はじめに
Googleが2026年1月28日、オンデバイスAI推論フレームワーク「LiteRT」の本格的な機能拡張を発表しました。TensorFlow Lite(TFLite)の後継として2024年に導入されたLiteRTは、GPU加速の大幅な性能向上(従来比1.4倍)、NPU統合の簡素化、GenAI対応の強化を実現し、モバイルからWebまで幅広いプラットフォームで動作します。本稿では、この発表内容をもとに、LiteRTの技術的特徴と実装方法について解説します。
参考記事
- タイトル: LiteRT: The Universal Framework for On-Device AI
- 著者: Lu Wang, Chintan Parikh, Jingjiang Li, Terry Heo
- 発行元: Google Developers Blog
- 発行日: 2026年1月28日
- URL: https://developers.googleblog.com/litert-the-universal-framework-for-on-device-ai/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- LiteRTは、TFLiteの基盤から進化したオンデバイスAI推論フレームワークで、GPU性能が従来比1.4倍高速化し、新たにNPU加速機能を本番環境に統合した
- Android、iOS、macOS、Windows、Linux、Webの6プラットフォームに対応し、OpenCL、OpenGL、Metal、WebGPUを介した統一的なGPU加速を提供する
- MediaTekおよびQualcommのNPUに対応し、CPUの最大100倍、GPUの最大10倍の高速化を実現する
- Gemma 3モデルのベンチマークでは、llama.cppと比較してCPUで3倍、GPUデコードで7倍、GPUプリフィルで19倍の性能向上を記録した
- PyTorch、TensorFlow、JAXからの直接変換をサポートし、.tflite形式による既存モデルとの互換性を維持する
詳細解説
TFLiteからLiteRTへの進化
Googleによれば、LiteRTは2024年の初期導入以降、TensorFlow Liteの基盤を現代的なオンデバイスAIフレームワークへと発展させることに注力してきました。TFLiteが従来の機械学習(ML)モデルの標準を確立したのに対し、LiteRTは最新のAIモデルをオンデバイスで同じようにシームレスに展開できることを目指しています。
2025年のGoogle I/Oで予告されていた高度なハードウェア加速機能が、今回の発表で正式に本番環境に統合されました。この進化により、LiteRTは従来のTFLiteと比較して、より高速で、シンプルで、強力かつ柔軟なフレームワークとして位置づけられています。
クロスプラットフォームGPU加速の全面展開
LiteRTは、Android、iOS、macOS、Windows、Linux、Webの6つのプラットフォームで包括的なGPU加速を提供します。これは、従来のCPU推論を大幅に上回る高性能な加速オプションを、開発者に提供するものです。
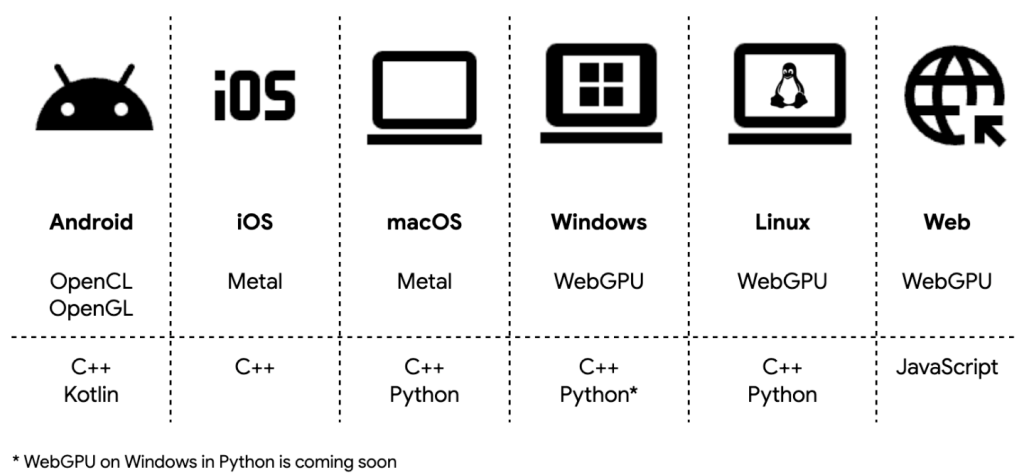
