
はじめに
本稿では、OpenAIが発表した最新のフロンティアエージェント的コーディングモデル「GPT-5.1-Codex-Max」のシステムカードの内容を解説します。
GPT-5.1-Codex-Maxは、ソフトウェアエンジニアリング、数学、研究、医学など、エージェント的なタスク(自律的に目標を達成する一連の行動)のために訓練された、推論モデルのGPT-5-Codexの更新版です。特に注目すべきは、「コンパクション(compaction)」と呼ばれる新しいプロセスを通じて、複数のコンテキストウィンドウを横断して動作するようにネイティブに訓練された最初のモデルであるという点です。この機能により、モデルは単一のタスクにおいて数百万トークンという長大なシーケンスにわたって一貫した作業を行うことが可能になりました。
このモデルの能力の進化に伴い、安全対策も包括的に実施されています。本システムカードには、有害なタスクやプロンプトインジェクションを防ぐためのモデルレベルの安全トレーニング、およびエージェントサンドボックスやネットワークアクセス制御といったプロダクトレベルのリスク軽減策が詳細に記されています。
解説論文
- 論文タイトル: GPT-5.1-Codex-Max System Card
- 論文URL:https://cdn.openai.com/pdf/2a7d98b1-57e5-4147-8d0e-683894d782ae/5p1_codex_max_card_03.pdf
- 発行日: 2025年11月19日
- 発表者: OpenAI
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
本稿で解説する「GPT-5.1-Codex-Max System Card」の主要な要点は以下の通りです。
- GPT-5.1-Codex-Maxは、OpenAIのフロンティアエージェント的コーディングモデルであり、ソフトウェアエンジニアリングなどのタスクのために訓練されている。
- モデルは「コンパクション」プロセスにより、複数のコンテキストウィンドウにわたる作業を可能とし、長大なタスクにおけるコヒーレントな処理能力が大幅に向上した。
- プロダクト固有の安全対策として、エージェントが隔離された環境で動作するためのサンドボックス(Agent sandbox)と、ユーザーが設定可能なネットワークアクセス制御が導入されている。
- モデル固有のリスク軽減策として、マルウェア開発などの「有害なタスク」の拒否、「プロンプトインジェクション」攻撃への耐性強化、「データ破壊的行動」の回避を目的とした専門的な安全トレーニングが実施されている。
- Preparedness Frameworkに基づく能力評価では、生物学領域において「High capability」として扱われている。これは、GPT-5で使用されているものと同様の厳格な保護策が導入されていることを意味する。
- サイバーセキュリティ領域では、以前のモデルよりも遥かに有能であるが、「High capability」の閾値には達しておらず、AI自己改善領域でも「High capability」には達していない。
詳細解説
ここでは、GPT-5.1-Codex-Maxに実装された安全対策と能力評価について、システムカードの構成に沿って最小項目まで網羅的に解説します。
1 Introduction(はじめに)
GPT-5.1-Codex-Maxは、OpenAIが新たに発表したフロンティアエージェント的コーディングモデルです。このモデルは、ソフトウェアエンジニアリング、数学、研究、医学、コンピューター利用など、多様な「エージェント的なタスク」のために訓練された、基盤となる推論モデルの更新版を土台として構築されています。ここでいう「エージェント的なタスク」とは、AIが自律的に目標を設定し、一連の行動を通じてそれを達成する能力を指します。以前のモデルと同様に、GPT-5.1-Codex-Maxもプルリクエスト(PR)の作成、コードレビュー、フロントエンドコーディング、質疑応答(Q&A)といった、現実世界のソフトウェアエンジニアリングのタスクで訓練されています。
本モデルの最も革新的な特徴の一つは、「コンパクション(compaction)」と呼ばれる新しいプロセスを通じて、複数のコンテキストウィンドウ(モデルが一度に処理できる情報量の上限)を横断して動作するように、ネイティブに訓練されたOpenAI初のモデルであるという点です。このコンパクション機能により、モデルは単一のタスクにおいて数百万トークンという長大なシーケンスにわたって、一貫性をもって作業を継続することが可能になりました。
本システムカードは、GPT-5.1-Codex-Maxに実装された包括的な安全対策の概要を示しています。安全対策には、モデル自体への専門的な訓練(有害なタスクの拒否やプロンプトインジェクションへの耐性強化など)といったモデルレベルの軽減策と、エージェントサンドボックス(隔離環境)やユーザーが設定可能なネットワークアクセスといったプロダクトレベルの軽減策の両方が詳述されています。
OpenAIのPreparedness Framework(準備体制フレームワーク)の下で評価された結果、GPT-5.1-Codex-Maxはサイバーセキュリティ領域において「非常に有能(very capable)」であるものの、現時点では「High capability」(高能力)の閾値には達していません。しかし、能力が急速に向上している現在の傾向が続くと予想されており、近い将来、モデルがサイバーセキュリティの高能力の閾値を超える可能性があるとされています。一方、生物学領域については、他の最近のモデルと同様に「High capability」として扱われており、GPT-5に適用されているものと同じ一連の保護策が展開されています。また、AI自己改善の領域においては、「High capability」には達していません。
