はじめに
本稿では、Googleが新たにリリースしたオープンウェイト大規模言語モデル(LLM)ファミリー「Gemma 3」について、特にGoogle Colaboratory (Colab) で実際に動かすことに焦点を当てて技術的な側面と具体的な利用方法を解説します。
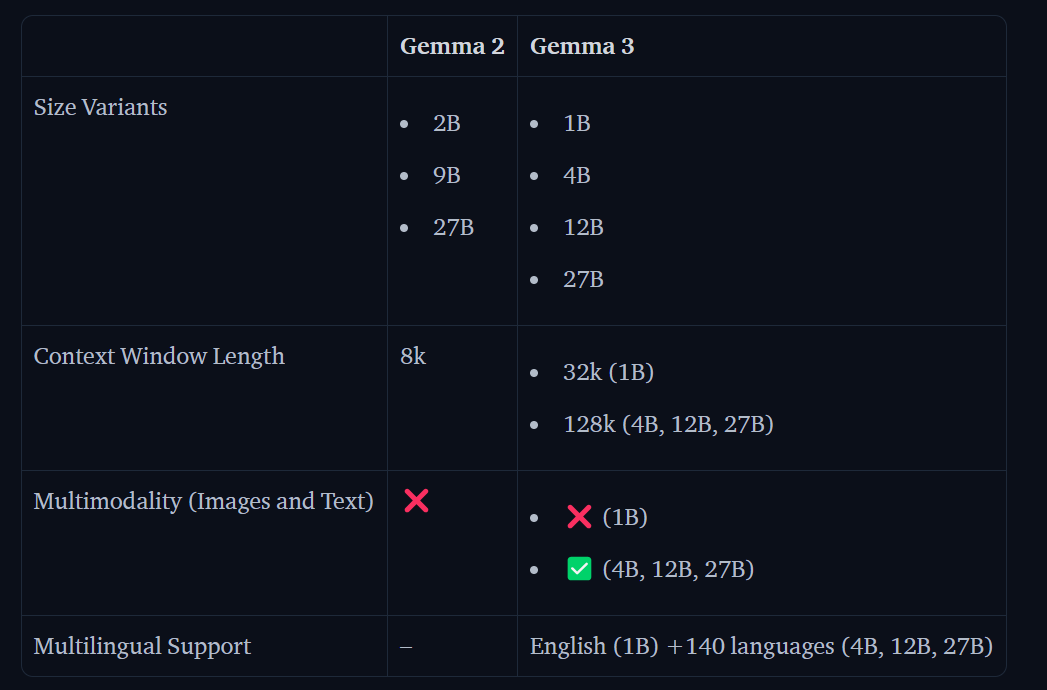
Gemma 3は、マルチモーダル(画像+テキスト)入力、140以上の言語対応、最大128kトークンの長文脈処理といった強力な機能を備えています。本稿を通じて、Colab環境でGemma 3のセットアップから推論実行までを行い、そのポテンシャルを体験するための一助となれば幸いです。
参照元:
- タイトル: Welcome Gemma 3: Google’s all new multimodal, multilingual, long context open LLM
- URL: https://huggingface.co/blog/gemma3
GoogleColab(本稿内のコードを集約)
- https://colab.research.google.com/drive/10PYdgC8QlUDf9pjbIfDZmCDVnFy4wnxo?usp=sharing
- 2025年4月13日動作確認済み

要点
- Gemma 3の概要: Google開発の最新オープンLLM。1B, 4B, 12B, 27Bの4サイズ展開。マルチモーダル(4B+)、多言語(4B+)、長文脈(最大128k)対応。
- Colabでの利用: Hugging Face transformersライブラリを使って比較的簡単に実行可能。GPUランタイムの利用を推奨。Hugging Face Hubへの認証が必要。
- 高性能: Gemma-3-4B-ITは前世代のGemma-2-27B-ITを、Gemma-3-27B-ITはGemini 1.5-Proに匹敵する性能。
- 注意点: Colabの無料枠ではメモリやGPU VRAMに制限があるため、大規模モデル(12B, 27B)の実行は困難な場合があります。本稿では主に4Bモデルを例に解説します。
詳細解説
Gemma 3の主な特徴
- 長文脈対応 (Longer Context Length): 1Bは32k、4B以上は128kトークン。段階的学習や位置埋め込み調整、KVキャッシュ最適化で実現。
- マルチモーダル対応 (Multimodality): 4B以上で画像+テキスト入力に対応。SigLIPエンコーダとPan and Scan技術を使用。
- 多言語対応 (Multilinguality): 4B以上で140+言語をサポート。データセット拡張とSentencePieceトークナイザー(262K語彙)採用。
Gemma 3の評価
LMSys Chatbot ArenaでGemma 3 27B ITが高いEloスコアを記録するなど、各種ベンチマークで優れた性能が報告されています。オープンモデルでありながら、クローズドモデルに匹敵する能力を持つ点が注目されます。
Google ColabでのGemma 3利用方法
ここでは、Hugging Face transformersライブラリを使用してGoogle ColabでGemma 3を実行する手順を解説します。
0. Colab設定の推奨:
- ランタイムのタイプを「GPU」に変更してください(例: T4)。メニューの「ランタイム」>「ランタイムのタイプを変更」から設定できます。GPUがないと推論に非常に時間がかかります。
- 無料版Colabではメモリ(RAM)やGPUメモリ(VRAM)に制限があります。大きなモデル(12B, 27B)はメモリ不足でエラーになる可能性が高いです。まずは4Bモデルで試すことをお勧めします。
1. 必要なライブラリのインストール
!pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3 torch accelerate Pillow requests
print("ライブラリのインストールが完了しました。")2. Hugging Face Hubへの認証 (重要)
