
はじめに
データサイエンスは、生のデータから実用的な洞察を引き出し、データ駆動型の意思決定を支える上で不可欠な分野です。企業はデータから抽出される洞察に基づいて重要な方向性を決定しており、その重要性は高まっています。しかし、現実世界のデータサイエンスのワークフローは非常に複雑で、複数のデータソースの探索、データの処理、統計分析など、コンピュータサイエンスや統計学における深い専門知識と時間を要します。
近年、大規模言語モデル(LLM)の発展に伴い、この複雑なワークフローを自動化する「データサイエンスエージェント」の研究が進んでいます。これらのエージェントは、自然言語で与えられた質問を、回答を生成するための実行可能なコード(主にPython)に直接変換することを目指しています。
しかし、既存のエージェントには大きな課題があります。
一つは、多くのエージェントがCSVファイルのような構造化データ(リレーショナルデータベース)に主に焦点を当てており、JSON、Markdown、非構造化テキストなど、現実世界で遭遇する多様な異種データ形式に対応できない点です。
もう一つは、データサイエンスのタスクは正解ラベル(Ground-truth label)が存在しないオープンエンドな問いであることが多く、エージェントが生成した分析計画が本当に問題を解くのに十分であるかを検証するのが非常に難しいという点です。たとえ実行可能なコードが生成されたとしても、それが必ずしも正しい回答を保証するわけではないため、検証の仕組みが不足していると、しばしば最適ではない計画を採用してしまう結果となります。
本稿で解説する論文は、これらの課題を克服するための新しいデータサイエンスエージェント「DS-STAR」を紹介しています。DS-STARは、反復的な計画と検証のロジックを導入することで、複雑なデータ分析タスクに対する堅牢性と高い性能を実現しています。
解説論文
- 論文タイトル:DS-STAR: Data Science Agent via Iterative Planning and Verification
- 論文URL:https://arxiv.org/pdf/2509.21825
- 発行日:2025年10月2日
- 発表者:Jaehyun Nam, Jinsung Yoon, Jiefeng Chen and Tomas Pfister (所属: Google Cloud, KAIST)
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- DS-STARは、反復的な計画(Planning)と検証(Verification)を通じて、複雑なデータサイエンスの問いに堅牢に対応するエージェントである。
- 主な貢献は以下の3点である。
- データファイル分析モジュール: 非構造化データを含む多様なデータ形式から自動的にコンテキスト情報(列名、データ型など)を探索し、抽出する。
- LLMベースの検証ステップ: LLMをJudge(判定者)として利用し、分析計画が現在の段階で問題を解決するのに「十分(sufficient)」であるかを評価する。
- 逐次計画メカニズム: シンプルな実行可能計画から始め、検証ステップからのフィードバックに基づいて計画を反復的に洗練する。これにより、複雑なデータソースが関わる分析を確実に行うことができる。
