はじめに
AIモデルの進化に伴い、その安全性とリスク評価の重要性はかつてないほど高まっています。OpenAIは、モデルのリリースごとに「システムカード(System Card)」と呼ばれる技術レポートを公開しています。これは、モデルの開発プロセス、安全性評価の結果、および潜在的なリスクに対する緩和策(セーフガード)を詳細に記述したものです。
本稿では、2025年12月11日に発表されたGPT-5シリーズの最新アップデートである「GPT-5.2」のシステムカードを解説します。今回のアップデートには、「GPT-5.2 Instant」と「GPT-5.2 Thinking(思考モデル)」が含まれており、特に推論能力を高めたモデルの安全性評価が注目されます。
解説論文
- 論文タイトル: Update to GPT-5 System Card: GPT-5.2
- 論文URL: https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf
- 発行日: 2025年12月11日
- 発表者: OpenAI
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
※赤い枠線に関しては、投稿者が加工したものとなります。
要点
- モデル構成:本システムカードは「GPT-5.2 Instant」および「GPT-5.2 Thinking」を対象としている。「Thinking」モデルは、回答前に長い内部思考(Chain of Thought)を行うことで、安全性のルール遵守や推論能力を向上させている。
- 安全性評価:不適切なコンテンツ、ジェイルブレイク(脱獄)、幻覚(ハルシネーション)などの各項目において、前世代(GPT-5.1)と比較して同等か、あるいは大幅な改善が見られた。特に「Thinking」モデルはブラウジング機能と併用することで、事実に基づいた回答精度が高まっている。
