
はじめに
近年、大規模言語モデル(LLM)の進化は目覚ましく、私たちの生活やビジネスに大きな影響を与え始めています。しかし、これらのモデルを特定の目的や分野に合わせてさらに高性能化するためには、「ファインチューニング」というプロセスが不可欠です。このファインチューニングには、しばしばプライバシーに配慮が必要なデータが用いられるため、その取り扱いが大きな課題となります。
本稿では、個人のプライバシーを厳格に保護しながらLLMのファインチューニングを行うための新しいアプローチについて、Google Researchが2025年5月23日に発表したブログ記事「Fine-tuning LLMs with user-level differential privacy」を基に、ユーザーレベルの差分プライバシー(User-level Differential Privacy) という技術が、どのようにしてこの課題を解決するのか、分かりやすく解説します。
引用元記事
- タイトル: Fine-tuning LLMs with user-level differential privacy
- 発行元: Google Research
- 発行日: 2025年5月23日
- URL: https://research.google/blog/fine-tuning-llms-with-user-level-differential-privacy/
要点
- 大規模言語モデル(LLM)の性能を特定ドメインで最大化するにはファインチューニングが有効であるが、使用データがプライバシーセンシティブである場合が多い。
- 差分プライバシー(DP) は、学習プロセスにノイズを注入することで、訓練データに対するプライバシーを厳密に保証する技術である。
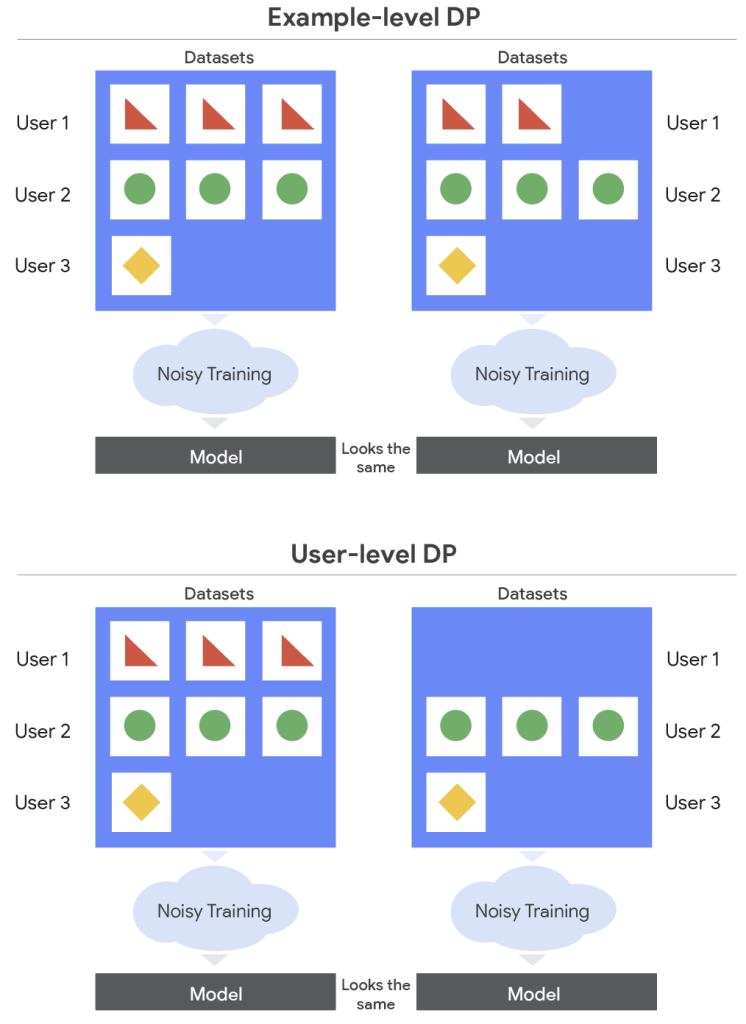
- 従来のDP研究の多くは、個々のデータ例のプライバシーを保護する事例レベルDP(example-level DP) に焦点を当てていたが、これには限界がある。特定のユーザーが多数のデータ例を提供している場合、個々のデータ例が保護されてもユーザーに関する情報が漏洩する可能性がある。
- ユーザーレベルDP(user-level DP) は、より強力なプライバシー保護形態であり、攻撃者がモデルを使用しても、特定のユーザーのデータが学習データセットに含まれていたかどうかといった情報を学習できないことを保証する。これは、データが実際にどのように所有されているかをよりよく反映する。
- ユーザーレベルDPは事例レベルDPよりも厳密であり、より多くのノイズを必要とするため、特に大規模モデルでは実装が困難である。
- 本研究(引用元記事)は、データセンターでのLLMのファインチューニングにおいて、ユーザーレベルDPを大規模に適用するためのアルゴリズム(ELSおよびULS)を調査し、最適化したものである。
- データセンターでの学習は、連合学習よりも柔軟性が高く、個々のデータ例やユーザー全体に対するクエリが可能であり、どのユーザーをクエリ対象にするかを選択できる。この柔軟性を活用して、より良い学習結果を目指した。
- 提案された最適化により、ELS(Example-Level Sampling)では必要なノイズ量を大幅に削減し、ELSとULS(User-Level Sampling)の両方で、貢献度バウンド(contribution bound) を事前に効果的に設定する戦略を開発した。
