
はじめに
Googleが2025年12月5日、最新のマルチモーダルAIモデル「Gemini 3 Pro」のビジョンAI機能について解説する記事を公開しました。本稿では、この発表内容をもとに、Gemini 3 Proの視覚理解能力の進化、特に文書・空間・画面・動画理解における性能向上と実用的な応用について解説します。
参考記事
- タイトル: Gemini 3 Pro: the frontier of vision AI
- 著者: Rohan Doshi
- 発行元: Google (The Keyword blog)
- 発行日: 2025年12月5日
- URL: https://blog.google/technology/developers/gemini-3-pro-vision/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Gemini 3 Proは単純な認識から真の視覚・空間推論への世代的飛躍を実現し、文書・空間・画面・動画理解で最高水準の性能を達成した
- MMMU ProやVideo MMMUなどの視覚ベンチマークで新記録を樹立し、従来モデルを大きく上回る性能を示している
- 18世紀の手書き帳簿から複雑な表を抽出したり、数式画像を正確なLaTeXコードに変換するなど、高度な文書理解能力を実証している
- 物体の位置をピクセル単位で指し示す機能や、10FPSでの高速動画処理により、ロボティクスやスポーツ分析での実用性が向上している
- 教育、医療、法律、金融など幅広い分野での応用が期待され、開発者はGoogle AI Studioで即座に試用可能である
詳細解説
視覚AIの新世代を切り開くGemini 3 Pro
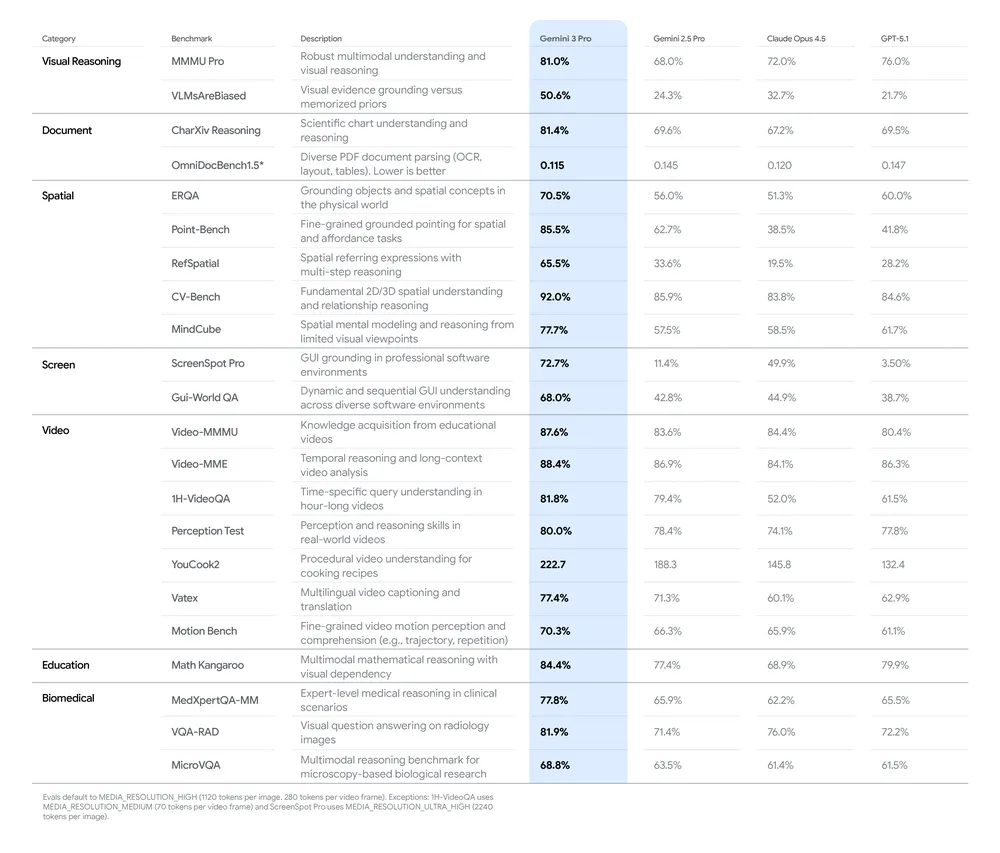
Googleによれば、Gemini 3 Proは「単純な認識から真の視覚・空間推論への世代的飛躍」を表すモデルとされています。MMMU ProやVideo MMMUといった複雑な視覚推論ベンチマークで最高水準の性能を記録しました。
MMMU Proは、マルチモーダル理解を評価する高難度ベンチマークとして知られており、大学レベルの専門知識と視覚情報の統合的理解を要求します。Video MMMUは動画理解能力を測る指標で、時系列での視覚情報の追跡と推論能力が問われます。これらのベンチマークで最高性能を達成したことは、Gemini 3 Proが従来モデルと比較して視覚理解の精度と深度において大幅に進化したことを示していると考えられます。
文書理解の進化
Gemini 3 Proの文書理解能力は、OCR(光学文字認識)から複雑な視覚推論まで、文書処理パイプライン全体にわたって大きく向上しています。
Googleの発表では、「デレンダリング」という能力が強調されています。これは視覚的な文書を構造化されたコード(HTML、LaTeX、Markdown)に逆変換する技術です。具体例として、18世紀のアルバニー商人の手書き帳簿から複雑な表を抽出したり、数式の画像を正確なLaTeXコードに変換したり、フローレンス・ナイチンゲールの極座標図をインタラクティブなチャートに再構築することに成功しています。