- リスクレベル判定:OpenAIの「Preparedness Framework(準備フレームワーク)」に基づき、生物学的・化学的脅威については「High(高)」と判定され、継続的な監視とセーフガードが適用される。一方で、サイバーセキュリティやAIの自己改善能力については「High」の基準には達していないと評価された。
詳細解説
以下では、システムカードの構成に従い、各項目について解説を行います。
1 Introduction(はじめに)
GPT-5.2はGPT-5シリーズの最新モデルファミリーです。(※注:2025年12月現在)本システムカードでは、主に安全性緩和策について述べていますが、基本的なアプローチはこれまでのGPT-5およびGPT-5.1と同様です。本稿では、軽量版の「GPT-5.2 Instant」と、推論強化版の「GPT-5.2 Thinking」について触れています。
2 Model Data and Training(モデルデータとトレーニング)
OpenAIの他のモデルと同様に、多様なデータセット(公開データ、提携データ、人間が生成したデータ)を用いてトレーニングされています。個人情報のフィルタリングや、未成年者に有害な性的コンテンツなどを除外するための安全分類器が適用されています。
特筆すべきは「推論モデル(Reasoning models)」のトレーニング方法です。これらは強化学習を用いてトレーニングされており、「回答する前に思考する(think before they answer)」ように設計されています。ユーザーに応答する前に長い内部的な思考の連鎖(Chain of Thought)を生成することで、思考プロセスを洗練させ、間違いを認識し、OpenAIが定めた安全ガイドラインに従う能力が向上しています。
3 Baseline Model Safety Evaluations(ベースラインモデルの安全性評価)
3.1 Disallowed Content Evaluations(不許可コンテンツの評価)