Gemma 3はアクセスが制限されたモデル(Gated Model)です。利用するには、事前にモデルページで利用規約に同意し、以下のセルを実行してColab環境からHugging Faceにログインする必要があります。
実行方法: このセルを実行すると、トークンを入力するためのテキストボックスが表示されます。Hugging Faceサイトで取得したアクセストークン(通常 hf_ で始まる文字列)をコピーし、そのボックスに貼り付けてEnterキーを押してください。
# モデルロード前に必ず実行)
from huggingface_hub import login
# Hugging Faceのアクセストークンを用意してください。
# トークンは https://huggingface.co/settings/tokens で生成できます。
# セキュリティのため、トークンを直接コードに書く代わりに、
# 以下の login() を実行後、表示される入力欄にトークンを貼り付けることを推奨します。
print("Hugging Face Hubにログインします。アクセストークンを入力してください。")
try:
login()
# またはトークンを直接指定する場合:
# hf_token = "hf_YOUR_TOKEN_HERE" # トークンをここに貼り付け
# login(token=hf_token)
print("Hugging Face Hubへのログインに成功しました。")
except Exception as e:
print(f"Hugging Face Hubへのログインに失敗しました: {e}")
print("トークンが正しいか、モデルページで利用規約に同意済みか確認してください。")
# エラーの場合はここで処理を中断することも検討
# exit()
3.pipeline APIでの利用 (最も簡単):
画像とテキストを入力としてテキストを生成する例です。モデルはbfloat16データ型で最適に動作します。
import torch
from transformers import pipeline
import requests # URL存在確認などにrequestsを使う場合があるためimportは残す
from PIL import Image # PILを使う他の処理のためにimportは残す
from io import BytesIO # BytesIOを使う他の処理のためにimportは残す
import warnings
# 警告を非表示にする(任意)
warnings.filterwarnings("ignore")
# --- 設定 ---
# 使用するモデルを選択 (Colab無料枠では4B推奨)
model_id = "google/gemma-3-4b-it"
# model_id = "google/gemma-3-12b-it" # Colab Pro以上推奨
# model_id = "google/gemma-3-27b-it" # Colab Pro以上推奨
# デバイスの確認 (GPUが利用可能か)
if torch.cuda.is_available():
device = "cuda"
# bfloat16がサポートされているか確認 (T4 GPUはサポート)
if torch.cuda.is_bf16_supported():
torch_dtype = torch.bfloat16
print("GPU (bfloat16対応) を使用します。")
else:
torch_dtype = torch.float16 # bfloat16非対応ならfloat16
print("GPU (bfloat16非対応) を使用します。float16を使用。")
else:
device = "cpu"
torch_dtype = torch.float32 # CPUの場合はfloat32
print("CPUを使用します。推論に時間がかかる可能性があります。")
# -------------
# パイプラインの初期化
print(f"パイプラインを初期化中 ({model_id})...")