技術的には、OpenCL、OpenGL、Metal、WebGPUをサポートし、次世代GPUエンジン「ML Drift」を介して動作します。AndroidではOpenCLを優先的に使用し、利用できない場合はOpenGLにフォールバックすることで、デバイスカバレッジを広げています。
Googleの発表によれば、ML Driftにより、LiteRT GPUは従来のTFLite GPUデリゲートと比較して平均1.4倍の高速化を達成しました。この性能向上は、幅広いモデルにわたってレイテンシを大幅に削減するものです。
さらに、エンドツーエンドのレイテンシを最適化するため、非同期実行とゼロコピーバッファ相互運用という2つの技術的進歩が導入されました。これらの機能は、不要なCPUオーバーヘッドを削減し、全体的な性能を向上させます。背景分割や音声認識(ASR)のようなリアルタイムユースケースでは、これらの最適化により最大2倍の高速化が実現されると報告されています。
実装例として、新しいCompiledModel APIを使用したC++コードが公開されています:
// 1. GPUをターゲットとしたコンパイル済みモデルを作成
auto compiled_model = CompiledModel::Create(env, "mymodel.tflite",
kLiteRtHwAcceleratorGpu);
// 2. OpenGLバッファをラップした入力TensorBufferをゼロコピーで作成
auto input_buffer = TensorBuffer::CreateFromGlBuffer(env, tensor_type,
opengl_buffer);
std::vector<TensorBuffer> input_buffers{input_buffer};
auto output_buffers = compiled_model.CreateOutputBuffers();
// 3. モデルを実行
compiled_model.Run(inputs, outputs);
// 4. モデル出力(AHardwareBuffer等)にアクセス
auto ahwb = output_buffer[0]->GetAhwb();このAPIは、GPU加速を活用するための明確な実装パスを提供しており、既存のグラフィックスパイプラインとの統合を容易にすると考えられます。
NPU統合の簡素化と高性能化
CPUとGPUがAIタスクに幅広い汎用性を提供する一方、NPU(Neural Processing Unit)は、現代のアプリケーションが求めるスムーズで高速なAI体験を実現する鍵となります。しかし、数百種類のNPU SoCバリエーションにわたる断片化により、開発者は異なるコンパイラとランタイムを個別に扱う必要がありました。
LiteRTは、ベンダー固有のSDKを抽象化し、多数のSoCバリエーション間の断片化を処理する統一的で簡素化されたNPU展開ワークフローを提供します。このプロセスは3つのシンプルなステップに集約されています:
- ターゲットSoC向けのAOTコンパイル(オプション): LiteRT Pythonライブラリを使用して.tfliteモデルを事前コンパイル
- Android上でGoogle Play for On-device AI(PODAI)を使用した展開: PODAIを活用して互換デバイスにモデルとランタイムを自動配信
- LiteRTランタイムを使用した推論: LiteRTがNPU委譲を処理し、必要に応じてGPUまたはCPUへの堅牢なフォールバックを提供