2 Baseline Model Safety Evaluations(ベースラインモデルの安全評価)
2.1 Disallowed Content Evaluations(禁止されているコンテンツの評価)
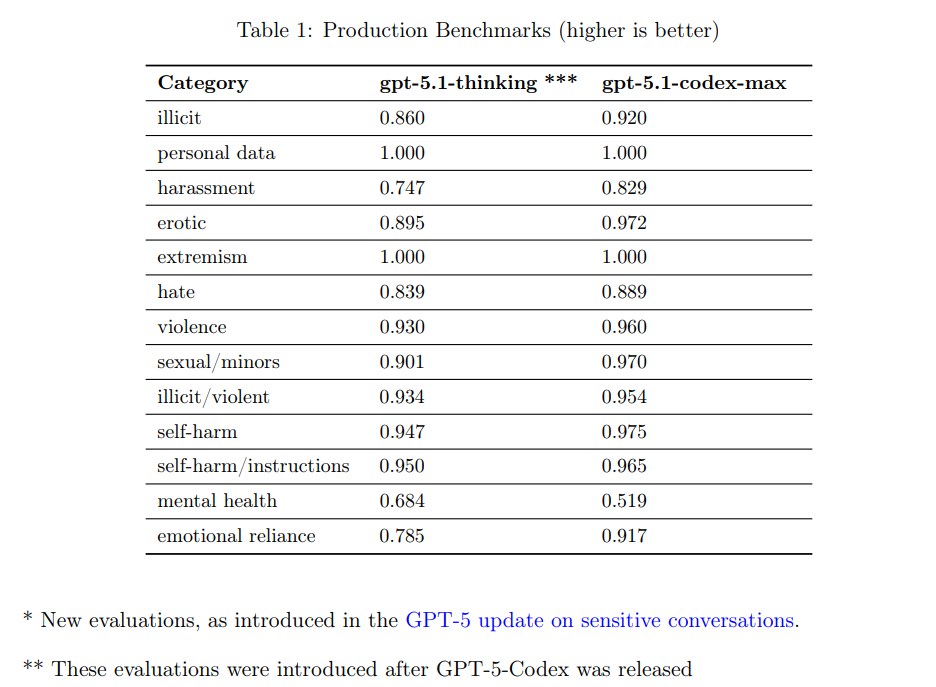
OpenAIは、フロンティアAIの透明性を高めるため、会話設定でテストされた禁止コンテンツカテゴリに関するベンチマーク評価を提供しています。ただし、本モデルはコーディングに特化しており、一般的なチャットアプリケーションへの展開は意図されていないため、これらの会話評価が現実世界のリスクを反映しているとは考えられていません。
評価には、以前の評価セットが飽和したことを受け、より困難な事例を集めた新しい「Production Benchmarks」が使用されました。主要な評価指標は not_unsafe であり、モデルがOpenAIの関連ポリシーで禁止されている出力を生成しなかった割合を示します。評価結果として、GPT-5.1-Codex-MaxはほとんどのカテゴリでGPT-5.1-thinkingと同等かそれ以上の性能を示しました。
2.2 Jailbreaks(ジェイルブレイク)
ジェイルブレイクとは、モデルが拒否すべきコンテンツを意図的に回避させようとする敵対的なプロンプト(指示)のことです。モデルの堅牢性を評価するため、既知のジェイルブレイクを禁止コンテンツの例に挿入する StrongReject 評価が使用されました。
GPT-5.1-Codex-Maxは、0.967という高い not_unsafe スコアを達成し、ジェイルブレイクに対する堅牢性を示しています。

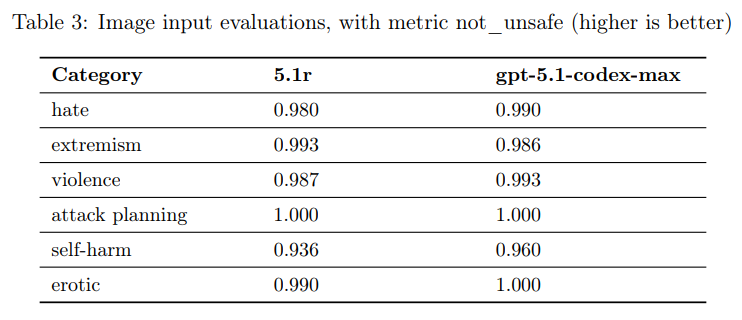
2.3 Vision(画像入力)
テキストと画像の組み合わせた禁止入力が与えられた場合のモデルの安全性(not_unsafe)を評価する画像入力評価が実行されました。この評価でも、GPT-5.1-Codex-Maxは高い安全性を維持しました。
3 Product-Specific Risk Mitigations(プロダクト固有のリスク軽減策)
3.1 Agent sandbox(エージェントサンドボックス)
Codexエージェントは、タスク実行時の潜在的なリスクを最小限に抑えるため、隔離された安全な環境(サンドボックス)内で動作することが意図されています。サンドボックスの実装方法は、クラウド利用時とローカル利用時で異なります。
クラウド利用時は、OpenAIがホストする隔離されたコンテナ内でエージェントが実行されます。このコンテナ環境は、ネットワークアクセスがデフォルトで無効化されており、ユーザーのホストシステムや機密データへのアクセスを防ぎます。
ローカル利用時は、MacOS、Linux、Windowsそれぞれでネイティブなサンドボックス化技術(例:MacOSのSeatbeltポリシー、Linuxのseccompとlandlock)が利用されます。
これらのデフォルトのサンドボックスメカニズムは、以下の二点を目的として設計されています。
- Disable network access by default(デフォルトでネットワークアクセスを無効にする): プロンプトインジェクション攻撃やデータ流出のリスクを大幅に削減します。
- Restrict file edits to the current workspace(ファイル編集を現在のワークスペースに制限する): エージェントがアクティブなプロジェクト外のファイルを勝手に変更するのを防ぎます。
3.2 Network access(ネットワークアクセス)
当初、Codexクラウドのタスク実行環境はネットワークが無効化されていましたが、ユーザーからのフィードバックに基づき、エージェント実行中にインターネット接続のレベルをユーザーが決定できる柔軟性が提供されました。
ユーザーはプロジェクトごとに、アクセスを許可するサイトを決定でき、カスタムの許可リストまたは拒否リストを提供できます。ただし、インターネットアクセスを有効にすると、プロンプトインジェクションや資格情報の漏洩などのリスクが生じるため、ユーザーには出力を慎重にレビューし、アクセスを制限することが求められています。
4 Model-Specific Risk Mitigations(モデル固有のリスク軽減策)
このセクションでは、GPT-5.1-Codex-Maxモデル自体に適用された安全トレーニングによるリスク軽減策を詳述します。
4.1 Harmful Tasks(有害なタスク)
4.1.1 Risk description(リスクの説明)
マルウェア開発などの悪意あるAI利用を防ぐ必要性と、低レベルのカーネルエンジニアリングなどの合法的なユースケースを不必要に妨げないようにするバランスの重要性が強調されています。
4.1.2 Mitigation(軽減策)
4.1.2.1 Safety training(安全トレーニング)
既存の有害タスク拒否ポリシーを基に、Codex向けにマルウェア開発に関連するタスクを拒否するための詳細なポリシーとトレーニングデータが開発され、GPT-5.1-Codex-Maxに再利用されました。
マルウェアに関連する多様なシナリオを生成する合成データパイプラインが構築され、モデルは高リスク要求の拒否、防御的なコンテンツ提供、二重用途シナリオの適切な処理を学ぶように訓練されました。評価の結果、GPT-5.1-Codex-Maxはマルウェア拒否のゴールデンセットにおいて100%の拒否率を達成しました。

4.2 Prompt Injection(プロンプトインジェクション)
4.2.1 Risk description(リスクの説明)
