はじめに
近年、大規模言語モデル(LLM)は目覚ましい進化を遂げ、文章作成、翻訳、質疑応答など、様々な分野でその能力を発揮しています。その応用範囲は科学技術分野にも広がり、研究開発を加速させる存在として大きな期待が寄せられています。しかし、LLMが科学研究という複雑な領域で真価を発揮するには、その能力を正確に評価する必要があります。
本稿では、Google Researchが発表したLLMの科学的問題解決能力を評価するための新しいベンチマーク(評価基準)「CURIE」、「SPIQA」、「FEABench」を紹介する記事「Evaluating progress of LLMs on scientific problem-solving」を基に、その内容を紹介します。これらのベンチマークは、LLMが科学論文のような長文の文脈を理解し、図や表を含む多様な情報(マルチモーダル情報)を解釈し、専門的なツールを使いこなす能力を測ることを目的としています。AIが科学者の研究活動をどのように支援できる可能性があるのか、その最前線を見ていきましょう。
引用元情報
- 記事タイトル: Evaluating progress of LLMs on scientific problem-solving
- 参照元URL: https://research.google/blog/evaluating-progress-of-llms-on-scientific-problem-solving/
- 発行日: 2025年4月3日
その他参考情報
- 元論文 (ICLR 2025採択予定): CURIE: Evaluating LLMs on Multitask Scientific Long-Context Understanding and Reasoning
- 関連論文 (NeurIPS 2024): SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers
- 関連論文 (MATH-AI workshop at NeurIPS 2024): FEABench: Evaluating Language Models on Multiphysics Reasoning Ability
- データセット等: GitHub (CURIE, SPIQA, FEABenchへのリンク含む)
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 現状の課題: 既存のLLM評価指標は、科学知識の記憶力や短い質問への応答能力に偏っており、実際の研究活動に必要な長文読解、マルチモーダル理解、推論能力を十分に測れていませんでした。
- 新しい評価基準の提案: Google Researchは、より現実的な科学的タスクにおけるLLMの能力を測定するため、3つの新しいベンチマークを開発しました。
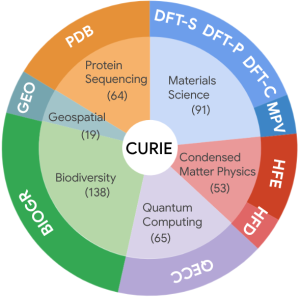
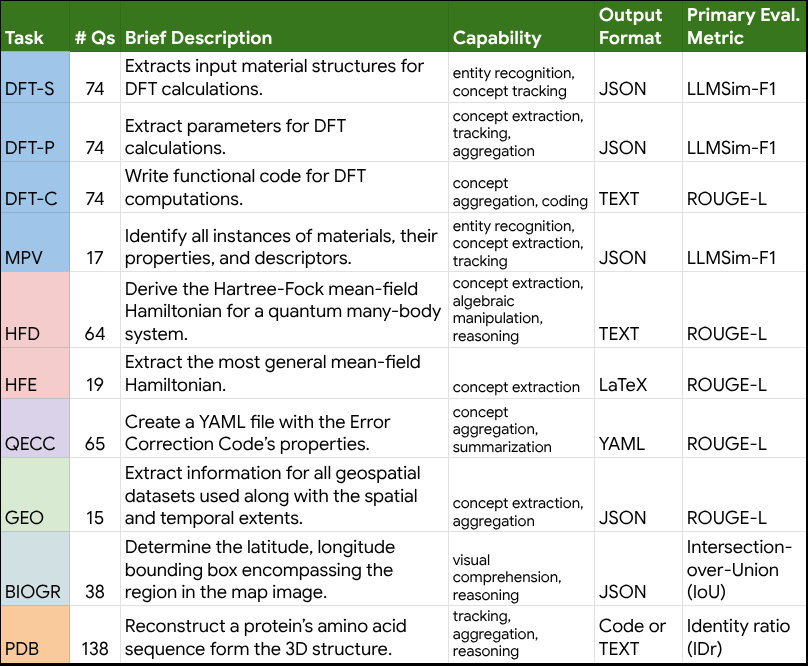
- CURIE: 科学論文全体を対象とし、長文の文脈理解、推論、情報抽出、集約能力を6つの科学分野(材料科学、物性物理学、量子コンピューティング、地理空間分析、生物多様性、タンパク質)にわたる10個のタスクで評価します。
- SPIQA: 科学論文中の図や表(マルチモーダル情報)と本文を結びつけて質問に答える能力を評価するデータセットとベンチマークです。
- FEABench: 有限要素解析(FEA)ソフトウェアのような専門ツールをLLMが操作し、工学的な問題を解決する能力を評価します。
- 評価結果: 現状の主要なLLMは、これらの新しいベンチマークにおいて、特に複数の情報を網羅的に抽出・集約するタスクなどで、まだ改善の余地が大きいことが示されました。しかし、論文から詳細情報を抽出し、指定された形式で応答を生成する点では有望な結果も得られています。
- 今後の展望: これらのベンチマークは、LLMの科学分野における応用可能性を測り、より信頼性の高い科学支援AIの開発を促進することを目指しています。
詳細解説
なぜ新しい評価基準が必要なのか?
