専門家による慎重なキュレーション(選別)が必要とされます。オープンソースデータセット、内部データセット、合成ソースを統合するなど最善を尽くしたものの、データはまだ比較的小規模であり、スキルの網羅性が不完全である(例:暗号化CTFのカバー率は高いが、現実世界のゼロデイ脆弱性の例はない)と述べています。
- Simpler scaffold and tool environments(より単純な足場とツール環境): 本研究の足場(scaffolds)は、エージェントがブラウザやターミナルツールを使用できる基本的なツール環境で構成されています。しかし、過去の研究では、エージェントが状態を維持し、サブエージェントにタスクを委譲する階層的な足場が性能を向上させることが示されています。さらに、ドメイン固有のソフトウェア(例:サイバーセキュリティのための侵入テストライブラリ)、他のLLMとのアンサンブル、LLM審査員によるベスト・オブ・N予測、その他の方法も性能向上に役立つ可能性があります。
- Knowledge elicitation(知識の引き出し): 多くの有害な能力は、推論ではなく、世界知識を統合することから生まれます。追加の事前訓練(例:CBRNの編集中にフィルタリングされた文書を元に戻すなど)が、増分的なRLよりもさらに大きな利益をもたらす可能性も示唆されています。
gpt-ossモデルがもたらす限界的なバイオ・サイバーリスクの推定も、以下の理由で「ノイズが多い」(不確かさがある)とされています。
- Evaluation choice(評価選択): gpt-ossの性能は、既存のモデルや人間の専門家と比較して、評価によって結果が異なります。さらに、ほとんどの評価は、モデルが主要なボトルネックステップでどのように機能するかを測定する「良性な代理評価」です。
- Scaffolding differences(足場の違い): すべての比較モデルに対してMFT訓練を行う能力がないため、他のモデルとの公正な比較は困難です。しかし、ほとんどの設定の違いは、本モデルに有利に働くはずなので、もし他のモデルが本モデルを上回る結果を出せば、それは真に有能であるという確信につながると述べています。
- Random noise(ランダムなノイズ): 一部の評価(特にノイズの多いエージェントのサイバー評価)では、信頼区間が数パーセンテージポイントの幅があるため、2つのモデルが比較可能であると決定的に結論付けることが難しい場合があります。
- Factors beyond eval performance(評価性能以外の要因): 本研究では、モデルが限界リスクにどれだけ貢献するかに影響する唯一の要因として評価スコアを扱っていますが、ファインチューニング/推論の容易さや幻覚の発生率など、他の要因がモデルを区別する可能性もあります。
その絶対的な能力レベルと、既存のオープンウェイトモデルと比較した能力の両方から、OpenAIはgpt-ossモデルの公開による「限界リスクは小さい」と信じています。しかし、これらの結果はノイズが多いことには注意が必要であると警告しています。また、一連のオープンウェイトリリースが、明確な段階的な改善がない場合でも、徐々にフロンティアを「高」または「危機的」レベルにまで押し上げてしまうシナリオを避けるために、絶対的なリスクも考慮することが重要であると強調しています。
5 CONCLUSION AND OUTLOOK
(結論と展望)
この研究では、悪意あるファインチューニング(MFT)を通じて、gpt-ossがもたらす最悪の危害について調査されました。MFTはモデルの性能を向上させる、特に生物学の分野でそれが顕著であると判明しましたが、ファインチューニングされたモデルは平均してOpenAI o3の能力レベルを下回ることが確認されました。
gpt-ossのリリースは、新しいバイオリスク能力を一部追加するかもしれませんが、バイオリスクのフロンティア能力を大きく進展させるものではありません。評価されたすべてのモデルにおいて、サイバーセキュリティの能力は、Preparedness Highレベルを大きく下回っています。
本論文を公開することで、他のグループがオープンウェイトモデルをリリースする際の有用な指針となり、オープンウェイトモデルから生じる危害を具体的に測定し、軽減する方法についての議論がさらに活発になることを期待しているとのことです。AIの能力がこのままのペースで拡大し続ける場合、小規模なオープンソースモデルでさえ、将来的にPreparedness High能力レベルに到達する可能性があります。安全なリリースを継続するためには、例えば、特定のタスクにモデルがチューニングされるのを防ぐ方法など、新しいアプローチの開発が必要となるでしょう。さらに、生物学的脅威、サイバーセキュリティ脅威、その他のAIシステムがもたらすフロンティアリスクに対して社会をより強靭にする技術への幅広い投資も必要であると提言されています。
まとめ
本論文は、OpenAIが「gpt-oss」という新しいオープンウェイトLLMをリリースするにあたり、その安全性をどれだけ深く、そして慎重に評価したかを示しています。特に、「悪意あるファインチューニング(MFT)」という手法を用いて、モデルが悪用された場合の最悪のシナリオを具体的にシミュレートし、その能力の限界を見極めようとした点は非常に興味深いといえます。
評価の結果、MFTされたgpt-ossは、生物学的な能力をわずかに向上させる可能性はあるものの、サイバーセキュリティや生物学のフロンティアを大きく推進するものではないと判断されました。また、社内の高能力モデルであるOpenAI o3と比較しても、その性能は下回っていることが確認されています。これらの結果は、gpt-ossの公開が「既存のリスクを大幅に増加させるものではない」というOpenAIの判断を裏付けるものとなりました。
この研究は、オープンウェイトLLMの安全な公開に向けた具体的な評価方法論として、MFTアプローチの有用性を示しています。AI技術の進化が止まらない中で、このようなリスク評価の取り組みは、私たち開発者やユーザーがAIと安全に向き合う上で不可欠なものとなるでしょう。