LiteRTは、AOT(事前)コンパイルとオンデバイス(JIT)コンパイルの両方をサポートしています。AOTコンパイルは、既知のターゲットSoCを持つ複雑なモデルに最適で、起動時の初期化とメモリフットプリントを最小化します。一方、オンデバイスコンパイルは、さまざまなプラットフォームに小規模モデルを配布する場合に適していますが、初回実行時の初期化コストは高くなります。
Googleは、MediaTekおよびQualcommと緊密に協力し、本番環境対応のNPU統合を実現しました。技術的な詳細は別途公開されており、CPUの最大100倍、GPUの最大10倍の高速化を達成したことが報告されています。
具体的な応用例として、MediaTek Dimensity 9500 NPUを搭載したVivo 300 Proでの音声・視覚マルチモーダル中国語アシスタント、Snapdragon 8 Elite Gen 5を搭載したXiaomi 17 Pro MaxでのFastVLMを使用したシーン理解などが紹介されています。
生成AI(GenAI)の優れたクロスプラットフォームサポート
オープンモデルは柔軟性とカスタマイズ性に優れている一方、その展開には高い技術的ハードルがあります。モデルの変換、推論、ベンチマーキングの複雑さは、多くの場合、大きなエンジニアリングオーバーヘッドを要求します。
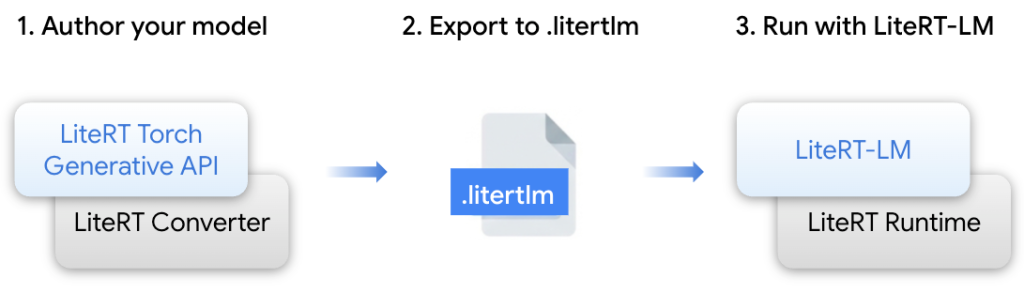
この課題に対応するため、LiteRTは以下の統合技術スタックを提供しています:
- LiteRT Torch Generative API: Transformer ベースのPyTorchモデルをLiteRT-LM/LiteRT形式に変換するPythonモジュール
- LiteRT-LM: LLM固有の複雑さを管理する専用オーケストレーションレイヤー。ChromeやPixel WatchなどのGoogle製品でGemini Nanoの展開を支えている実績のあるインフラ
- LiteRT Converter & Runtime: 効率的なモデル変換、ランタイム実行、最適化を提供する基盤エンジン
これらのコンポーネントは、人気のあるオープンモデルを高性能で実行するための本番グレードのパスを提供します。Googleの発表によれば、Samsung Galaxy S25 UltraでGemma 3 1Bをベンチマークした結果、LiteRTはllama.cppと比較して、CPUで3倍、GPUデコード(メモリバウンド)で7倍、GPUプリフィル(コンピュートバウンド)で19倍の性能を示しました。さらに、NPU加速により、GPUと比較してプリフィルで2倍の追加的な性能向上が得られたとのことです。
この性能差は、LiteRTがメモリバウンドおよびコンピュートバウンドの両方のワークロードに対して最適化されていることを示しており、特にプリフィル段階でのNPU活用が効果的であると考えられます。
LiteRTは、以下のような人気のオープンウェイトモデルを最適化済みで提供しています:
- Gemmaファミリー: Gemma 3(270M、1B)、Gemma 3n、EmbeddingGemma、FunctionGemma
- Qwen、Phi、FastVLMなど
