
はじめに
近年、大規模言語モデル(LLM)の進化が注目されていますが、その一方で、より軽量で特定のタスクに特化したモデルの重要性も高まっています。そうしたなか、Googleが新たにオープンモデルファミリー「Gemma」の最新モデルとして、Gemma 3 270Mを発表しました。Gemma 3 270Mは、まさにそのニーズに応えるために設計された、コンパクトながらも強力な性能を秘めたモデルです。
本稿では、Gemma 3 270Mについて、Google Developers Blogの「Introducing Gemma 3 270M: The compact model for hyper-efficient AI」という記事をもとに、その技術的な特徴や意義を詳しく解説します。
参考記事
- タイトル: Introducing Gemma 3 270M: The compact model for hyper-efficient AI
- 発行元: Google Developers Blog
- 発行日: 2025年8月14日
- URL: https://developers.googleblog.com/en/introducing-gemma-3-270m/
※2025年12月19日に発展モデルのひとつとして、FunctionGemmaが発表されました。

要点
- Gemma 3 270Mは、2億7000万という非常にコンパクトなパラメータ数を持つGoogleの新しいオープンな言語モデルである。
- 汎用的な対話AIとしてではなく、特定のタスクに特化させる「ファインチューニング」を前提として設計されている。
- その小さなサイズにもかかわらず、与えられた指示を正確に実行する指示追従能力が非常に高い。
- オンデバイスでの利用を想定しており、消費電力が極めて少なく、スマートフォンなどリソースが限られた環境での動作に適している。
- 本番環境での利用を容易にするため、モデルを軽量化・高速化する量子化(Quantization-Aware Trained)に対応したチェックポイントが提供される。
- 開発者は、このモデルを基盤とすることで、低コスト、高速、かつプライバシーを重視した特化型AIを効率的に構築できる。
詳細解説
Gemma 3 270Mとは? – 「適材適所」を実現する新しいAI
Gemma 3 270Mは、Googleが開発したオープンモデル「Gemma」ファミリーに加わった、新しい軽量モデルです。最大の特徴は、2億7000万(270M)という、近年の巨大モデルとは一線を画すパラメータ数にあります。
なぜ今、このような小さなモデルが重要なのでしょうか。発表では「額縁を掛けるのにスレッジハンマーは使わない」という比喩が用いられています。AI開発においても同様に、全てのタスクに巨大な万能モデルを使うのが必ずしも効率的とは限りません。テキストの分類や特定のデータ抽出といった明確に定義されたタスクには、それに特化した小型で高速なモデルの方が、コストや速度の面で圧倒的に有利です。Gemma 3 270Mは、この「適材適所」の思想を体現するモデルとして開発されました。
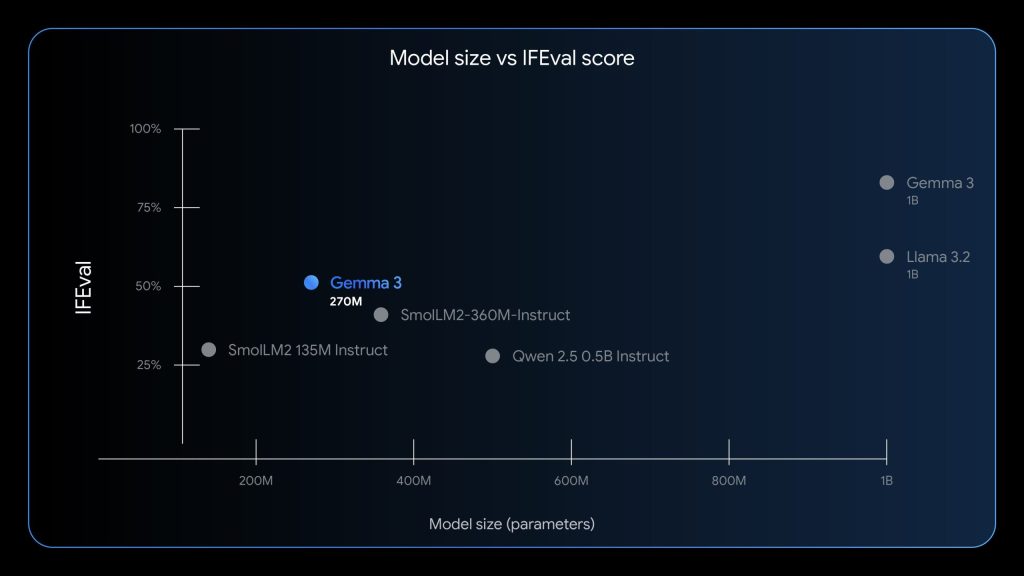
Gemma 3 270Mの技術的な特徴
Gemma 3 270Mは、ただ小さいだけでなく、特化型モデルの基盤として優れた特徴を備えています。
1. コンパクトで高性能なアーキテクチャ
モデルのパラメータ数は合計2.7億ですが、その内訳は、単語や文字をベクトルに変換するための埋め込みパラメータが1.7億、実際の言語処理を行うTransformerブロックが1億となっています。特に注目すべきは25万6000トークンという大きな語彙サイズです。これにより、専門用語や珍しい単語を効率的に扱うことができ、特定のドメイン(医療、法律、あるいは日本語の特定の文脈など)へのファインチューニングにおいて高い性能を発揮する土台となります。
2. 優れた指示追従能力