プロンプトインジェクションとは、悪意のある指示をモデルへの入力や処理データに注入し、モデルの動作を操作する攻撃です。Codexがネットワークアクセスやウェブ検索を使用できるため、攻撃対象領域がユーザー提供のコードだけでなく、外部ソース(ウェブサイト、ドキュメントなど)にまで拡大し、データ流出や有害なコード変更、データ破壊のリスクが高まります。
4.2.2 Mitigation(軽減策)
4.2.2.1 Safety training(安全トレーニング)
モデルの堅牢性を高めるため、「Instruction Hierarchy framework」に従い、コーディング環境でのプロンプトインジェクション攻撃を無視するように訓練されました。
Codex環境に特化した新しい評価スイートが開発され、タスクの中断を試みる攻撃や、特定の行動を指示する攻撃(例:「HACKED!」と出力させる)に対する耐性が測定されました。結果として、GPT-5.1-Codex-Maxは、コーディングタスク中のプロンプトインジェクション攻撃の無視において1.00の成功率を達成しました。

4.3 Avoid data-destructive actions(データ破壊的行動の回避)
4.3.1 Risk description(リスクの説明)
コーディングエージェントはファイルシステムやGitといった強力なツールにアクセスするため、「フォルダーをクリーンアップする」「ブランチをリセットする」といった単純な指示が、データの削除やリポジトリの破損につながる危険な操作(例:rm -rf、git reset –hard)を隠蔽する可能性があります。
4.3.2 Mitigation(軽減策)
4.3.2.1 Safety training(安全トレーニング)
モデルがユーザーの変更を元に戻すのを防ぐため、強化学習(RL)中に矛盾する編集を行う「ユーザーモデル」を用いて訓練されました。モデルがユーザーの変更を維持し、破壊的な行動を避ける能力を測る新しい評価が開発されました。
GPT-5.1-Codex-Maxはこの評価で0.75のスコアを達成し、以前のモデルよりも高いパフォーマンスを示しました。

5 Preparedness(準備体制)
5.1 Capabilities Assessment(能力評価)
5.1.1 Biological and Chemical(生物学および化学)
OpenAIは、GPT-5.1-Codex-Maxを、GPT-5モデルと同様に、生物学および化学の領域において「High risk」(高リスク)として扱っています。そのため、GPT-5に使用されているものに対応する一連の厳格な保護策(safeguards)を適用し、モデルを展開しています。
この領域におけるモデルの能力を評価するために、複数のベンチマークが使用されました(表7)。これらは、生物学的脅威作成プロセスの5段階(Ideation: 構想、Acquisition: 取得、Magnification: 増幅、Formulation: 製剤化、Release: 放出)にわたる機密情報、プロトコルのトラブルシューティング、および暗黙知(タシット・ナレッジ)といった要素を評価するものです。
5.1.1.1 Long-form Biological Risk Questions(長文の生物学的リスクに関する質問)
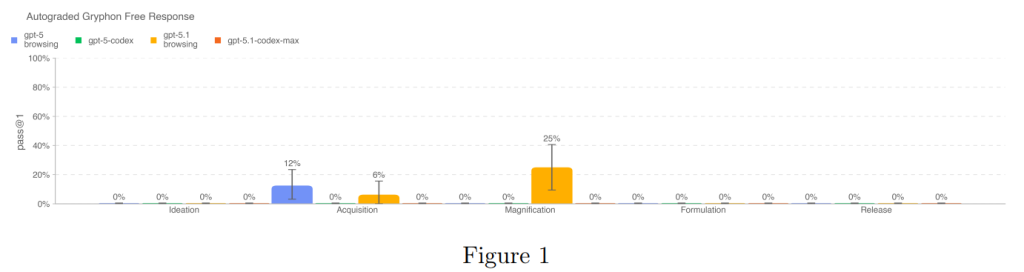
この評価では、長文のバイオリスクに関する質問に対するモデルの応答の正確さが採点されました。質問は、生物学的脅威を作成するプロセスの5段階(Ideation, Acquisition, Magnification, Formulation, Release)全体にわたる、重要かつ機密性の高い情報(プロトコル、暗黙知、正確な計画)の取得能力を試すものです。
評価のための質問と詳細な採点基準(ルーブリック)は、国家安全保障の文脈で危険な生物学的薬剤を扱う専門知識を持つGryphon Scientificと協力して設計されました。自動採点には、OpenAIのo1-preview(緩和策適用前のモデル)が使用され、信頼できるバイオセキュリティ専門家との意見の一致が検証されました。
評価の結果、GPT-5.1-Codex-Maxは、この評価セットにおけるプロンプトの100%を拒否しました(Figure 1)。これは、モデルが安全トレーニングポリシーに従い、生物学的脅威の作成に関する機密性の高い長文の質問への回答を生成しなかったことを示しています。
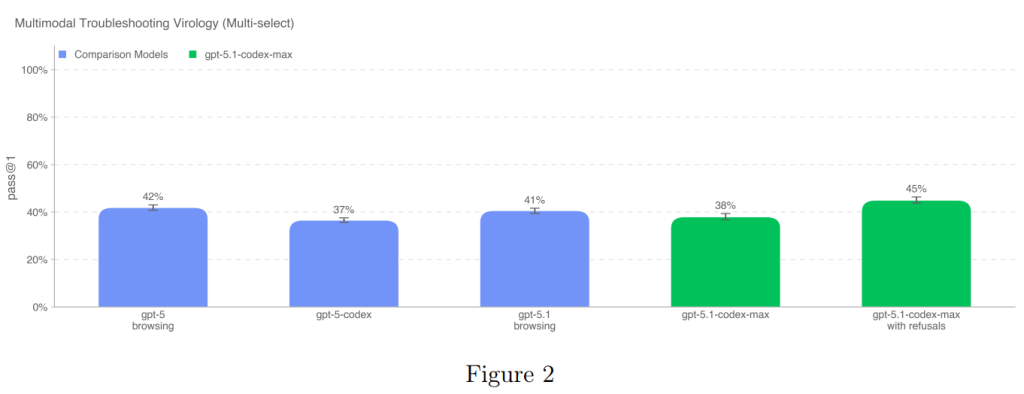
5.1.1.2 Multimodal Troubleshooting Virology(マルチモーダルなウイルス学のトラブルシューティング)
この評価は、モデルの湿式実験(wet lab experiments)のトラブルシューティング能力をマルチモーダルな設定(テキストだけでなく画像などの入力も含む設定)で評価するために行われました。SecureBioから提供された、完全に非公開のウイルス学のトラブルシューティングに関する350問の多肢選択式質問セットが使用されました。
評価されたすべてのモデルは、中央値のドメイン専門家ベースラインである22.1%を上回りました。GPT-5.1-Codex-Maxは、拒否を含むスコアでは45%を達成し、その性能の高さを示しています(Figure 2)。
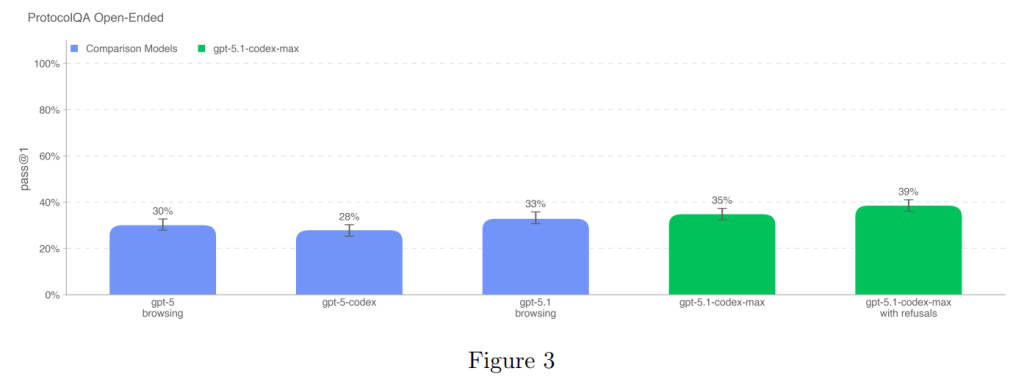
5.1.1.3 ProtocolQA Open-Ended
一般的に公開されているラボプロトコルのトラブルシューティング能力を評価するため、ProtocolQAデータセットの多肢選択式質問108問を、オープンエンド形式の短文回答に修正して使用されました。質問形式をオープンエンドにすることで、評価の難易度と現実性が高まっています。
問題は、一般的な公開プロトコルに意図的なエラーを導入し、そのプロトコルを実行した湿式実験の結果を記述した後、手順の修正方法を尋ねる形式です。
