
はじめに
近年、AI技術は目覚ましい発展を遂げていますが、その学習には大量のデータが不可欠です。しかし、個人情報や機密情報を含むデータを扱う際には、プライバシーの保護が極めて重要な課題となります。この課題を解決する一つの方法として、元のデータの特徴を保ちつつ個人を特定できないようにした「合成データ」の利用が注目されています。
しかし、高品質な合成データを生成するには、これまで数十億パラメータを持つような大規模言語モデル(LLM)をプライベートデータで再学習(ファインチューニング)させる必要があり、膨大な計算コストがかかるため、多くの開発者にとっては現実的ではありませんでした。
本稿では、この課題に対し、より軽量なモデルで効率的にプライバシーを保護した合成データを生成する新しいフレームワーク「CTCL」について解説します。
参考記事
- タイトル: Beyond billion-parameter burdens: Unlocking data synthesis with a conditional generator
- 発行元: Google Research
- 発行日: 2025年8月14日
- URL: https://research.google/blog/beyond-billion-parameter-burdens-unlocking-data-synthesis-with-a-conditional-generator/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- CTCLは、巨大なLLMのファインチューニングを必要とせず、プライバシーを保護した高品質な合成テキストデータを生成するための新しいフレームワークである。
- 1.4億パラメータという軽量なモデルを使用するため、計算コストを大幅に削減でき、リソースが限られた環境でも利用可能である。
- 「トピックモデルによるデータの分類」と「キーワードに基づく条件付き生成」を組み合わせることで、元のデータのトピック分布を正確に再現する。
- 差分プライバシー(DP)という技術を用いることで、個人の情報が漏洩するリスクを数学的に抑制し、強いプライバシー保証を実現する。
- 一度モデルを学習させれば、追加のプライバシーコストなしで、必要な量の合成データを自由に生成できる高いスケーラビリティを持つ。
- 実験において、特に強いプライバシー保護が求められる条件下で、既存の他手法を上回る性能を実証した。
詳細解説
背景:なぜ今、プライバシーを守るデータ生成技術が重要なのか?
