はじめに
Google DeepMindが2025年11月11日、AI視覚認識モデルを人間の認知構造に近づける研究成果をNature誌で発表しました。AIは物体識別では高い精度を示す一方、人間が自然に理解する概念の階層構造を捉えられないという課題があります。本稿では、この問題を解決する「AligNet」という手法と、それによってもたらされる実用的な性能向上、そして開発者が実際に活用できる方法について解説します。
参考記事
メイン記事:
- タイトル: Teaching AI to see the world more like we do
- 著者: Andrew Lampinen, Klaus Greff
- 発行元: Google DeepMind
- 発行日: 2025年11月11日
- URL: https://deepmind.google/blog/teaching-ai-to-see-the-world-more-like-we-do/
関連情報:
- タイトル: AligNet Project Training Code, Data, and Model Checkpoints
- 発行元: Google DeepMind GitHub
- URL: https://github.com/google-deepmind/alignet
- タイトル: The Levels dataset
- 著者: Lukas Muttenthaler ほか
- 発行元: G-Node
- URL: https://doi.gin.g-node.org/10.12751/g-node.hg4tdz/
要点
- AIビジョンモデルは物体識別では優れているが、人間のような概念階層(「車と飛行機は共に乗り物」という抽象的理解)を捉えられず、表面的な特徴に依存する傾向がある
- 認知科学の「odd-one-out」タスクで人間とAIの判断を比較すると、多くのケースでAIは人間と異なる選択をし、背景色やテクスチャなど表面的特徴を重視することが明らかになった
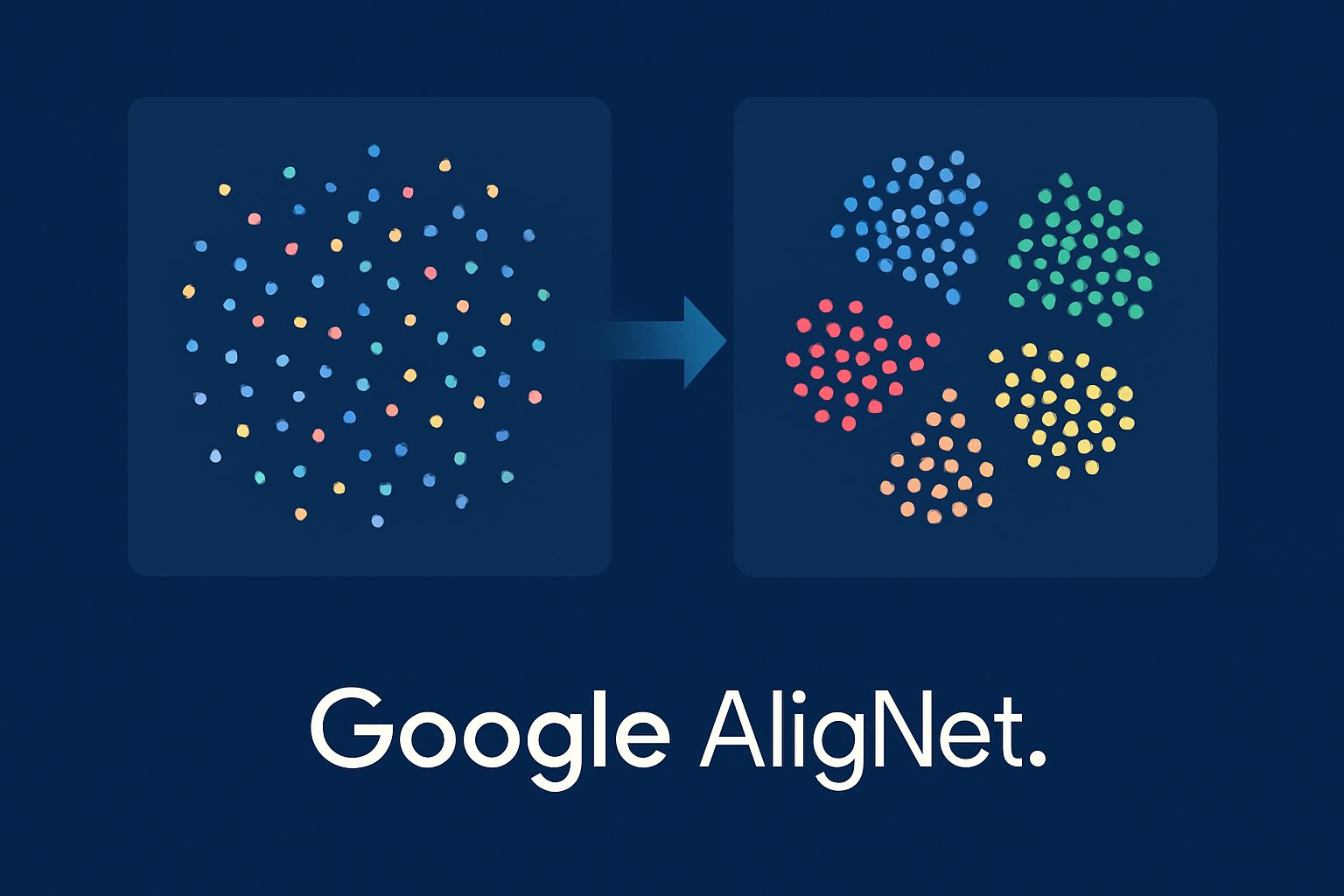
- AligNetは3ステップの手法で、少数の人間判断データから1000万枚規模の合成データセットを生成し、複数のビジョンモデルを人間の認知構造に整合させることに成功した
- アライメント後のモデルは、few-shot学習やdistribution shiftなどの課題で従来モデルを大きく上回る性能を示し、実用的な展開が期待される
