
はじめに
Google Researchが2025年10月20日、差分プライバシー(Differential Privacy)を適用した合成写真アルバムの生成手法を発表しました。本稿では、この新しい手法の仕組みと評価結果、プライバシー保護技術としての意義について解説します。
参考記事
- タイトル: A picture’s worth a thousand (private) words: Hierarchical generation of coherent synthetic photo albums
- 著者: Weiwei Kong(Software Engineer), Umar Syed(Research Scientist)
- 発行元: Google Research Blog
- 発行日: 2025年10月20日
- URL: https://research.google/blog/a-pictures-worth-a-thousand-private-words-hierarchical-generation-of-coherent-synthetic-photo-albums/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Google Researchは、差分プライバシーを適用した合成写真アルバムを生成する新手法を開発した
- この手法は、画像を一度テキスト表現に変換してから階層的に生成するという2つの特徴的なアプローチを採用している
- YFCC100Mデータセットでの評価では、実データと合成データの間で高いMAUVEスコアを記録し、テーマの一貫性も維持された
- テキストを中間表現として使用することで、計算コストの削減とプライバシー保護の両立を実現している
詳細解説
差分プライバシーと合成データ生成の課題
差分プライバシーは、データセットを分析に使用する際に、個人の機密情報が保護されることを数学的に保証する技術です。Googleによれば、この技術は約20年前に登場して以来、単純な統計計算から複雑なAIモデルの微調整まで、様々なデータ分析手法に適用されてきました。
従来のアプローチでは、各分析手法ごとに個別にプライバシー保護を実装する必要があり、これは複雑で負担が大きく、エラーが発生しやすいという課題がありました。生成AIモデルを使用すれば、元のデータセットの差分プライバシー対応の合成版を一度作成するだけで済むため、ワークフローが大幅に簡素化されます。
ただし、これまでの研究の多くは短いテキストや個別画像といった単純な出力に焦点を当ててきました。現代のマルチモーダルデータを扱うアプリケーションでは、より複雑な現実世界のシステムや行動をモデル化する必要があるため、単純な非構造化データでは不十分だったと考えられます。
テキスト中間表現と階層的生成という2つの特徴
今回発表された手法は、従来の差分プライバシー対応画像生成アプローチと2つの点で大きく異なります。1つ目はテキスト中間表現の使用、2つ目は階層的なデータ生成です。
具体的な処理の流れは次の通りです。まず、元のアルバム内の各写真をAI生成の詳細なテキストキャプションに置き換え、アルバム全体のテキスト要約も生成します。次に、差分プライバシー対応の微調整を施した大規模言語モデル(LLM)のペアを使用して、同様の構造化表現を生成します。1つ目のモデルはアルバム要約を生成し、2つ目のモデルはアルバム要約を基に個別の写真キャプションを生成します。そして、階層的な方法で写真アルバムの構造化表現を生成し、最後にこれらをテキストから画像へのAIモデルで画像セットに変換します。
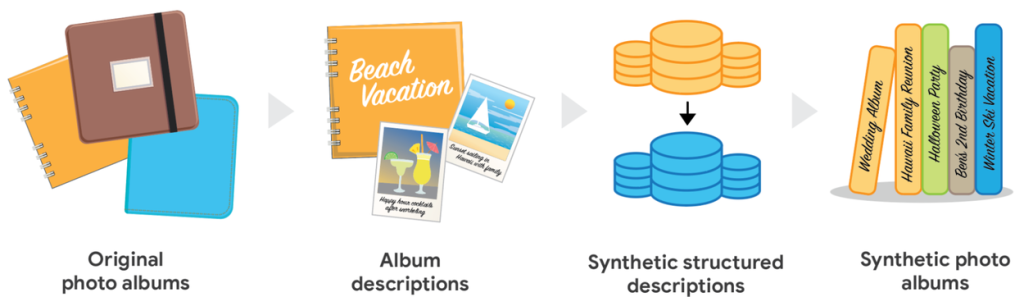
この手法には複数の利点があります。テキスト生成は大規模言語モデルの主要な強みであり、画像をテキストで説明する操作は情報を削減する処理であるため、差分プライバシーを有効にしない場合でも合成写真が元の画像の正確なコピーになる可能性が低くなります。また、画像生成はテキスト生成よりもはるかにコストがかかるため、まずテキストを生成することで、最も関心のあるコンテンツに基づいてアルバムをフィルタリングしてから画像生成に進むことができます。
階層的生成戦略により、各アルバム内の写真は内部的に一貫性が保たれます。これは、アルバム内の各写真キャプションが同じアルバム要約をコンテキストとして生成されるためです。計算コストの面でも、Self-Attentionによりトレーニングコストがコンテキスト長の二乗でスケールするため、コンテキストの短い2つのモデルをトレーニングする方が、長いコンテキストを持つ1つのモデルをトレーニングするよりもはるかに低コストになります。
「千の言葉」の実証実験
Googleは、画像を言葉で説明することが情報の損失が大きすぎるのではないかという懸念に対し、興味深い実証実験を行いました。Geminiに画像を数百語で説明させ、その説明文を再度Geminiに入力して画像を生成させたところ、元の画像の主要な特徴が再現されました。

