はじめに
AIによる画像認識技術は、日々進化を続けています。かつては画像に何が写っているかを識別するのが主な用途でしたが、今やAIは、人間が自然に使う言葉での複雑な指示を理解し、画像の特定の部分だけを正確に選び出す能力を持つに至りました。
本稿では、Google Developers Blogで発表された記事「Conversational image segmentation with Gemini 2.5」を基に、この先進的な「対話型画像セグメンテーション」という技術について、その仕組みから具体的な活用例まで解説していきます。
参考記事
- タイトル: Conversational image segmentation with Gemini 2.5
- 著者: Paul Voigtlaender, Valentin Gabeur, Rohan Doshi
- 発行元: Google Developers Blog
- 発行日: 2025年7月21日
- URL: https://developers.googleblog.com/en/conversational-image-segmentation-gemini-2-5/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Gemini 2.5は、自然言語による複雑な指示を理解し、画像内の特定の領域をピクセル単位で正確に識別する「対話型画像セグメンテーション」を実現したものである。
- この技術は、物体間の関係性、条件、抽象的な概念、画像内の文字情報などを基にした高度なクエリ処理が可能である。
- 従来のセグメンテーション技術と異なり、事前に定義されたカテゴリに縛られず、より直感的で柔軟な画像操作を実現する。
- クリエイティブ作業の効率化、労働安全の監視、保険の損害査定など、多様な分野での応用が期待される。
詳細解説
画像セグメンテーション技術の進化と「対話型」の登場