AI、特に言語モデルの開発において、データは「燃料」のようなものです。しかし、医療記録、顧客との対話履歴、社内文書など、価値あるデータの多くはプライバシーに関わる情報を含んでいます。これらのデータをそのままAIの学習に使うことは、情報漏洩のリスクを伴います。
そこで合成データが解決策として期待されています。これは、実在しないものの、元のデータが持つ統計的な特徴やパターンを忠実に再現した人工的なデータです。合成データを使えば、プライバシーを守りながらAIを学習させることができます。
この合成データ生成に差分プライバシー(Differential Privacy, DP)という技術を組み合わせるのが現在の主流です。これは、「データセットに特定の個人のデータが含まれていてもいなくても、出力結果がほとんど変わらないようにする」という考え方で、個人のプライバシーを強力に保護します。プライバシー保護の強度はε(イプシロン)という指標で表され、εが小さいほど、より強力なプライバシー保護を意味します。
しかし、従来の有力な手法は、巨大なLLMを差分プライバシーを適用しながらファインチューニングする必要がありました。これには膨大な計算機リソースと時間が必要となり、誰でも手軽に利用できる技術ではありませんでした。
新しい解決策「CTCL」フレームワークの全体像
今回紹介するCTCL (Data Synthesis with ConTrollability and CLustering) は、この「計算コスト」と「プライバシー保護」の両立という課題を解決するために開発されました。CTCLは、巨大なモデルに頼るのではなく、軽量なモデルを巧みに利用することで、効率的かつ安全に高品質な合成データを生成します。
そのプロセスは、大きく分けて以下の3つのステップで構成されています。
- 事前準備: 公開されている大規模データを使って、汎用的な「トピック分類器」と「文章生成器」を一度だけ作成する。
- プライベートドメインの学習: プライバシーを守りたいデータ(プライベートデータ)の特徴を、プライバシーを保護しながら学習する。
- 合成データの生成: 学習したモデルを使って、プライベートデータの特徴を再現した合成データを生成する。
これから、各ステップをより具体的に見ていきましょう。
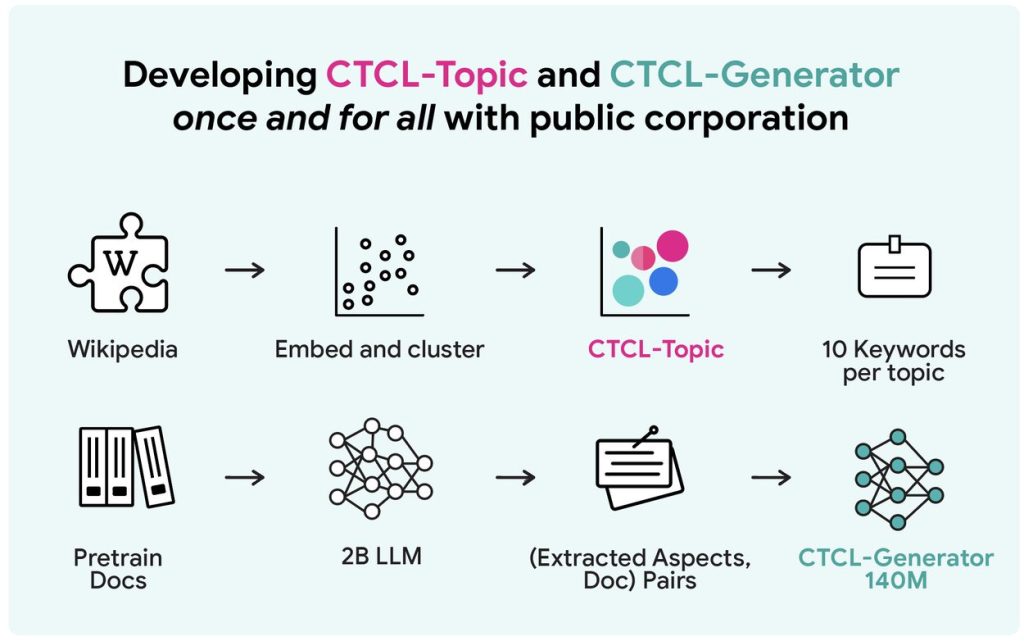
ステップ1:汎用的な「道具」を一度だけ準備する
CTCLでは、まずどんなデータにも対応できる汎用的な2つの「道具」を、Wikipediaなどの公開データを使って準備します。この準備は一度だけで済み、その後は様々なプライベートデータに応用できます。