この実験は差分プライバシーを満たしていませんが、合成画像生成の中間ステップとしてのテキストの有用性を示しています。「百聞は一見に如かず」ということわざがありますが、Googleの実験結果は「一見は千語に値する、しかしそれ以上の価値はない」ことを示唆しています。
YFCC100Mデータセットでの評価結果
Googleは、この手法をYFCC100Mデータセットで検証しました。YFCC100Mは、クリエイティブ・コモンズ・ライセンスで公開されている約1億枚の画像を含むリポジトリです。評価では、同じユーザーが同じ1時間以内に撮影した写真をグループ化して「アルバム」を形成しました。
評価指標として、元のアルバムと合成アルバムの類似度を測るMAUVEスコア(ニューラル埋め込みベースの意味的類似性の尺度)を計算しました。Googleによれば、微調整前後で、実データと合成データの間でアルバム要約と写真キャプションの両方において高いMAUVEスコアが記録されました。
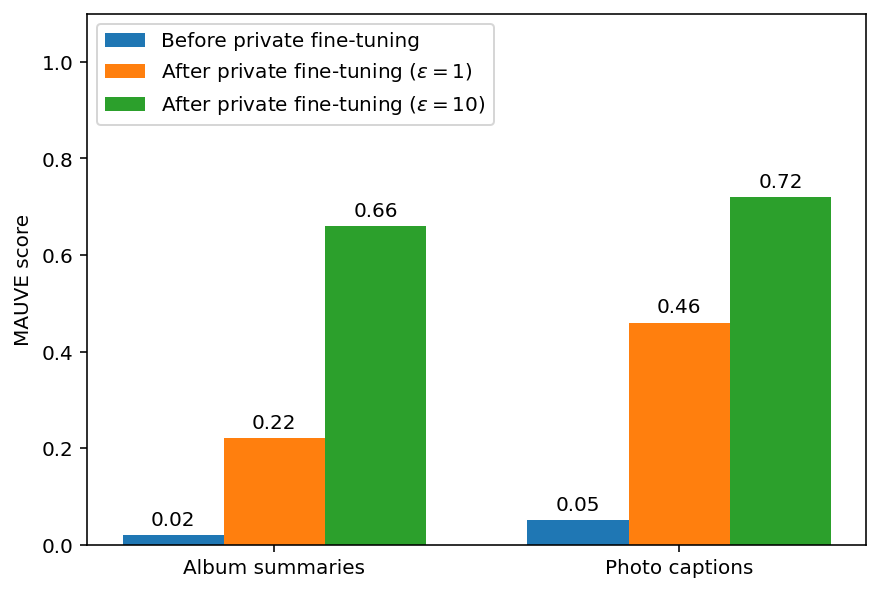
また、アルバム要約で最も一般的なトピックを計算したところ、実データと合成データの間で非常に似通っていることが確認されました。

視覚的な検証でも、各合成写真アルバムは実際の写真アルバムと同様に、通常は共通のテーマを中心に構成されていることが示されました。

MAUVEスコアはプライバシーパラメータε(イプシロン)の値によって変化し、εの値が高いほどプライバシー制約が弱くなりますが、同時に合成データの品質も向上する傾向が見られました。これは、プライバシー保護の強度とデータの有用性の間にトレードオフが存在することを示しています。
今後の展望と課題
Googleは、この手法が「単純なテキストや孤立した画像を超えた合成データの利点を拡張するための道筋を示した」としています。現代のAIが直面する課題は、プライバシーを保護するだけでなく、構造的かつ文脈的に豊かなデータを必要とするという点です。
この手法は、大量の高品質データの必要性とユーザープライバシー保護の必要性との間の緊張関係を解決する一助となる可能性があります。ただし、実際の業務への適用を考える際には、計算コストや生成される合成データの品質と元データとの乖離度など、実装上の考慮点を慎重に評価する必要があるでしょう。
まとめ
Google Researchが発表した階層的合成写真アルバム生成手法は、テキストを中間表現として活用することで、差分プライバシー保護と計算効率の両立を実現しています。
YFCC100Mデータセットでの評価では、実データと合成データの間で高い意味的類似性が確認されました。プライバシー保護技術の実用化において、重要な前進と言えるのではないでしょうか。