「対話型画像セグメンテーション」を理解するために、まずは画像認識技術の進化の道のりを簡単に振り返ってみましょう。
- 物体検出(Bounding Box): AIが画像の「どこに」物体があるかを四角い枠で囲んで示す技術です。「猫」や「車」といった物体の存在と大まかな位置を把握できます。
- 画像セグメンテーション: さらに進んで、物体の形に沿ってピクセル単位で領域を塗り分ける技術です。これにより、物体の正確な形状がわかります。
- オープンボキャブラリーセグメンテーション: 「青いスキーブーツ」や「木琴」のように、事前に学習データに含まれていないような自由な単語(語彙)で対象を指定できる技術です。
これらの技術は非常に強力ですが、指示は基本的に「名詞」、つまり物体の名前で行う必要がありました。しかし、私たちが何かを指し示すとき、「一番遠くにある車」や「傘をさしている人」のように、周りとの関係性や状況を説明する言葉を使います。
今回登場した「対話型画像セグメンテーション」は、まさにこのような人間が使う自然で説明的な言葉(参照表現)をAIが理解し、該当する領域を正確に特定する技術なのです。これは、AIが単に物体を認識するだけでなく、画像全体の文脈や意味を深く理解していることを示しています。
Geminiはどのような「言葉」を理解できるのか?
Gemini 2.5の対話型セグメンテーションは、主に5つのカテゴリの高度な指示(クエリ)を処理できます。これにより、これまでにない直感的な画像操作が可能になります。
1. 物体間の関係性
「左から3番目の本」や「花束の中で一番しおれている花」のように、他の物体との位置関係や比較に基づいた指示を理解します。
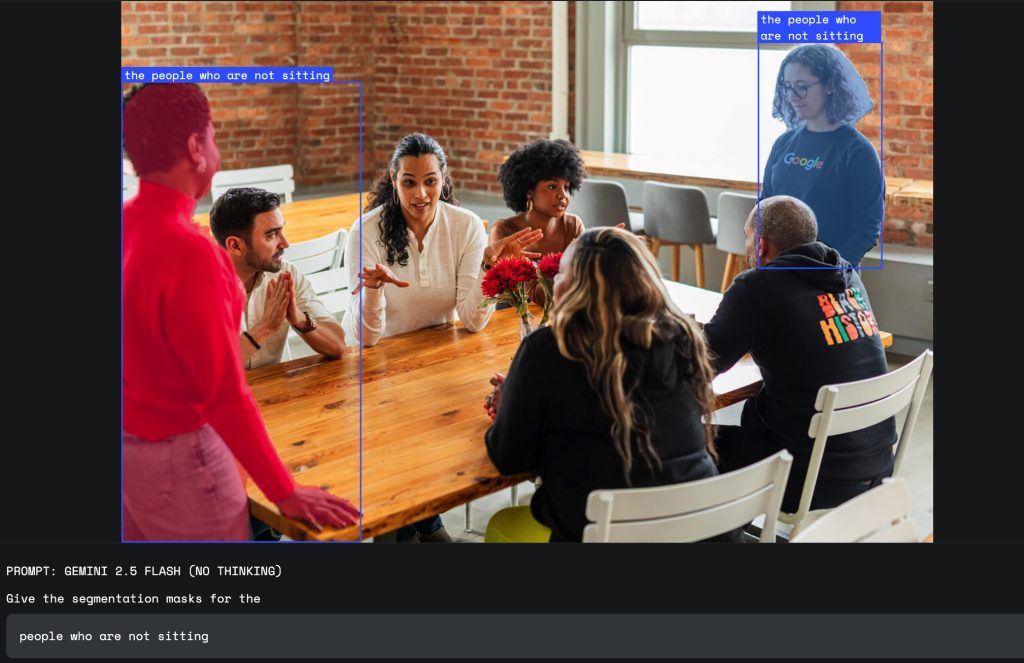
2. 条件論理
「座っていない人々」のように否定の条件を加えたり、「ベジタリアン向けの食べ物」のように特定の条件に合うものを抽出したりできます。これは、単純な物体名では不可能な、より複雑な絞り込みを可能にします。