try:
pipe = pipeline(
"image-text-to-text",
model=model_id,
device=device,
torch_dtype=torch_dtype # 量子化やメモリ効率化のため
)
print("パイプラインの初期化完了。")
except Exception as e:
print(f"パイプライン初期化エラー: {e}")
print("Hugging Face Hubへの認証が完了しているか、メモリ不足でないか確認してください。")
exit() # エラーが発生したら終了
# --- 推論の実行 ---
# 画像のURLとプロンプト
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"
text_prompt = "このお菓子には何の動物が描かれていますか?詳細に教えてください。"
# 画像のURLを直接 content 内に含める
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": image_url},
{"type": "text", "text": text_prompt}
]
}
]
# 推論実行
print("推論を実行中...")
try:
# 【変更点】pipeline呼び出しを変更
# text=messages の形式で、raw_images引数は使用しない
output = pipe(text=messages, max_new_tokens=200) # <<< 変更点
# outputの構造を確認するためのprint文(デバッグ用、必要ならコメント解除)
# print("Pipeline output structure:", output)
# 出力テキストを取得 (元の形式でアクセスできるか試す)
generated_text = output[0]["generated_text"][-1]["content"]
print("\n--- 生成結果 ---")
print(generated_text)
print("----------------")
except KeyError as e:
print(f"KeyErrorが発生しました: キー '{e}' が見つかりません。")
print("考えられる原因: pipelineの出力形式が想定と異なります。上記のデバッグ用print文でoutputの構造を確認してください。")
# 代替の出力形式を試す (例: outputが直接リストや文字列の場合)
# print("Alternative output attempt:", output)
except Exception as e:
print(f"推論中に予期せぬエラーが発生しました: {e}")
print("メモリ不足やモデルとの互換性の問題が考えられます。")
# --- メモリ解放 (Colabでは特に重要) ---
del pipe
torch.cuda.empty_cache() # キャッシュクリア
print("リソースを解放しました。")
# ------------------------------------4. 詳細な推論 (Transformers – マルチモーダル)
pipelineよりも細かい制御(プロンプトテンプレートの適用など)を行いたい場合は、モデルクラス (Gemma3ForConditionalGeneration) とプロセッサ (AutoProcessor) を直接使用します。(注意: 事前にステップ2の認証セルを実行してください。)
import torch
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
import requests
from PIL import Image
from io import BytesIO
import warnings
# 警告を非表示にする(任意)
warnings.filterwarnings("ignore")
# --- 設定 ---
model_id = "google/gemma-3-4b-it" # Colab無料枠推奨
if torch.cuda.is_available():
device = "cuda"
if torch.cuda.is_bf16_supported():
dtype = torch.bfloat16
print("GPU (bfloat16対応) を使用します。")
else:
dtype = torch.float16
print("GPU (bfloat16非対応) を使用します。float16を使用。")
else:
device = "cpu"
dtype = torch.float32
print("CPUを使用します。")
# -------------
# モデルとプロセッサのロード
print(f"モデル ({model_id}) とプロセッサをロード中...")
try:
# device_map="auto" は複数GPUやCPUへの自動割り当て。Colabの単一GPUなら device へ直接ロードも可
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=dtype,
device_map="auto", # メモリに応じてCPUにも配置される可能性あり
# device_map=device # 明示的に指定する場合
).eval() # 推論モードに設定
processor = AutoProcessor.from_pretrained(model_id)
print("ロード完了。")
except Exception as e:
print(f"モデル/プロセッサのロードエラー: {e}")
print("Hugging Face Hubへの認証が完了しているか、メモリ不足でないか確認してください。")
exit()
# --- 推論の実行 ---
image_url = "https://huggingface.co/spaces/big-vision/paligemma-hf/resolve/main/examples/password.jpg"
text_prompt = "この画像に書かれているパスワードは何ですか?"