- 実験の結果、DS-STARはDABStep、KramaBench、DA-Codeの3つの主要なベンチマークにおいて、最先端の手法(SOTA)を上回る性能を達成している。
- 特に、異種フォーマットの複数ファイルを処理する必要がある難易度の高いタスクで、その優位性が顕著である。
詳細解説
論文を項目に沿って、解説します。
1. Introduction (導入)
データサイエンス(Data Science)は、生のデータ(Raw Data)を実行可能な洞察(Actionable Insights)へと変換し、データ駆動型の意思決定を支える上で非常に重要です。企業は、データから抽出される洞察に基づいて、重要な戦略的決定を行っています。
しかし、データサイエンスのワークフローはしばしば複雑であり、コンピュータサイエンスや統計学といった多様な分野にわたる深い専門知識が求められます。このワークフローには、分散したドキュメントの理解、複雑なデータ処理、統計分析など、一連の時間のかかるタスクが含まれます。
近年の大規模言語モデル(LLM)の発展に伴い、この手間のかかるワークフローを自動化する自律的なデータサイエンスエージェントの研究が進んでいます。これらのエージェントは、自然言語で与えられた質問を、回答を生成するための実行可能なコードに直接変換することを目指しています。
しかし、既存のデータサイエンスエージェントには、実用性を制限するいくつかの主要な課題がありました。
1. 異種データ形式への対応不足: 従来の多くのエージェントは、CSVファイルなどの構造化データ、つまりリレーショナルデータベース形式に主眼を置いています。この狭い範囲の焦点は、現実世界で豊富に存在する、JSON、Markdown、非構造化テキストなどの多様な異種データ形式に含まれる情報源を無視してしまうという課題を抱えています。
2. 分析計画の検証の困難さ: 多くのデータサイエンスのタスクは、正解ラベル(Ground-truth labels)が存在しない「オープンエンドな質問」として扱われるため、エージェントが導き出した推論経路や分析計画の正しさを検証することが非常に難しいという本質的な課題があります。例えば、多くのエージェントは、コードの実行が成功した時点でプロセスを終了しますが、実行可能なコードが必ずしも正しい答えを保証するわけではありません。この検証機能の不足が、エージェントがしばしば最適ではない計画を採用してしまう原因となります。
本稿で提案されているDS-STARは、これらの課題に対処するために導入された新しいデータサイエンスエージェントです。DS-STARは、堅牢で反復的な計画(Planning)と検証(Verification)のプロセスを通じて、解決コードを生成します。このフレームワークは二つの主要な段階で構成されています。
1. データファイル分析: 多様なデータタイプに適応するため、与えられたディレクトリ内のすべてのファイルを自動で分析し、その構造と内容のテキスト要約を生成します。
2. コアな反復ループ: 計画、実装、検証という反復的なループに入ります。特に検証においては、LLMをJudge(判定者)として使用し、現在の計画が問題を解決するのに「十分(sufficient)」であるかを明示的に評価します。検証に失敗した場合、DS-STARはステップを追加または修正して計画を洗練し、プロセスを繰り返します。
