
はじめに
Googleは2025年9月25日、ロボットが物理世界を理解し、複雑なタスクを自律的に実行するための新しいAIモデル「Gemini Robotics-ER 1.5」を開発者向けに公開したことを発表しました。このモデルは、ロボットの「脳」として機能し、人間のように周囲の状況を認識し、多段階のタスクを計画・実行する能力を持ちます。
本稿では、Google AI Developer Blogなどで報じられた内容をもとに、この「Gemini Robotics-ER 1.5」が持つ技術的な特徴とその可能性について、簡単に解説します。
参考記事
- 発行元: Google AI Developer Blog
- 発行日: 2025年9月25日
- タイトル: Building the Next Generation of Physical Agents with Gemini Robotics-ER 1.5
- URL: https://developers.googleblog.com/ja/building-the-next-generation-of-physical-agents-with-gemini-robotics-er-15/
- 発行元: Google DeepMind
- 発行日: 2025年9月25日
- タイトル: Gemini Robotics 1.5 brings AI agents into the physical world
- URL: https://deepmind.google/discover/blog/gemini-robotics-15-brings-ai-agents-into-the-physical-world/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Googleがロボットの高度な「思考」を担う物理世界推論モデル「Gemini Robotics-ER 1.5」を開発者向けにプレビュー公開した。
- このモデルは、ロボットの司令塔(脳)として機能し、視覚・空間認識、長期的なタスク計画、進捗推定に優れている。
- Google検索などのツールを自律的に呼び出し、外部情報を活用してタスクを解決できる。
- VLA(視覚言語行動)モデル「Gemini Robotics 1.5」と連携し、計画(ERモデル)と実行(VLAモデル)を分担するエージェントシステムを構成する。
- タスクの複雑さに応じて思考時間と応答速度のバランスを調整できる「思考バジェット」機能を搭載している。