- CTCL-Topic(話題の地図):
これは、文章がどのような話題(トピック)について書かれているかを分類するためのモデルです。Wikipediaにある約600万の文書を解析し、「科学」「スポーツ」「歴史」といった約1000個のトピックに分類します。そして、各トピックを最もよく表す10個のキーワードを紐付けます。これにより、どんな文章でも、どのトピックに属するのか、またそのトピックはどんなキーワードで特徴づけられるのかを判断できる「話題の地図」のようなものが出来上がります。 - CTCL-Generator(文章生成職人):
こちらは、与えられた条件に基づいて文章を生成する言語モデルです。特筆すべきは、そのパラメータ数が1.4億と、一般的なLLM(数十億〜数千億)と比較して非常に軽量である点です。このモデルは、「キーワード」や「文書の種類」といった指示(条件)を与えると、その条件に合った文章を生成できるように事前学習されています。まるで「お題を与えると、それに沿った文章を上手に作ってくれる職人」のような存在です。
ステップ2:プライベートデータの特徴を学習する
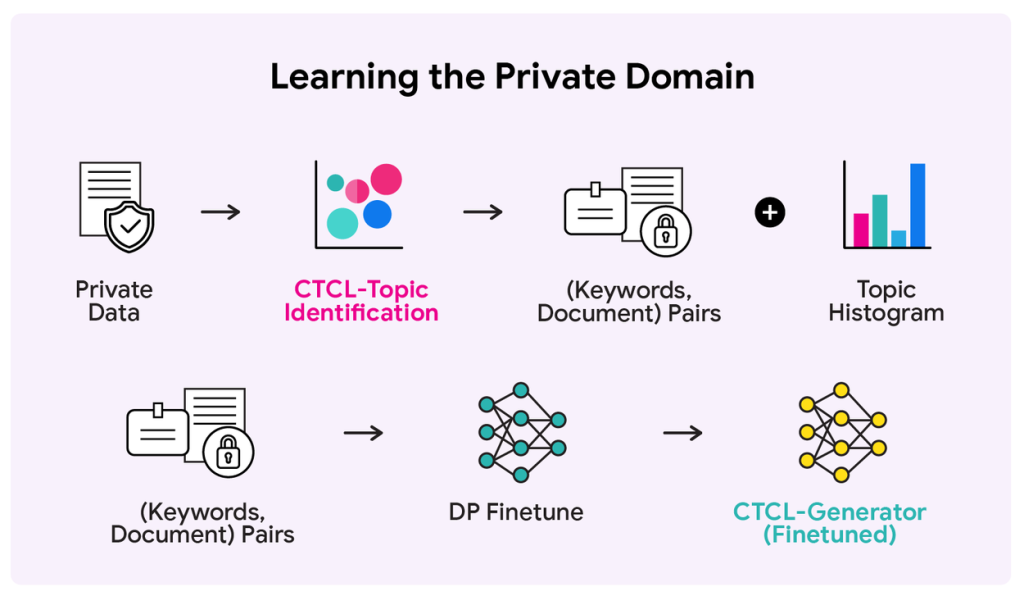
次に、この2つの道具を使って、保護したいプライベートデータセットの特徴を学習します。この際、差分プライバシー(DP)を適用することで、個々のデータの内容が外部に漏れないようにします。
- まず、プライベートデータセット内の各文書をCTCL-Topicの「話題の地図」に照らし合わせ、どのトピックがどのくらいの割合で含まれているかの統計情報(トピックヒストグラム)を、DPを適用して安全に収集します。これにより、「このデータセットは医療に関する話題が30%、法律に関する話題が20%…」といった全体像を、プライバシーを保ちながら把握できます。
- 同時に、プライベートデータセットの各文書を「(その文書が属するトピックの)10個のキーワード」と「文書本体」のペアに変換します。
- このキーワードと文書のペアを使って、軽量な文章生成職人(CTCL-Generator)をDPでファインチューニングします。これにより、職人はそのプライベートデータが持つ特有の文体や専門用語を学習し、「特定のドメインに特化した文章生成職人」へと進化します。
ステップ3:高品質な合成データを生成する
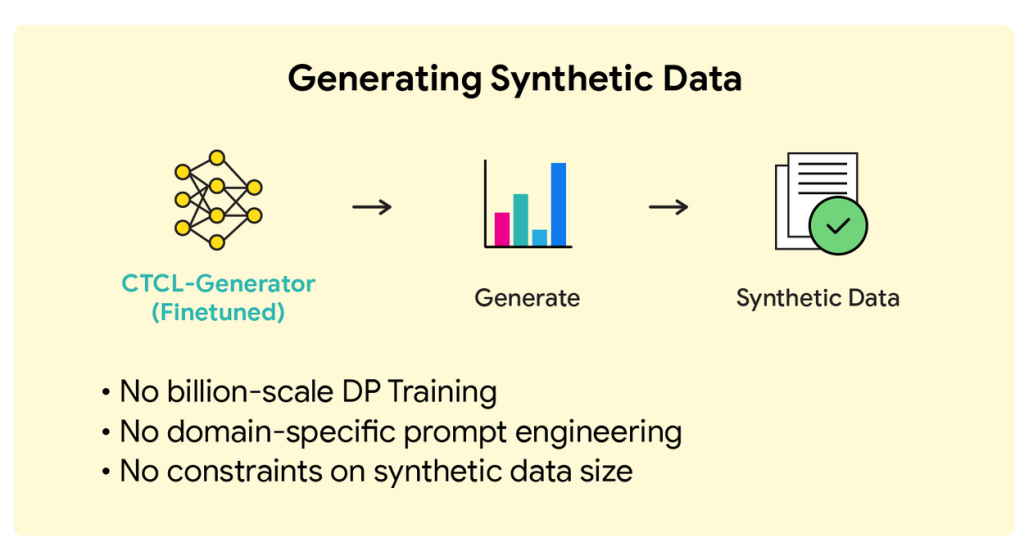
最後のステップでは、いよいよ合成データを生成します。