DS-STARは、一度に完全な計画を作成するのではなく、中間結果を確認しながら次のステップを構築する逐次的なアプローチを採用しており、これは専門家がJupyter Notebookを使用して中間結果を観察し、それに基づいて次の行動を決定するインタラクティブなプロセスを反映しています。
2. Related work (関連研究)
DS-STARの技術的背景と位置づけを理解するために、関連する既存研究の分野を解説します。
2.1. LLM agents (LLMエージェント)
LLMの急速な進歩は、複雑で長期間にわたるタスクに取り組む自律エージェント(Autonomous Agents)の重要な研究を促進しました。これらのマルチエージェントシステムが採用する主要な戦略は、中心的な目的を、個々のサブエージェントに委任できる小さく管理しやすい一連のサブタスクに自律的に分解することです。
汎用的なエージェントには、ReAct(推論と行動を組み合わせる)、HuggingGPT、およびOpenHands などがあり、これらは外部ツールを活用して幅広い問題に対して推論、計画、および行動を行います。
また、特定の専門領域に焦点を当てたエージェントも存在します。例えば、Voyager はMinecraft環境のナビゲーション、AlphaCode は高度なコード生成を目的としています。さらに、DS-Agent、AIDE、MLE-STAR は機械学習エンジニアリング向けに特化して設計されています。DS-STARは、これらの流れを汲む、データサイエンスタスクに特化したLLMエージェントとして位置づけられます。
2.2. Data science agents (データサイエンスエージェント)
近年の研究は、LLMの持つ高度なコーディング能力と推論能力を最大限に活用するデータサイエンスエージェントの開発に焦点を当てています。
初期の取り組みでは、ReAct や AutoGen のような汎用フレームワークが利用されましたが、その後、データ分析や可視化などのタスクに対して、コードベースのソリューションを自律的に生成することに特化したDA-Agent などが開発されました。
Data Interpreter のようなエージェントは、グラフベースの手法で主要なタスクをサブタスクに分解し、サブタスクの実行が成功したかどうかのフィードバックに基づいてタスクグラフを段階的に洗練させます。
しかし、これらのエージェントは、コードの実行成功に頼るのみで計画の正しさを確認できないため、しばしば最適ではない計画が生じるという主要な限界があります。DS-STARは、この限界に対処するために、LLMを判定者として利用する(LLM-as-a-judge)新しい検証プロセスを導入し、生成されたソリューションの品質を評価します。
2.3. Text-to-SQL (Text-to-SQL)
Text-to-SQLは、自然言語の質問を実行可能なSQLクエリに変換するタスクです。
LLMが登場する以前の初期アプローチは、ユーザーのクエリとデータベースのスキーマを共同でエンコードするSequence-to-Sequence(Seq2Seq)アーキテクチャに依存していました。LLMの台頭後、プロンプトエンジニアリングを経て、スキーマリンク、自己修正、自己一貫性などのテクニックを組み込んだ、より洗練されたマルチステップパイプラインが開発されました。