- 開発者はGoogle AI StudioおよびGemini APIを通じて、このモデルを利用開始できる。
詳細解説
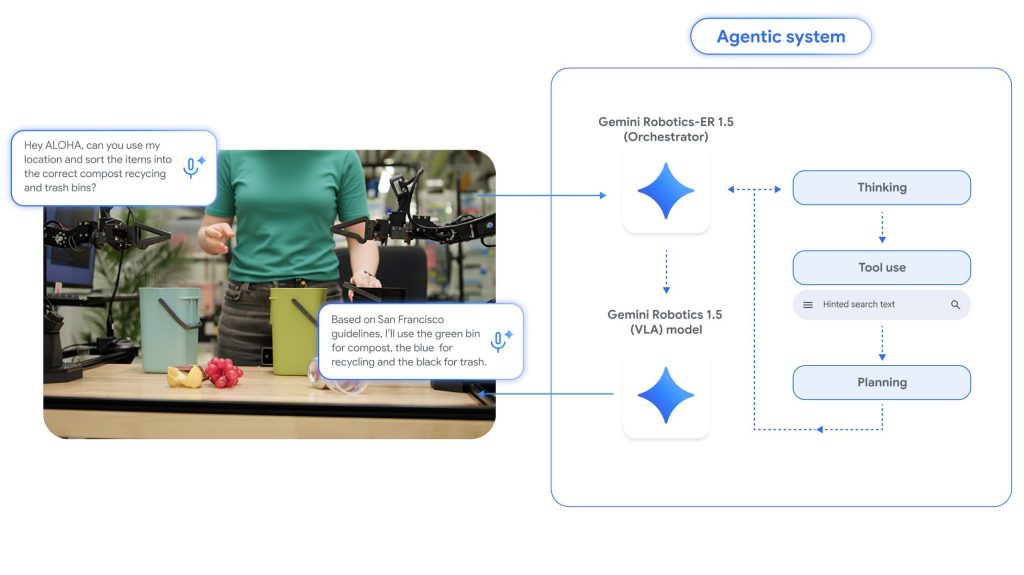
Gemini Roboticsとは:ロボットを知能化するエージェントシステム
現代のロボットは、決められた単純作業を正確にこなすことは得意ですが、「机の上を片付けて」といった曖昧で複雑な指示を理解し、状況に応じて行動することは非常に困難です。Googleが開発したGemini Roboticsは、このような課題を解決するために作られた、物理世界で活動するエージェント(ロボット)向けのAIモデル群です。
このシステムは、主に2つのモデルが連携して動作します。
- Gemini Robotics-ER 1.5(本稿で解説するモデル)
- 役割は「司令塔(脳)」です。Vision-Language Model (VLM) に分類され、画像や言語を理解し、タスク全体の計画立案、論理的な意思決定、ツールの使用などを担当します。ERは Embodied Reasoning(物理世界の推論) を意味します。
- Gemini Robotics 1.5
- 役割は「実行役(身体)」です。Vision-Language-Action (VLA) モデルに分類され、司令塔から受け取った具体的な指示を、ロボットのモーターを動かすための行動命令に変換します。
例えば、「地域のルールに従ってゴミを分別して」という指示があった場合、まず司令塔である Gemini Robotics-ER 1.5 がGoogle検索で地域のゴミ分別ルールを調べ、目の前にあるゴミを認識し、「アルミ缶はリサイクル、野菜くずはコンポストへ」といった具体的な計画を立てます。そして、その計画を「実行役」である Gemini Robotics 1.5 に伝え、VLAモデルが「アルミ缶を掴んで青い箱に入れる」といった一連の動作を生成する、という流れになります。
Gemini Robotics-ER 1.5の核心的な機能
このモデルは、ロボットが物理世界と効果的にインタラクションするために、いくつかの重要な機能を備えています。
1. 高度な空間・時間認識能力
ロボットが物を掴んだり移動したりするためには、物体の位置を正確に把握する必要があります。「Gemini Robotics-ER 1.5」は、画像内の物体の2D座標を極めて高い精度で特定できます。これにより、ロボットは自身の3Dセンサーと組み合わせて、物体の三次元空間での正確な位置を割り出すことが可能になります。
