
はじめに
もし、ロボットがインターネットに繋がっていなくても、まるで人間のようにこちらの言葉を理解し、身の回りのものを器用に扱えるようになったら、私たちの生活や産業はどう変わるでしょうか?
本稿では、Google DeepMindが発表した画期的なロボティクスAIモデル「Gemini Robotics On-Device」について、2025年6月24日に公開された同社の公式ブログ記事「Gemini Robotics On-Device brings AI to local robotic devices」を基に、その核心的な内容と将来的な可能性を解説します。
引用元記事
- タイトル: Gemini Robotics On-Device brings AI to local robotic devices
- 著者: Carolina Parada
- 発行元: Google DeepMind
- 発行日: 2025年6月24日
- URL: https://deepmind.google/discover/blog/gemini-robotics-on-device-brings-ai-to-local-robotic-devices/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Google DeepMindは、ロボット本体で直接動作するように最適化された新しいVLA(視覚言語行動)モデル「Gemini Robotics On-Device」を発表した。
- 最大の特徴は、クラウド接続を必要としない「オンデバイス」処理であり、これにより低遅延での応答と、オフライン環境での安定した動作を実現する。
- 自然言語の指示を理解し、バッグのジッパーを開けたり衣類をたたんだりといった、高度な器用さが求められるタスクを実行できる汎用性を持つ。
- わずか50~100回程度の少ない実演データで新しいタスクに迅速に適応(ファインチューニング)できる、高い学習効率を誇る。
- 双腕ロボットや人型ロボットなど、異なる形状(エンボディメント)のロボットにも適応可能であり、幅広い応用が期待される。
- 開発者がこのモデルを容易に評価・導入できるよう、専用のSDK(ソフトウェア開発キット)が提供される。
詳細解説
「オンデバイスAI」がロボットにもたらす革命とは?
今回の発表で最も重要なキーワードが「オンデバイス(On-Device)」です。これは、AIモデルがクラウド上の巨大なサーバーではなく、ロボットというデバイス本体に搭載され、その内部で全ての計算処理が完結することを意味します。
これまでの多くの高度なAIは、大量の計算を必要とするため、データを一度インターネット経由でクラウドに送り、そこで処理された結果を受け取るという仕組みでした。しかし、この方法には「通信遅延(レイテンシー)」や「通信環境への依存」という課題がありました。