- すべてのコード、データセット、モデルがオープンソースで公開されており、開発者は即座に利用可能である
詳細解説
AIが抱える視覚認識の根本的な課題
Google DeepMindによれば、現在のAIビジョンシステムは写真の整理や物体識別で広く使われていますが、人間とは異なる方法で視覚世界を組織化しています。例として、数百種類の自動車メーカーやモデルを識別できるAIでも、車と飛行機が「共に金属製の大型乗り物」という共通性を捉えられないケースがあると指摘されています。
この問題は、AIがどのように視覚情報を内部表現として保持するかという根本的な仕組みに起因しています。人間の脳は猫を見たとき、色や毛並みといった基本的概念から「猫らしさ」という高次概念まで階層的に表現を形成します。一方、AIビジョンモデルも画像を高次元空間の点として表現しますが、その組織化の仕方が人間の認知構造と異なるため、予期しない振る舞いを示すことがあります。
「odd-one-out」タスクで明らかになった人間とAIの違い
研究チームは、認知科学で古くから用いられる「odd-one-out」タスクを使って、人間とAIの視覚認識の違いを分析しました。このタスクでは、3つの画像から仲間外れを1つ選ぶことで、どの2つを「似ている」と判断するかが分かります。
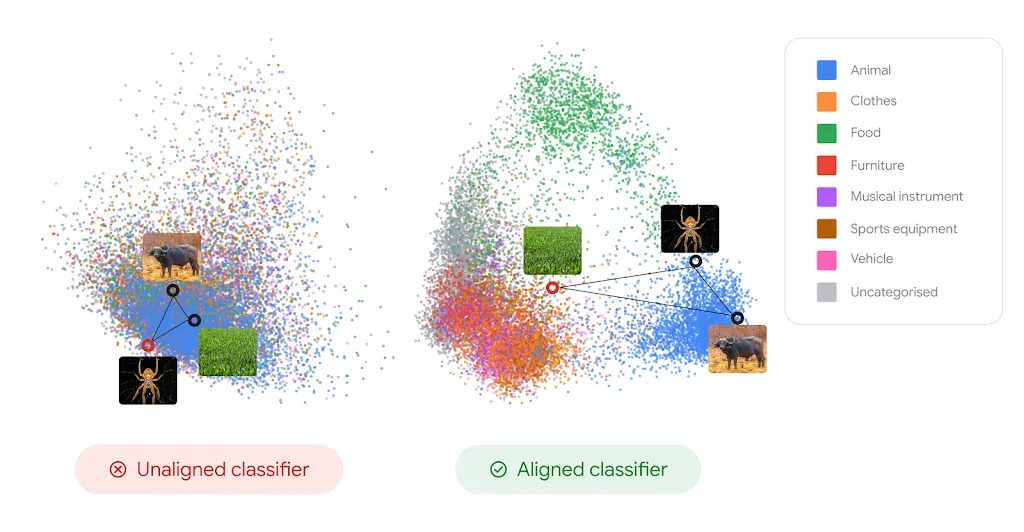
Google DeepMindの分析では、バク、羊、バースデーケーキのような明確なケースでは人間とAIの判断が一致します。しかし興味深いことに、人間の間で強い合意がある場合でも、AIは異なる判断をするケースが多数発見されました。具体例として、ヒトデ、猫、ラクダの3つが提示された場合、多くの人間はヒトデを仲間外れと判断しますが、ほとんどのビジョンモデルは背景色やテクスチャといった表面的特徴に着目し、猫を選択したと報告されています。
このような系統的な不整合は、画像分類モデルから教師なし学習モデルまで、様々なタイプのビジョンモデルで観察されました。モデルの内部表現を2次元投影(PCA)で可視化すると、動物、食品、家具といった異なるカテゴリーが混在した構造のない状態であることが確認されています。
3ステップのアライメント手法「AligNet」