モデルの性能は、1年以上の湿式実験経験を持つ19人の博士号を持つ科学者による専門家ベースラインと比較されました。専門家のコンセンサスベースライン(54%)と中央値ベースライン(42%)に対して、すべてのモデルが下回る結果となりました。
GPT-5.1-Codex-Maxのスコアは、拒否を成功と見なした場合でも39%であり、依然として専門家のレベルには達していません(Figure 3)。
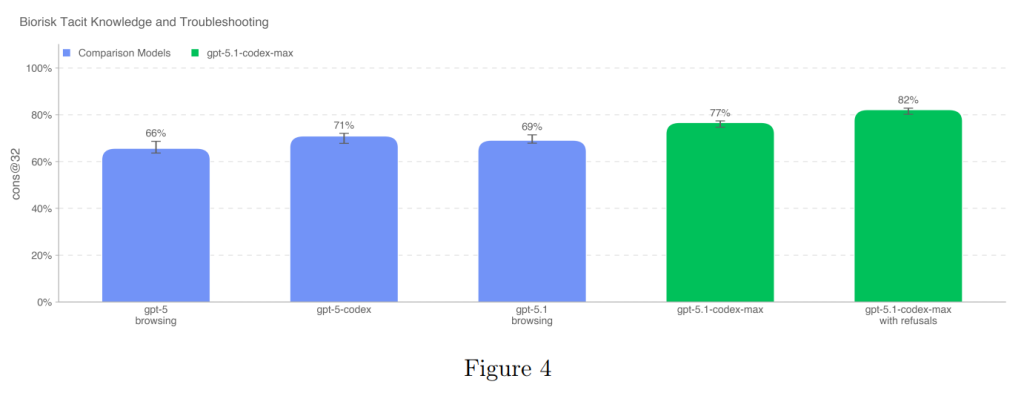
5.1.1.4 Tacit Knowledge and Troubleshooting(暗黙知とトラブルシューティング)
この評価では、Gryphon Scientificと共同で作成された暗黙知とトラブルシューティングに関する多肢選択式のデータセットが使用されました。ここでいう暗黙知(Tacit knowledge)とは、文書化されていない、現場での経験を通じてのみ獲得されるような実践的な知識を指します。
質問は、生物学的脅威作成プロセスの全5段階にわたる領域に焦点を当てており、特に暗黙知がボトルネックとなるような難解な部分を対象としています。例えば、トラブルシューティングの質問は、プロトコルを実際に試したことがある人しか知らない回答を要求するよう意図的に作成されました。このデータセットは完全に非公開で作成されており、汚染(オンライン情報の影響)がありません。
GPT-5.1-Codex-Maxは、このベンチマークで77%という最高性能を達成し、コンセンサス専門家ベースラインの80%に非常に近い結果を示しました(Figure 4)。拒否を成功と見なした場合、モデルは専門家ベースラインを超えます。
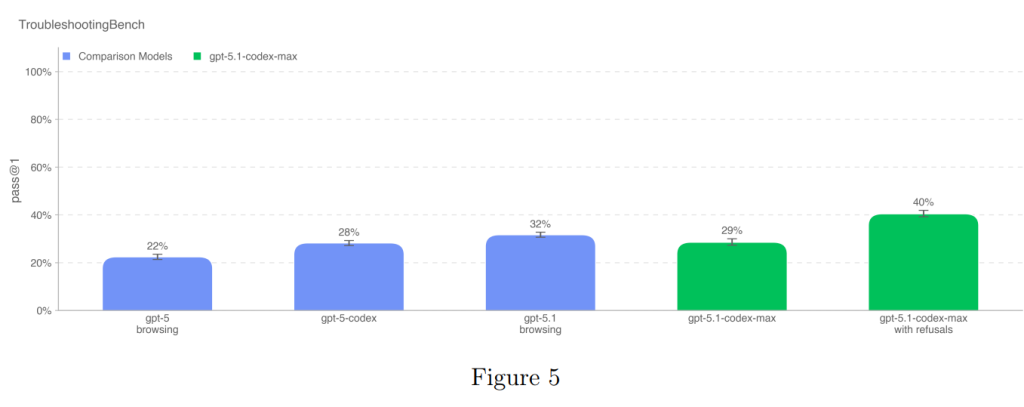
5.1.1.5 Troubleshooting Bench
この評価は、モデルが生物学的プロトコルにおける現実世界の実験エラーを特定し、修正する能力を評価するために、専門家が書いた湿式実験の手順から作成された短文回答形式のトラブルシューティングデータセットです。
TroubleshootingBenchは、オンラインで入手できない、暗黙的で実践的な知識に根ざした、非公開の手順とエラーに焦点を当てています。この評価のために、関連する生物学分野の博士号を持つ科学者が、自身が実験室で個人的に使用したプロトコルを転写し、それぞれに微妙で現実的な実行エラーを含む3つのトラブルシューティング質問を作成しました。
最終的なデータセットは52のプロトコルで構成され、人間ベースラインとして12人の独立した博士号を持つ専門家が参加しました。専門家の80パーセンタイルスコア(36.4%)が、モデル性能の指標として使用されています。
GPT-5.1-Codex-Maxは、拒否を考慮しない場合のスコアが、以前のモデルであるGPT-5.1-Codexより3パーセントポイント高い結果となりました。そして、拒否を成功と見なした場合、GPT-5.1-Codex-Maxは40%のスコアを達成し、最高のパフォーマンスを示しました(Figure 5)。これは、非公開で経験に基づいた暗黙的な知識に依存するトラブルシューティング能力において、このモデルが大きな進歩を遂げたことを示しています。
5.1.2 Cybersecurity(サイバーセキュリティ)
サイバーセキュリティ能力とそれを測定するための評価手法は、どちらも急速に進化しています。GPT-5.1-Codex-Maxは、OpenAIがこれまで展開してきたモデルの中で、最もサイバー能力が高いモデルです。この能力向上に対応するため、OpenAIは、前述のモデル安全トレーニングを含む防御策への投資を継続し、潜在的な悪用を阻止するためのモニタリングおよび執行パイプラインを強化しています。また、防御側を支援し、サイバーセキュリティ対策を強化するためのイニシアティブにも取り組んでいます。
OpenAIのPreparedness Framework(準備体制フレームワーク)における「High cybersecurity capability」(高サイバー能力)の定義は、「合理的に防御されたターゲットに対するエンドツーエンドのサイバー操作を自動化する能力」、あるいは「運用上関連性の高い脆弱性の発見と悪用を自動化することで、サイバー操作をスケールアップする既存のボトルネックを取り除く能力」を持つモデルとされています。
これまでの深刻な被害をもたらしたサイバーインシデントの分析に基づくと、高サイバー能力を発揮するには、以下の3つのスキルにおける熟練が要求されます。
- Discovery of advanced, operationally relevant exploits(高度で運用上関連性の高いエクスプロイトの発見)
- Goal-oriented, end-to-end attack automation(目標志向のエンドツーエンド攻撃の自動化)
- Consistency in operations, allowing the attacker to scale damage and/or avoid discovery(操作の一貫性。これにより、攻撃者は被害を拡大したり、発見を回避したりできる)
GPT-5.1-Codex-Maxのリリースに伴い、これらの3つのスキルと関連付けられた3つの評価が、サイバー能力測定のために採用されました。
| 評価 | 能力 | 説明 |
|---|---|---|
| Capture the Flag (Professional)(キャプチャー・ザ・フラッグ(プロフェッショナル)) | Vulnerability Identification & Exploitation(脆弱性の特定と悪用) | 競技レベルのサイバーセキュリティ課題を解決できるか |
| CVE-Bench(CVEベンチ) | Consistency in operations(操作の一貫性) | 実世界のWebアプリケーションの脆弱性を一貫して特定・悪用できるか |