LaTeXは数式や学術文書の組版システムとして広く使われており、手書きや画像の数式をLaTeXコードに自動変換できることは、学術研究や教育分野での生産性向上に大きく貢献すると思います。
さらに注目すべきは、長文レポート内での複雑な多段階推論能力です。CharXiv Reasoningベンチマークでは80.5%のスコアを記録し、人間の基準値を上回りました。CharXivは、学術論文のチャートと図表を対象とした推論ベンチマークで、複数の図表を横断した論理的推論能力を評価します。
実例として、62ページに及ぶ米国国勢調査局の報告書「Income in the United States: 2022」の分析が示されています。モデルは異なる図表から情報を抽出し、「Money Income」のジニ係数が-1.2%減少した一方で「Post-Tax Income」が3.2%増加した理由を、ARPA政策の失効と刺激策の終了という政策的要因と関連付けて説明しました。これは単なるデータ抽出ではなく、因果関係の推論能力を示しています。
空間理解とロボティクスへの応用
Gemini 3 Proの空間理解能力には、2つの重要な機能があります。
第一に、画像内の特定位置をピクセル精度で指し示す「ポインティング機能」です。Googleによれば、2D座標のシーケンスを連結することで、人間のポーズ推定や時系列での軌跡追跡などの複雑なタスクを実行できるとされています。
第二に、オープンボキャブラリー参照機能です。これにより、モデルは多様な表現で物体とその意図を識別できます。実用例として、「この散らかったテーブルをどう片付けるか計画を立てて」とロボットに指示したり、AR/XRデバイスで「マニュアルに従ってネジを指し示して」と依頼することが可能になります。
従来のロボティクスシステムでは、物体認識のために事前に学習した限定的な語彙に依存していましたが、オープンボキャブラリーアプローチでは、自然言語での柔軟な指示が可能になり、ロボットの汎用性が大幅に向上すると考えられます。
画面理解とコンピュータ使用の自動化
Gemini 3 Proの空間理解能力は、デスクトップおよびモバイルOSの画面理解で特に顕著です。Googleによれば、この信頼性の高さにより、反復的なタスクを自動化するコンピュータ使用エージェントを構築できるとされています。
UI理解能力は、QAテスト、ユーザーオンボーディング、UX分析などのタスクにも応用可能です。デモ動画では、Excelシート上でピボットテーブル機能を使用して各プロモーションタイプの総収益を新しいシートにまとめるタスクを、モデルが正確なクリック操作とタイピングで実行しています。
従来のRPA(ロボティック・プロセス・オートメーション)ツールは、事前に定義された要素のIDやXPathに依存していましたが、視覚ベースのアプローチでは、UIの変更に対してより柔軟に対応できる可能性があります。
動画理解の向上
Gemini 3 Proは動画理解において3つの重要な進化を遂げています。
第一に、高フレームレート理解です。1秒あたり1フレーム以上でサンプリングする際の高速動作理解が大幅に強化されました。Googleの例では、10FPS(デフォルトの10倍速)で処理することで、ゴルフスイングの詳細な動作分析が可能になっています。