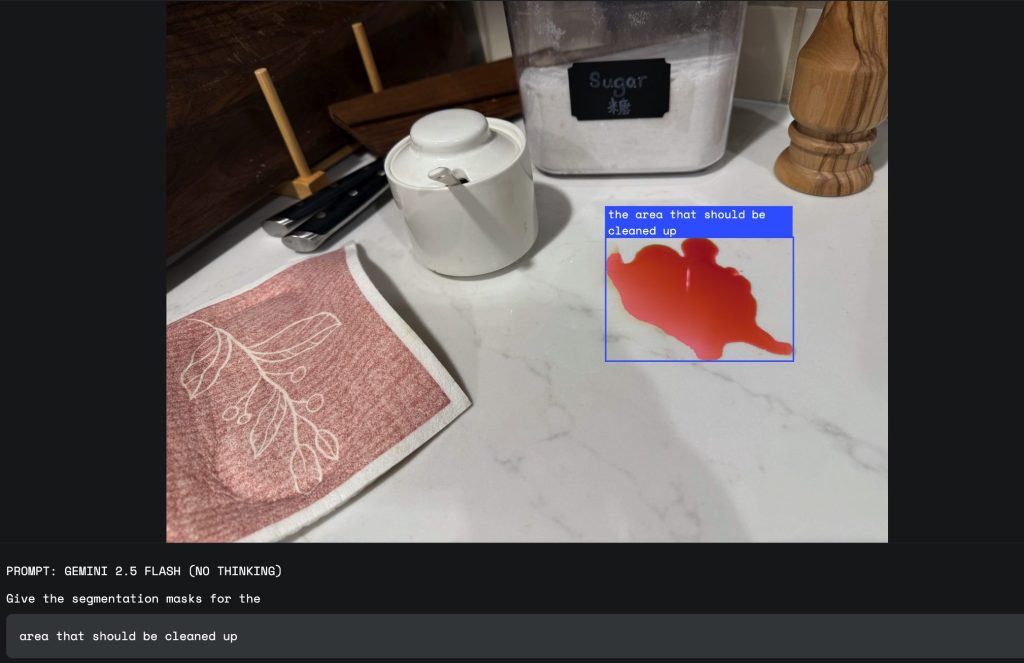
3. 抽象的な概念
この技術の特に強力な点として、「損傷」「散らかった場所」「好機」といった、視覚的な定義が一つに定まらない抽象的な概念を理解できることが挙げられます。Geminiは、その知識ベースを活用して、例えば「損傷」が何を意味するのか(へこみ、ひび割れなど)を文脈から判断し、該当箇所を特定します。
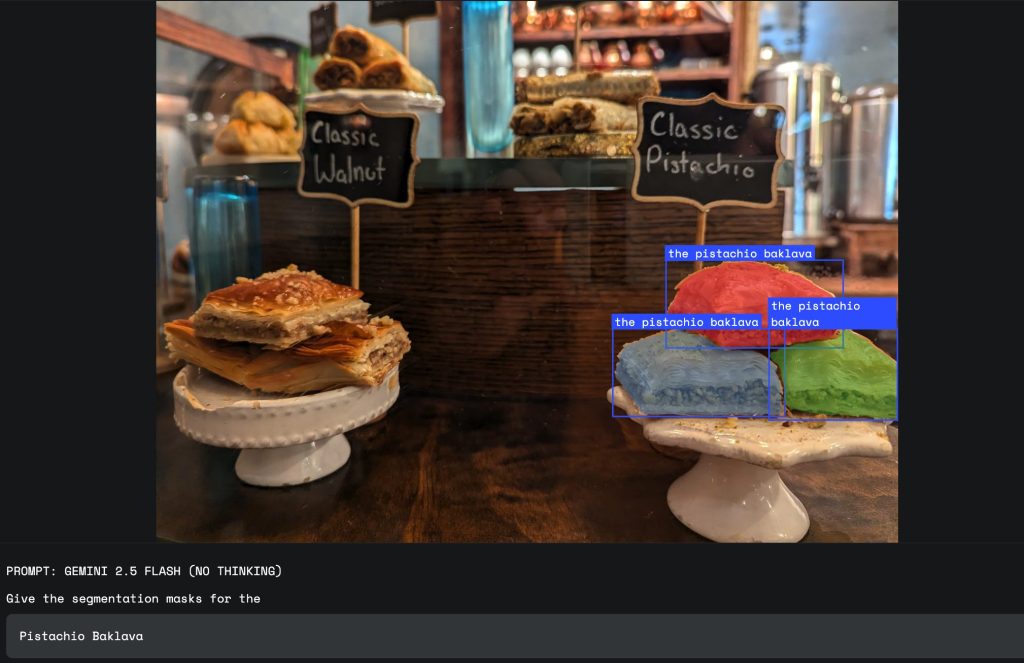
4. 画像内のテキスト(OCR連携)
「『Pistachio』と書かれたバクラヴァ」のように、画像内に写っている文字情報を読み取り(OCR)、それを手掛かりに対象を特定します。見た目が似ている商品を正確に見分ける際に非常に有効です。
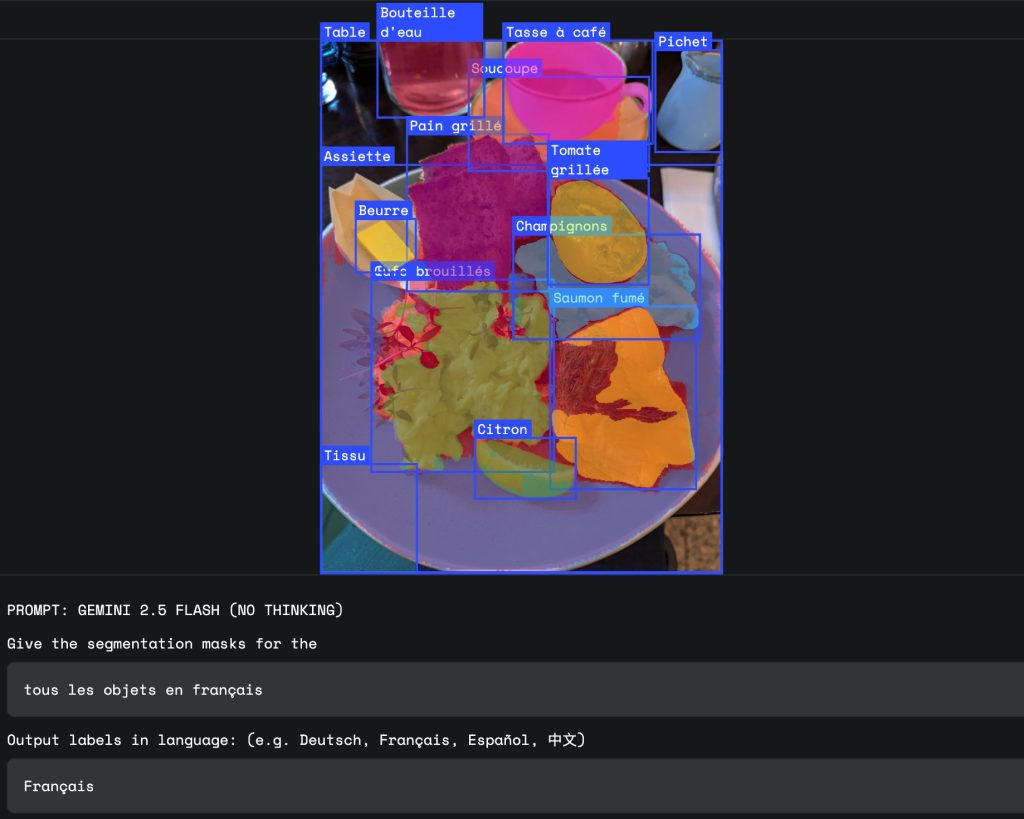
5. 多言語ラベル
指示は英語に限りません。フランス語や日本語など、多様な言語での指示に対応しており、グローバルな利用が可能です。
この技術がもたらす未来:具体的な活用事例
では、この対話型画像セグメンテーションは、私たちの社会や仕事にどのような変化をもたらすのでしょうか。
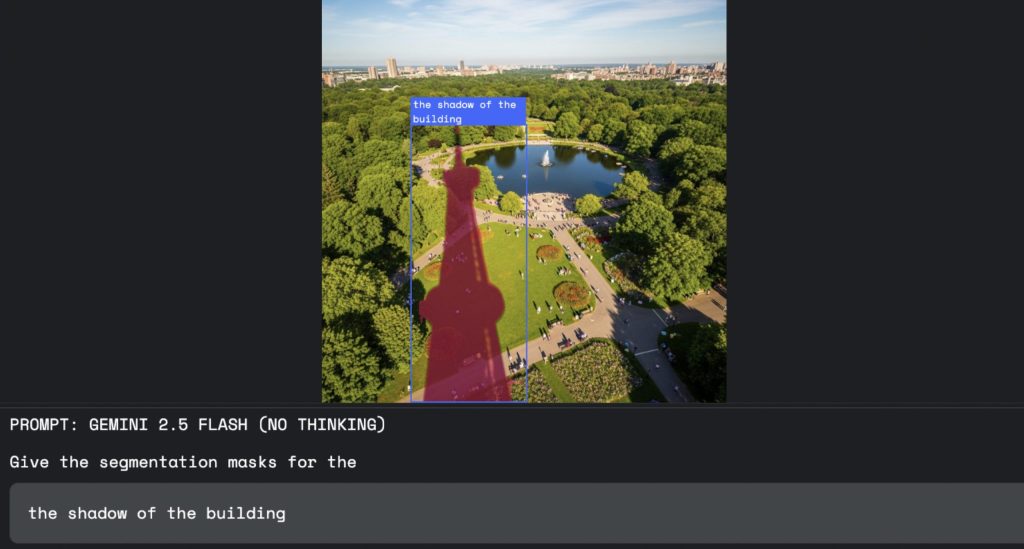
1. クリエイティブ作業の革新
デザイナーや編集者は、画像編集ソフトで複雑な選択範囲を作成する際、多大な時間と労力を費やしてきました。この技術を使えば、「公園に落ちる塔の影だけを選択して」と指示するだけで、AIが瞬時に正確な選択を行ってくれます。これにより、クリエイターはより本質的な創造的作業に集中できるようになります。
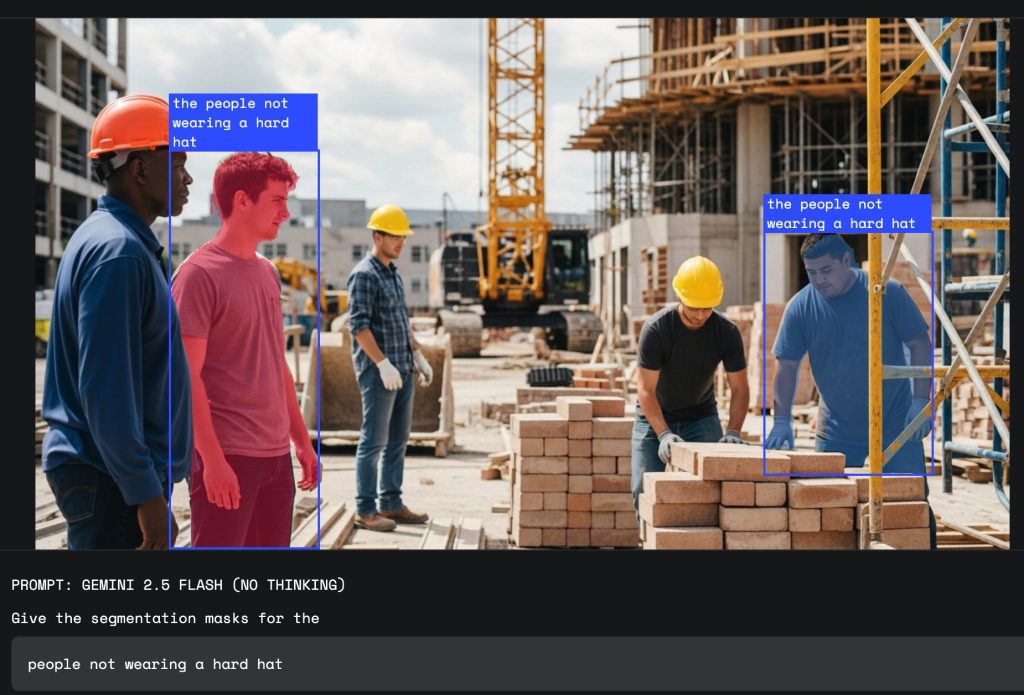
2. 安全・コンプライアンス監視の高度化
建設現場や工場の安全管理において、「ヘルメットを着用していない作業員をハイライト表示する」といった指示で、危険な状態にある人をリアルタイムに特定できます。これにより、事故を未然に防ぎ、より安全な労働環境の構築に貢献します。