例えば、以下のプロンプトでキッチンにある物体を指し示すよう指示すると、モデルは ハルシネーションを起こすことなく、存在する物体だけの座標を正確に出力します。
プロンプト:
Identify where I should put my mug to make a cup of coffee. Return a list of JSON objects in the format: [{"box_2d": [y_min, x_min, y_max, x_min], "label": <label>}], where the coordinates are normalized between 0-1000.

さらに、動画を解析して一連の動作の順序や因果関係を理解する時間的推論も可能です。これにより、ロボットはタスクの進捗状況を把握したり、行動の結果を予測したりすることができます。
2. アフォーダンスの推論と長期タスクの計画
アフォーダンスとは、物や環境が持つ「〜できる」という行動の可能性を意味します。例えば、ドアノブは「回せる」、椅子は「座れる」といった性質です。「Gemini Robotics-ER 1.5」はこのアフォーダンスを深く理解し、長期的なタスクを計画できます。
発表で紹介されているコーヒーを入れる例では、モデルは以下のような一連の問いに答え、タスクの各ステップでどこを操作すべきかを正確に示します。
- 「コーヒーを入れるためにマグカップはどこに置くべき?」 → コーヒーメーカーのドリップトレイ部分を指し示す
- 「コーヒーポッドはどこに入れるべき?」 → ポッドを入れるスロット部分を指し示す
- 「蓋を閉めるにはどう動かせばいい?」 → 蓋のハンドルを閉じるための軌道を複数のポイントで示す
- 「飲み終わったマグカップはどこに置くべき?」 → 片付けのためにシンクの中を指し示す
これは単なる物体認識ではなく、「コーヒーを入れる」という文脈の中で、各オブジェクトがどのような役割を持ち、どう操作されるべきかを推論していることを示しています。
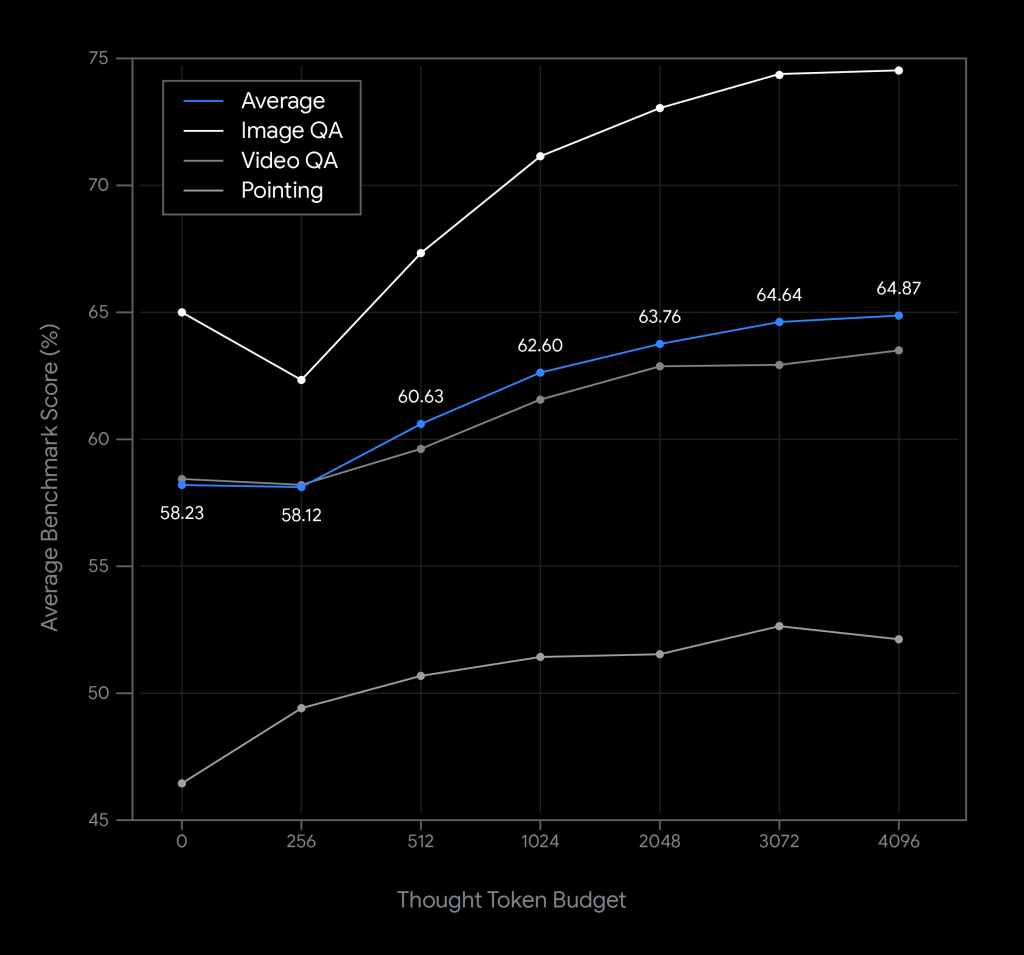
3. 柔軟な思考バジェット (Flexible thinking budget)
AIモデルの応答速度と推論の精度は、多くの場合トレードオフの関係にあります。複雑なタスクほど「考える時間(計算リソース)」が必要になりますが、リアルタイム性が求められる場面では迅速な応答が不可欠です。