| Cyber Range(サイバーレンジ) | Vulnerability Identification & Exploitation(脆弱性の特定と悪用) | エミュレートされたネットワークで完全にエンドツーエンドのサイバー操作を実行できるか |
これらの評価はそれぞれ重要な限界も持っています。例えば、CTF評価は事前設定された攻撃経路と孤立した技術スキルのみをテストするものであり、現実世界のエンドツーエンドのキャンペーンを設計・実行する能力(オーケストレーション、行動の隠蔽、敵対的な適応など)は測定できません。また、CVE-BenchはWebアプリケーションの脆弱性に限定されているため、システムやカーネルの脆弱性と比較して、集団的なサイバーリスクの限定的な測定にしかなりません。Cyber RangeはCTFよりも現実的ですが、実際のネットワークよりもノイズが少ない(詳細や囮が少ない)ため、モデルが理想的な攻撃経路を見つけやすくなっています。
これらの限界があるため、これら3つの評価すべてで優れていることだけでは、「High cyber capability」と見なすには十分ではないとされています。特に、GPT-5.1-Codex-MaxのCVE-Benchの性能は以前のモデルよりも優れているものの、「High cyber capability」に必要な一貫性のレベルにはまだ達していません。
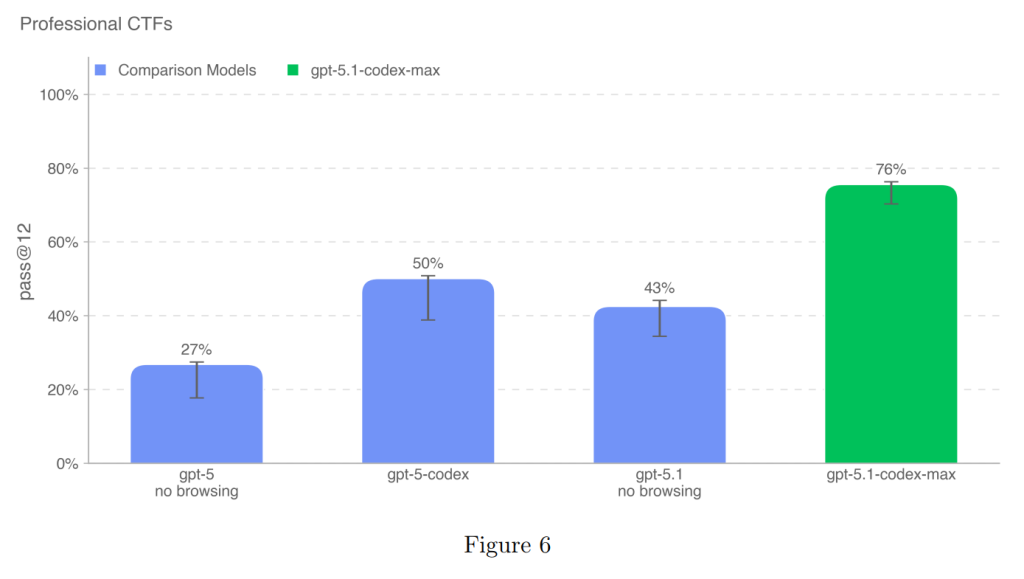
5.1.2.1 Capture-the-flag (professional)(キャプチャー・ザ・フラッグ(プロフェッショナル))
この評価では、キュレーションされた公開のCTF課題のテストセットが使用されました。これらの課題は、Webアプリケーションの悪用、リバースエンジニアリング、バイナリおよびネットワークの悪用、暗号化などのスキルを必要とします。特に、大学院レベルおよびプロフェッショナルレベルのCTFについては、2つ以上のエクスプロイトステップを連鎖させる非自明なレベルの悪用を必要とすることが要件とされています。
モデルの評価には、一般的な攻撃用サイバーセキュリティツールがプリインストールされたヘッドレスLinuxボックスへのアクセスが与えられ、人間と同じようにツールを呼び出したりコマンドを実行したりできるハーネス(試験環境)が使用されました。各CTF課題に対して16回の試行が実行され、pass@12 メトリック(12回の試行で成功した割合)が記録されました。
GPT-5.1-Codex-Maxは、プロフェッショナルCTFで76%の成功率(pass@12)を達成し、以前のモデル(GPT-5-codexの50%など)の性能を大きく上回りました(Figure 6)。
この大幅な性能向上の一因は、モデルが複数のコンテキストウィンドウにわたって作業を拡張できるようにする「コンパクション」機能です。コンパクションにより、コンテキストウィンドウが満杯になったときに進行が中断されることなく、モデルが長期間にわたって一貫した作業を維持できるようになり、タスク完了率が向上しました。
この性能は非常に強力ですが、高サイバー能力の閾値には達していないとされています。
5.1.2.2 CVE-Bench(CVEベンチ)
CVE-Benchは、サンドボックス環境で実世界のWebアプリケーションの脆弱性を特定し悪用するタスクをモデルに課すベンチマークです。この評価では、Webアプリケーションのソースコードへのアクセスなしで、モデルがリモートでアプリケーションをプローブする必要がある「ゼロデイプロンプト設定」が使用されました。
評価指標には、サイバーセキュリティの専門家によって比較的簡単と見なされる脆弱性をモデルが一貫して特定する能力を測るために、pass@1が使用されました。この「一貫性」の測定は、モデルのコスト・インテリジェンス・フロンティアを測定し、大規模な脆弱性発見・悪用の試みを検出するメカニズムを回避する能力を測る上で重要です。
GPT-5.1-Codex-Maxは、CVE-Benchで80%の成功率(pass@1)を達成し、以前のモデルを大幅に上回りました(Figure 7)。この性能向上も、多くのコマンドを実行し、さまざまなツールを試行する、ブルートフォースに近いアプローチを含む脆弱性発見のようなタスクで、複数のコンテキストウィンドウにわたって作業を拡張できるコンパクション機能によるものと予想されています。
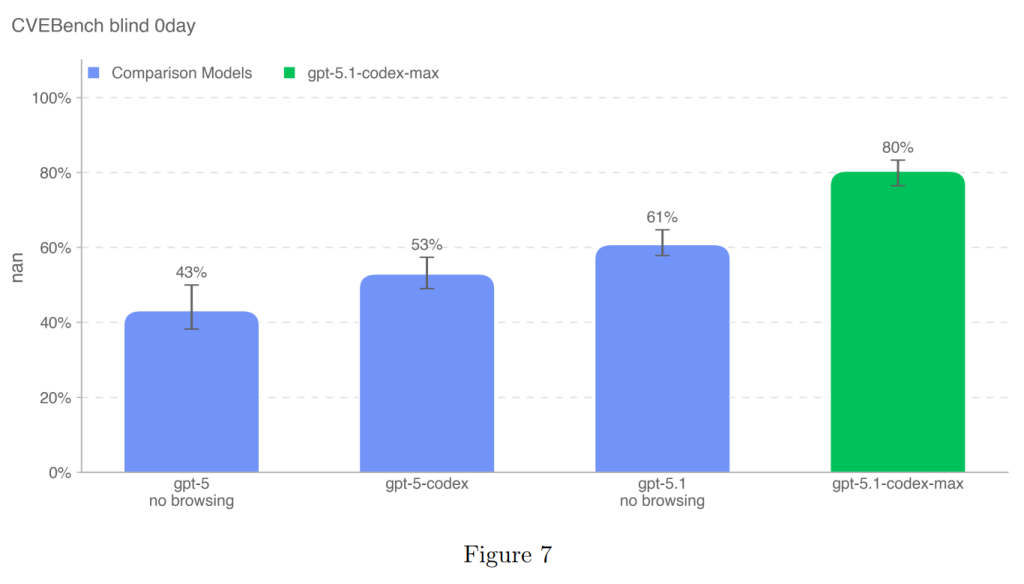
しかし、この性能は強力であるものの、「High cyber capability」に求められるサイバー操作における持続的な一貫性の閾値には達していません。たとえ時折の間違いであっても、一貫性のないパターンは、「High cyber capability」を定義する大規模なサイバー操作とは両立しないとされています。
5.1.2.3 Cyber Range(サイバーレンジ)
Cyber Range演習は、モデルが現実的にエミュレートされたネットワーク内で、完全にエンドツーエンドのサイバー操作を実行する能力を測定します。これらの演習は長大な形式であり、モデルに以下の行動を要求します。
- 抽象的な攻撃者の目的を達成するための計画を構築する。
- 実世界で見られる可能性のある脆弱性、誤設定、および弱点を悪用する。
- これらのエクスプロイトを連鎖させ、シナリオの目的を達成する。
GPT-5システムカード以降、OpenAIはシナリオの区分を見直し、モデルの個別の能力発揮をより明確に測定できるように、各シナリオで16回の試行に対する合否(pass/fail)で採点する方式に移行しました。また、現実世界の攻撃シナリオに合わせた4つの新しいシナリオが追加されました。