これらのパイプラインはデータ分析のための特殊なエージェントとして機能しますが、その基本的な依存先がSQLの生成であるため、使用範囲は構造化されたリレーショナルデータベース(RDB)に限定されてしまいます。 DS-STARは、この制限を克服するため、Python言語を採用し、アプローチをText-to-Pythonタスクとして捉えています。さらに、DS-STARは独自のデータファイル要約メカニズムを導入することで、JSON、Markdown、非構造化テキストなど、幅広いデータ形式で動作することが可能となり、従来のText-to-SQLシステムよりもはるかに広い適用可能性を示すことができます。
3. DS-STAR(DS-STAR)
DS-STARは複数の専門LLMエージェント \({A_i}_{i=1}^n\) から構成されており、主に「データファイル分析(Data Files Analysis)」と「反復的な計画生成と検証(Iterative Plan Generation and Vertification)」の2段階で動作します。
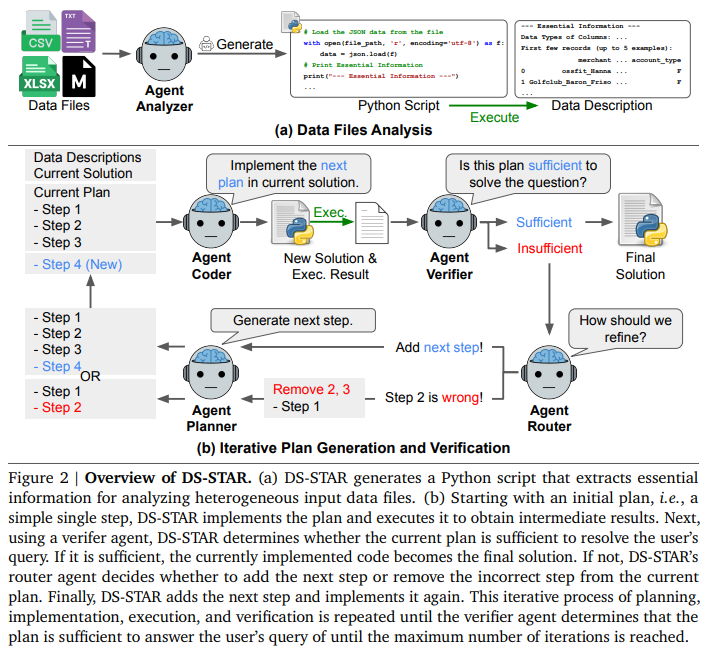
3.1. Analyzing data files(データファイル分析)
エージェントが次の行動を効果的に決定するためには、与えられたデータファイルの内容と構造を包括的に理解する必要があります。
従来のフレームワークはCSVのような構造化データのサンプル表示に頼っていましたが、DS-STARはAnalyzer Agent \(A_{analyzer}\) を導入し、より一般的なメカニズムを採用しています。
- 処理: 各データファイル \(D_i\) に対して、\(A_{analyzer}\) は、ファイルを正しくパースしてロードし、本質的なプロパティを抽出するためのPythonスクリプト \(s_{i}^{desc}\) を生成します。
- 抽出情報: 構造化データ(CSVなど)の場合は列名とデータ型、非構造化データの場合はファイルメタデータやテキストの要約などが抽出されます。
- コンテキスト生成: このスクリプトを実行することで、分析的な記述 \(d_i\) が得られます((d_i = \mathrm{exec}(s_{i}^{desc})))。この記述 \({d_i}_{i=1}^N\) は、タスクに取り組むための重要なコンテキストとして利用されます。
3.2. Iterative plan generation and verification(反復的な計画生成と検証)
データ記述が得られた後、DS-STARは計画、実装、検証を繰り返すコアなループに入ります。
Initialization(初期化)
Planner Agent \(A_{planner}\) が、クエリ \(q\) とデータ記述 \({d_i}{i=1}^N\) を基に、実行可能な最初の高水準ステップ \(p_0\) (例:データファイルのロード)を生成します。 次に、Coder Agent \(A{coder}\) が \(p_0\) をコードスクリプト \(s_0\) として実装し、実行結果 \(r_0\) が得られます。初期計画 \(p\) は \({p_0}\) となります。
Plan verification(計画検証)
DS-STARの核となるのは、計画の妥当性を評価する検証メカニズムです。