「Gemini Robotics-ER 1.5」は、開発者がこのバランスを調整できる「思考バジェット」という機能を提供します。これにより、例えば「目の前の障害物を避ける」といった緊急性の高いタスクには思考バジェットを小さくして素早く反応させ、「部屋の掃除計画を立てる」といった複雑なタスクにはバジェットを大きくして、より精度の高い計画を生成させるといった使い分けが可能になります。
4. クロスエンボディメント学習
従来のロボット学習では、特定のロボットで学習した動作を他の形状や構造の異なるロボットに適用することは困難でした。「Gemini Robotics 1.5」(VLAモデル)は、この課題を解決する画期的な能力を示しています。
このモデルは、異なる「エンボディメント」(ロボットの物理的な形状や構造)間で学習した動作を転移させることができます。例えば、ALOHA 2ロボットでのみ訓練されたタスクが、Apptronikの人型ロボット「Apollo」や双腕Frankaロボットでも自動的に実行可能になります。これにより、新しいロボットに対する学習時間を大幅に短縮し、ロボットの汎用性を飛躍的に向上させることができます。
この能力は、ロボット工学の長年の課題であった「学習の転移可能性」を実現するものであり、様々な形状のロボットが共通の知識ベースを活用できる未来への重要な一歩となります。
5. 安全性への取り組み
物理世界で動作するロボットにとって、安全性は最も重要な課題です。「Gemini Robotics-ER 1.5」は、安全性向上のために以下の2つの側面で改善が図られています。
- セマンティックセーフティ(意味論的な安全性): 危険または有害なタスクの計画を理解し、生成を拒否するように設計されています。
- 物理的制約の認識: ロボットの可搬重量やアームの可動範囲といった、開発者が定義した物理的な制約を認識し、それを超えるような計画を立てない能力が向上しています。
ただし、Googleはモデルレベルの安全機能だけでは不十分であり、非常停止ボタンや衝突回避システムといった従来のロボット工学における安全対策を多層的に組み合わせる「スイスチーズアプローチ」が不可欠であると強調しています。
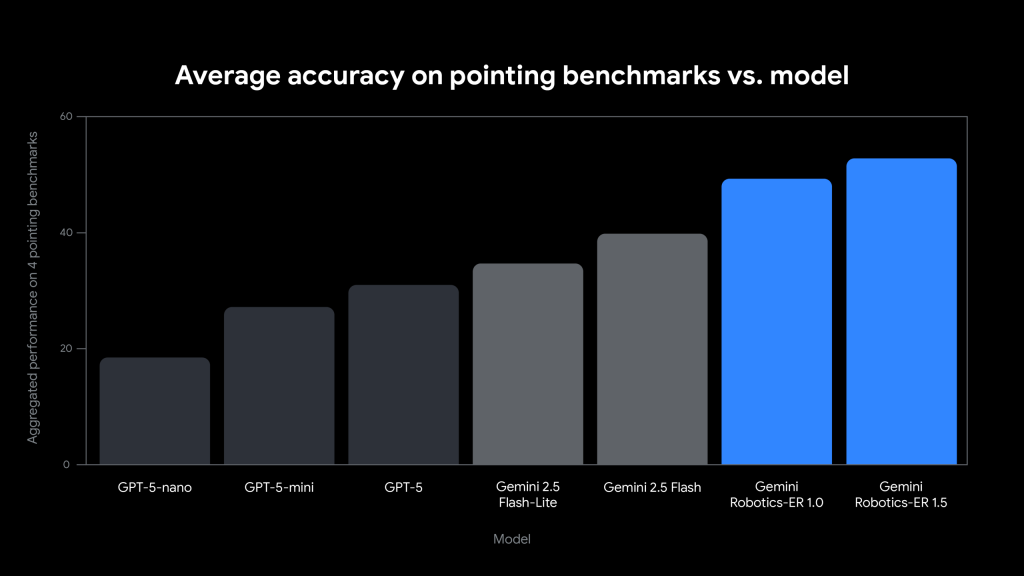
ベンチマーク性能
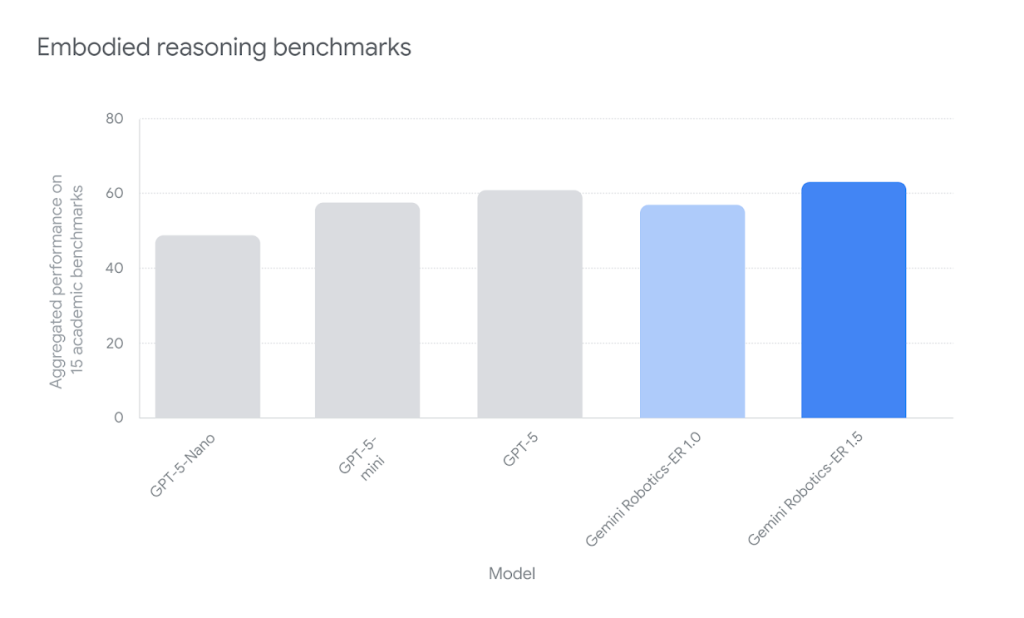
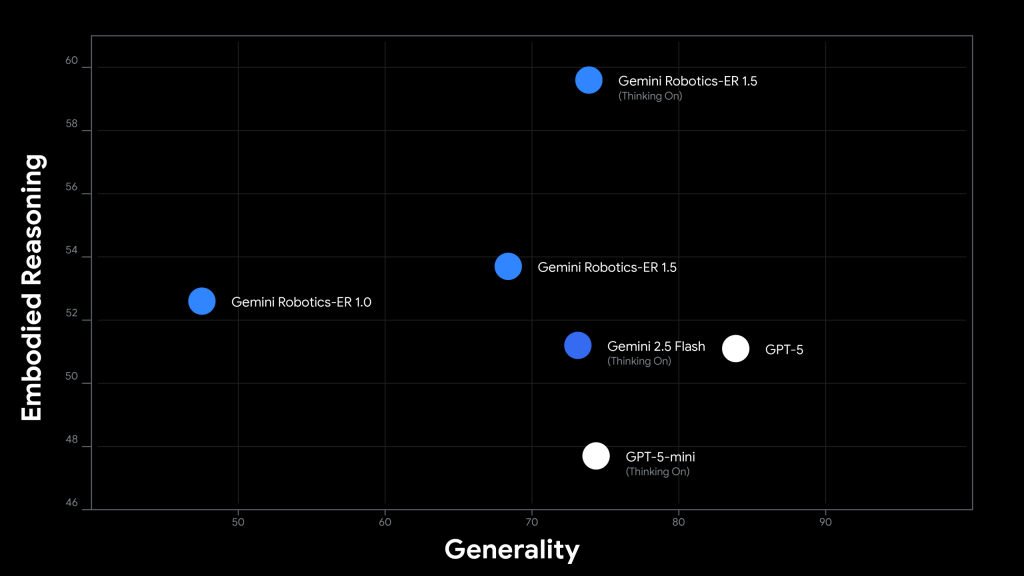
