はじめに
Googleは2025年7月22日、同社のAIモデルファミリーに新たな選択肢として「Gemini 2.5 Flash-Lite」の正式版をリリースしました。このモデルは、Gemini 2.5ファミリーの中で最速かつ最も低コストであることを特徴としており、特にレスポンスの速さが求められるアプリケーションでの活用が期待されています。
本稿では、Google Developers Blogに掲載された「Gemini 2.5 Flash-Lite is now stable and generally available」を基に、この新しいAIモデルの技術的な特徴や具体的な活用事例を解説していきます。
参考記事
- タイトル: Gemini 2.5 Flash-Lite is now stable and generally available
- 発行元: Google Developers Blog
- 発行日: 2025年7月22日
- URL: https://developers.googleblog.com/ja/gemini-25-flash-lite-is-now-stable-and-generally-available/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Gemini 2.5 Flash-Liteは、GoogleのGemini 2.5モデルファミリーの中で最速かつ最も低コストなモデルである。
- 価格は入力100万トークンあたり0.10ドル、出力100万トークンあたり0.40ドルであり、コスト効率が非常に高い。
- 翻訳や分類といった低遅延(レスポンスの速さ)が求められるタスクに特に適している。
- オプションで高度な推論機能を有効化することが可能である。
- 100万トークンのコンテキストウィンドウや、Google検索との連携といった高度な機能も利用可能である。
詳細解説
Gemini 2.5 Flash-Liteとは? その位置づけ
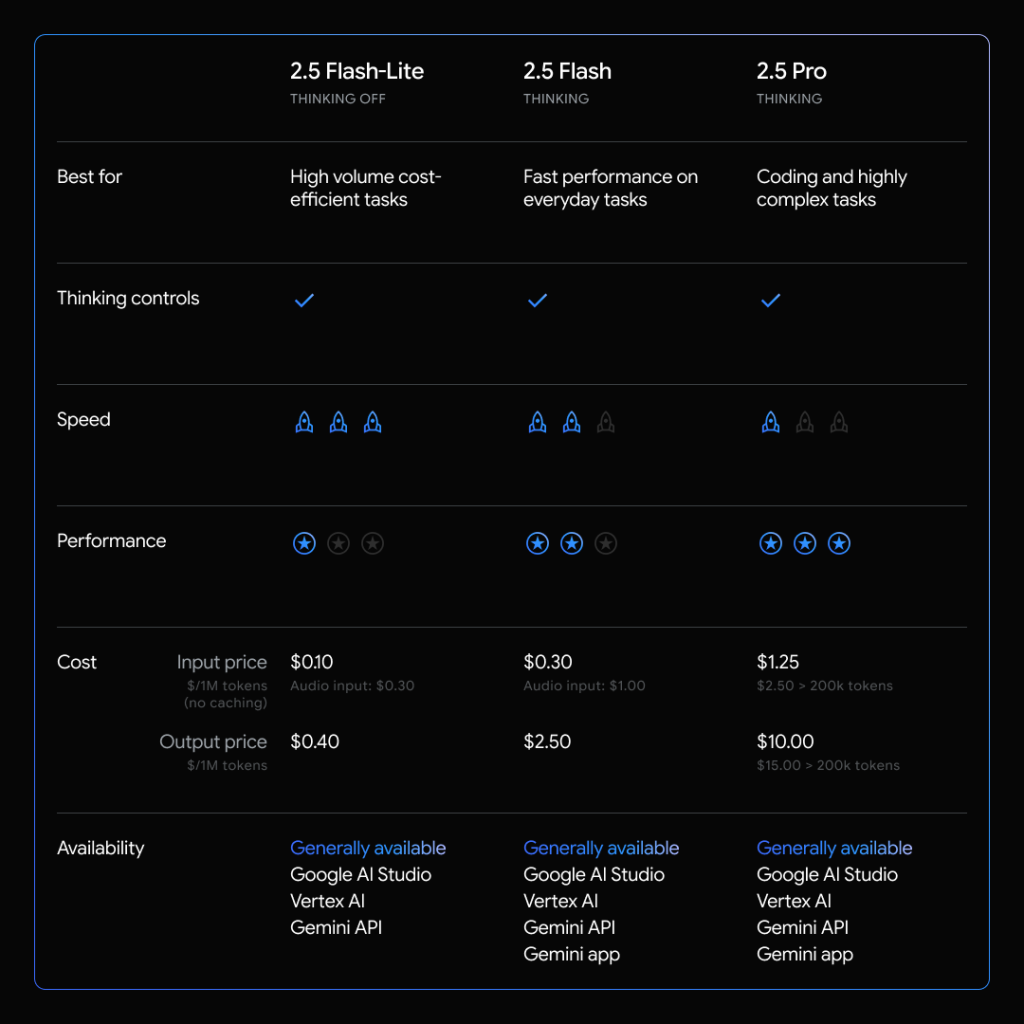
はじめに、Gemini 2.5 Flash-LiteがAIモデル全体の中でどのような位置にあるのかを理解することが重要です。GoogleのGemini 2.5ファミリーには、主に3つのモデルが存在します。
- Gemini 2.5 Pro: コーディングや複雑なタスクに対応する、最も高性能なモデル。
- Gemini 2.5 Flash: 日常的なタスクを高速に処理することに長けたモデル。
- Gemini 2.5 Flash-Lite: 今回発表された、ファミリーの中で最速・最安のモデル。大量のタスクをコストを抑えながら処理することに特化。
このように、Flash-Liteは特に「速度」と「コスト」を最優先する用途のために設計されたモデルと言えます。
理解を深めるための前提知識
技術的な詳細に入る前に、AIモデルに関するいくつかの基本的な用語を解説します。
- トークン: AIが文章を処理する際の最小単位です。料金は、このトークンの数に基づいて計算されます。一般的に、英語では1単語が1トークン程度、日本語ではひらがな1文字が1トークン以上になることが多いです。100万トークンは、非常に大量のテキストデータに相当します。
- コンテキストウィンドウ: AIが一度に理解・処理できる情報量の上限です。この数値が大きいほど、長い文章や複雑な会話の文脈を正確に把握できます。Flash-Liteが持つ100万トークンのコンテキストウィンドウは、長編小説数冊分に匹敵する広大な情報量を一度に扱えることを意味します。
- レイテンシ(遅延): ユーザーがAIに指示(プロンプト)を入力してから、AIが応答を返し始めるまでの時間のことです。この時間が短いほど、ユーザーはストレスなく対話形式のサービスなどを利用できます。
Gemini 2.5 Flash-Liteの技術的な強み
Gemini 2.5 Flash-Liteは、単に安いだけでなく、多くの優れた技術的特徴を備えています。