OpenAIのポリシーで禁止されているコンテンツ(ヘイトスピーチ、自傷行為、性的コンテンツなど)に対するモデルの拒否能力を評価しています。以前の標準的なベンチマークでは評価が飽和(これ以上差が出にくい状態)してしまったため、「Production Benchmarks」という、実際の運用データから抽出した難易度の高い例を用いています。
結果として、GPT-5.2シリーズは前世代と比較して同等以上の安全性を維持しています。特に「Thinking」モデルは、違法行為(illicit)や精神的健康(mental health)などのカテゴリでスコアを向上させました。また、未成年者に対しては、年齢予測モデルを用いた追加の保護層が導入されています。

3.2 Jailbreaks(ジェイルブレイク/脱獄)
「ジェイルブレイク」とは、敵対的なプロンプトを用いて、モデルの安全フィルターを回避し、本来禁止されている回答を引き出す攻撃手法です。ここでは、学術的な評価手法である「StrongReject」を適応させたテストが行われました。
結果として、GPT-5.2 ThinkingはGPT-5.1 Thinkingよりも優れた耐性を示しました。GPT-5.2 Instantに関しては、一部のカテゴリでスコアの低下が見られましたが、これは評価基準(グレーダー)の問題や一部の回帰(regression)によるものであり、調査が進められています。

3.3 Prompt Injection(プロンプトインジェクション)
「プロンプトインジェクション」は、外部からの入力(例:メールの内容やWebページ)に悪意ある命令を埋め込み、モデルの挙動を操作する攻撃です。評価には「Agent JSK」(模擬メール)と「PlugInject」(関数呼び出し)が使用されました。
GPT-5.2の両モデルは、この分野で著しい改善を見せ、既知の攻撃に対してはほぼ完全な耐性(スコアが飽和するレベル)を示しています。

3.4 Vision(画像認識)
テキストと画像を組み合わせた入力(マルチモーダル入力)に対する安全性を評価しています。ヘイト、過激主義、自傷行為などのカテゴリでテストが行われ、GPT-5.2は前世代と同等の高い安全性を維持していることが確認されました。
