
はじめに
近年、大規模言語モデル(LLM)の進化は目覚ましく、私たちの生活や仕事に大きな変化をもたらしています。ChatGPTのようなLLMは、大量のデータを使って学習することで、非常に自然な文章を生成したり、複雑なタスクをこなしたりできるようになりました。
しかし、この発展の裏には、重要な課題が潜んでいます。それは、LLMの学習に使われる「トレーニングデータ」に関する問題です。特に、著作権で保護されたコンテンツが無許可で使用されているのではないか、という懸念が高まっています。これは、クリエイターの権利に関わるだけでなく、AI企業に対する訴訟リスクにもつながりかねません。例えば、New York TimesとOpenAIの間の訴訟などが報じられています。
トレーニングデータは、企業の競争戦略上、通常は非公開とされています。そのため、ある特定の著作物(例えば、書籍や記事など)がLLMの学習に使われたかどうかを確認することは非常に困難です。
本記事で解説する論文「DE-COP: Detecting Copyrighted Content in Language Models Training Data」は、この難しい課題に挑むための新しい検出手法「DE-COP」を提案しています。トレーニングデータが非公開の「ブラックボックスモデル」に対しても有効な手法として注目されています。
引用元記事
- タイトル: DE-COP: Detecting Copyrighted Content in Language Models Training Data
- 発行元: INESC-ID, University of California, Carnegie Mellon University
- 発行日: 2024年2月15日
- URL: https://arxiv.org/pdf/2402.09910
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- DE-COP手法の提案: 大規模言語モデルのトレーニングデータに含まれる可能性のある著作権付きコンテンツを検出するための新しい手法「DE-COP」を提案している。
- MCQAに基づくアプローチ: DE-COPは、LLMに多肢選択式の質問を投げかけ、元の文章(verbatim text)と複数の言い換え(paraphrase)の中から、元の文章を識別できるか否かをテストするというシンプルなアイデアに基づいている。モデルがトレーニング中にその文章に触れていれば、より高い精度で元の文章を識別できるはず、という直感を利用している。
- ブラックボックスモデルへの適用可能: 既存の多くの検出手法がモデルの内部情報(トークン確率など)へのアクセスを必要とするのに対し、DE-COPは完全に中身が見えない「ブラックボックスモデル」(例: ChatGPT, Claude)に対しても適用できるという大きな利点があります。
- 新しいベンチマークの作成: 本研究のために、書籍の文章を集めた「BookTection」と、研究論文の文章を集めた「arXivTection」という2つの新しい評価用ベンチマークを作成しています。
- 高い検出性能: 実験の結果、DE-COPは様々なモデルにおいて著作権の可能性のある書籍を効果的に検出できることを示しました。トークン確率にアクセスできるモデルでは、既存の最良手法と比較して検出性能(AUC)が9.6%向上しました。また、ブラックボックスモデルでは、既存手法が約4%の精度だったのに対し、DE-COPは平均72%という高い精度を達成しています。
- 人間の性能との比較: 人間が同じ検出タスクを行った実験では、モデルほど正確に元の文章を識別できませんでした。このことは、モデルの高い精度が単なる偶然ではなく、トレーニングデータに触れたことによるものであるという仮説を裏付けています。
詳細解説
1. はじめに (Introduction)
LLMの急速な発展は、大量のデータを活用することで実現されています。しかし、そのデータを収集する過程で、倫理的・法的な基準を満たすことが難しくなってきています。特に、個人情報や財務情報、そして著作権で保護されたコンテンツの保護が課題となっています。
不適切なデータ収集は、著作権者の許諾なくコンテンツがモデルの知識に取り込まれる事態を招き、知的財産権を侵害する可能性があります。これにより、AI企業の評判が傷つくだけでなく、AI開発に対する一般の人々の見方にも悪影響を与えかねません。実際に、New York TimesとOpenAIの訴訟や、Stable Diffusionなどに対する集団訴訟などが起きています。
LLMのトレーニングデータに含まれる著作権付きコンテンツを検出することは、AI製品をより民主的にし、モデル所有者が著作権の法的要件を遵守し、コンテンツ著者に適切な補償を行うためにも非常に重要です。しかし、前述の通り、企業のトレーニングデータは競争上の理由から非公開であることが多く、特定のコンテンツが使用されたかどうかを確かめることは困難です。
本論文は、このような背景から、トレーニングデータが非公開のLLMに対しても適用できる、著作権付きコンテンツ検出手法であるDE-COPを提案しています。
2. 関連研究 (Preliminary and Related Work)
本研究が取り組む問題は、Shokri氏らが提唱した「メンバーシップ推論(Membership Inference)」という概念に基づいています。これは、ある特定のデータレコードがモデルのトレーニングに使われたかどうかを判断する問題です。