LLMは、インターネット上の膨大なテキストデータから学習し、人間が使う言葉(自然言語)を理解し生成する能力を獲得しました。これにより、一般的な知識に関する質問応答や文章の要約などは得意としています。しかし、科学研究の現場では、単に知識を記憶しているだけでは不十分です。
科学者は、長大な論文を読み解き、そこに書かれた複雑な実験データや理論を理解し、図や表に示された情報を正確に解釈し、それらを組み合わせて新しい知見を得たり、問題を解決したりする必要があります。時には、シミュレーションソフトなどの専門的なツールを駆使することも求められます。
従来のLLM評価の多くは、短い質問に対して選択肢から答えを選ばせる形式(多肢選択式)や、断片的な知識の記憶力を問うものが中心でした。これでは、上記のような実際の科学研究に近い、複雑で長文の文脈に依存するタスクにおけるLLMの実力を正しく評価することは困難でした。そこで、Google Researchは、このギャップを埋めるために新しい評価基準の開発に着手したのです。
新しいベンチマークの紹介
CURIE (Context Understanding, Reasoning and Information Extraction)
- 目的: 科学論文全体(非常に長い文脈)を読み込み、専門知識に基づいて推論したり、必要な情報を抽出したり、複数の情報を集約したりする能力を評価します。
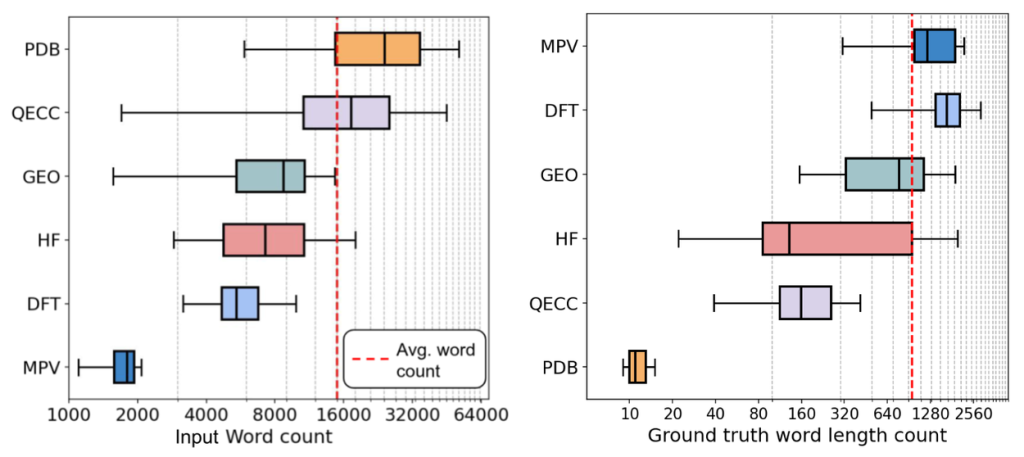
- 特徴: 材料科学から生物多様性まで、6つの多様な科学分野をカバーする10種類のタスクが含まれます。これらのタスクは、情報抽出、推論、概念追跡、集約、代数的操作、マルチモーダル理解、分野横断的な専門知識など、実際の研究ワークフローを模倣しています。例えば、「論文全体を読んで、実験で使われた全ての材料とその特性をリストアップしなさい」といった、網羅的な情報抽出を求めるタスクなどがあります。
- 評価方法: 回答が自由記述形式になることも多いため、従来の自動評価指標(ROUGE-Lなど)に加え、LLM自身を使って回答の質を評価する「LMScore」や「LLMSim」といった新しい評価手法も導入しています。これにより、より人間の評価に近い、柔軟な評価を目指しています。