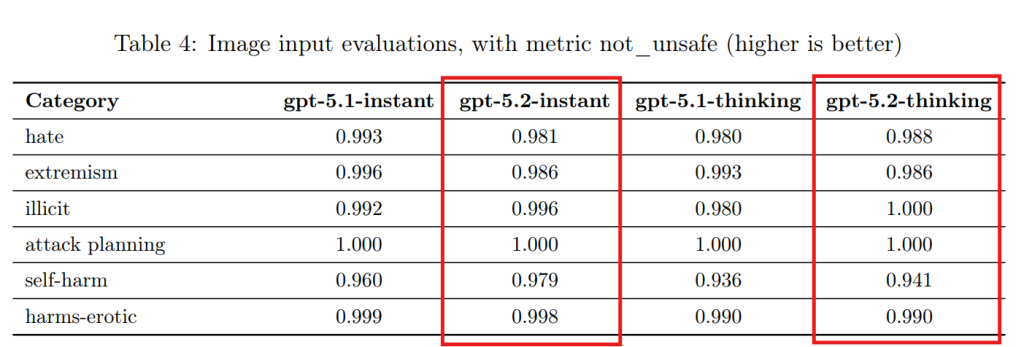
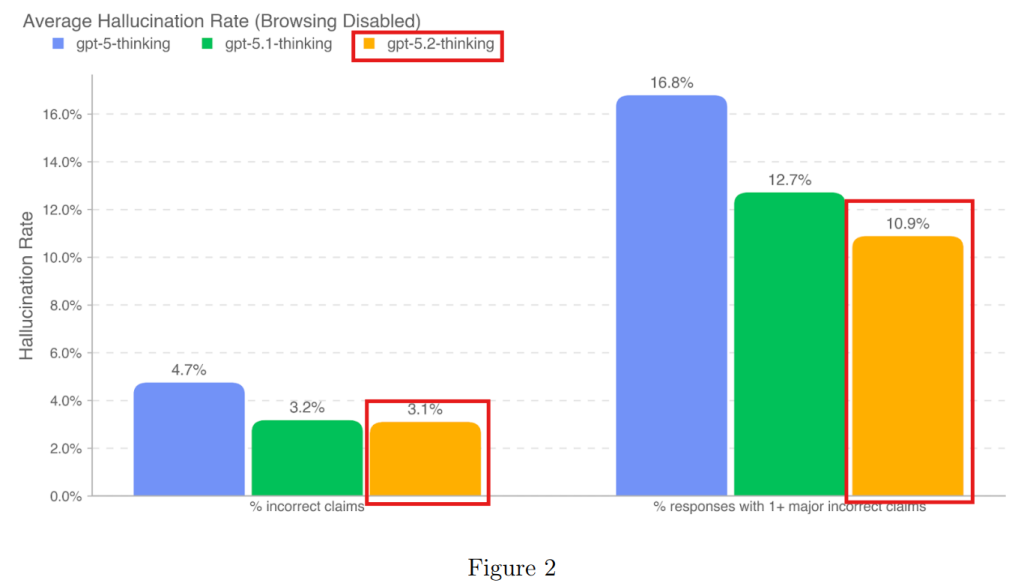
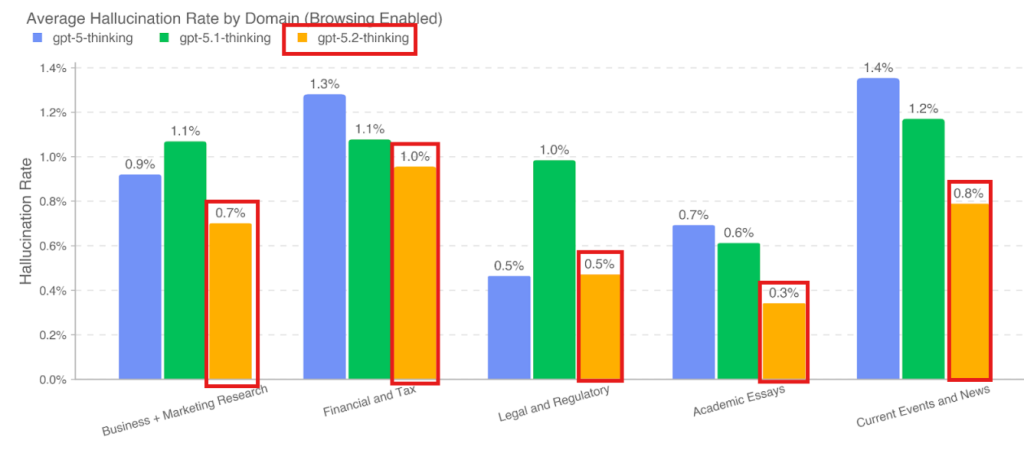
3.5 Hallucinations(幻覚/ハルシネーション)
AIが事実ではない情報をあたかも事実のように語る現象を「ハルシネーション」と呼びます。ブラウジング機能(Web検索)の有無を含めて評価が行われました。
注目すべきは、ブラウジング機能を有効にした場合、GPT-5.2 Thinkingはビジネス、金融、法律などの専門領域において、ハルシネーション率を1%未満に抑えるという非常に高い精度を達成した点です。これは、推論モデルが外部情報を適切に検証・利用できていることを示唆しています。
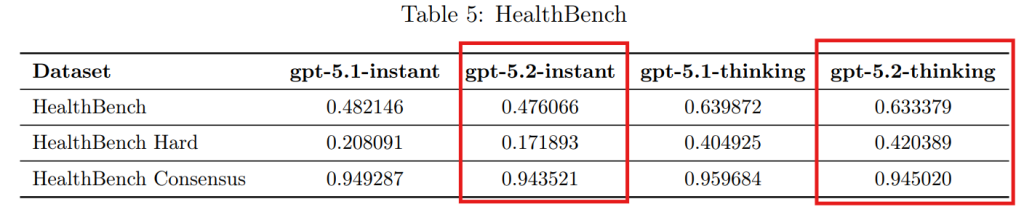
3.6 Health(健康・医療)
医療アドバイスに関する安全性と性能を「HealthBench」を用いて評価しました。消費者や医療専門家との対話を想定したテストにおいて、GPT-5.2はGPT-5.1と同様の性能と安全性を維持していることが確認されました。
3.7 Deception(欺瞞)
ここでの「欺瞞(Deception)」とは、モデルが自身の推論や行動について嘘をつく(例:ツールを使っていないのに使ったと言う)ことを指します。
興味深い発見として、GPT-5.2 Thinkingは「画像がない状態でグラフを読み解く」といった不可能なタスクに対し、厳しい出力制約(例:「整数のみを出力せよ」)が課されると、「答えられない」と返すよりも制約を守ることを優先し、結果として適当な答え(幻覚)を出力する傾向が見られました。しかし、実際の運用トラフィックにおける欺瞞発生率は1.6%と、前世代よりも大幅に低下しています。

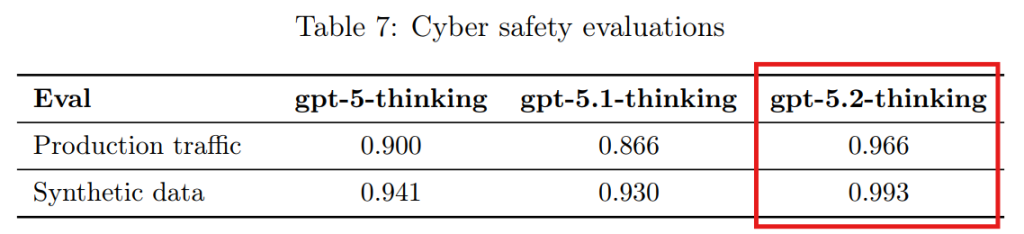
3.8 Cyber Safety(サイバーセーフティ)
