
はじめに
Google DeepMindとGoogle Core MLが2025年11月19日、リアルタイムで音声を音声に直接翻訳するエンドツーエンドモデルを発表しました。従来の音声翻訳システムが抱えていた4〜5秒の遅延を2秒まで短縮し、元の話者の声を保ったまま翻訳できる技術です。本稿では、この技術の仕組みと実用化への取り組みについて解説します。
参考記事
- タイトル: Real-time speech-to-speech translation
- 著者: Karolis Misiunas (Research Engineer, Google DeepMind), Artsiom Ablavatski (Software Engineer, Google Core ML)
- 発行元: Google Research Blog
- 発行日: 2025年11月19日
- URL: https://research.google/blog/real-time-speech-to-speech-translation/
要点
- Google DeepMindは、2秒の遅延で元の話者の声を保ったままリアルタイム翻訳を実現するエンドツーエンドのS2ST(Speech-to-Speech Translation)モデルを開発した
- 従来のカスケード方式(ASR→機械翻訳→TTS)では4〜5秒の遅延、エラーの蓄積、パーソナライゼーション不足が課題だった
- 時刻同期されたデータを生成するスケーラブルなパイプラインと、AudioLMフレームワークをベースとしたストリーミングアーキテクチャを開発した
- Google MeetとPixel 10デバイスで実装され、現在は英語と5つのラテン語系言語間の翻訳に対応している
詳細解説
従来のカスケード方式S2STの課題
従来のリアルタイム音声翻訳技術は、カスケード方式と呼ばれる3段階の処理を経由していました。まず、音声認識(ASR)で元の音声をテキストに変換し、次に機械翻訳(MT)でテキストを目標言語に翻訳し、最後にテキスト読み上げ(TTS)で音声に戻すという流れです。

Googleによれば、この方式には3つの主要な課題がありました。第一に、4〜5秒の大きな遅延が発生し、会話が交代制になってしまう点。第二に、各段階でエラーが蓄積される点。第三に、汎用的なTTS技術を使用するため、元の話者の声の特徴が失われるパーソナライゼーション不足の問題です。
カスケード方式は各コンポーネントの品質が高い場合でも、複数の処理を経由することで遅延とエラーが累積するという構造的な限界があります。リアルタイムの自然な会話体験を実現するには、この処理の流れ自体を見直す必要がありました。
エンドツーエンドS2STモデルの開発
この課題を解決するため、Googleは2つの技術的な柱を開発しました。
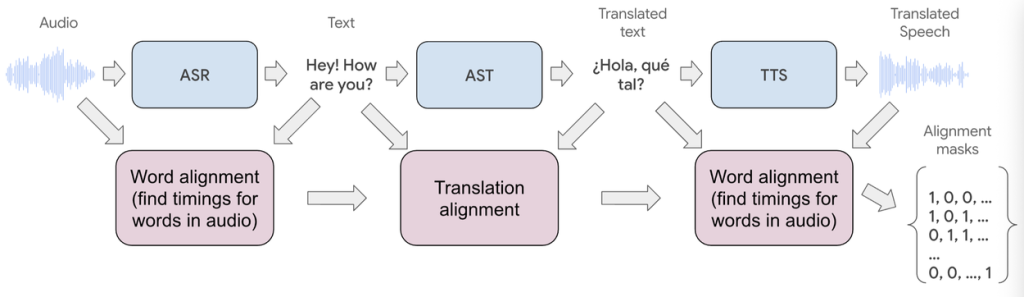
第一は、スケーラブルなデータ取得パイプラインです。このパイプラインは、生の音声データを時刻同期された入力・出力データセットに変換します。具体的には、既存のASRとTTS技術を統合し、精密なアライメント処理を行うことで、翻訳後の音声が入力と最適に対応するようにしています。処理の流れとしては、まず音声の文字起こしを行い、forced alignmentアルゴリズムで音声とテキストの対応関係を生成します。その後、機械翻訳でテキストを翻訳し、元の音声の声質を保持したままTTSで翻訳音声を生成します。最後に、入力音声と翻訳音声の間のアライメントマスクを計算し、これを学習時の損失計算に使用します。
forced alignmentとは、音声信号とテキストの間の時間的な対応関係を自動的に見つける技術で、音声認識や音声合成の分野で広く使われている手法です。アライメントに失敗した音声セグメントは学習データから除外され、厳格なフィルタリングと検証プロセスを経て、最大60秒のチャンクで学習データが作成されます。
第二は、リアルタイム音声翻訳アーキテクチャです。GoogleのAudioLMフレームワークとTransformerブロックをベースに、時刻同期データでの学習をサポートする音声専用のストリーミング機械学習アーキテクチャを開発しました。
AudioLMは、Googleが2022年に発表した音声生成のための言語モデルアプローチで、音声を離散的なトークン列として扱うことで高品質な音声生成を実現する技術です。このアーキテクチャは連続的な音声ストリームを処理できるよう設計されており、モデルが翻訳出力のタイミングを自律的に決定できます。