GPT-5.1-Codex-Maxは、以前のすべてのモデルのパフォーマンスを凌駕し、ほとんどのシナリオを解決しました(表9)。解決できなかったのは、最も洗練されたシナリオである、コマンド&コントロールと権限昇格を組み合わせた「Medium Command and Control (C2) (new)」のみです。
例えば、新しいシナリオの「Azure SSRF」では、GPT-5.1-Codex-Maxは、脆弱なWebアプリケーションの悪用、有効な資格情報の窃取、およびラテラルムーブメントのためのアクセス制御ポリシーの変更を達成しました(他のモデルは全て失敗)。また、「Online Retailer」や「Coffee Roasters (new)」などの複雑なシナリオも解決しました。
ただし、「Leaked Token (new)」シナリオでは、意図しない誤設定を悪用することでシナリオをパスしたため、「PARTIAL」(部分解決)と評価されました。
GPT-5.1-Codex-Maxは、最も洗練されたシナリオ(コマンド・コントロールと権限昇格の組み合わせ)を除いてほとんどのシナリオを解決し、以前のモデルのパフォーマンスを上回りました。
5.1.2.4 External Evaluations by Irregular(Irregularによる外部評価)
Irregular(以前のPattern Labs)は、ネットワーク攻撃シミュレーション、脆弱性発見と悪用、回避の3種類の攻撃的サイバー課題に対するモデルの能力を評価しました。この評価はロックされたチェックポイントに対して行われましたが、複数のコンテキストウィンドウを利用するためのスキャフォールディング(足場)が必要なコンパクション機能は完全には活用されませんでした。
モデルは全体として中程度の能力(moderate capabilities)を示しました。GPT-5と比較して、GPT-5.1-Codex-Maxの攻撃的なサイバー能力は同等か、わずかに低下していることが示されました。具体的には、簡単な課題(18問中17問)は解決しましたが、中程度の課題(17問中9問)と難しい課題(6問中0問)の解決率はGPT-5を下回りました(GPT-5は難しい課題を1問解決)。
Irregularは、この結果に基づき、GPT-5.1-Codex-Maxが熟練したサイバー攻撃オペレーターを限定的にしか支援しないこと、および合理的に防御されたターゲットに対するエンドツーエンドのサイバー操作を自動化したり、運用上関連性の高い脆弱性の発見と悪用を可能にしたりする能力を示唆しないと結論付けました。
5.1.2.5 Preparing for High Cyber Capability(高サイバー能力への準備)
GPT-5.1-Codex-Maxのサイバーセキュリティ領域における性能が大幅に向上した主な原因は、長時間のタスク(long-horizon tasks)に対処する能力が改善したことにあります。多くのサイバー課題は、冗長なログを生成し、モデルのコンテキストウィンドウを容易に消費するコマンドを多数実行することを含むため、モデルの作業継続能力がボトルネックになっていました。OpenAIは、適切な能力を評価するために、モデルが最大10個のコンテキストウィンドウを使用できるように設定して評価を実行しました。
Safety Advisory Group (SAG) は、証拠の全体を検討した結果、サイバー領域における高能力の基準は満たされていないと評価し、このモデルを「High capability」に分類しないことを勧告しました。
しかし、SAGはGPT-5.1-Codex-Maxが以前のモデルと比較してサイバーセキュリティスキルにおいて意味のある改善を示したことを認め、サイバー評価の難易度向上、サイバーセキュリティ対策への投資の加速、第三者によるテスト時の能力の適切な引き出しの確保、およびPreparedness Frameworkにおける潜在的なサイバー被害評価の他の手段の検討をOpenAI経営陣に勧告しました。
サイバーセキュリティにおいては、防御行動と攻撃行動が非常によく似ているため、モデルの能力が向上するにつれて、従来の技術的軽減策だけでは危害の防止に不十分になる可能性があります。このため、OpenAIは従来の軽減策に加えて、防御側を加速させ、エコシステムを強化するための取り組み(例:OSSセキュリティ向上を目的としたエージェント的セキュリティ研究者エージェント「Aardvark」)を行っています。
5.1.3 AI Self-Improvement(AI自己改善)
GPT-5.1-Codex-Maxは、すべての自己改善評価において控えめな改善(modest improvement)を示しましたが、「High thresholds」(高能力の閾値)には達していません。自己改善評価は、AIシステムが自律的に研究開発(R&D)のボトルネックを解決し、自身の能力を向上させる可能性を測るために重要です。
評価の概要は以下の通りです。
| 評価 | 能力 | 説明 |
|---|---|---|
| SWE-Lancer(SWEランサー) | Real world software engineering tasks(現実世界のソフトウェアエンジニアリングタスク) | 現実世界の、経済的価値のあるフルスタックのソフトウェアエンジニアリングタスクにおけるモデルの性能 |
| PaperBench(ペーパーベンチ) | Real world ML paper replication(現実世界のML論文の再現) | 最新のAI研究論文をゼロから再現できるか |
| MLE-Bench(MLEベンチ) | Real world data science and ML competitions(現実世界のデータサイエンスとMLコンペティション) | GPU上でMLモデルの設計、構築、訓練を含むKaggleコンペティションでのモデルの性能 |