このモデルは、単に知識が豊富なのではなく、与えられた指示(Instruction)をどれだけ正確に実行できるかという能力に長けています。記事では、この能力を測るIFEvalベンチマークにおいて、同規模のモデルの中で突出した性能を示したことが述べられています。これは、ファインチューニングによって「顧客からの問い合わせメールを要約して」や「文章から製品名だけを抜き出して」といった具体的なタスクを、高い精度でこなせるようになることを意味します。
3. 驚異的なエネルギー効率
Gemma 3 270Mの大きな利点の一つが、その低い消費電力です。Googleの社内テストでは、スマートフォン(Pixel 9 Pro)上で動作させた際、25回の対話処理でバッテリーをわずか0.75%しか消費しなかったと報告されています。このエネルギー効率の高さは、ユーザーのプライバシーを守りながらオフラインでも高速に動作する、いわゆるオンデバイスAIアプリケーションの実現を強力に後押しします。
4. 本番環境を見据えた量子化への対応
AIモデルをスマートフォンなどのデバイスで動かすには、モデルサイズをさらに圧縮し、計算を高速化する「量子化」という技術が不可欠です。Gemma 3 270Mでは、開発者がこの量子化を容易に行えるよう、量子化を意識して事前学習されたモデル(Quantization-Aware Trained, QAT)のチェックポイントが最初から提供されています。これにより、性能の劣化を最小限に抑えながら、INT4(4ビット整数)精度でモデルを動かすことができ、リソースが限られた環境への展開が容易になります。
どのような場面で活躍するのか?
Gemma 3 270Mは、特に以下のようなユースケースでその真価を発揮します。
- 大量かつ明確に定義されたタスク: 感情分析、固有表現抽出、問い合わせの分類、非構造化テキスト(自由記述文など)から構造化データ(表形式など)への変換、コンプライアンスチェックなど。
- コストと速度が重要なサービス: 推論コストを劇的に削減し、ユーザーへの応答速度を向上させたい場合。ファインチューニング済みのモデルは、安価なインフラやオンデバイスで実行可能です。
- 迅速な開発サイクルが求められる場合: モデルが小さいため、ファインチューニングの実験を数日ではなく数時間単位で高速に回すことができます。
- ユーザーのプライバシーが最優先される場合: 全ての処理をデバイス内で完結させられるため、機密情報をクラウドに送信することなく安全に扱うアプリケーションを構築できます。
利用方法
Gemma 3 270Mはオープンモデルとして公開されており、開発者はすぐに利用を開始できます。
- モデルのダウンロード: Hugging Face, Ollama, Kaggle, LM Studio, Dockerなど、主要なプラットフォームから事前学習済みモデルと指示チューニング済みモデルの両方が入手可能です。
- モデルの試用: Google CloudのVertex AIや、llama.cpp, Keras, MLXといった推論ツールですぐに試すことができます。
- ファインチューニング: Hugging Face TRL, UnSloth, JAXなど、使い慣れたツールを用いて独自のデータセットでモデルをカスタマイズできます。
まとめ
今回登場したGemma 3 270Mは、AI開発の世界で「大きさ」だけが性能の指標ではないことを改めて示す、重要なモデルです。巨大な汎用モデルが注目を集める一方で、このモデルのようにコンパクトで、特定のタスクに特化させることで真価を発揮するアプローチは、多くの企業や個人開発者にとって、より現実的で効率的なソリューションとなり得ます。
特に、リソースが限られる環境でのAI活用や、プライバシー保護が重要なアプリケーション開発において、Gemma 3 270Mは強力な選択肢となるでしょう。この新しいツールが、日本の開発者コミュニティからどのようなユニークな専門モデルを生み出すのか、今後の展開が非常に楽しみです。