「Gemini Robotics-ER 1.5」は、物理世界推論における性能を客観的に評価するため、15の学術ベンチマークで検証されました。これらには、Embodied Reasoning Question Answering (ERQA)、Point-Bench、RefSpatial、RoboSpatial-Pointingなどが含まれ、ポインティング精度、画像質問応答、動画質問応答といった多様な能力が測定されています。
その結果、同モデルは全ての評価項目において最先端(state-of-the-art)の性能を達成し、物理世界における空間理解と推論能力で他のモデルを大きく上回る結果を示しています。この高い性能は、実世界のロボットアプリケーションにおける信頼性と実用性を裏付ける重要な指標となっています。
開発を始めるには
「Gemini Robotics-ER 1.5」は、現在プレビュー版として開発者に提供されています。以下のリソースから利用を開始できます。
- Google AI Studio: Webブラウザ上でモデルを直接試すことができます。
https://aistudio.google.com/prompts/new_chat?model=gemini-robotics-er-1.5-preview&utm_source=gemini-robotics-er-1.5&utm_medium=blog&utm_campaign=launch - Gemini API: 自身のアプリケーションにモデルを組み込むためのAPIです。
https://ai.google.dev/gemini-api/docs/robotics-overview?utm_source=gemini-robotics-er-1.5&utm_medium=blog&utm_campaign=launch - Colabノートブック: 実践的なコード例を通じて、モデルの利用方法を学べます。
https://github.com/google-gemini/cookbook/blob/main/quickstarts/gemini-robotics-er.ipynb?utm_source=gemini-robotics-er-1.5&utm_medium=blog&utm_campaign=launch
まとめ
今回発表された「Gemini Robotics-ER 1.5」は、ロボットが単なる道具から、自律的に思考し、複雑な問題を解決するパートナーへと進化する道筋を示しています。物理世界を深く理解し、人間と自然言語で対話しながらタスクを計画・実行する能力は、製造業や物流、家庭内支援など、様々な分野でロボットの可能性を大きく広げると考えられます。








