
はじめに
Google ResearchとGoogle DeepMindが2025年11月13日、天然林と植林を区別する全球マップ「Natural Forests of the World 2020」を公開しました。EU森林破壊規制(EUDR)などへの対応を目的とし、10メートル解像度で92.2%の精度を達成しています。本稿では、この技術の仕組みと実装方法について解説します。
参考記事
メイン記事:
- タイトル: Separating natural forests from other tree cover with AI for deforestation-free supply chains
- 著者: Maxim Neumann, Charlotte Stanton
- 発行元: Google Research Blog
- 発行日: 2025年11月13日
- URL: https://research.google/blog/separating-natural-forests-from-other-tree-cover-with-ai-for-deforestation-free-supply-chains/
関連情報:
- タイトル: Natural Forests of the World 2020 – Dataset
- 発行元: Google Earth Engine Catalog
- 発行日: 2025年11月13日
- URL: https://developers.google.com/earth-engine/datasets/catalog/projects_nature-trace_assets_forest_typology_natural_forest_2020_v1_0_collection
- タイトル: GeeFlow – Large scale datasets generation
- 発行元: Google DeepMind GitHub
- 発行日: 2025年
- URL: https://github.com/google-deepmind/geeflow
- タイトル: Jeo – Model training and inference for geospatial AI
- 発行元: Google DeepMind GitHub
- 発行日: 2025年
- URL: https://github.com/google-deepmind/jeo
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Google ResearchとGoogle DeepMindは、天然林と植林を区別する全球マップ「Natural Forests of the World 2020」を10メートル解像度で公開した
- MTSViT(Multi-modal Temporal-Spatial Vision Transformer)モデルを使用し、Sentinel-2衛星画像と地形データを時系列で分析することで92.2%の精度を達成した
- EU森林破壊規制(EUDR)への対応を主目的とし、2020年12月31日時点の天然林をベースラインとして提供する
- データセット生成用のGeeFlowとモデル訓練用のJeoという2つのオープンソースライブラリが公開され、研究者や開発者が同様の手法を実装できる
- 2026年には6つの森林タイプ(原生林、自然再生林、植林、プランテーション、樹木作物、その他)を区別する新マップのリリースが予定されている
詳細解説
天然林識別の課題とEU規制の背景
森林は降雨の調整、洪水の緩和、炭素の貯蔵・吸収といった重要な機能を持ち、陸上生物種の大部分を支えています。しかし、森林破壊は依然として深刻な速度で進行しています。
Googleによれば、従来の衛星データを用いた森林マッピングでは、数百年続く天然林生態系と新たに植えられた森林や樹木作物プランテーションを区別することが困難でした。既存のマップの多くは単に「樹木被覆」を示すのみで、これは木質植生の基本的な測定値に過ぎません。この結果、短期的なプランテーションの伐採と、生物多様性に富んだ天然林の永続的な喪失を同列に扱う「リンゴとオレンジの比較」のような状況が生じていました。
この区別の必要性は、EU森林破壊規制(EUDR)などの新たな国際規制によってさらに重要になっています。EUDRは、コーヒー、カカオ、ゴム、木材、パーム油などの製品がEU市場で販売される際、2020年12月31日以降に森林破壊または劣化した土地由来であってはならないと定めています。この規制は、原生林や自然再生林などの天然林を保護することを目的としており、2020年時点の天然林を示す信頼性の高い高解像度マップが必要とされています。