print("画像を準備中...")
try:
response = requests.get(image_url)
response.raise_for_status()
image = Image.open(BytesIO(response.content)).convert("RGB")
print("画像準備完了。")
except Exception as e:
print(f"画像処理エラー: {e}")
exit()
# チャット形式の入力を作成 (システムプロンプトは任意)
messages = [
# {"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{
"role": "user",
"content": [
{"type": "image", "url": image_url}, # プレースホルダー
{"type": "text", "text": text_prompt}
]
}
]
print("入力を処理中 (プロセッサ)...")
try:
# プロセッサでテキストと画像を処理し、モデル入力形式に変換
inputs = processor.apply_chat_template(
messages,
raw_images=[image], # PIL Imageオブジェクトを渡す
add_generation_prompt=True, # モデルが応答を生成しやすいように末尾にマーカーを追加
tokenize=True,
return_dict=True,
return_tensors="pt" # PyTorchテンソルで返す
).to(model.device) # モデルと同じデバイスにデータを送る
print("入力処理完了。")
except Exception as e:
print(f"プロセッサ処理エラー: {e}")
exit()
# 入力トークン数を記録 (生成部分のみを後で抽出するため)
input_len = inputs["input_ids"].shape[-1]
print("テキスト生成を実行中...")
# torch.inference_mode() または torch.no_grad() で勾配計算を無効化しメモリ効率化
with torch.inference_mode():
try:
generation_output = model.generate(
**inputs,
max_new_tokens=100, # 生成する最大トークン数
do_sample=False # Falseで決定論的出力 (毎回同じ結果)
# do_sample=True, temperature=0.7, top_k=50 # ランダム性を加える場合
)
print("生成完了。")
except Exception as e:
print(f"生成エラー: {e}")
print("メモリ不足などが考えられます。")
exit()
# 生成されたトークンIDのみを抽出 (入力部分を除く)
generation_ids = generation_output[0][input_len:]
# トークンIDをデコードしてテキストに戻す
decoded_text = processor.decode(generation_ids, skip_special_tokens=True)
print("\n--- 生成結果 ---")
print(decoded_text)
print("----------------")
# --- メモリ解放 ---
del model
del processor
del inputs
del generation_output
torch.cuda.empty_cache()
print("リソースを解放しました。")
# -----------------5. 詳細な推論 (Transformers – テキストのみ)
マルチモーダルモデルをテキスト専用LLMとして使う場合や、1Bモデルを使う場合は、Gemma3ForCausalLMを使用します。Vision Encoderがロードされないため、メモリ消費を抑えられます。(注意: 事前にステップ2の認証セルを実行してください。)
import torch
from transformers import AutoTokenizer, Gemma3ForCausalLM
import warnings
# 警告を非表示にする(任意)
warnings.filterwarnings("ignore")
# --- 設定 ---
# 1Bモデルや、4B以上のモデルをテキストのみで使う場合に指定
model_id = "google/gemma-3-1b-it" # テキスト専用モデル
if torch.cuda.is_available():
device = "cuda"
if torch.cuda.is_bf16_supported():
dtype = torch.bfloat16
print("GPU (bfloat16対応) を使用します。")
else:
dtype = torch.float16
print("GPU (bfloat16非対応) を使用します。float16を使用。")
else:
device = "cpu"
dtype = torch.float32
print("CPUを使用します。")
# -------------
# モデルとトークナイザーのロード (CausalLM と AutoTokenizer を使用)
print(f"モデル ({model_id}) とトークナイザーをロード中...")