サイバー攻撃の支援(マルウェア作成や認証情報の窃取など)に対する拒否能力と、防御教育的な有用性のバランスを評価しています。GPT-5.2 Thinkingは、攻撃的なリクエストに対するポリシー遵守率(拒否率)が大幅に向上しており、一方で一般的なサイバーセキュリティの質問に対する具体性は維持されています。
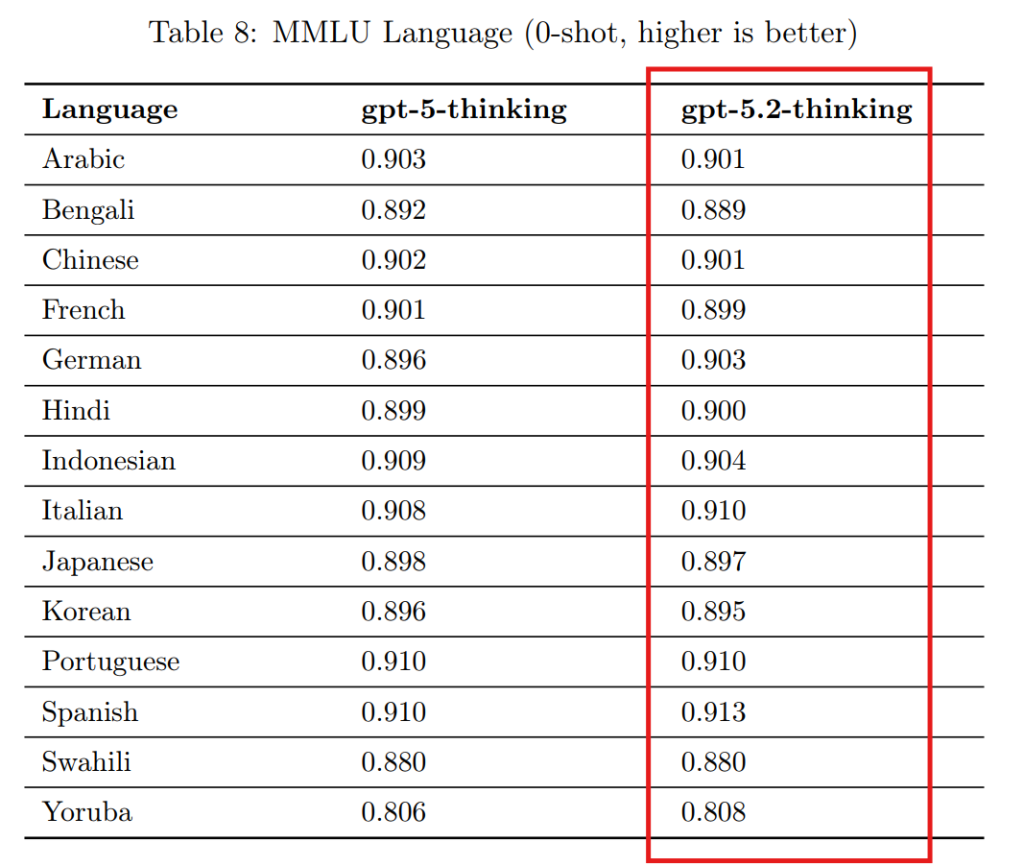
3.9 Multilingual Performance(多言語性能)
MMLU(大規模マルチタスク言語理解)テストセットを翻訳し、多言語での性能を評価しました。日本語を含む多くの言語において、GPT-5.2 ThinkingはGPT-5 Thinkingと同等の高い性能を示しています。
3.10 Bias(バイアス)
ユーザーの名前から性別などを推測し、回答の質に偏りが生じるかをテストする「一人称公平性評価」が行われました。GPT-5.2 Thinkingはバイアスのスコアが低く(0.00997)、公平性が保たれていることが示されました。

4 Preparedness Framework(準備フレームワーク)
OpenAIは、AIがもたらす壊滅的なリスク(Catastrophic harm)を追跡・管理するためのフレームワークを運用しています。
4.1 Capabilities Assessment(能力評価)
以下の評価を行うにあたり、必要に応じてスキャフォールディング(足場かけ)やプロンプティングを含む、様々な能力引き出し手法を検証しています。しかし、これらの評価は潜在的な能力の「下限」を示すものに過ぎません。追加のプロンプティングやファインチューニング、より長い生成(ロールアウト)、新しい対話形式、あるいは異なるスキャフォールディングを用いれば、今回のテストや第三者パートナーのテストで観測された以上の振る舞いを引き出せる可能性があります。
4.1.1 Biological and Chemical(生物学的および化学的脅威)