「Gemini Robotics On-Device」は、この課題を解決します。ロボットがインターネットに接続されていない状況でも、自律的に思考し、行動できるようになります。これは、例えば以下のような大きな利点をもたらします。
- 応答速度の向上: 通信のタイムラグがなくなるため、ロボットが瞬時に判断し、滑らかに動作できます。精密な作業や人間との協調作業において極めて重要です。
- オフラインでの安定稼働: 工場や倉庫、災害現場など、Wi-Fi環境が不安定または存在しない場所でも、ロボットは問題なく任務を遂行できます。
- セキュリティとプライバシー: 映像などの機密データを外部のサーバーに送信する必要がないため、情報漏洩のリスクを低減できます。
このモデルは、VLA(Vision Language Action)モデルと呼ばれる種類のAIを基にしています。これは、ロボットが搭載するカメラからの「視覚(Vision)」情報と、人間からの「言語(Language)」による指示を統合的に理解し、具体的な「行動(Action)」へと変換する仕組みです。つまり、「この引き出しを開けて、中のリンゴを取って」といった複雑な命令を、見て、聞いて、実行できるのです。
驚異的な汎用性と、わずかな実演で学ぶ「高速適応能力」
「Gemini Robotics On-Device」は、単にオンデバイスで動くだけではありません。その性能も非常に優れています。記事で示されたベンチマーク結果を見ると、特に「汎化性能」と「高速な適応能力」が際立っています。
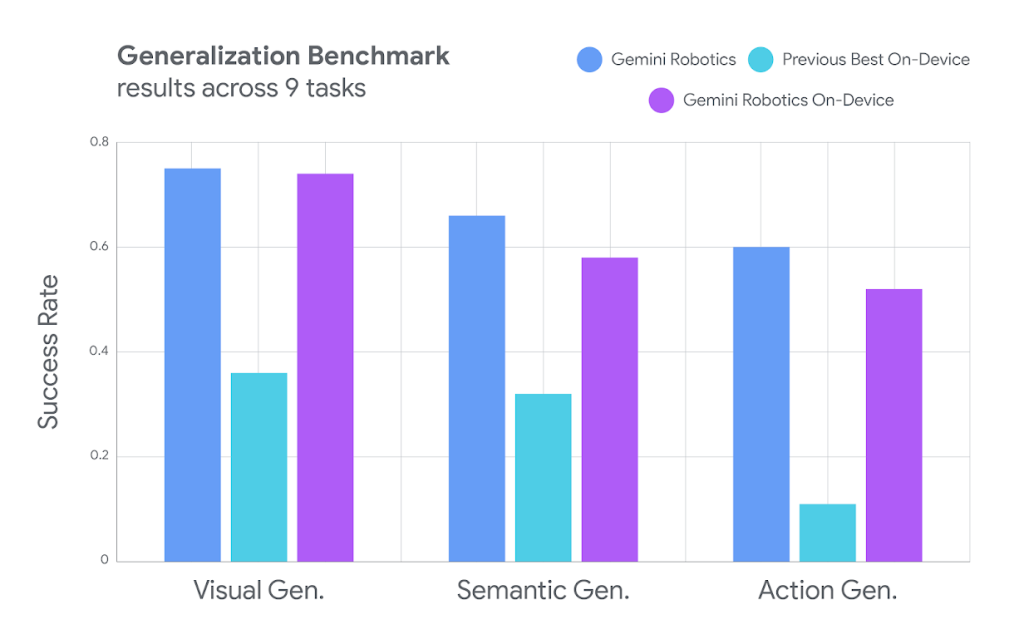
- 高い汎化性能:
汎化性能とは、AIが学習データに含まれていない「初めて見るモノ」や「初めての状況」にどれだけうまく対応できるかを示す能力です。このモデルは、視覚的(見たことのない物体)、意味的(「飲み物を取って」という指示でジュースもお茶も理解する)、行動的(状況に応じて最適な動きを判断する)な全ての側面で、既存のオンデバイスモデルを大きく上回る性能を示しています。これは、ロボットがより柔軟で賢く振る舞えることを意味します。
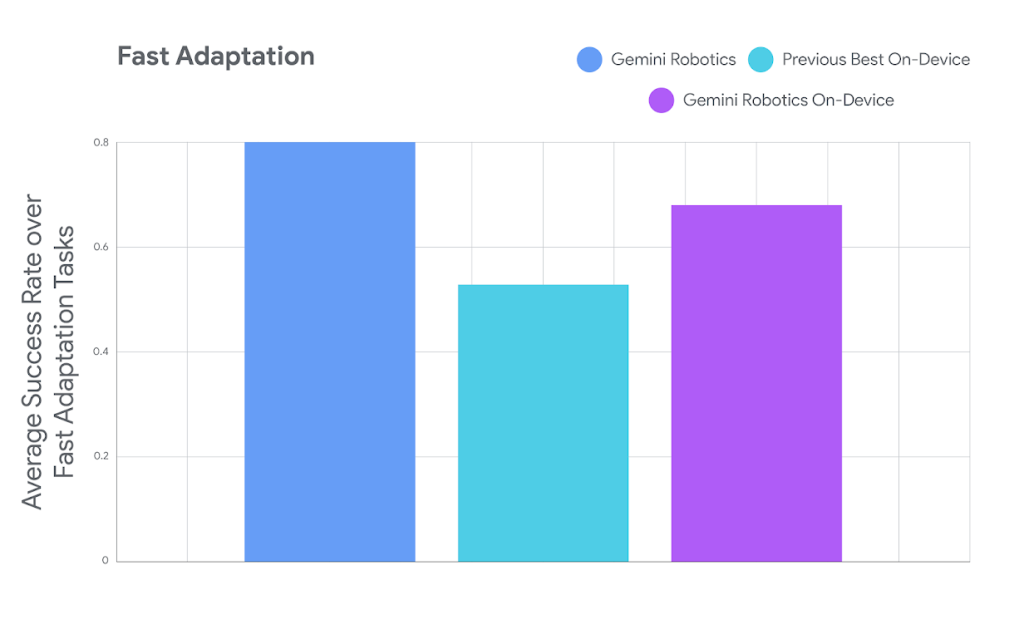
- 高速な適応能力(ファインチューニング):
このモデルの最も驚くべき点の一つは、新しいタスクへの適応の速さです。AIに新しい作業を覚えさせるには、通常、大量の学習データ(デモンストレーション)が必要でした。しかし、このモデルはわずか50回から100回程度のデモンストレーションで、新しいタスクを高精度で実行できるようになります。記事では、弁当箱のジッパーを閉める、サラダのドレッシングをかけるといった7つの器用な作業でその性能が実証されています。