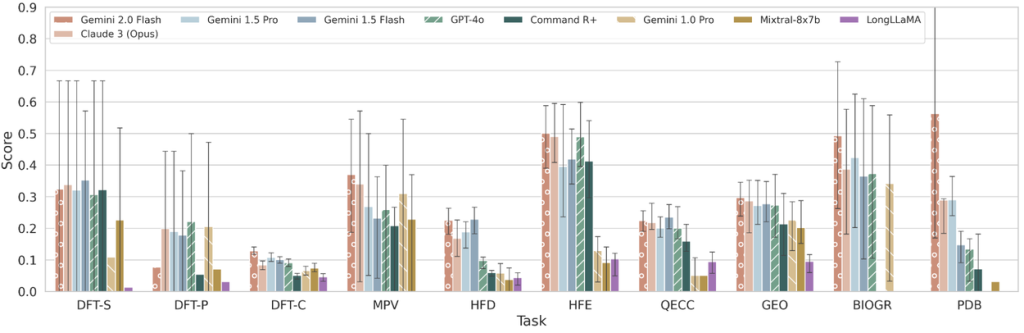
- 結果: 有名なLLMを評価したところ、全体的に改善の余地が大きいことが分かりました。特に、論文全体から網羅的に情報を探し出してまとめるようなタスク(DFT, MPV, GEOなど)で苦戦する傾向が見られました。一方で、専門家は、LLMが論文から詳細を抽出し、指定された形式で回答を生成する能力には有望さを感じています。

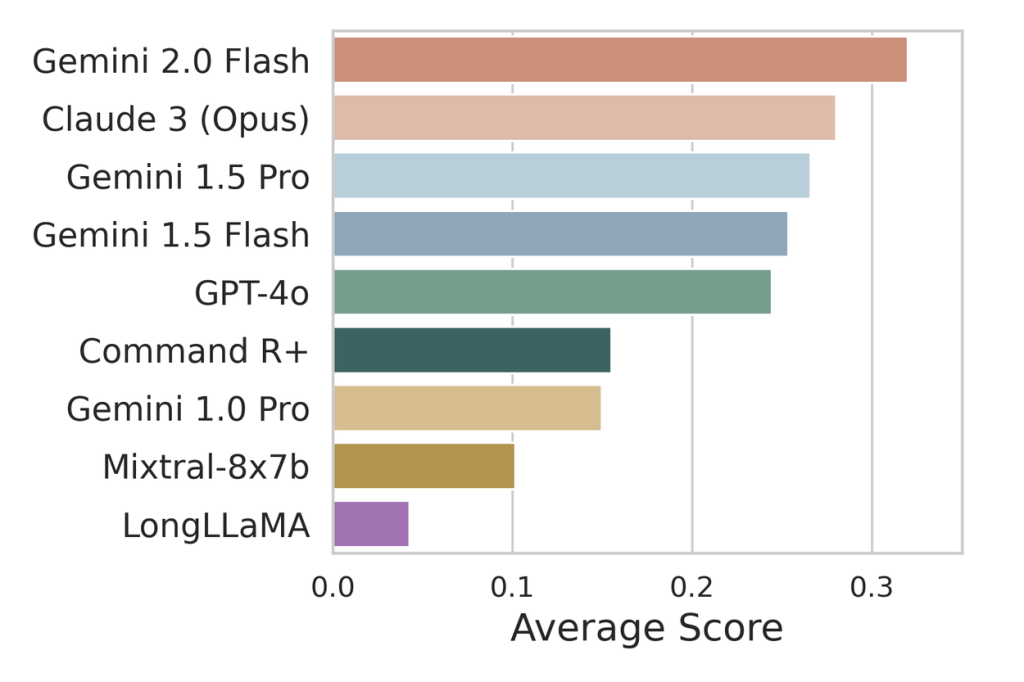
SPIQA (Scientific Paper Image Question Answering)
- 目的: 科学論文における図や表は、重要な情報や研究の概要を視覚的に伝えるために不可欠です。SPIQAは、LLMがこれらの画像情報(マルチモーダル情報)と本文テキストを同時に理解し、関連する質問に正しく答えられるかを評価します。
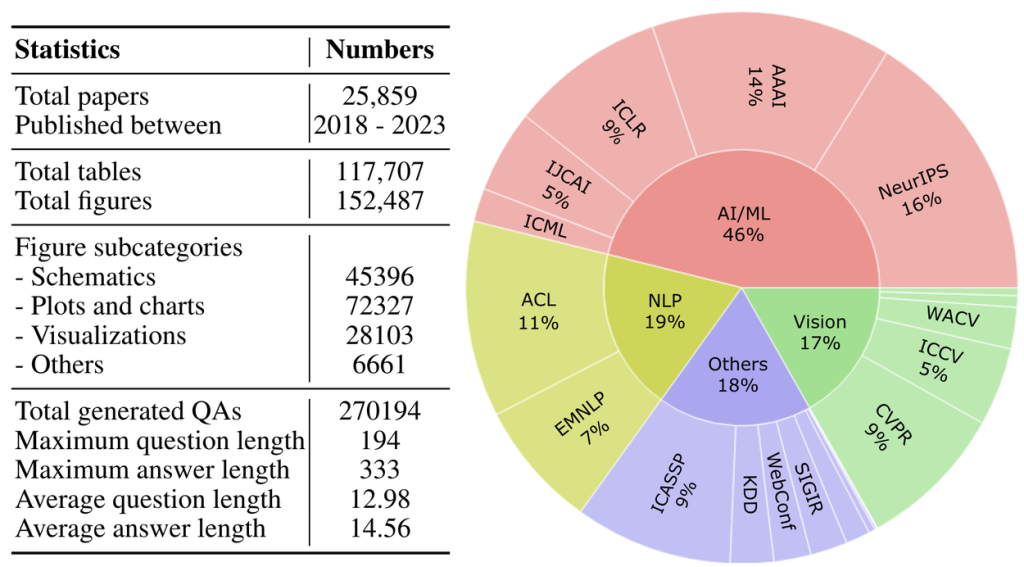
- 特徴: コンピュータサイエンス分野の論文約2万5千件から、27万件以上の質問と回答のペアを含む大規模なデータセットを構築しました。質問は、複数の図や表、グラフ、模式図、結果の可視化などを参照する必要があります。
- 結果: 主要なマルチモーダルLLMを評価し、さらにオープンソースのモデルをSPIQAデータセットでファインチューニング(追加学習)することで、性能が大幅に向上することを示しました。これは、科学分野の画像理解と言語推論能力を向上させる有望な道筋を示唆しています。
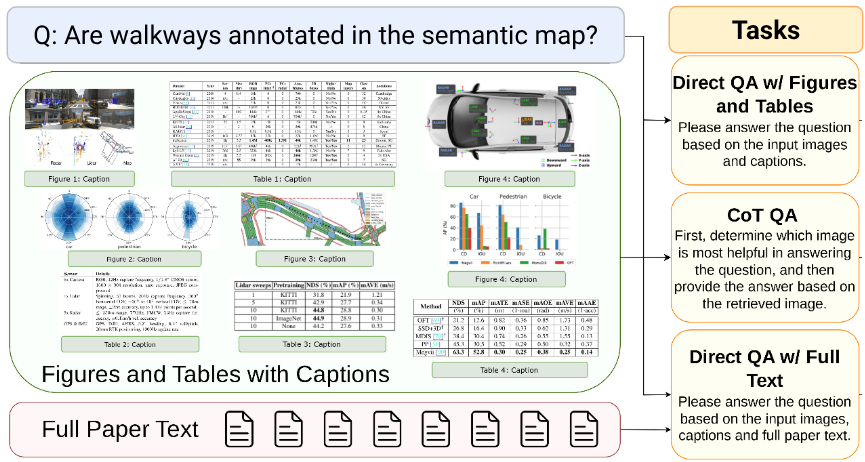
FEABench (Finite Element Analysis Benchmark)
- 目的: 科学や工学分野では、シミュレーションソフトウェアなどの専門ツールを使って定量的な問題を解くことが日常的に行われます。FEABenchは、LLMが自然言語で書かれた問題記述を理解し、有限要素解析(FEA)ソフトウェア(この研究ではCOMSOL Multiphysics®を使用)を操作して問題を解決する一連の能力を評価します。