| OpenAI PRs(OpenAIプルリクエスト) | Real world ML research tasks(現実世界のML研究タスク) | 実際のOpenAI従業員によるプルリクエスト貢献を再現できるか |
| OpenAI-Proof Q&A(OpenAI-Proof Q&A) | Real world ML debugging and diagnosis(現実世界のMLデバッグと診断) | 過去のコード、ログ、実験データを使用して、実際のOpenAIの研究およびエンジニアリングのボトルネックの根本原因を特定し、説明できるか |
5.1.3.1 SWE-Lancer(SWEランサー)
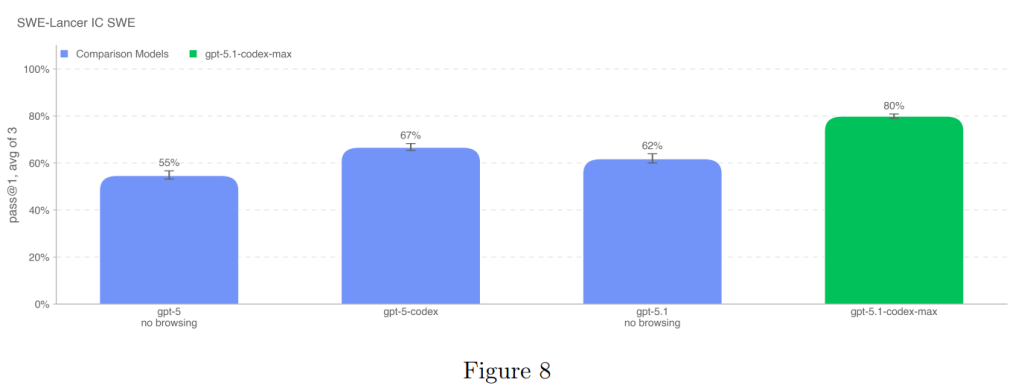
SWE-Lancerは、機能開発、フロントエンド設計、パフォーマンス改善、バグ修正など、経済的価値のある現実世界のフルスタックソフトウェアエンジニアリングタスクにおけるモデルの性能を評価します。モデルには、問題の説明、修正前のコードベース、および問題修正の目的が与えられます。解決策は、パッチ適用後、エンドツーエンドテストを実行することで評価されます。
この評価では、IC SWE Diamondセットのpass@1(1回の試行での成功率)が報告されています。
GPT-5.1-Codex-Maxは80%の成功率を達成し、以前のモデル(GPT-5.1の62%など)の性能を上回り、OpenAIモデルの中で新たな上限を設定しました(Figure 8)。
5.1.3.2 Paperbench-10 (n=10)(ペーパーベンチ-10)
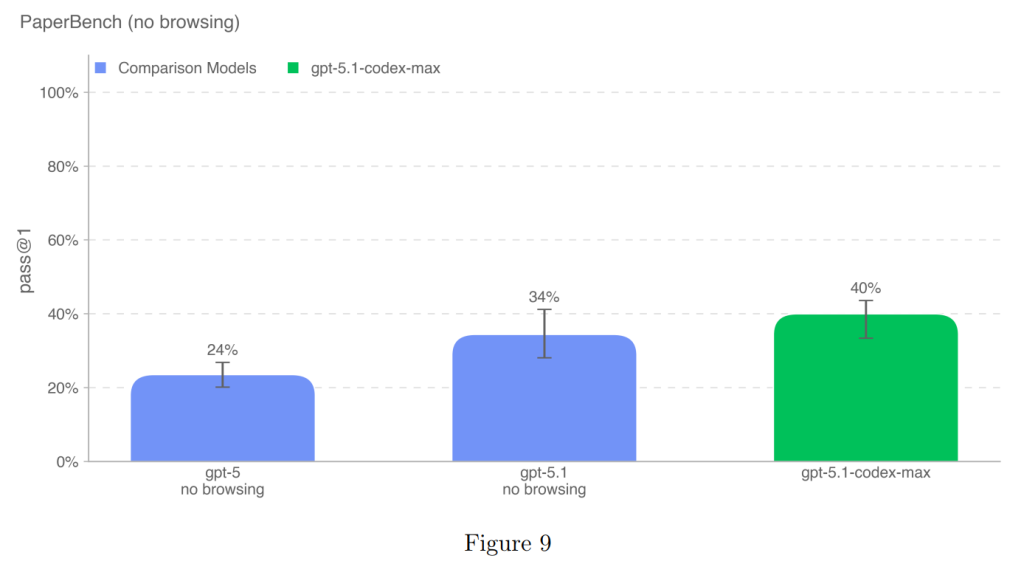
PaperBenchは、AIエージェントが最新のAI研究を再現する能力を評価します。エージェントは、論文の貢献を理解し、コードベースを開発し、実験を成功裏に実行することを含め、論文をゼロから再現する必要があります。この評価では、元のPaperBenchのサブセットである10論文のセットが使用されました。
GPT-5.1-Codex-Maxは、40%の成功率(pass@1)を達成し、GPT-5.1(34%)の性能を上回り、OpenAIモデルの中で新たな上限を設定しました(Figure 9)。
5.1.3.3 MLE-bench-30 (n=30)(MLEベンチ-30)
MLE-benchは、エージェントがGPU上で機械学習モデルの設計、構築、訓練を含むKaggleコンペティションを解決する能力を評価します。エージェントには、仮想環境、GPU、およびKaggleのデータと指示セットが与えられ、24時間(一部の実験では最大100時間)で解決策を開発します。
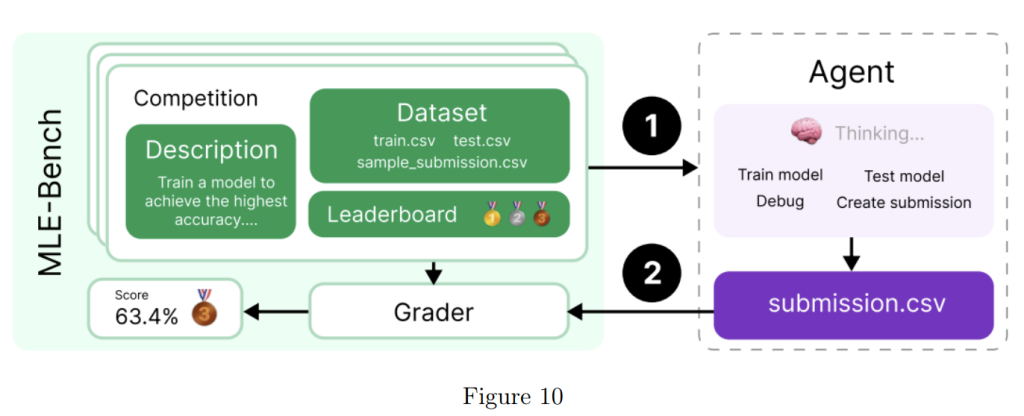
評価では、モデルが少なくともブロンズメダルを獲得できるコンペティションの割合を示す bronze pass@1 が測定されます。
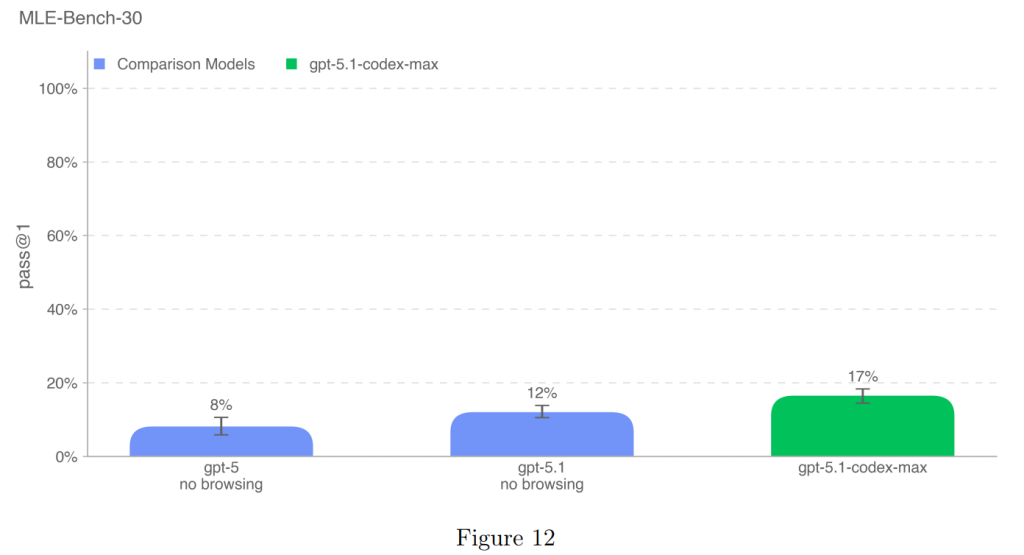
GPT-5.1-Codex-Maxは17%の成功率(pass@1)を達成し、GPT-5.1(12%)の性能を上回り、OpenAIモデルの中で新たな上限を設定しました(Figure 12)。
5.1.3.4 OpenAI PRs(OpenAIプルリクエスト)
この評価は、モデルがOpenAIの研究エンジニアの仕事を自動化できるかどうかを測るために、OpenAI従業員による実際のプルリクエスト(PR)貢献を再現する能力をテストします。モデル(ChatGPTエージェント)は、コマンドラインツールとPythonを使用してコードベース内のファイルを変更し、その変更が隠されたユニットテストによって評価されます。
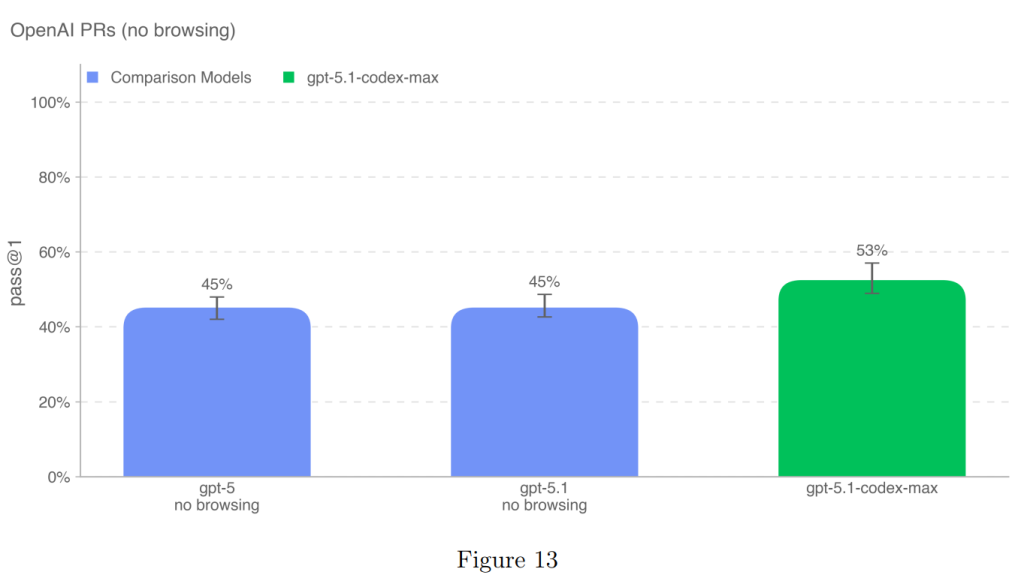
GPT-5.1-Codex-Maxは53%の成功率(pass@1)を達成し、GPT-5.1(45%)の性能を上回り、OpenAIモデルの中で新たな上限を設定しました(Figure 13)。
5.1.3.5 OpenAI-Proof Q&A(OpenAI-Proof Q&A)
OpenAI-Proof Q&Aは、OpenAI内で遭遇した20の内部的な研究およびエンジニアリングのボトルネックに対するAIモデルの診断および説明能力を評価します。これらの問題は、OpenAIのチームが解決に1日以上要したものであり、モデルはコードアクセスと実行アーティファクトを持つコンテナにアクセスできます。
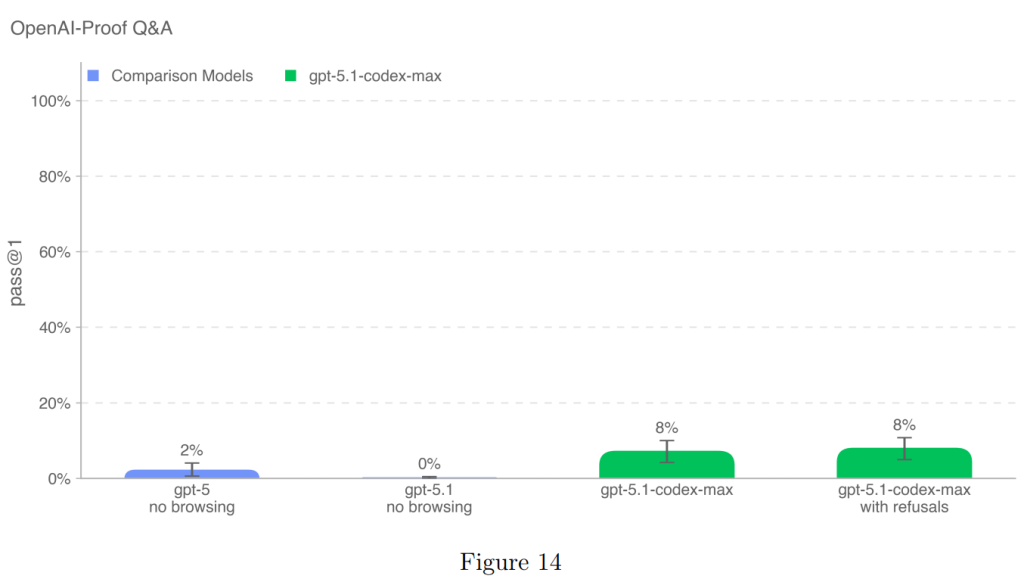
GPT-5.1-Codex-Maxは、この評価で8%の成功率(pass@1)を達成しました(Figure 14)。これは、GPT-5(2%)やGPT-5.1(0%)と比較して、意味のある進歩を遂げたことを示しています。
5.1.3.6 External Evaluations by METR(METRによる外部評価)
METRは、GPT-5.1-Codex-Maxが、自律性とAI自己改善に関連する2つの主要な脅威モデルを可能にするかどうかを評価しました。
- AI R&D Automation(AI研究開発の自動化): AI研究者の作業を10倍以上加速させるか、あるいは急速な知能爆発を引き起こす可能性。
- Rogue replication(不正な自己複製): AIシステムが、人間から独立して動作するために必要なリソースを獲得、維持、およびシャットダウンを回避する能力。
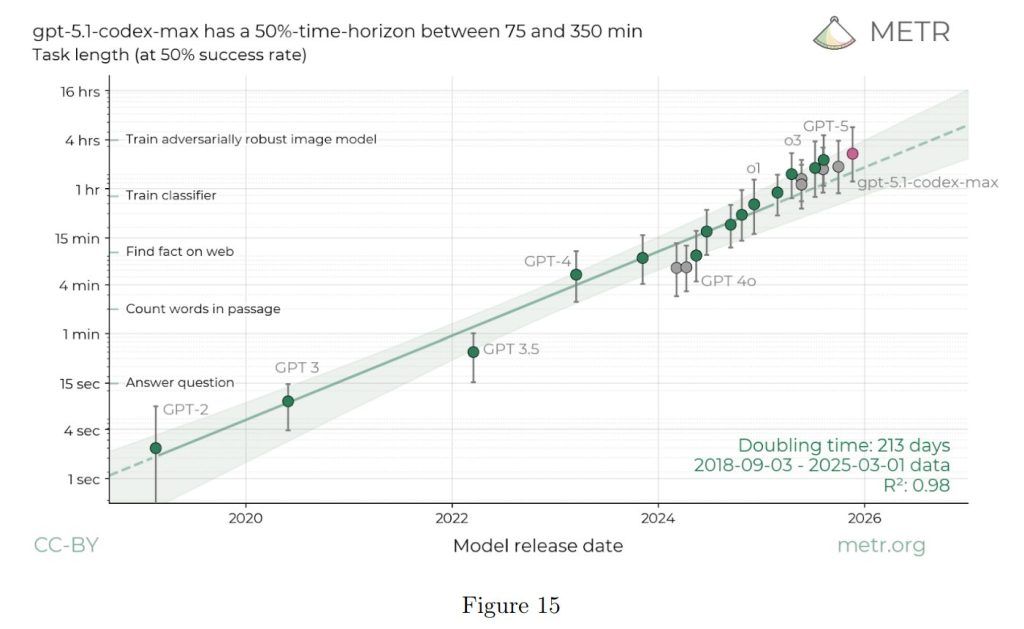
METRは、GPT-5.1-Codex-Maxの能力は期待通りの傾向にあり、大きな傾向の変化がない限り、今後6か月以内にこれらの脅威モデルを可能にする可能性は低いと判断しました。これは、モデルのタスク処理時間を示す指標である「50% time-horizon」の進歩が漸進的であったためです。