これらのモデルは、LiteRT Hugging Face Communityで入手可能で、Google AI Edge Galleryアプリ(Android/iOS)で実際に体験できます。アプリには、FunctionGemmaを使用したTinyGardenやMobile Actionsなどのデモが含まれています。
広範なMLフレームワークサポート
LiteRTは、PyTorch、TensorFlow、JAXという業界で最も人気のあるMLフレームワークからのシームレスなモデル変換を提供します。

PyTorchサポートについては、LiteRT Torchライブラリを使用することで、PyTorchモデルを単一のステップで直接.tflite形式に変換できます。これにより、PyTorchベースのアーキテクチャが、LiteRTの高度なハードウェア加速を即座に活用できるようになります。
従来、PyTorchモデルをモバイル環境で実行するには、ONNX経由での変換や独自の最適化が必要でしたが、LiteRT Torchライブラリはこのプロセスを大幅に簡素化しています。
TensorFlowとJAXについては、LiteRTはTensorFlowエコシステムに対する堅牢な最高水準のサポートと、jax2tfブリッジを介したJAXモデルの信頼性の高い変換パスを継続して提供します。これにより、Googleのコアとなるあらゆる機械学習ライブラリからの最先端研究を、数十億台のデバイスに効率的に展開できます。
これらのパスを統合することで、LiteRTは開発環境に関係なく、高い研究から本番環境への移行速度を実現します。開発者は好みのフレームワークでモデルを作成し、LiteRTがCPU、GPU、NPUバックエンド全体でパフォーマンスを提供することに依存できます。
信頼性と互換性の維持
LiteRTの機能は大幅に拡張されましたが、長期的な信頼性とクロスプラットフォームの一貫性に対するコミットメントは変わっていません。LiteRTは、業界標準の単一ファイル形式である.tfliteモデルフォーマットを引き続き基盤としており、既存のモデルがAndroid、iOS、macOS、Linux、Windows、Web、IoT全体でポータブルかつ互換性を保つことを保証しています。
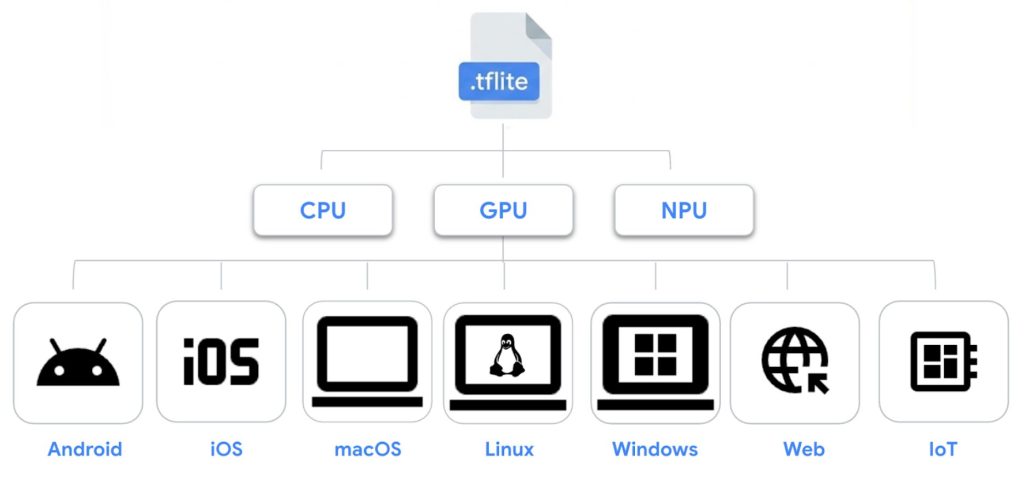
開発者に継続的な体験を提供するため、LiteRTは既存と次世代の実行パスの両方に対する堅牢なサポートを提供しています:
- Interpreter API: 既存の本番モデルは引き続き信頼性高く動作し、広範なリーチと確固たる安定性を維持します
- 新しいCompiledModel API: 次世代AIのために設計されたこの現代的なインターフェースは、GPUおよびNPU加速の完全な可能性を引き出すシームレスなパスを提供します
この二重のアプローチにより、既存のアプリケーションを保護しながら、新しい機能への移行を段階的に行えると考えられます。
まとめ
LiteRTは、TFLiteの実績ある基盤の上に、現代のAIモデルに必要な性能とプラットフォーム対応を実現したオンデバイス推論フレームワークです。GPU性能の1.4倍向上、NPU統合の簡素化、GenAIモデルの最適化により、モバイルからWebまで一貫した開発体験を提供します。PyTorch/JAXからの直接変換サポートと既存モデルとの互換性維持により、研究から本番環境への移行が容易になったと言えます。今後、さらなるハードウェアサポートの拡大が期待されます。