この問題に対処するため、研究チームは独自の3ステップ手法を開発しました。従来、認知科学者が収集したTHINGSデータセットには数百万の人間判断が含まれていますが、使用される画像は数千枚程度に限定されています。この規模では強力なビジョンモデルを直接ファインチューニングすると、すぐに過学習が発生し、事前学習で獲得したスキルを忘却してしまうという課題がありました。
Google DeepMindが提案した解決策は以下の通りです。
まず、SigLIP-SO400Mという事前学習済みビジョンモデルの上に小さなアダプターを配置し、THINGSデータセットで慎重に訓練します。メインモデルを凍結し、アダプター訓練を適切に正則化することで、事前訓練を忘却しない「教師モデル」を作成します。
次に、この教師モデルを人間らしい判断の代理として使用し、100万枚の異なる画像を用いた1000万規模の合成odd-one-outデータセット「AligNet」を生成します。これは実際の人間から収集できる規模をはるかに超えています。
最後に、この大規模データセットで他のAIモデル(生徒)をファインチューニングします。データセットの多様性により過学習は問題とならず、生徒モデルは内部表現マップをより深く再構築できます。
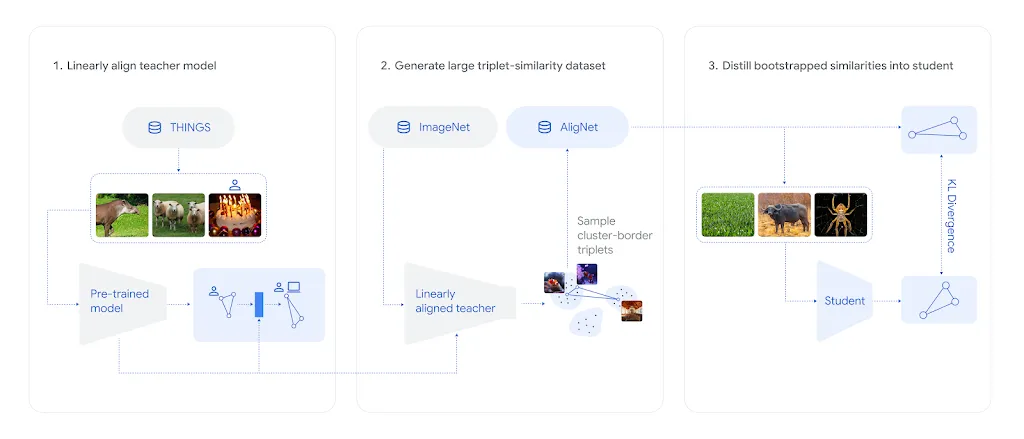
アライメント後の生徒モデルの表現は、構造のない混在状態から、動物(青色)や食品(緑色)などの高次概念が明確に分離された組織化された状態へと変化します。この再組織化は、認知科学で知られる人間知識の階層構造に従って進行し、類似度の高いカテゴリー(同一の下位カテゴリーに属する2匹の犬など)は近づき、類似度の低いペア(異なる上位カテゴリーのフクロウとトラック)は離れていくことが確認されました。

評価結果と実用的な性能向上
研究チームは、アライメント済みモデルを複数の認知科学タスクで評価しました。その1つが、多数の画像を類似度に基づいて配置するmulti-arrangementタスクです。さらに、研究チームが新たに収集した「Levels」という評価データセットも使用されました。Google DeepMindによれば、すべてのケースでアライメント済みモデルは人間との整合性が大幅に向上し、様々な視覚タスクで人間の判断とより高い頻度で一致したとされています。
興味深いことに、モデルは人間らしい不確実性の形式も学習しました。テストでは、モデルの判断における不確実性が、人間が選択にかかる時間と強く相関しており、これは不確実性の一般的な代理指標と考えられています。
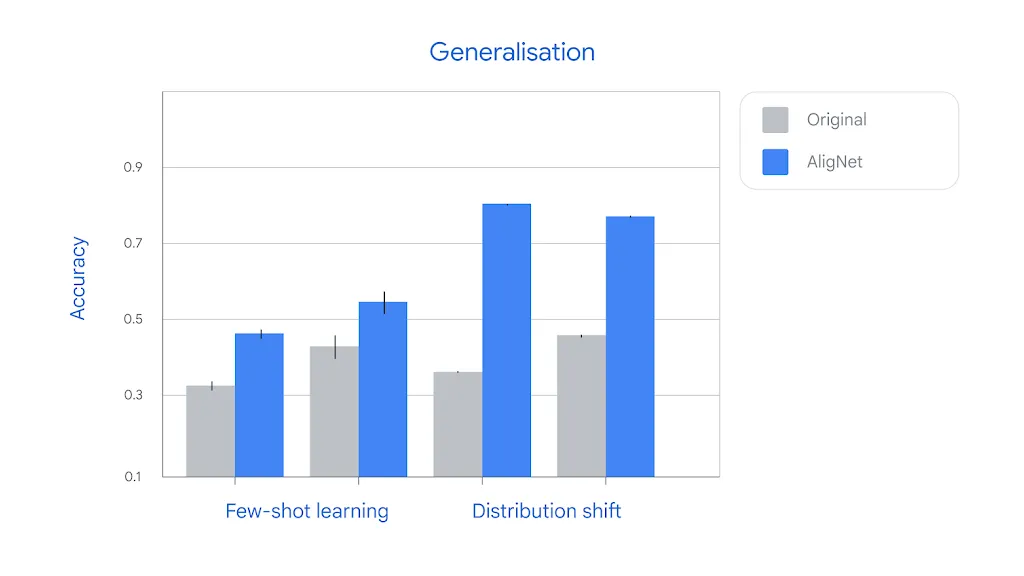