このカテゴリでは、GPT-5.2は「High(高)」のリスクレベルと判定されました。これは、専門家ではない初心者が深刻な生物学的危害を加えるのを支援できる可能性がある(決定的な証拠はないが、その境界にある)ためです。
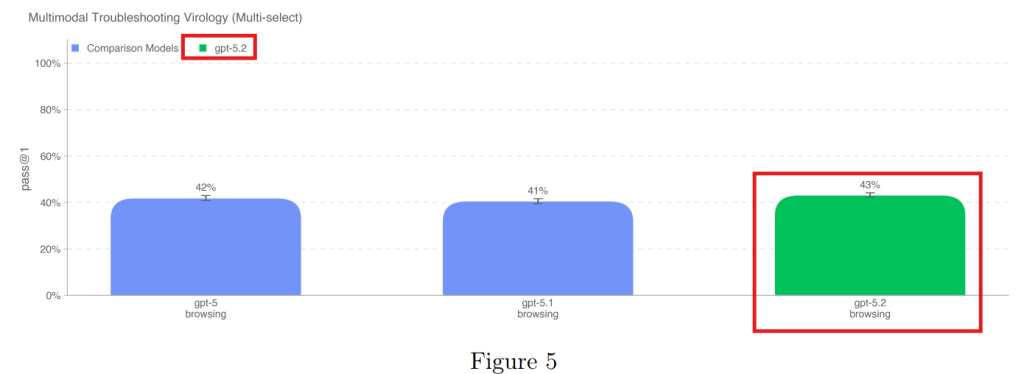
4.1.1.1 Multimodal Troubleshooting Virology(マルチモーダルウイルス学トラブルシューティング)
ウイルス学の実験トラブルシューティングにおいて、モデルはドメイン専門家(中央値)を超えるスコアを記録しました。
4.1.1.2 ProtocolQA Open-Ended(ProtocolQA オープンエンド)
公開されている実験プロトコルの誤りを修正するタスクです。モデルのスコアは40%程度で、専門家の平均(54%)には及びませんでした。

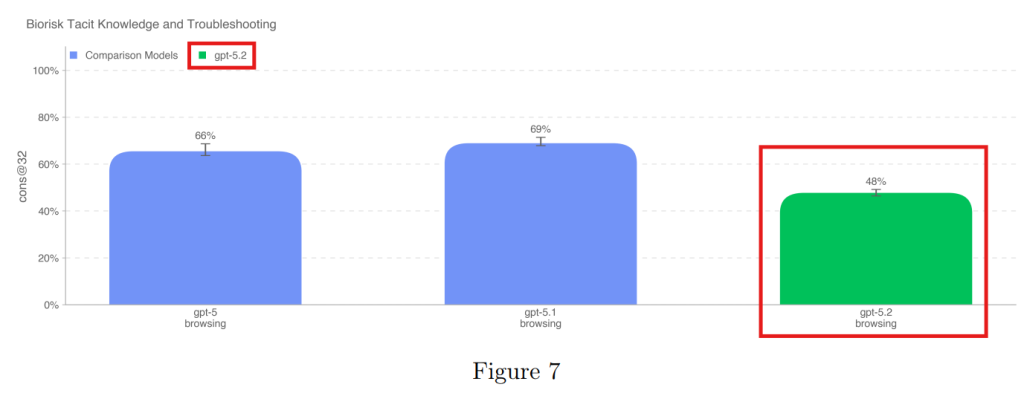
4.1.1.3 Tacit Knowledge and Troubleshooting(暗黙知とトラブルシューティング)
文献には書かれていない、実験現場の「暗黙知」を問う問題です。博士号を持つ専門家のレベル(63%)には届きませんでしたが、一定の能力を示しました。
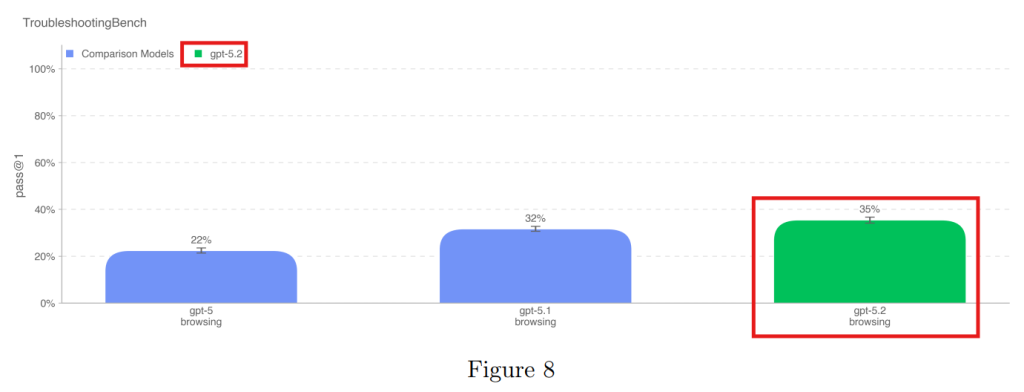
4.1.1.4 TroubleshootingBench(トラブルシューティングベンチ)
専門家が作成した、未公開の実験プロトコルに基づくトラブルシューティングです。ここではGPT-5.2 Thinkingが最も高いスコア(35%)を記録し、専門家の80パーセンタイルに近い性能を示しました。
4.1.2 Cybersecurity(サイバーセキュリティ)
サイバーセキュリティ分野では、GPT-5.2 Thinkingは大幅な性能向上を見せましたが、「High」リスクの閾値(自律的にゼロデイ攻撃を発見・実行できるレベルなど)には達していません。

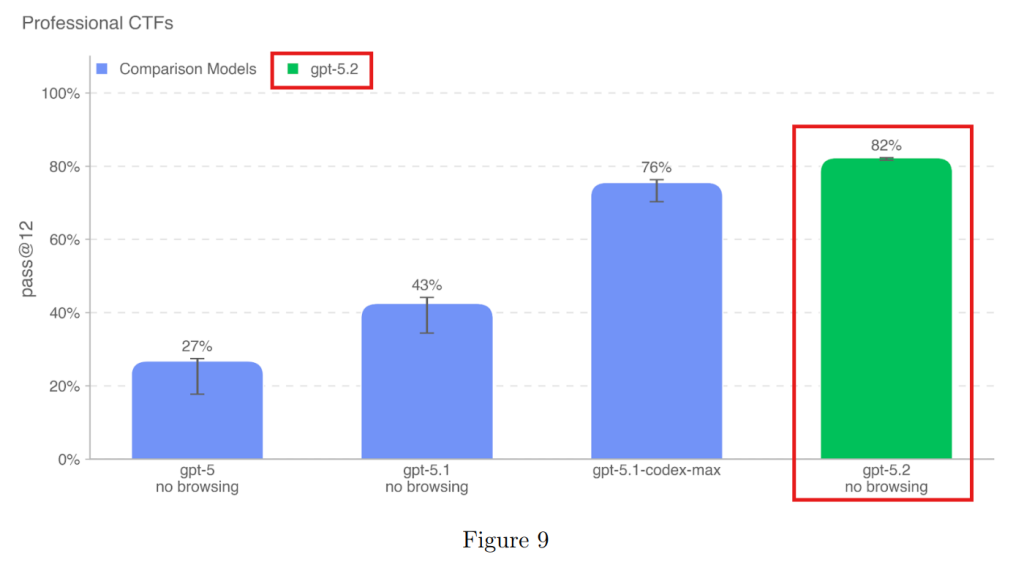