- ステップ2で安全に収集したトピックヒストグラム(話題の割合)に基づき、どのトピックのデータをいくつ生成するかを決定します。例えば、「医療」のトピックが30%なら、生成するデータ全体の30%が医療に関するものになるようにします。
- 次に、生成したいトピックに対応する10個のキーワードを、ステップ2で特化させた文章生成職人(CTCL-Generator)に指示として与えます。
- 指示を受け取った生成職人は、学習した文体や知識を基に、キーワードに沿った新しい文章を生成します。
このプロセスを繰り返すことで、元のプライベートデータのトピック分布を正確に再現しつつ、内容は全く新しい、プライバシーが保護された合成データセットを構築できます。差分プライバシーの性質上、一度モデルを学習させてしまえば、追加のプライバシーコストを支払うことなく、必要なだけデータを生成し続けられる点も大きな利点です。
実験で示されたCTCLの有効性
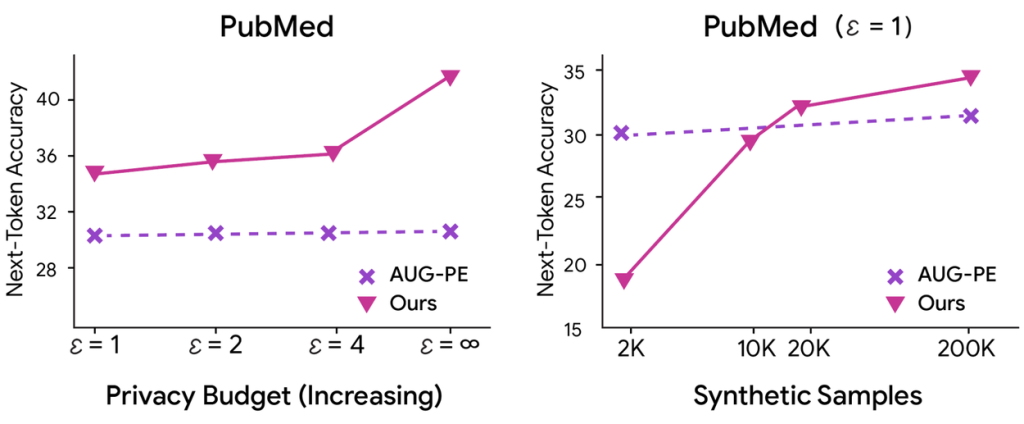
研究チームは、医療論文の要約やチャット対話など、4つの異なるデータセットでCTCLの性能を評価しました。その結果、CTCLは既存のどの手法よりも高い品質の合成データを生成できることが示されました。
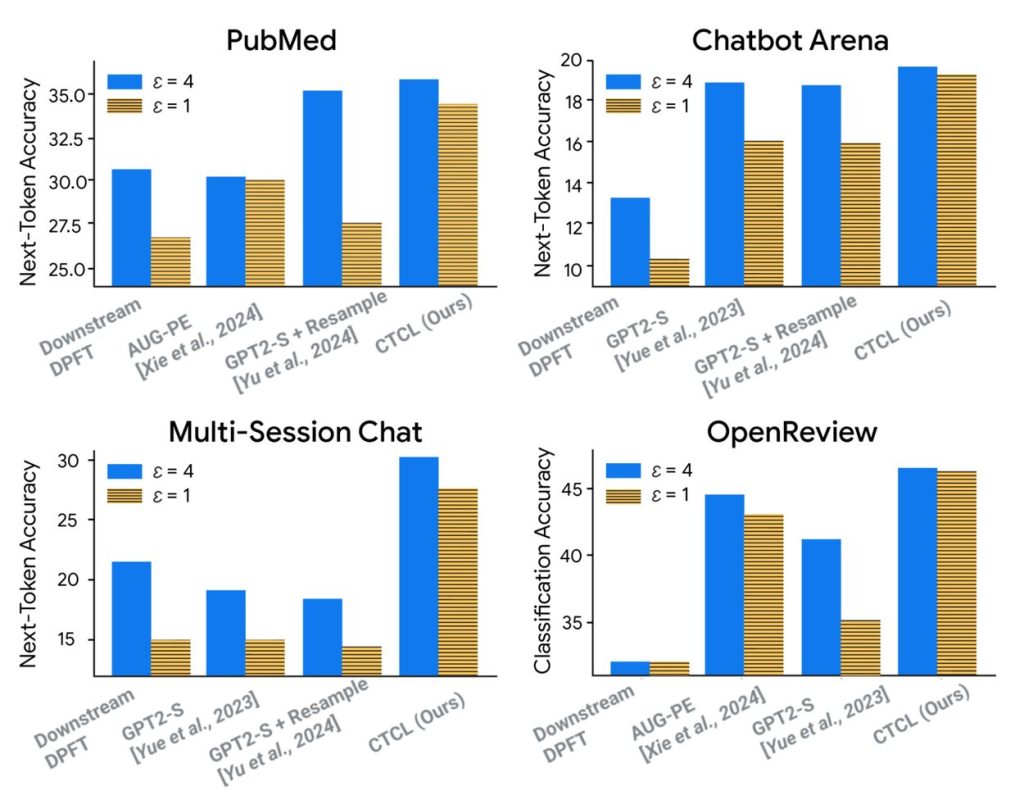
特に注目すべきは、プライバシー保護を強くすればするほど(ε値を小さくするほど)、他の手法との性能差が顕著になった点です。これは、CTCLがプライバシーと実用性のトレードオフを高いレベルで解消していることを意味します。また、生成する合成データの量を増やしていくと、CTCLで生成したデータで学習したモデルの性能は向上し続けましたが、他の手法では早い段階で性能向上が頭打ちになることも確認されました。これは、CTCLが持つ優れたスケーラビリティを示しています。
まとめ
本稿で解説したCTCLは、巨大な言語モデルに頼ることなく、軽量なモデルを効果的に活用することで、プライバシー保護と高品質な合成データ生成を両立させる新しいフレームワークです。
「トピックの分布をキーワードで制御する」というアイデアにより、計算コストを大幅に抑えつつ、元のデータの重要な特徴を保持することに成功しました。これにより、これまで計算リソースの制約で大規模モデルを扱えなかった多くの研究者や開発者にとっても、安全なデータ活用の道が大きく開かれる可能性があります。
データプライバシーの重要性がますます高まる現代において、CTCLのような技術は、AIの発展をより安全で持続可能なものにするための重要な一歩と言えるでしょう。