第二に、「thinking」モードによる動画推論です。このモードでは、物体認識を超えた真の動画推論が可能になり、時系列での複雑な因果関係を追跡できます。「何が起きているか」だけでなく「なぜ起きているか」を理解します。
第三に、長尺動画からのアクション抽出です。モデルは長編コンテンツから知識を抽出し、それを動作するアプリや構造化されたコードに即座に変換できます。
動画からコードへの変換機能は、チュートリアル動画から自動的にプログラムを生成したり、作業手順の動画からワークフロー自動化スクリプトを作成するといった応用が想定されます。
実世界での応用事例
Googleは、Gemini 3 Proの能力が様々な分野で活用されると説明しています。
教育分野では、図表を多用する数学や理科の問題に対応し、中学校から大学院レベルまでのマルチモーダル推論問題を解決できます。Math Kangarooのような視覚数学パズルや、複雑な化学・物理の図表にも対応しています。また、Nano Banana Proの生成機能を支えており、学生の宿題の間違いを視覚的に指摘することが可能です。
医療・生物医学画像分野では、MedXpertQA-MM(専門家レベルの医学推論試験)、VQA-RAD(放射線画像のQ&A)、MicroVQA(顕微鏡ベースの生物学研究)などの主要ベンチマークで最高水準の性能を達成しています。
法律・金融分野では、複雑なワークフローを支援します。金融プラットフォームはチャートや表が密集した詳細なレポートを分析でき、法律プラットフォームは高度な文書推論の恩恵を受けます。Harvey.aiは「Gemini 3の高度な法的推論の改善、特に複雑な修正が入った契約書の理解と編集能力に感銘を受けている」とコメントしています。
開発者向け機能:メディア解像度制御
Gemini 3 Proは、画像のネイティブアスペクト比を保持する方式で視覚入力を処理し、全体的な品質が大幅に向上しました。
Googleによれば、開発者は新しいmedia_resolutionパラメータを通じて、パフォーマンスとコストを細かく制御できるとされています。
- 高解像度: 密なOCRや複雑な文書理解など、細部が重要なタスクで忠実度を最大化
- 低解像度: 一般的なシーン認識や長文コンテキストタスクなど、単純なタスクでコストとレイテンシを最適化
この機能により、用途に応じて視覚トークンの使用量を調整し、精度とコストのバランスを取ることができます。具体的な推奨事項は、Gemini 3.0のドキュメントガイドで確認できます。
今すぐ試せる開発環境
Googleは開発者に向けて、開発者向けドキュメントとGoogle AI Studioでの試用を提供しています。Google AI Studioでは、今すぐモデルを試すことが可能です。
まとめ
Gemini 3 Proは、視覚AI分野で単純な認識から真の推論への世代的飛躍を実現しました。文書・空間・画面・動画の各領域で最高水準の性能を達成し、教育から医療、法律、金融まで幅広い実用的応用の可能性を示しています。開発者は即座にGoogle AI Studioで試用でき、新しいアプリケーション開発の基盤として活用できます。視覚理解の精度とコスト管理の両立を実現した本モデルは、AIの実用化をさらに加速させる可能性があると思います。