EUDRは2024年に施行された規制で、企業がサプライチェーンにおける森林破壊リスクを評価し、デューデリジェンスを実施することを義務付けています。この規制への対応には、信頼できる森林マップと継続的なモニタリングシステムが不可欠です。
MTSViTモデルの技術的アプローチ
単一の衛星画像から天然林と複雑なアグロフォレストリーシステムや50年前に植えられた森林を区別することは困難です。Googleはこの課題を克服するため、森林管理者のように1年間にわたって土地の変化を観察するAIモデルを開発しました。
MTSViT(Multi-modal Temporal-Spatial Vision Transformer)モデルは、1,280×1,280メートルのパッチを分割し、その中の各10×10メートルピクセルが天然林である確率を推定します。このアプローチにより、モデルは単一のスナップショットではなく、周囲の文脈に基づいて評価を行うことができます。
Vision Transformerは、画像認識分野で近年注目されているアーキテクチャで、画像をパッチに分割し、各パッチ間の関係性を自己注意機構(Self-Attention)で学習する手法です。MTSViTはこれを拡張し、時系列データと空間データを同時に処理できるように設計されています。
モデルは、Sentinel-2衛星による季節ごとの画像データと地形データ(標高、傾斜、方位など)を分析します。時間経過を観察することで、複雑な天然林と均一で成長の速い商業プランテーションを区別する独特のスペクトル、時間的、テクスチャ的特徴(異なる森林タイプを認識するためのデータパターン)を識別します。
Sentinel-2は欧州宇宙機関(ESA)が運用する地球観測衛星で、10メートル解像度で13のスペクトルバンドを提供します。マルチスペクトル画像により、可視光だけでなく近赤外線や短波赤外線のデータも取得でき、植生の健康状態や種類の識別に有効です。
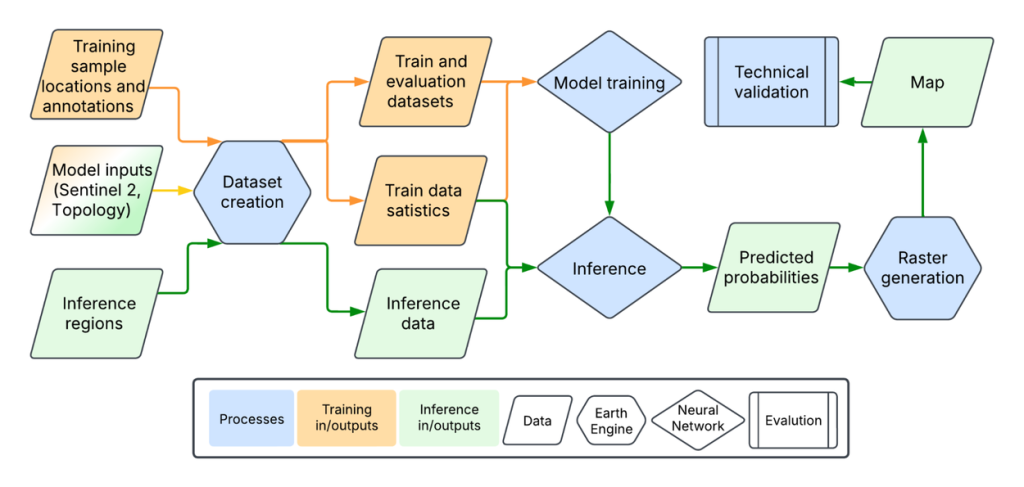
データセット構築とグローバルマップ生成
Natural Forests of the World 2020マップを構築するため、研究チームは全球で120万箇所以上の1,280×1,280メートルパッチを10メートル解像度でサンプリングし、大規模なマルチソースの訓練データセットを作成しました。
このデータを使用してMTSViTモデルを訓練し、天然林とその他の土地タイプの複雑なパターンを認識させました。訓練されたモデルを地球上のすべての陸地に適用することで、シームレスで全球一貫性のある10メートル確率マップが生成されました。
Googleによれば、マップを厳密に検証するため、2015年の全球森林管理に焦点を当てた独立データセットを再利用し、そのラベルを2020年の天然林に焦点を当てるように更新した評価データセットを作成しました。この独立した全球データセットとの照合において、92.2%の精度を達成しています。
この精度水準は、リモートセンシングによる土地被覆分類としては高い水準と言えます。一般的な土地被覆分類では80-85%程度の精度が標準的とされる中、92.2%という数値は実用的な応用に十分な精度と考えられます。ただし、複雑なアグロフォレストリーシステムや小規模農業モザイク、疎林(サバンナなど)、火災や伐採直後の森林など、一部の状況では識別が困難な場合があることも報告されています。
実装可能なオープンソースツール
Googleは、この研究で使用された手法を研究者や開発者が再現・応用できるよう、2つの主要なオープンソースライブラリを公開しています。
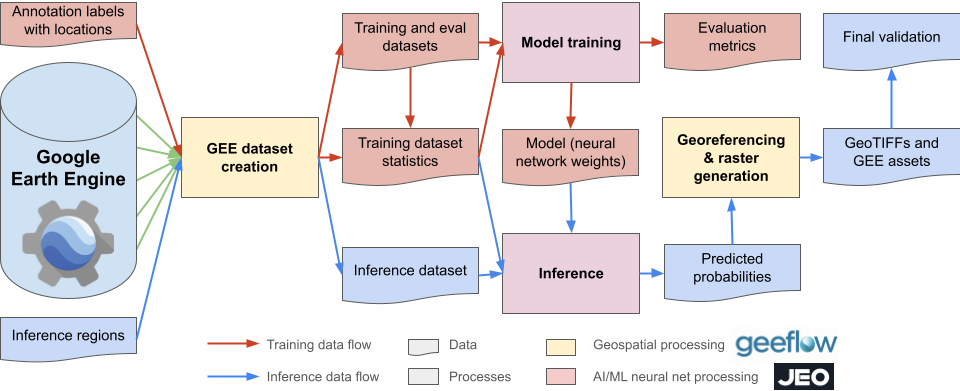
GeeFlowは、Google Earth Engine(GEE)を使用して大規模な地理空間データセットを生成するためのライブラリです。衛星画像やリモートセンシングデータ、GEEからのラベルデータなど、任意のタイプの地理空間データをサポートし、任意の空間的・時間的解像度でデータをサンプリングできます。
設定ファイルにより、データソース、空間解像度、時間範囲、使用するバンドなどを柔軟に指定できます。例えば、Sentinel-2の特定のバンド(RGB)を10メートル解像度で年次集約する設定や、Sentinel-1のレーダーデータを季節ごとにサンプリングする設定などが可能です。生成されたデータはTensorFlow Datasets(TFDS)形式で出力され、機械学習パイプラインに直接統合できます。