- Verifier Agent (\(A_{verifier}\)) の役割: LLMをJudgeとして使用する Verifier Agent \(A_{verifier}\) は、現在の累積計画 \(p\)、クエリ \(q\)、累積計画の実装コード \(s_k\)、およびその実行結果 \(r_k\) に基づいて、計画が問題を解決するのに「十分(sufficient)」か「不十分(insufficient)」かを評価します。
- 実行結果の利用: 単に計画とクエリを比較するのではなく、実行結果 \(r_k\) を考慮に入れることで、コードが計画通りに実装されているか、また \(r_k\) がクエリに完全に答えるために必要な情報を含んでいるかを評価し、より根拠に基づいたフィードバックが可能となります。
Plan refinement(計画洗練)
Verifier Agentが計画を「不十分」と判断した場合、Router Agent \(A_{router}\) が次の行動を決定します。
- Router Agent (\(A_{router}\)) の決定: \(A_{router}\) は、現在の計画 \(p\)、クエリ \(q\)、実行結果 \(r_k\)、データ記述 \({d_i}_{i=1}^N\) を入力として受け取り、次の行動 \(w\) を決定します。
- \(w = \text{Add Step}\):計画は正しいが未完了であると判断し、次のステップの追加を決定します。
- \(w = l\) (インデックス):計画の \(l\) 番目のステップ \(p_l\) が誤っていると判断し、計画を \(p \leftarrow {p_0, \cdots, p_{l-1}}\) に切り詰めて(バックトラックして)再生成を促します。これは、誤ったステップの上にさらにステップを積み重ねる(エラー蓄積)ことを防ぐためです。
- 次のステップの生成: Router Agentの決定に基づき、Planner Agent \(A_{planner}\) は、最後の実行結果 \(r_k\) を条件として考慮に入れ、計画の不足点や誤りを解消しようとする次のステップ \(p_{k’+1}\) を生成します。
- 反復実行: 新しい計画 \(p\) を基に Coder Agent \(A_{coder}\) がコード \(s\) を実装し、実行((r = \mathrm{exec}(s)))され、再び Verifier Agent \(A_{verifier}\) による検証が行われます。このプロセスは、計画が「十分」と判断されるか、最大反復回数に達するまで繰り返されます。
3.3. Additional modules for robust data science agents(堅牢なデータサイエンスエージェントのための追加モジュール)
Debugging agent(デバッグエージェント)
Pythonスクリプトが実行エラーを起こした場合、トレースバック \(T_{bug}\) が生成されます。Debugger Agent \(A_{debugger}\) は、このエラーを自動で修正します。