- 実験の結果、提案された最適化手法を用いることで、厳格なプライバシー要件下でも、事前学習済みモデルを使用するよりもユーザーレベルDPでファインチューニングした方が有利であることが示された。特に多くの場合でULSが優れた性能を示した。
詳細解説
なぜプライバシー保護が重要なのか? LLMと差分プライバシー
LLMは、大量のテキストデータで学習することで、人間のような自然な文章を生成したり、質問に答えたりする能力を獲得します。しかし、より専門的なタスクや特定のニーズに対応させるためには、その分野のデータセットを使って追加学習(ファインチューニング)を行う必要があります。例えば、医療分野のLLMであれば医療記録や論文データ、法律分野であれば判例データなどが考えられます。これらのデータは、非常に機密性が高く、個人のプライバシー情報 を含んでいることが少なくありません。
もし、このようなプライバシーセンシティブなデータが不適切に扱われ、LLMが学習内容を「記憶」してしまい、その結果として個人情報が出力されてしまうようなことがあれば、深刻なプライバシー侵害につながります。そこで登場するのが差分プライバシー(Differential Privacy: DP) という考え方です。
差分プライバシーとは、簡単に言えば、「ある個人のデータが学習データセットに含まれていてもいなくても、モデルの出力がほとんど変わらないようにする」ことで、個人のプライバシーを数学的に保証する仕組みです。これを実現するために、学習プロセスに意図的にランダムなノイズ(無作為なデータ)を加えます。このノイズによって、モデルが個々のデータの影響を受けすぎないようにし、特定の個人に関する情報がモデルから推測されるリスクを低減します。
「事例レベル」と「ユーザーレベル」のプライバシー:何が違うのか?
差分プライバシーには、保護の対象によっていくつかのレベルがあります。従来よく研究されてきたのは、事例レベルDP(example-level DP) です。これは、データセット内の個々のデータレコード(例えば、ある一人のユーザーが書いた1つのレビュー、1枚の写真など)のプライバシーを保護します。
しかし、これだけでは不十分な場合があります。例えば、あるユーザーAさんが、特定のサービスに関するレビューを100件投稿したとします。事例レベルDPでは、その100件のレビューそれぞれが個別に保護されます。しかし、攻撃者がモデルの挙動を分析することで、「ユーザーAさんのデータ群全体が学習に使われたかどうか」や「ユーザーAさんがどのような傾向のレビューを書くか」といった、ユーザーAさん個人に関する情報を推測できてしまうかもしれません。
そこで、より強力な保護を提供するのがユーザーレベルDP(user-level DP) です。これは、特定のユーザーに関連する全てのデータ(先の例で言えば、ユーザーAさんの100件のレビュー全て)が学習データに含まれていたとしても、そのユーザーに関する情報がモデルから漏洩しないように保護します。つまり、「あるユーザーのデータがごっそり学習に使われたか否か」を区別できないようにするのです。これは、特に一人のユーザーが多数のデータを生成する現代のデータ利用状況において、より現実的で強力なプライバシー保護と言えます。携帯電話のような分散型デバイスでモデルを学習する連合学習(Federated Learning) の分野では、このユーザーレベルDPが頻繁に利用されています。
しかし、ユーザーレベルDPは、事例レベルDPよりも厳格なため、学習の際により多くのノイズを加える必要 があります。ノイズを多く加えすぎると、モデルの学習がうまくいかず、性能が低下してしまうというジレンマがあります。特に、LLMのような巨大なモデルでは、この問題はさらに深刻になります。