さらに重要な発見として、人間との整合性向上は、AIモデルとしての全般的な性能向上にもつながることが示されました。アライメント済みモデルは、1枚の画像から新しいカテゴリーを学習するfew-shot学習や、テスト画像の種類が変化してもロバストな判断を維持するdistribution shiftへの対応など、様々な困難なタスクで大幅に優れた性能を発揮しました。
few-shot学習は、限られたデータから新しい概念を獲得する能力を測る指標で、実用的なAIシステムでは重要な要素です。また、distribution shiftは、訓練データとテスト条件が異なる場合の頑健性を評価するもので、現実世界への展開において不可欠な性質と言えるでしょう。
実装方法
この研究の特筆すべき点は、成果が完全にオープンソース化されていることです。GitHubリポジトリでは、AligNetデータセット、ファインチューニング用のコード、複数のアライメント済みモデルのチェックポイントが公開されています。
公開されているモデルには、SigLIP-B、DINOv2-B、ViT-B、CLIP-Vit-Bなど8種類のベースモデルが含まれ、それぞれについて事前学習のみのベースモデル、AligNetでアライメントしたモデル、比較用の未変換モデルの3つのバリエーションが提供されています。これらはTensorFlowのSavedModel形式で配布されており、以下のようなシンプルなコードで即座に利用可能です。
import tensorflow as tf
import numpy as np
# モデルのロード
model = tf.saved_model.load("SigLIP-B-alignet")
forward = model.signatures['serving_default']
# 推論の実行
images = np.zeros((8, 224, 224, 3), dtype=np.float32)
output = forward(images=images)出力には、最終層前のロジット(pre_logits)、ImageNet分類用ロジット(i1k_logits)、トリプレット用ロジット(triplet_logits)、各レイヤーの内部表現(layer_{NUM})が含まれており、用途に応じて使い分けることができます。
具体的な活用シーン
実際の活用シーンとしては、以下のようなケースが考えられます。