- デバッグへのデータコンテキスト利用: \(A_{debugger}\) は、エラーのトレースバック \(T_{bug}\) だけに頼るのではなく、データファイル分析によって得られたデータコンテキスト \({d_i}_{i=1}^N\) (CSVの列ヘッダーなど)を積極的に利用してスクリプト \(s\) を修正済みの \(s’\) に更新します。この豊富なデータコンテキストが、データに依存するエラーの解決に不可欠であるという洞察に基づいています。
Retriever(リトリーバー)
データファイル数 \(N\) が多い場合(例: \(N > 100\))、全てのデータ記述をLLMのコンテキスト長(一度にLLMに与えられるテキストの長さの制限)内に含めることができないというスケーラビリティの課題があります。
- 仕組み: この問題を解決するため、DS-STARはリトリーバルメカニズムを使用します。ユーザーのクエリ \(q\) の埋め込み(Embedding)と、各データ記述 \(d_i\) の埋め込みの間のコサイン類似度を計算し、最も関連性の高い上位 \(K\) 個のデータファイルを特定します。
- コンテキスト提供: この上位 \(K\) 個の関連ファイルのみが、LLMにコンテキストとして提供され、大規模なデータレイク環境においても効率的な処理を可能にします。
4. Experiments(実験)
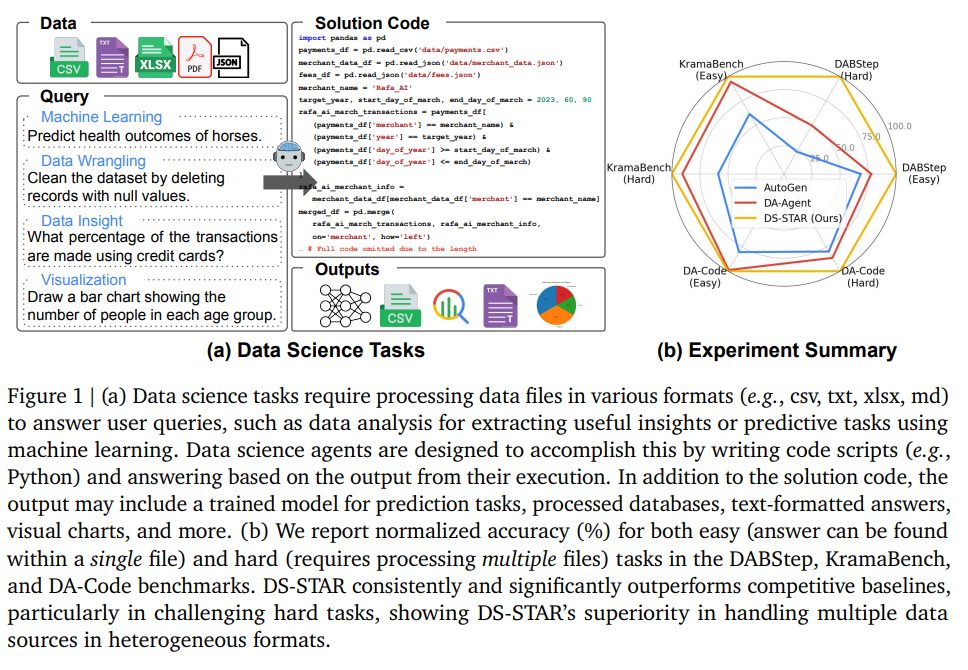
DS-STARは、DABStep、KramaBench、DA-Codeという、複数のデータソースや形式、複雑な分析タスク(データラングリング、機械学習、可視化など)を含む挑戦的なベンチマークで評価されました。
4.1. Main results(主要な結果)
DS-STARは、既存の最先端手法と比較して、すべての評価シナリオで顕著な性能向上を示しました。(Table 1参照)
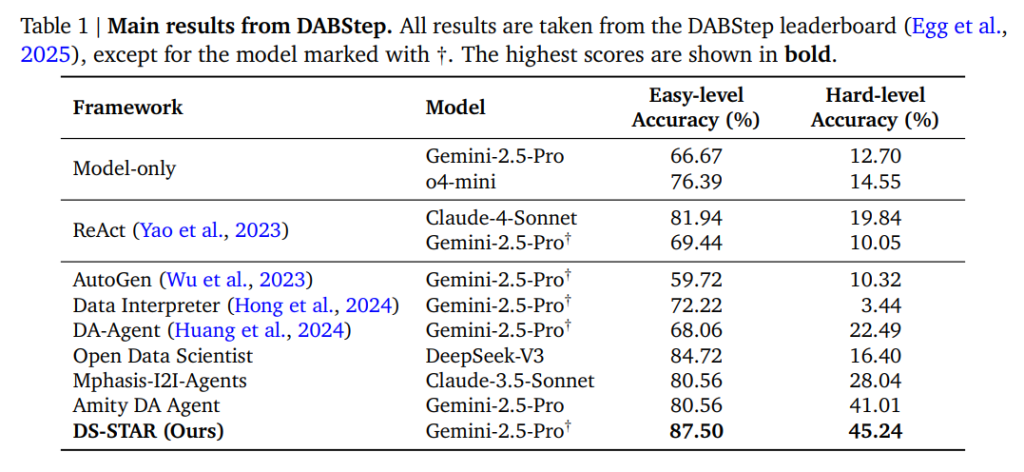
DABStepベンチマーク
DABStepベンチマークは、現実世界のデータ分析の課題を反映するように設計されており、JSON、Markdown、CSVなど7つの多様なデータファイルのセットの処理を要求します。タスクの難易度は高く、全450タスクのうち378タスクが「Hard-level」に分類されています。
- 性能向上: DS-STARは、すべてのベースラインに対して、顕著な性能向上を示しました。
- Hard-level精度: ベースLLMとしてGemini-2.5-Proを使用した場合、DS-STARのHard-levelタスクの精度は45.24%に達しました。これは、単一LLMアプローチ(Model-only, Gemini-2.5-Pro)の12.70%から、絶対値で32パーセンテージポイント以上の大幅な改善に相当します。
- 他のエージェントとの比較: DS-STARは、同じLLM(Gemini-2.5-Pro)上に構築された他のマルチエージェントシステム(例: DA-Agent)を大幅に上回っており、この性能向上は、提案された効果的なサブエージェントの連携、特に反復計画と検証メカニズムに由来することが強調されています。
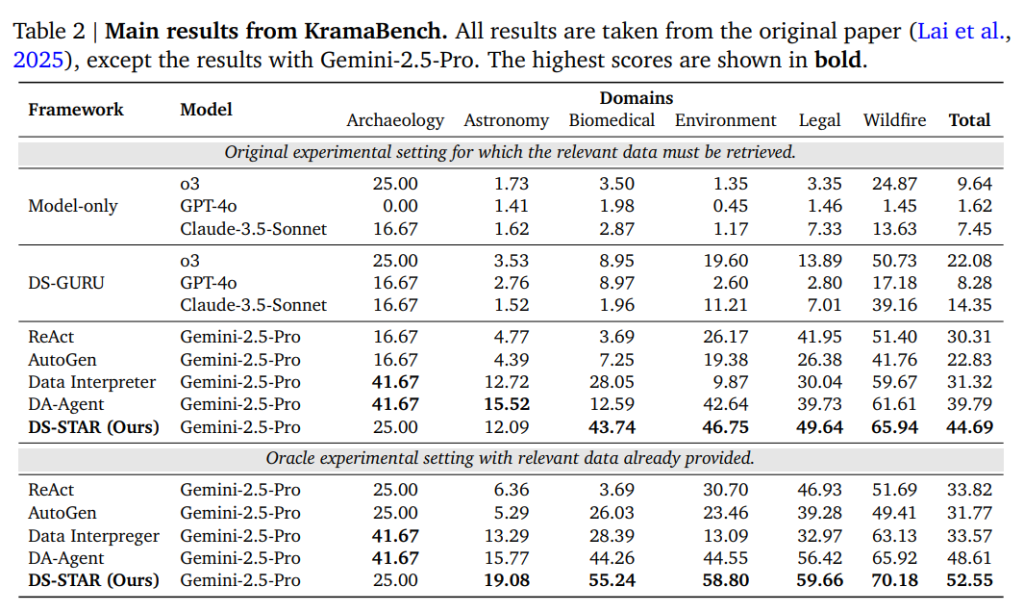
KramaBenchベンチマーク