データセンターでの学習の柔軟性を活かす
引用元記事の研究では、このユーザーレベルDPを、データセンターでLLMをファインチューニングする際に、いかに効率よく、かつモデルの性能を損なわずに実現するかに焦点を当てています。
データセンターでの学習は、各ユーザーのデバイス上で行う連合学習とは異なり、データが集中的に管理されているため、学習プロセスにおいてより柔軟な操作が可能です。例えば、
- 個々のデータ事例だけでなく、ユーザー単位でのデータアクセスが可能。
- 学習の各ラウンドで、どのユーザーのデータを利用するかを選択できる。
研究チームは、この柔軟性を最大限に活用して、ユーザーレベルDPを実現しつつ、モデルの性能低下を最小限に抑える方法を探求しました。
ユーザーレベルDPを実現する2つのアプローチ:ELSとULS
ユーザーレベルDPを実現するための主要なアルゴリズムとして、DP-SGD(Differential Privacy Stochastic Gradient Descent:差分プライバシー確率的勾配降下法)をベースにした2つの手法が比較検討されました。DP-SGDは、モデルの学習中に勾配(モデルのパラメータを更新するための情報)にノイズを付加することで差分プライバシーを実現する一般的な手法です。
- ELS (Example-Level Sampling:事例レベルサンプリング)
- まず、各ユーザーが学習データセットに提供できるデータ事例の最大数を制限します(これを貢献度バウンドと呼びます)。
- その後、通常のDP-SGDと同様に、データセットからランダムに個々のデータ事例をサンプリングしてバッチ(学習単位)を形成します。
- 事例レベルDPの保証をユーザーレベルDPの保証に変換するために、より多くのノイズを加えます。
- ULS (User-Level Sampling:ユーザーレベルサンプリング)
- こちらも同様に、貢献度バウンドを設定します。
- DP-SGDでバッチを形成する際に、ランダムにデータ事例をサンプリングする代わりに、ランダムにユーザーをサンプリングします。そして、サンプリングされたユーザーの全てのデータ事例(貢献度バウンドの範囲内)をバッチに含めます。
- この方法は、連合学習の考え方に近いですが、データセンターではランダムサンプリングが可能です。
これら2つのアプローチの大きな違いは、何をランダムにサンプリングするか(データ事例か、ユーザーか)という点です。
最適化の鍵:「貢献度バウンド」と「ノイズ量の削減」
これらのアルゴリズムをLLMにそのまま適用するだけでは、十分な性能は得られません。研究チームは、いくつかの重要な最適化を行いました。
- ELSにおけるノイズ量の最適化:
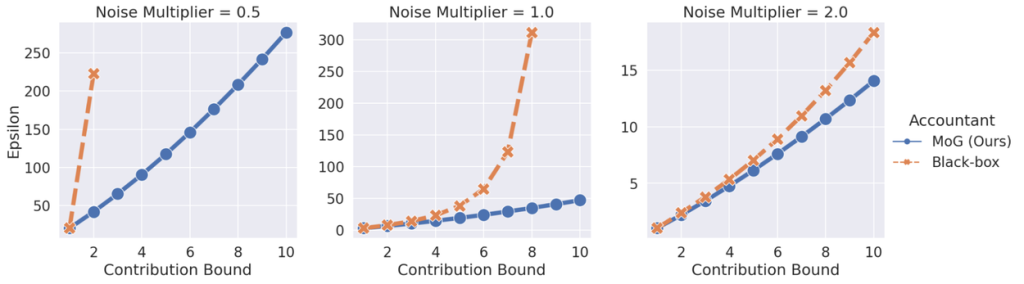
従来のELSでは、事例レベルDPからユーザーレベルDPへの変換の際に、必要以上に多くのノイズが加えられていました。研究チームは、理論的な解析を深めることで、同じプライバシー保証を保ちつつ、加えるノイズの量を大幅に削減できることを証明しました。ノイズが減れば、それだけモデルの学習精度が向上します。下のグラフは、貢献度バウンドに対して必要なプライバシーコスト(ε:イプシロン、小さいほどプライバシー保護が強い)を示しており、提案手法(MoG (Ours))が従来手法(Black-box)よりも大幅に少ないノイズで済むことを示しています。 - 貢献度バウンドの最適化戦略:
各ユーザーが提供できるデータ事例の最大数(貢献度バウンド)をどう設定するかは、性能に大きく影響します。貢献度バウンドを小さく設定しすぎると、多くのデータが切り捨てられてしまい、モデルが十分に学習できません。逆に大きく設定すると、プライバシーを保護するために大量のノイズが必要になり、やはり性能が低下します。
LLMの学習には非常にコストがかかるため、様々な貢献度バウンドで何度も試行錯誤するのは現実的ではありません。そこで、研究チームは、学習を開始する前に効果的な貢献度バウンドを決定するための戦略を開発しました。- ELSの場合:各ユーザーが持つデータ事例数の中央値を貢献度バウンドとする。
- ULSの場合:貢献度バウンドの関数として総ノイズ量を予測し、その予測を最小化する貢献度バウンドを選択する。
実験結果:ユーザーレベルDPでのファインチューニングは有効
これらの最適化を施したELSとULSを、3億5000万パラメータを持つTransformerモデルのファインチューニングタスクで比較しました。データセットには、StackOverflow(プログラミングQ&Aサイトのデータ)とCC-News(ニュース記事データ)が用いられました。
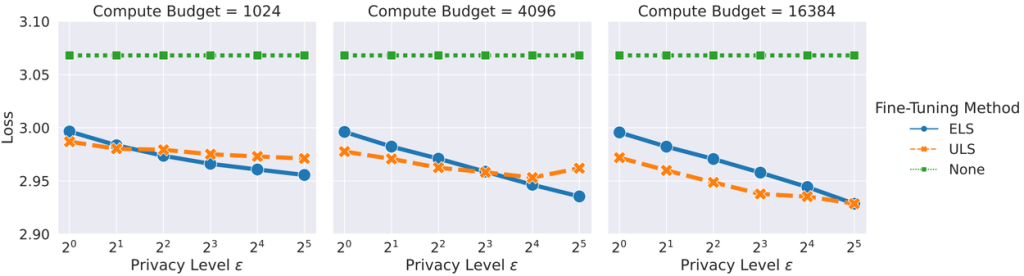
実験の結果、ほとんどの場合において、ULSがELSよりも優れた性能を示すことが分かりました。ただし、CC-Newsデータセットにおいて、より強いプライバシー保護を求める場合や、計算資源が少ない場合には、ELSの方が良い結果となることもありました。
特筆すべきは、これらの最適化により、厳格なユーザーレベルのプライバシー要件を満たしながらも、両手法ともに事前学習済みモデルをそのまま使うよりも優れた性能を達成したことです。これは、プライバシーを保護しつつ、ドメイン固有のデータでLLMを効果的にファインチューニングできることを示しています。
まとめ
本稿では、Google Researchによる「Fine-tuning LLMs with user-level differential privacy」という研究成果に基づき、ユーザーレベルの差分プライバシーを用いて大規模言語モデル(LLM)を安全にファインチューニングする手法について解説しました。
重要なポイントは以下の通りです。
- ユーザーレベルDPの重要性: 個々のデータだけでなく、ユーザー単位でのプライバシーを保護することで、より現実的で強力な情報漏洩対策となります。
- データセンター学習の活用: データセンターでの学習の柔軟性を活かし、ELSおよびULSという2つのアプローチでユーザーレベルDPを実現しました。
- 貢献度バウンドとノイズ量の最適化: ELSでは必要なノイズ量を理論的に削減し、両手法で貢献度バウンドを効率的に決定する戦略を開発することで、モデル性能の低下を最小限に抑えました。
- 実証された有効性: 実験により、ユーザーレベルDPを適用したファインチューニングが、プライバシーを保護しつつLLMの性能を向上させる上で有効であることが示されました。
この研究は、プライバシーに配慮が必要な機密データを用いてLLMを特定の目的に合わせて調整したいと考えている開発者や研究者にとって、非常に重要な道筋を示すものです。今後、このような技術がさらに発展し、より安全で信頼性の高いAIの活用が進むことが期待されます。私たちユーザーにとっても、自分のデータがどのように扱われるかを知り、プライバシーが保護された上でAIの恩恵を受けられるようになることは、非常に大きな意義があると言えるでしょう。