model = None # エラー処理のためにNoneで初期化
tokenizer = None # エラー処理のためにNoneで初期化
try:
model = Gemma3ForCausalLM.from_pretrained(
model_id,
torch_dtype=dtype,
# device_map="auto",
device_map=device # 明示的に指定する場合
).eval()
# テキストのみなので AutoTokenizer を使用
tokenizer = AutoTokenizer.from_pretrained(model_id)
print("ロード完了。")
except Exception as e:
print(f"モデル/トークナイザーのロードエラー: {e}")
print("Hugging Face Hubへの認証が完了しているか、メモリ不足でないか確認してください。")
exit()
# --- 推論の実行 ---
# チャット形式の入力 (システムプロンプトとユーザープロンプト)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "あなたはユーザーの質問に簡潔かつ正確に答えるAIアシスタントです。"}],
},
{
"role": "user",
"content": [{"type": "text", "text": "大規模言語モデルについて、重要な概念を3つ挙げてください。"}],
},
]
print("入力を処理中 (トークナイザー)...")
try:
# トークナイザーで処理 (画像は扱わない)
if model and tokenizer:
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
print("入力処理完了。")
else:
print("モデルまたはトークナイザーがロードされていません。")
exit()
except Exception as e:
print(f"トークナイザー処理エラー: {e}")
exit()
# 入力トークン数を記録
input_len = inputs["input_ids"].shape[-1]
print("テキスト生成を実行中...")
with torch.inference_mode():
try:
generation_output = model.generate(
**inputs,
max_new_tokens=200, # 生成する最大トークン数
do_sample=True, # 少し多様な出力を試す
temperature=0.7,
top_k=50
)
print("生成完了。")
except Exception as e:
print(f"生成エラー: {e}")
exit()
# 生成部分のみデコード
generation_ids = generation_output[0][input_len:]
decoded_text = tokenizer.decode(generation_ids, skip_special_tokens=True)
print("\n--- 生成結果 ---")
print(decoded_text)
print("----------------")
# --- メモリ解放 ---
del model
del tokenizer
del inputs
del generation_output
torch.cuda.empty_cache()
print("リソースを解放しました。")
# -----------------オンデバイス/低リソースデバイスでの利用
Gemma 3は比較的小さなモデルサイズも提供されており、オンデバイスでの利用も可能です。
- MLX (Apple Silicon):
mlx-vlmライブラリを使うことで、MacやiPhoneなどのApple SiliconデバイスでVLMを実行できます。- インストール:
pip install git+https://github.com/Blaizzy/mlx-vlm.git - 実行例 (4bit量子化モデル):
python -m mlx_vlm.generate --model mlx-community/gemma-3-4b-it-4bit --max-tokens 100 --temp 0.0 --prompt "この乗り物のコードは何ですか?" --image https://farm8.staticflickr.com/7212/6896667434_2605d9e181_z.jpg
- Llama.cpp (CPU/GPU):
- 事前量子化されたGGUF形式のファイルを利用することで、CPUや様々なGPU環境で効率的に実行できます。
- GGUFファイルのダウンロード: Hugging Face Collection
- ビルド/ダウンロード: Llama.cpp GitHub
- 実行例 (ローカルチャットサーバー):
./build/bin/llama-cli -m ./gemma-3-4b-it-Q4_K_M.gguf -p "あなたは誰ですか?" -n 100 # またはインタラクティブモード # ./build/bin/llama-cli -m ./gemma-3-4b-it-Q4_K_M.gguf- 前提知識: GGUFは、llama.cppで利用されるモデルファイル形式で、量子化(モデルのパラメータを低精度で表現し、サイズと計算量を削減する技術)されていることが多いです。Q4_K_Mなどは量子化のレベルを示します。
まとめ
本稿では、Googleの最新オープンモデルGemma 3について、その概要、技術的な進化、性能、そして具体的な利用方法を解説しました。Gemma 3は、マルチモーダル、多言語、長文脈への対応を果たし、特に4B以上のモデルでは画像とテキストを組み合わせた高度なタスクが可能になりました。性能面でも大幅な向上を遂げており、比較的小さなモデルでも高い能力を発揮し、大規模モデルは最先端のクローズドモデルに匹敵する結果を示しています。また、transformersライブラリやMLX、Llama.cppなど、様々な環境で利用するためのエコシステムも整備されています。
Gemma 3は、その高い性能とアクセシビリティにより、AIエンジニアにとって強力なツールとなるでしょう。ぜひ本稿で紹介した方法を参考に、Gemma 3を活用した開発や研究を進めてみてください。