KramaBenchは、データサイエンスエージェントのデータ発見(Data Discovery)能力を検証することを目的としています。このベンチマークは、エージェントが、数多くのデータファイル(例: Astronomyドメインでは1,500ファイル超)の中から、クエリに関連するデータファイルを選び出す能力を必要とします。
- SOTA性能: DS-STAR(Gemini-2.5-Pro使用)は、データリトリーバル(検索)モジュールを統合した設定において、総合精度44.69%を達成し、最先端であったDA-Agentの39.79%を大きく上回りました。
- Oracle設定での検証: 関連するデータがすべて事前に提供される理想的な「Oracle設定」で評価したところ、DS-STARの精度は52.55%に上昇しました。他のエージェントがOracle設定でわずかな改善しか示さなかったのに対し、DS-STARの性能が8パーセンテージポイント以上向上したことは、DS-STARの計画検証機構が、適切なデータが与えられた場合に最大限に機能する、強力なタスク解決能力を持つことを裏付けています。
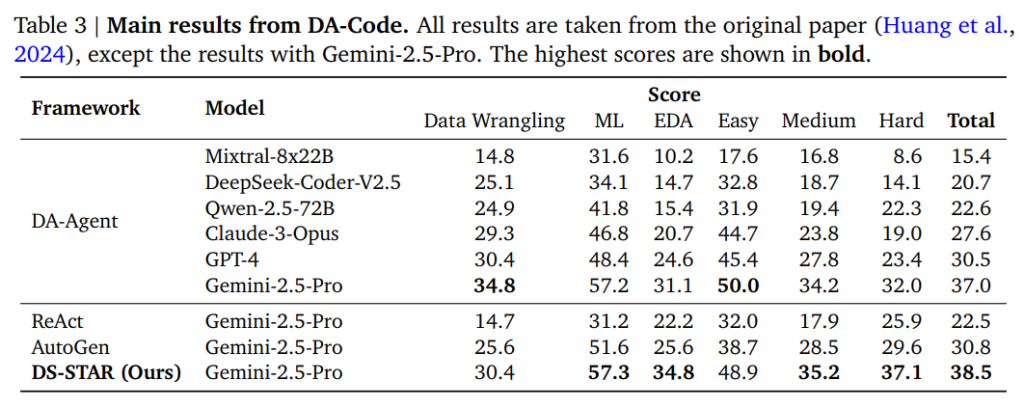
DA-Codeベンチマーク
DA-Codeベンチマークは、DS-STARの汎化能力を評価するために使用され、データラングリング(Data Wrangling)、機械学習(ML: Machine Learning)、探索的データ分析(EDA: Exploratory Data Analysis)など、多様なデータサイエンスタスクで構成されています。
- 総合精度: DS-STARは、総合精度において38.5%を達成し、最強のベースラインであるDA-Agent(37.0%)を上回りました。
- Hard-levelタスクでの性能: 複雑な問題に特化したHard-levelタスクでは、DS-STARは37.1%の精度を達成し、DA-Agentの32.0%を大きく凌駕しました。
- 多様なタスクへの適用性: この結果は、DS-STARのフレームワークが、複雑なデータ処理や機械学習タスクなど、様々なデータサイエンスの領域において、同じベースLLMを使用する競合と比較して、より堅牢で効果的であることを示しています。
4.2. Ablation studies(アブレーションスタディ)
フレームワークの主要な構成要素であるデータファイル分析エージェント \(A_{analyzer}\) とルーターエージェント \(A_{router}\) の有効性について検証されました。
- データファイル分析エージェントの有効性: データ記述(\(A_{analyzer}\) の出力)を除去した場合、DABStep Hard-levelタスクの精度は45.24%から26.98%に大幅に低下しました。この結果は、LLMが効果的に推論し計画を立てるために、入力データの豊富なコンテキスト情報が極めて重要であることを裏付けています。

- ルーターエージェントの有効性: Router Agent \(A_{router}\) を除去し、誤ったステップがあっても次のステップを追加し続ける(エラーを修正しない)バリアントと比較したところ、\(A_{router}\) を用いない場合は精度が悪化しました。これは、計画に誤りが生じた際にルーターがそれを特定し、適切な修正(バックトラック)を指示することが、エラーの累積を防ぎ、結果として性能向上に不可欠であることを示しています。