- 特徴: 手作業で検証された15問のベンチマーク問題(FEABench Gold)と、アルゴリズムで生成された大規模な問題セットが含まれます。
- 結果: このベンチマークに含まれる問題は非常に挑戦的であり、評価対象となったLLMやエージェントは、問題を完全かつ正確に解くことができませんでした。これは、LLMが専門的なソフトウェアを自律的に操作して複雑な問題を解決するには、まだ大きな課題があることを示しています。

専門家の役割と今後の方向性
これらのベンチマーク開発の全ての段階において、各分野の専門家が重要な役割を果たしました。現実的なタスクの定義、関連論文の選定、正確で詳細な正解データの作成、そして評価指標の妥当性の確認に至るまで、専門家の知見が不可欠でした。
Google Researchは、これらのベンチマーク(CURIE, SPIQA, FEABench)のデータセットと評価コードをGitHubで公開し、コミュニティによる利用と貢献を奨励しています。これにより、科学分野におけるLLMの評価手法がさらに洗練され、信頼できるAIによる科学的発見の支援が進むことが期待されます。
まとめ
本稿では、Google Researchが提案したLLMの科学的問題解決能力を評価するための新しいベンチマーク「CURIE」、「SPIQA」、「FEABench」について解説しました。これらのベンチマークは、従来の評価手法では捉えきれなかった、長文コンテキストの理解、マルチモーダル情報の解釈、専門ツールの利用といった、より現実の科学研究に近い能力を測定しようとする意欲的な試みです。 評価結果は、現在のLLMが科学者の研究活動を完全に代替するにはまだ課題が多いことを示していますが、同時に、特定のタスクにおいては研究者を支援する大きな可能性も示唆しています。これらの評価基準を通じてLLMの能力が向上していくことで、将来的にはAIが科学研究の様々な場面で頼れるパートナーとなる日が来るかもしれません。