これは、ロボットを現場に導入する際の時間とコストを劇的に削減できる可能性を秘めており、ロボット活用のハードルを大きく下げるものです。
ロボットの「体」を選ばない、驚きの適応力
AIモデルは、特定のロボットの形状(エンボディメント)に合わせて開発されることが多く、他の形状のロボットに流用するのは困難でした。
しかし、「Gemini Robotics On-Device」は、元々「ALOHA」という研究用の双腕ロボットで学習されたにもかかわらず、全く異なる形状のロボットにも適応できることが示されました。具体的には、産業用の双腕ロボット「Franka FR3」や、Apptronik社が開発した人型ロボット「Apollo」に移植され、自然言語の指示に従って器用な作業をこなすことに成功しています。
この事実は、このモデルが特定のハードウェアに縛られない、非常に汎用性の高い「ロボットの脳」として機能することを示しています。これにより、様々なメーカーが開発する多種多様なロボットに、この賢いAIを搭載できる道が開かれます。
開発者を支え、安全性を追求する姿勢
Google DeepMindは、この革新的な技術を広く普及させるため、開発者向けのSDK(ソフトウェア開発キット)の提供も発表しました。SDKには、モデルの評価ツールや物理シミュレーター(MuJoCo)でのテスト環境などが含まれており、開発者は自身のアプリケーションにこのモデルを迅速に組み込み、テストすることが可能になります。
また、安全性と責任ある開発にも重点が置かれています。AIが誤った解釈や危険な動作をしないよう、意味的な安全性をチェックする仕組みや、物理的な安全を確保する低レベルのコントローラーと連携させています。これは、AIを現実世界で活用する上で不可欠な取り組みであり、技術の社会実装に対する真摯な姿勢の表れと言えるでしょう。
まとめ
今回発表された「Gemini Robotics On-Device」は、ロボティクス分野における大きなブレークスルーです。AIがクラウドから解き放たれ、ロボット本体に宿ることで、低遅延、オフラインでの安定稼働、そして高い安全性が実現します。
さらに、少ないデータで新しいタスクを迅速に学習する能力と、異なるロボットにも適応できる汎用性は、これまでロボットの導入を阻んできた多くの壁を取り払う可能性を秘めています。
この技術が普及すれば、私たちの家庭ではより賢いお手伝いロボットが生まれ、工場では生産ラインがさらに柔軟になり、医療や介護の現場では人間の負担を軽減する頼もしいパートナーが登場するかもしれません。本稿で解説した「Gemini Robotics On-Device」は、AIが仮想世界から物理世界へと本格的に進出し、私たちの生活を根底から変えていく、そんな未来の始まりを告げる重要な一歩なのです。