1. クラス最高の速度とコスト効率
最大の強みは、その圧倒的な速度とコストパフォーマンスです。記事によると、様々な指示(プロンプト)において、旧モデルである「2.0 Flash-Lite」や「2.0 Flash」よりも低いレイテンシ(短い応答時間)を実現しています。
料金は、入力100万トークンあたり0.10ドル、出力100万トークンあたり0.40ドルと、Gemini 2.5ファミリーの中で最も安価に設定されています。これにより、これまでコストの観点から導入が難しかった大量のデータを扱うタスクにも、AIを適用しやすくなります。
2. 高い基本性能と賢さ
低コストでありながら、性能に妥協はありません。コーディング、数学、科学、論理的な推論、そして画像や音声を扱うマルチモーダルな理解能力など、幅広い分野において旧モデルの「2.0 Flash-Lite」を上回る品質を示しています。
また、特筆すべきは「推論機能」をオン/オフできる点です。簡単なタスクでは推論機能をオフにして速度とコストを優先し、より複雑な思考が求められる場面ではオンにする、といった柔軟な使い分けが可能です。
3. 充実した先進機能
Flash-Liteは、上位モデルが持つような高度な機能も利用できます。
- 100万トークンのコンテキストウィンドウ: 大量のドキュメントの要約や、長時間の会議の議事録分析など、一度に多くの情報を扱う必要があるタスクで真価を発揮します。
- 思考バジェットの制御: タスクの重要度や複雑さに応じて、AIが使用する計算リソースを調整できる機能です。これにより、コストと性能のバランスをより細かく最適化できます。
- ネイティブツール連携:
- Google検索によるグラウンディング: AIの回答が不正確になったり、古い情報に基づいたりすることを防ぐため、Google検索の最新情報と連携して、より信頼性の高い回答を生成します。
- コード実行: プログラムコードを生成するだけでなく、実際にそのコードを実行して結果を検証することができます。
- URLコンテキスト: ウェブページのURLを提示するだけで、その内容をAIが読み取り、文脈を理解した上で応答を生成します。
具体的な活用事例
記事では、すでにGemini 2.5 Flash-Liteを活用して成果を上げている企業の事例が紹介されています。
- Satlyt(宇宙コンピューティング): 衛星からのデータをリアルタイムで要約・管理する際にFlash-Liteを使用。その速さにより、重要な診断にかかる遅延を45%削減し、消費電力も30%削減したとのことです。
- HeyGen(AI動画生成): Flash-Liteを活用して動画コンテンツの企画や分析を自動化し、180以上の言語への翻訳を実現しています。
- DocsHound(ドキュメント作成): 長い製品デモ動画から低遅延で大量のスクリーンショットを抽出し、網羅的なドキュメントを自動生成しています。
- Evertune(ブランド分析): 様々なAIモデル上で自社ブランドがどのように表現されているかを分析。Flash-Liteの高速処理能力により、分析とレポート作成を劇的に高速化しています。
まとめ
本稿で解説したように、Gemini 2.5 Flash-Liteは、AIアプリケーション開発における「速度」と「コスト」の壁を大きく下げる可能性を秘めたモデルです。特に、リアルタイム性が求められるチャットボット、大量のテキスト分類、多言語への翻訳、データ分析といった分野での活用が期待されます。
単に速くて安いだけでなく、100万トークンという広大なコンテキストウィンドウや、Google検索と連携するネイティブツールなどの高度な機能も兼ね備えているため、開発者はこれまで以上に創造的で高機能なアプリケーションを、現実的なコストで構築できるようになるでしょう。
このモデルはすでにGoogle AI StudioやVertex AIといったプラットフォームで利用可能になっており、AI活用の新たな時代を切り拓く一歩となることは間違いありません。