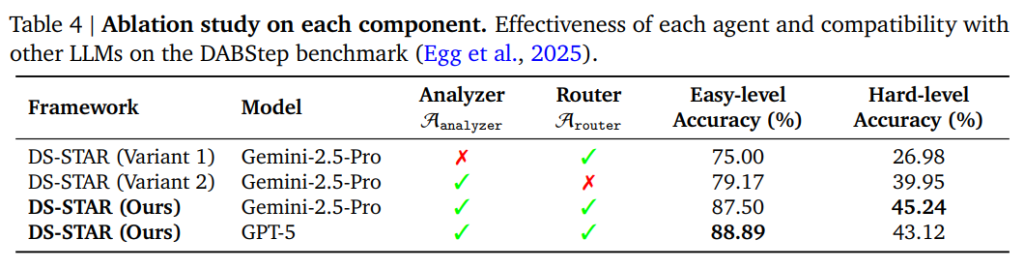
- 他のLLMとの互換性: DS-STARは、ベースLLMとしてGPT-5を使用した場合でも高い性能を示し、フレームワークの汎用性が確認されました。
4.3. Analysis(分析)
計画の反復洗練回数について分析されました。
- タスク難易度と反復回数: 難易度の高いタスク(Hard tasks)ほど、十分な計画を生成するためにより多くの反復回数が必要であることがわかりました。DABStepにおいて、Hardタスクは平均5.6回の反復を要したのに対し、Easyタスクは平均3.0回でした。
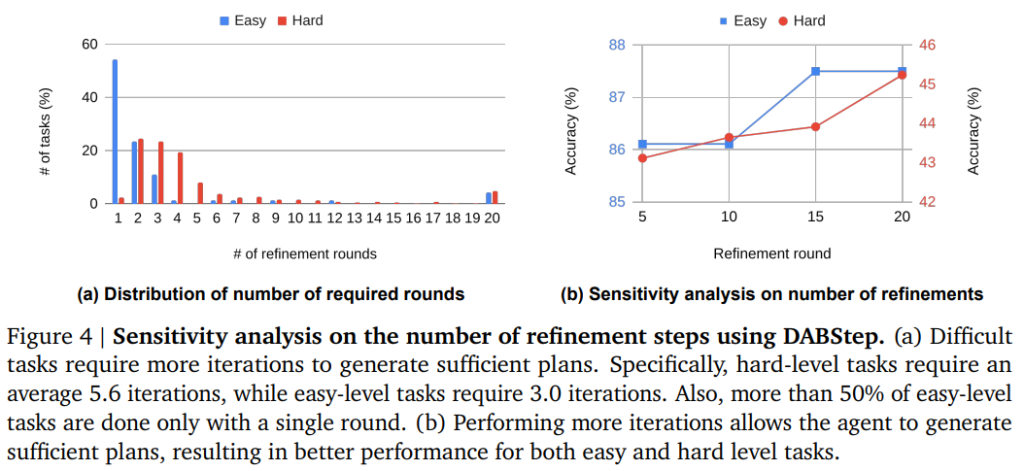
- 反復回数の感度分析: 最大反復回数(デフォルトは20回)を増やすと、Hardタスクの精度は一貫して向上しました。これは、複雑な問題に対しては、より多くの洗練ステップを実行する機会を与えることが、より十分な計画の生成につながり、性能を向上させることを証明しています。
5. Conclusion(結論)
データサイエンスの問題を自律的に解決するために設計された新しいエージェント「DS-STAR」を紹介しました。
アプローチには2つの主要な要素があります。(1) 多様なデータ形式(heterogeneous data formats)を扱うためのファイルの自動分析、および (2) 新しいLLMベースの検証メカニズムによって反復的に洗練される、逐次的な計画(プラン)の生成です。
DABStep、Kramabench、DA-Code(いずれもベンチマーク名)においてDS-STARの有効性を示し、従来の手法を凌駕することで新たな最先端技術(state-of-the-art)を確立しました。
限界と今後の展望
現在の研究は、DS-STARの完全自動化フレームワークに焦点を当てています。今後の研究における魅力的な方向性は、このフレームワークを「ヒューマン・イン・ザ・ループ(human-in-the-loop、人間が介在する)」設定へと拡張することです。
DS-STARの自動化能力と、人間の専門家が持つ直感やドメイン知識(専門知識)を、どのように相乗効果(シナジー)で組み合わせるかを研究することは、パフォーマンスを大幅に向上させ、システムの実用性を高めるための有望な方向性を示しています。
まとめ
本稿では、異種データ形式への対応と、LLMベースの検証による堅牢な反復計画メカニズムを特徴とする新しいデータサイエンスエージェント、DS-STARについて解説いたしました。
DS-STARは、従来のLLMベースのエージェントが抱えていた、構造化データへの依存や、オープンエンドなタスクにおける計画の妥当性検証の難しさを効果的に克服しています。LLMを「Judge」として活用し、計画の「十分性」を評価させるという独自のアプローチと、データファイル分析モジュールの組み合わせにより、現実世界の複雑なデータ分析タスクに対して高い堅牢性と精度を確立しました。
本研究の今後の展望としては、DS-STARの完全自動化されたフレームワークをさらに発展させ、「Human-in-the-loop」(人間の専門家がプロセスに介入する形態)の環境を調査し、自動化された能力と人間の直感やドメイン知識を相乗的に組み合わせることで、さらなる性能向上と実用性の強化を目指す方向性が示唆されています。