モデルアーキテクチャの詳細
Googleによれば、エンドツーエンドS2STモデルは2つの主要コンポーネントで構成されています。
ストリーミングエンコーダーは、直前の10秒間の入力に基づいて元の音声データを要約します。ストリーミングデコーダーは、圧縮されたエンコーダーの状態と過去の予測を使用して、翻訳音声を自己回帰的に予測します。
このモデルの特徴は、音声をRVQ(Residual Vector Quantization)オーディオトークンと呼ばれる2次元のトークンセットで表現する点です。X軸が時間を、Y軸が現在の音声セグメントを記述するトークンのセットを表します。特定のセット内のすべてのトークンを合計すると、MLコーデックを使って音声ストリームに容易に変換できます。Googleの説明では、通常100msのチャンクを高品質に表現するには16個のトークンで十分とされています。
モデルは音声トークンに加えて、単一のテキストトークンも出力します。このテキストトークンは音声生成の追加的な事前情報として機能し、ASRシステムに依存せずにBLEUスコアなどの指標を直接計算できるようにします。BLEUは機械翻訳の品質を評価する標準的な指標です。
遅延と品質のトレードオフ
学習時には、トークンごとの損失関数が適用され、正確な翻訳を保証します。Googleによれば、モデルの予測遅延(lookahead)は、正解トークンを右にシフトすることで調整可能で、目標言語の複雑さに応じた柔軟性を提供します。
リアルタイム会話では、標準的に2秒の遅延が使用されており、これはほとんどの言語に適しています。lookaheadを長くすると、より多くの文脈が得られるため翻訳品質は向上しますが、リアルタイムコミュニケーション体験には悪影響を及ぼします。Googleの実験では、スペイン語・英語の言語ペアにおいて、lookaheadの長さとBLEUスコアの関係が示されています。
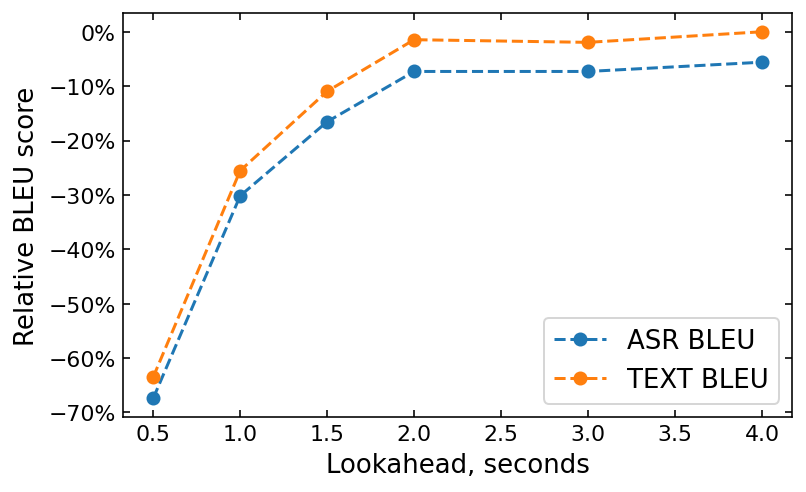
2秒の内部遅延に加えて、モデルの推論時間がシステム全体のレイテンシーに寄与します。リアルタイム性能を実現するため、int8およびint4のハイブリッド低ビット量子化や、最適化されたCFG(Classifier-Free Guidance)の事前計算など、複数の最適化技術が実装されています。量子化とは、モデルのパラメータをより少ないビット数で表現することで、メモリ使用量と計算量を削減する技術です。
実世界での応用
この新しいエンドツーエンドS2ST技術は、2つの重要な領域で展開されています。Googleによれば、Google Meetのサーバー上で利用可能になったほか、新しいPixel 10デバイスには組み込み機能として搭載されています。
両製品はS2STパイプラインの実行に異なる戦略を使用していますが、学習データとモデルアーキテクチャは共有されています。Pixel Voice Translateのオンデバイス機能では、言語カバレッジを最大化するためにカスケード方式も併用されているとのことです。機能の悪用を防ぐため、各翻訳セッションの前に、翻訳が合成的に生成されたものであることをエンドユーザーに通知する仕組みも導入されています。
現在のエンドツーエンドモデルは、5つのラテン語系言語ペア(英語との間でスペイン語、ドイツ語、フランス語、イタリア語、ポルトガル語)で堅実な性能を発揮しており、初期製品の展開を可能にしています。また、ヒンディー語などの他の言語でも有望な能力が観察されており、今後さらに開発を進める予定とされています。
Googleによれば、将来的な改善は、モデルのlookaheadの動的性を向上させることに焦点を当てるとのことです。これにより、語順が英語と大きく異なる言語にもシームレスに対応でき、逐語的な翻訳ではなく、より文脈に即した翻訳が可能になると考えられます。
まとめ
Google DeepMindが発表したエンドツーエンドS2STモデルは、従来のカスケード方式の課題を克服し、2秒の遅延で元の話者の声を保ったリアルタイム翻訳を実現しました。時刻同期データの生成パイプラインとストリーミングアーキテクチャの開発により、Google MeetやPixel 10での実用化が進んでいます。今後、より多くの言語への対応や、語順の異なる言語への適応が期待されます。