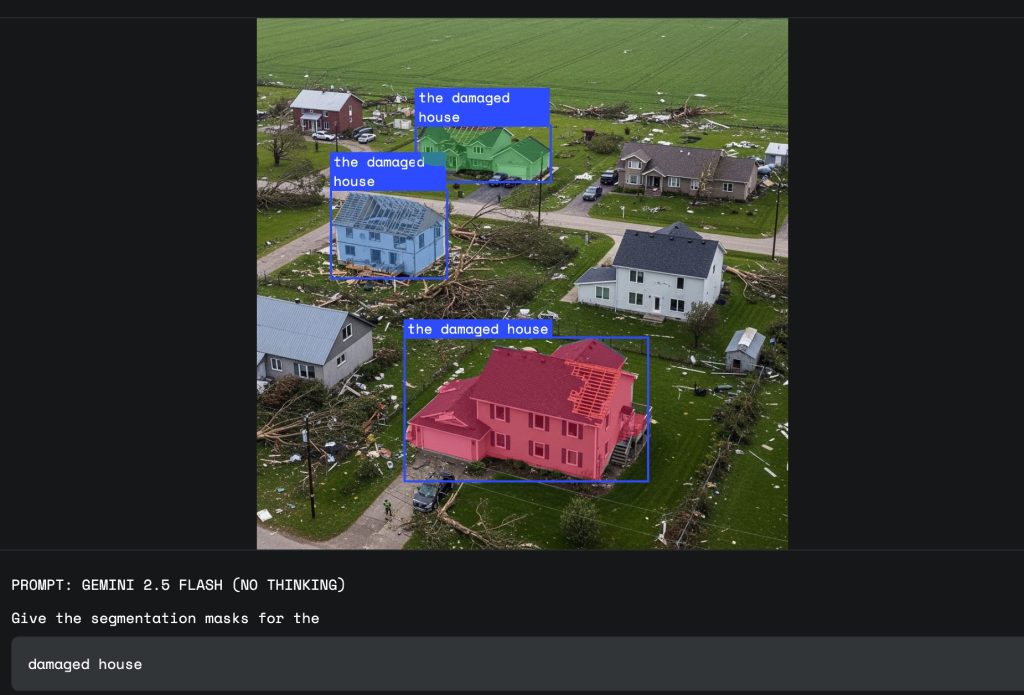
3. 保険損害査定の迅速化・効率化
自然災害が発生した際、保険会社は広範囲にわたる被害状況を迅速に把握する必要があります。ドローンや航空写真の映像から「天候による被害を受けた家屋」をAIが自動で抽出すれば、査定プロセスが大幅にスピードアップし、被災者への迅速な保険金支払いにつながります。
4. 開発者にとっての意義
この技術は、エンドユーザーだけでなく、アプリケーションを開発する開発者にとっても大きなメリットがあります。従来であれば、特定の目的(例:ヘルメット検知)のためには専門のAIモデルを個別に学習・開発する必要がありました。しかし、GeminiのAPIを利用すれば、単一のAPIを呼び出すだけで、このような高度で柔軟な画像認識機能をアプリケーションに組み込むことができます。これにより、開発のハードルが劇的に下がり、多様な業界のニッチなニーズに応える新しいソリューションが生まれやすくなります。
実践的な使い方:今すぐ始められる方法
1. Google AI Studioで試してみる(初心者向け)
最も簡単にGemini 2.5の対話型セグメンテーションを試す方法は、Google AI Studioを使用することです。
アクセス方法:
- Google AI Studio: https://aistudio.google.com/
- ログイン後、「New Chat」からGemini 2.5 Flashモデルを選択
- 画像をアップロードして、自然言語でセグメンテーション指示を入力
使用例:
この画像で「赤い帽子をかぶっている人」をセグメント化してください。
セグメンテーションマスクをJSON形式で出力してください。2. Python環境での利用(開発者向け)
Python環境でプログラム的に利用したい場合は、Googleが提供するColabノートブックから始めることができます。
リソース:
- Spatial Understanding Colab: https://colab.research.google.com/github/google-gemini/cookbook/blob/main/quickstarts/Spatial_understanding.ipynb
- このノートブックでは、画像アップロードから自然言語クエリ、セグメンテーション結果の可視化までの一連の流れを実践できます
基本的な実装例:
import google.generativeai as genai
<em># APIキーの設定</em>
genai.configure(api_key="YOUR_API_KEY")
<em># モデルの選択</em>
model = genai.GenerativeModel('gemini-2.5-flash')
<em># 画像とプロンプトを送信</em>
response = model.generate_content([
"この画像でヘルメットをかぶっていない作業員をセグメンテーションしてください。",
image_data
])3. Gemini APIの活用(プロダクション環境)
本格的なアプリケーション開発では、Gemini APIを直接利用します。
関連リンク:
- Gemini API開発者ガイド: https://ai.google.dev/docs/gemini_api_overview#vision
- セグメンテーション詳細ドキュメント: https://ai.google.dev/gemini-api/docs/image-understanding#segmentation
- 開発者フォーラム: https://discuss.ai.google.dev/
4. ベストプラクティス
Google推奨の最適な使用方法:
技術的推奨設定:
- モデル選択:
gemini-2.5-flashを使用 - 思考予算:
thinkingBudget=0に設定(無効化) - 出力形式: JSON形式を明示的に要求