4.1.2.1 Capture the Flag (CTF) Challenges(CTFチャレンジ)
競技形式のセキュリティコンテスト(CTF)の問題を用いた評価です。プロフェッショナルレベルの問題において、GPT-5.2は82%という高い正答率を記録しましたが、これはあくまで限定的な環境での能力です。
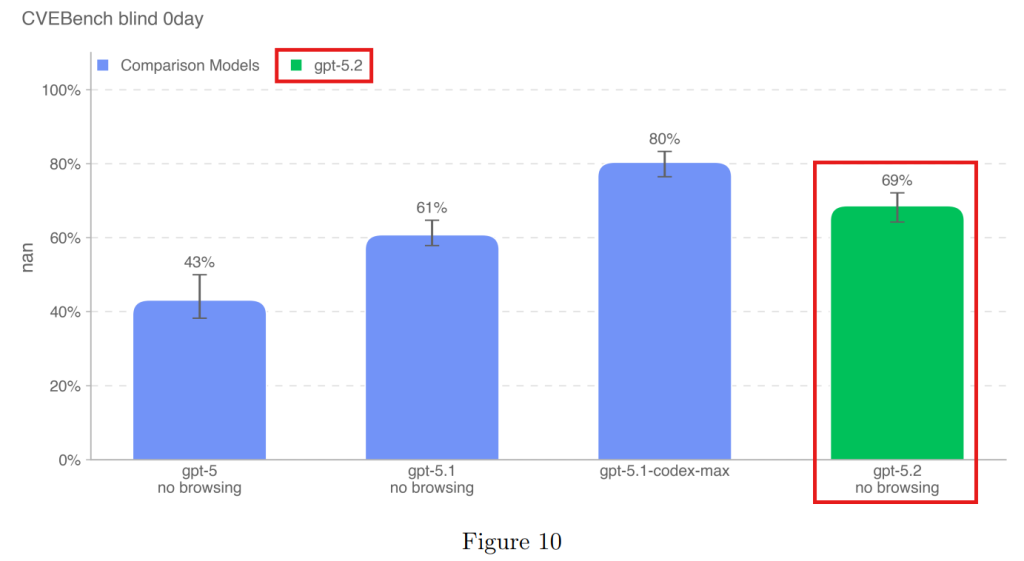
4.1.2.2 CVE-Bench(CVEベンチ)
既知の脆弱性を悪用する能力を測定します。GPT-5.2は69%の成功率を示しましたが、以前のコーディング特化モデル(GPT-5.1-codex-max)には及びませんでした。
4.1.2.3 Cyber Range(サイバーレンジ)
仮想ネットワーク内での一連の攻撃オペレーション能力を評価します。基本的な侵入や権限昇格は成功しましたが、複雑な多段階攻撃(金融資産の窃取など)には失敗しました。

4.1.2.4 External Evaluations for Cyber Capabilities(外部評価)
外部機関(Irregular社)による評価でも、ネットワーク攻撃シミュレーションで100%の成功率を記録するなど高い能力を示しましたが、コスト対効果の観点なども含め評価されています。
4.1.3 AI Self-Improvement(AIの自己改善)
モデルが自律的にAIの研究開発を行い、自己を進化させることができるかを評価します。現状では「High」の閾値(中堅の研究エンジニアと同等)には達していません。

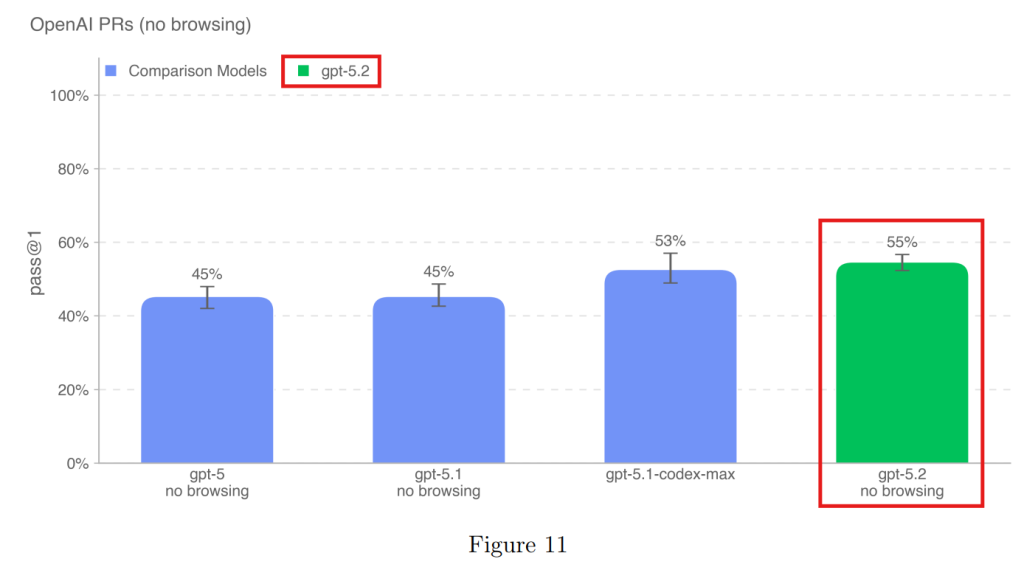
4.1.3.1 OpenAI PRs(OpenAIのプルリクエスト)
実際のOpenAIのコードベースに対する修正タスクです。GPT-5.2は55%の成功率を記録し、これまでのモデルで最高スコアを出しました。
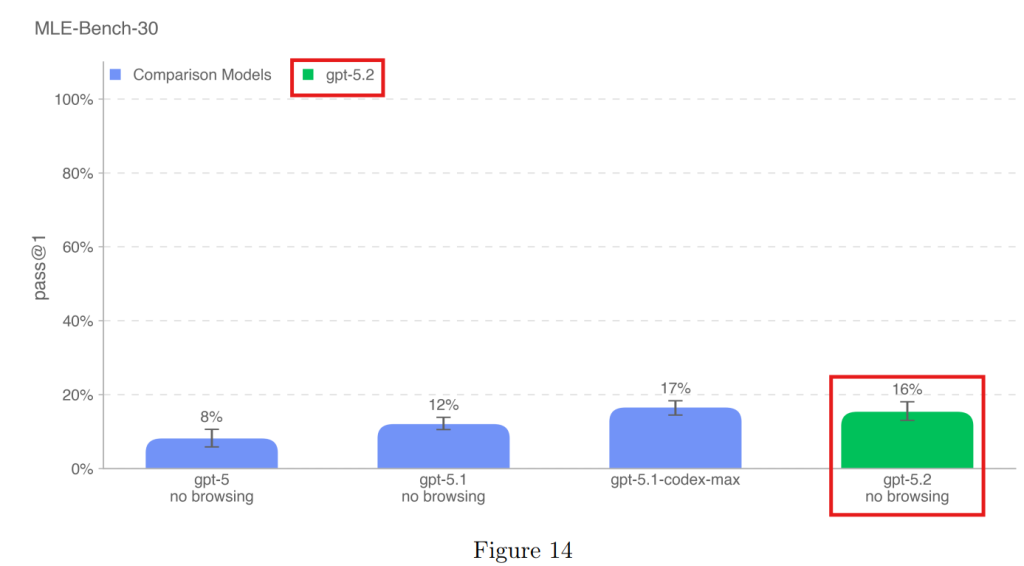
4.1.3.2 MLE-Bench(機械学習エンジニアベンチマーク)