第一に、少数サンプルからの学習が必要な場面です。例えば、製造業での不良品検査において、希少な不良パターンを数枚の画像から学習する必要がある場合、AligNetアライメント済みモデルは概念の階層構造を理解しているため、より効率的に学習できる可能性があります。
第二に、ドメイン適応が必要なアプリケーションです。医療画像解析では、異なる病院や撮影機器で取得された画像に対してもロバストな性能が求められます。AligNetモデルは表面的特徴への依存が少ないため、撮影条件の違いに影響されにくい判断ができると考えられます。
第三に、人間との協調が重要な場面です。コンテンツモデレーションや画像検索システムでは、AIの判断が人間の直感と大きく乖離していると、ユーザーの信頼を損ないます。人間の概念構造に整合したモデルを使用することで、より予測可能で信頼性の高いシステムを構築できるでしょう。
第四に、説明可能性が求められるシステムです。金融や採用などの重要な意思決定において、AIがどのような類似性判断を行っているかを説明する必要がある場合、人間の概念階層に沿った判断を行うモデルは、より理解しやすい説明を提供できる可能性があります。
また、既存のビジョンモデルをベースとしたアプリケーションを開発している場合、AligNetでファインチューニングすることで、追加の性能向上を得られる可能性があります。GitHubで公開されているコードを使用すれば、独自のデータセットでAligNetスタイルの訓練を実行することも可能です。
導入を検討する際の考慮点としては、モデルのサイズと推論速度のトレードオフがあります。アライメント処理自体はモデルの推論速度に大きな影響を与えませんが、ベースモデルの選択は重要です。また、すべての視覚タスクでAligNetが有利とは限らないため、自身のユースケースで実際に評価することが推奨されます。
まとめ
Google DeepMindの研究は、AIビジョンモデルが人間の概念階層構造を捉えられないという根本的課題に対し、実用的な解決策を提示しました。少数の人間判断から大規模な合成データセットを生成する3ステップ手法により、モデルの内部表現を人間の認知構造に近づけることに成功しています。アライメント後のモデルは、人間との整合性が向上するだけでなく、few-shot学習やdistribution shiftへの対応など実用的な性能も大幅に改善しています。すべての成果がオープンソースで公開されており、開発者は即座に活用できる状態にあるため、様々な実世界アプリケーションへの応用が期待されます。