Jeoは、JAXとFlaxを使用した地理空間リモートセンシングおよび地球観測のためのモデル訓練・推論フレームワークです。効率的なデータパイプラインのためにtf.dataを活用し、TensorFlow Datasetsとの統合に重点を置いています。CPU、GPU、Google Cloud TPU VMでシームレスに動作するように設計されています。
これらのライブラリは、Natural Forests of the World 2020マップの作成に使用された実際のワークフローを反映しており、研究者や開発者が同様の手法を自身のプロジェクトに適用することを可能にします。
実装の基本的な流れは以下の通りです:
- GeeFlowを使用してGoogle Earth Engineから必要な衛星画像と地形データを取得し、訓練データセットを構築
- 生成されたTFDS形式のデータセットをJeoに読み込み
- MTSViTまたは独自のモデルアーキテクチャを定義し訓練
- 訓練されたモデルを使用して推論を実行し、マップを生成
この一連のプロセスは、適切な計算リソース(特にGPUまたはTPU)があれば、研究機関や企業でも実装可能と考えられます。
今後の展開と6分類マップ
Googleは、2026年に新たな多年次の全球森林タイプマップシリーズをリリースする予定です。これらのマップは、世界の土地を6つの異なるタイプに分類します:原生林、自然再生林、植林、プランテーション林、樹木作物、その他の土地被覆です。
この分類により、森林の種類をより詳細に区別し、時間経過に伴う変化を理解することが可能になります。例えば、生態系に優しいコーヒーやカカオのアグロフォレストリーシステムと、大規模な商業プランテーションを区別できるようになります。
また、研究コミュニティへの貢献を促進するため、2つの大規模ベンチマークデータセットも公開されています。Plantedデータセットは、64種類の植林や樹木作物を認識するための230万以上の時系列分類例を含むグローバルなマルチセンサー長時系列データセットです。Forest Typology(ForTy)ベンチマークは、天然林、植林、樹木作物のセマンティックセグメンテーションモデル向けに、20万のマルチソースおよびマルチテンポラル画像パッチとピクセル単位のラベルを提供します。
これらのベンチマークデータセットは、次世代のAIモデルの開発と厳密なテストを可能にし、森林分析の精度向上に貢献すると期待されます。
データアクセスと活用方法
Natural Forests of the World 2020マップは、複数の方法でアクセス可能です。Google Earth Engineのカタログを通じて、研究者や開発者はプログラマティックにデータを取得できます。また、確率マップとしても公開されており、ユーザーは自身のニーズに合わせて確率閾値を適用し、二値の天然林マップを作成できます。
データはCC-BY 4.0ライセンスで公開されており、「This dataset is produced by Google」という帰属表示を行うことで、研究、教育、商業目的での利用が可能です。
実用的な応用例としては、企業がサプライチェーンのデューデリジェンスを実施する際に、原材料の調達地が天然林の破壊に関与していないかを確認する用途が考えられます。政府機関は森林破壊のモニタリングに活用でき、保全団体は保護活動の優先順位付けに使用できるでしょう。
技術的には、Google Earth Engine APIを通じて、JavaScriptまたはPythonでマップデータにアクセスし、カスタム分析や可視化を行うことができます。Earth Engineの計算能力を活用することで、ペタバイト規模のデータ処理も可能になります。
まとめ
Google ResearchとGoogle DeepMindによるNatural Forests of the World 2020マップは、AIを活用して天然林と植林を全球規模で区別する初の高解像度マップです。EUDRなどの規制対応に必要な基準を提供するとともに、オープンソースツールの公開により、研究者や開発者が同様の手法を実装できる環境が整いました。2026年に予定されている6分類マップのリリースにより、森林モニタリングと保全活動がさらに高度化することが期待されます。