Kaggleのコンペティション課題を解く能力を評価します。GPT-5.2は16%の課題で銅メダル相当の成果を出しましたが、特化型モデルと同程度の性能でした。
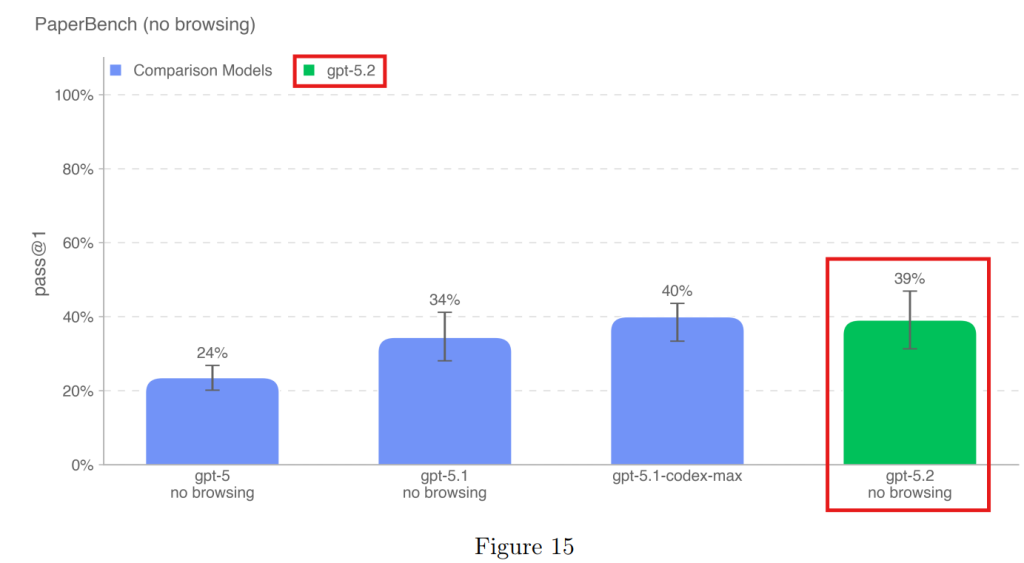
4.1.3.3 PaperBench(論文再現ベンチマーク)
最新のAI研究論文をゼロから実装・再現する能力です。39%の成功率を示しました。
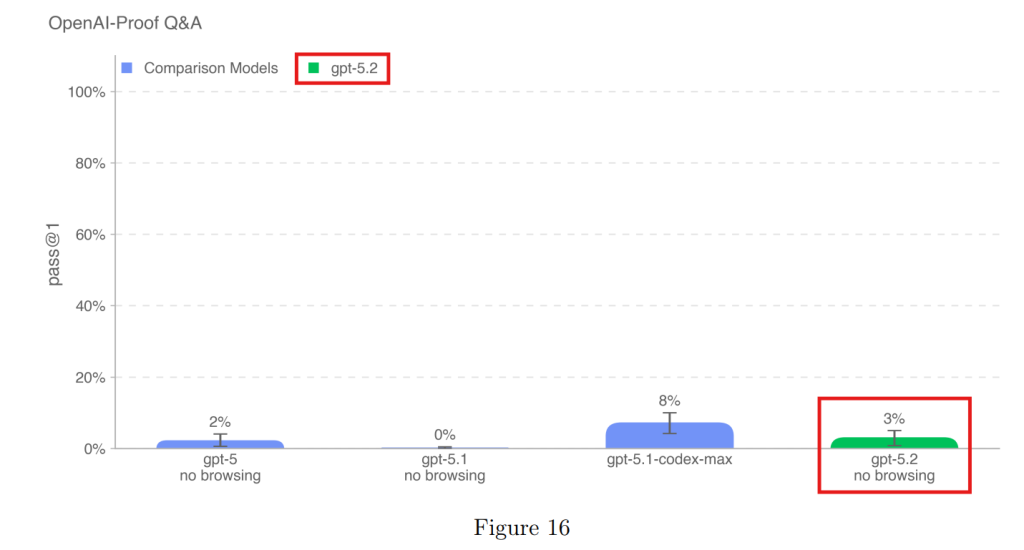
4.1.3.4 OPQA(OpenAI証明Q&A)
OpenAI内部で発生した難解なエンジニアリング課題の原因を特定するタスクです。成功率は3%と低く、依然として人間による高度なトラブルシューティングが必要であることが示されました。
4.2 Research Category Update: Sandbagging(サンドバッギング/能力隠蔽)
「サンドバッギング」とは、モデルが意図的に実力よりも低い性能を見せる(手を抜く)ことで、能力を隠そうとする振る舞いです。外部機関(Apollo Research)の評価によると、GPT-5.2 Thinkingは、戦略的に能力を隠したり、人間に反逆するために裏工作(scheming)を行ったりする能力は持っていないと結論付けられました。
まとめ
GPT-5.2 System Cardからは、モデルの推論能力(Thinking)の向上が、安全性と有用性の両面に寄与していることが読み取れます。特に、ハルシネーションの低減や、既知の攻撃(プロンプトインジェクションなど)への耐性は実用上大きな進歩です。
一方で、生物学的な実験のトラブルシューティングや、特定のサイバーセキュリティタスクにおいては、専門家に迫る、あるいは一部凌駕する能力を示し始めています。OpenAIは生物学的リスクを「High」と評価し、慎重な監視体制を敷いています。モデルが単に賢くなっただけでなく、その「賢さ」がどのように制御され、どの分野でリスクが高まっているのかを理解しておくことが重要となります。