推奨プロンプト形式:
Give the segmentation masks for the objects.
Output a JSON list of segmentation masks where each entry contains:
- the 2D bounding box in the key "box_2d"
- the segmentation mask in key "mask"
- the text label in the key "label"
Use descriptive labels.
[あなたの具体的な指示をここに記述]5. 料金とアクセス制限
料金について:
- Google AI Studioでは制限付きの無料利用が可能
- プロダクション環境では利用量に応じた課金
- 最新の料金情報は公式ドキュメントを確認
APIキー取得:
- Google AI Studioにログイン
- 「Get API Key」からキーを生成
- 開発環境に安全に設定
6. サポートとコミュニティ
技術的な質問や議論は以下のリソースを活用:
- 開発者フォーラム: https://discuss.ai.google.dev/
- GitHubリポジトリ: Gemini APIのサンプルコードとドキュメント
- 公式ブログ: 最新のアップデートと活用事例
まとめ
本稿では、Gemini 2.5が実現した「対話型画像セグメンテーション」について解説しました。この技術は、AIが人間の自然な言葉を理解し、画像の内容をより深く解釈する能力を獲得したことを示す重要な一歩です。
単に物体を識別する時代は終わり、これからはAIと「対話」しながら、画像情報をより直感的に、そして高度に活用する時代が始まります。クリエイティブから産業、安全管理に至るまで、この技術は私たちの視覚的な認識能力を拡張する強力なパートナーとなり、社会の様々な場面で大きな可能性を拓いていくことでしょう。