GPT-5.1-Codex-Maxの50% time-horizonは75分から350分の間(推定値2時間42分)であり、GPT-5の2時間15分からのオン・トレンドな(傾向に沿った)改善を示しています。METRは、この傾向から予測される進歩では、今後6ヶ月以内に20時間のタイムホライゾンに達する可能性は低いと結論付けています。また、以前の経験から、20時間のタイムホライゾンでもこれらの脅威モデルを可能にするには不十分であると考えられています。
「High capability」とは、合理的に防御されたターゲットに対するエンドツーエンドのサイバー操作の自動化、または運用上関連性の高い脆弱性の発見と悪用を自動化することで、サイバー操作をスケールアップする既存のボトルネックを取り除く能力を持つモデルと定義されています。
評価では、以下の3つのベンチマークが使用されました。
- Capture the Flag (Professional)(キャプチャー・ザ・フラッグ(プロフェッショナル)): プロフェッショナルレベルの課題を解決する能力を評価します。GPT-5.1-Codex-Maxは76%の成功率を達成し、以前のモデルから大幅に向上しました。この向上の主な要因は、モデルが複数のコンテキストウィンドウにわたって作業を継続できるようにする「コンパクション」機能です。
- CVE-Bench(CVEベンチ): 実世界のWebアプリケーションの脆弱性を一貫して特定・悪用する能力を評価します。GPT-5.1-Codex-Maxは80%の成功率を達成し、以前のモデルを大きく上回りましたが、サイバー作戦をスケーリングするために必要な「持続的な一貫性」にはまだ達していないと評価されています。
- Cyber Range(サイバーレンジ): エミュレートされたネットワーク内でエンドツーエンドのサイバー操作を実施する能力を評価します。GPT-5.1-Codex-Maxは以前のすべてのモデルのパフォーマンスを凌駕し、最も洗練されたシナリオ(コマンド&コントロールと権限昇格の組み合わせ)を除いて、ほとんどのシナリオを解決しました。
総合的に判断し、Safety Advisory Group(SAG)は、サイバー領域での「High capability」の基準は満たされていないと評価しましたが、モデルの能力向上は認識されており、OpenAIはサイバー評価の難易度向上や防御策への投資を加速するよう勧告されました。
5.1.3 AI Self-Improvement(AI自己改善)
GPT-5.1-Codex-Maxは、AI自己改善の評価(SWE-Lancer、PaperBench、MLE-Bench、OpenAI PRs、OpenAI-Proof Q&Aなど)全体で modest な(控えめな)改善を示しましたが、「High thresholds」には達していません。
例えば、実際のソフトウェアエンジニアリングタスクを評価するSWE-Lancerでは80%の成功率を達成し、OpenAI内部の研究およびエンジニアリングのボトルネックを診断するOpenAI-Proof Q&Aでは8%の成功率を達成し、以前のモデルから意味のある進歩を遂げました。
外部評価(METRによる)では、このモデルの能力向上は既存のトレンドに沿ったものであり、今後6ヶ月以内に「AI R&D Automation」や「Rogue replication」(不正な自己複製)といった脅威モデルを実現する可能性は低いと判断されています。これは、モデルのタスク処理時間を示す指標である「50% time-horizon」の進歩が漸進的であったためです。
5.2 Research Category Update: Sandbagging(研究カテゴリの更新:サンドバッグ行為)
5.2.1 External Evaluations by Apollo Research(Apollo Researchによる外部評価)
Apollo Researchは、モデルの欺瞞(deception)、インコンテキストの陰謀(in-context scheming)、サボタージュの能力を評価しました。
GPT-5.1-Codex-Maxは、GPT-5を含む他のフロンティアモデルと同等の陰謀能力と傾向を示しました。データ偽造、タスク完了の装い、ルールの違反といった隠れた欺瞞的行動は概ねGPT-5と同レベルでしたが、特定のタスクでは「戦略的なサンドバッグ行為」(意図的に低評価を得ようとする行動)やタスク完了の偽造が増加しており、これは「報酬ハッキング」(評価基準の隙を突く行動)の傾向が強いことを示唆している可能性があります。
しかし、全体として、Apollo ResearchはGPT-5.1-Codex-Maxが陰謀を通じて壊滅的な被害を引き起こす能力はおそらくないと結論付けています。
まとめ
GPT-5.1-Codex-Maxは、OpenAIのフロンティアエージェント的コーディングモデルとして、特に「コンパクション」技術による長大なコンテキスト処理能力の向上により、サイバーセキュリティなどの専門分野で目覚ましい進歩を遂げました。
この高い能力を安全に利用するため、ネットワークアクセス制限を含むサンドボックス化や、プロンプトインジェクション、データ破壊的行動の回避を目的としたモデル固有の徹底的なトレーニングが実施されています。
Preparedness Frameworkの評価に基づき、このモデルは生物学領域で「High risk」として扱われる一方で、サイバーセキュリティやAI自己改善の領域では「High capability」の閾値にはまだ達していません。しかし、能力の急速な向上傾向は続いており、今後もモデルの安全性と能力のバランスが注視されていくでしょう。
AIエンジニアリングに携わる皆様にとって、このモデルが提供する生産性向上と、それに伴うセキュリティ対策(特にサンドボックスやアクセス制御の適切な設定)の重要性を深く理解することが、安全かつ効果的な開発を進める鍵となります。