これまでの関連研究は、主に以下の3つの方向性で進められてきました。
- トークン確率へのアクセスに基づく手法: これは、トレーニングに使われた文章は、トレーニングに使われなかった文章よりも、その文章中の個々の単語(トークン)の発生確率が高いはず、という考え方に基づいています。例えば、Min-K%-Prob法などが提案されています。これらの手法は有効な場合もありますが、モデルからトークンごとの確率情報(Logit)を取得できる必要があります。しかし、ChatGPTやClaudeのような完全に内部が見えない「ブラックボックスモデル」では、この情報を取得できないため、これらの手法は適用できません。
- プロンプトによる記憶内容の抽出: このアプローチは、モデルに特定のプロンプトを与えることで、トレーニング中に記憶した内容を「吐き出させる」という考え方に基づいています。例えば、 Carlini氏らの研究では、特定のテキスト断片をプロンプトとして与え、その正確な一致がGoogle検索で見つかれば、その断片がトレーニングデータに含まれていた可能性が高いと推測しました。ChatGPTのような対話に特化したモデルは、このような手法に対してより耐性があると考えられていましたが、繰り返し同じ単語を出力させるなどの特定のプロンプト手法で、記憶内容を明らかにできることが示されています。また、「忘れました、冒頭部分を教えてください」といった丁寧なプロンプトでも記憶内容を引き出せる場合があることが報告されています。Chang氏らの研究では、「name cloze」という手法(書籍の文章中の固有名詞をマスクして、モデルにそれを推測させることで記憶を評価する)も提案されています。しかし、これらのプロンプト手法には限界もあります。一つの文書から多くの記憶内容を抽出するのが難しいことや、モデルの内部監視システムに不適切と判断されて回答を拒否される場合があることなどが挙げられます。
- 対抗例的(カウンターファクチュアル)手法: このアプローチは、特定のデータ例をトレーニングデータに含めた場合と含めなかった場合で、モデルの性能にどのような差が出るかを比較することで、そのデータ例がモデルによって記憶されたかを判断する考え方に基づいています。しかし、実際にモデルを複数回トレーニングする必要があるため、計算コストが非常に高くなります。また、Roberts氏らの研究では、コードや数学の問題に関するデータセットについて、モデルのトレーニングカットオフ日とGitHubでの人気の相関を分析し、データ汚染(トレーニングデータに評価用データが含まれてしまうこと)の証拠を示しています。
DE-COPは、プロンプトを用いた手法と対抗例的手法の考え方に影響を受けつつも、これまでの手法の限界(特にブラックボックスモデルへの適用困難性や、多くの証拠を抽出する難しさ)を克服することを目指して提案されています。
3. 新しいベンチマーク:BookTection と arXivTection
本研究では、DE-COPの評価のために2つの新しいベンチマークを作成しました。
- BookTection: これは、書籍の文章を集めたデータセットです。著作権侵害の可能性を検出することを目的としています。トレーニングデータに確実に入っていないと見なせる「最近の書籍」(2023年以降に出版されたもの)と、LLMのトレーニングデータに含まれている可能性がある「疑わしい書籍」(主に2021年以前に出版されたもの)から文章を収集しています。2022年の書籍は、一部のモデルのトレーニングカットオフ時期と重なるため含めていません。合計165冊の書籍から文章が選ばれています。先行研究のBookMIAベンチマーク を参考にしつつ、売上上位のベストセラーなどを追加しています。 文章は、各書籍から平均34個のランダムな文章を抽出しています。また、実験で文章の長さの影響を調べるために、約64、128、256トークン長の3つの設定でデータセットを公開しています。各オリジナルの文章には、Claude 2.0を用いて作成された3つの言い換え(paraphrase)が付随しています。Claude 2.0を用いたparaphrase生成プロンプトは付録に記載されています。
- arXivTection: これは、arXivに公開されている研究論文の文章を集めたデータセットです。arXiv論文は、通常LLMのトレーニングデータに含まれることが多いため、DE-COP手法の妥当性を確認するための「概念実証(proof-of-validity)」データセットとして使用されました。2023年以降に出版された論文と、2022年以前の論文から、それぞれ半数ずつ(合計50本)の論文が選ばれています。約128トークン長の文章を抽出しています。
4. 提案手法:DE-COP
提案手法DE-COPは、カウンターファクチュアル memorization の研究に影響を受けています。その核心は、多肢選択式の質問応答(MCQA)タスクにおけるモデルの性能を観察することで、特定の文章がトレーニングデータに含まれているかを判断するという点です。タスクは、与えられた複数の選択肢(元の文章と3つの言い換え)の中から、正しい元の文章を識別するというものです。
モデルがトレーニング中にその文章に触れた場合、トレーニングに使われなかった場合と比較して、元の文章を正しく選択する頻度が大幅に高くなる、という前提に基づいています。Figure 2にDE-COPの全体的な流れが示されています。
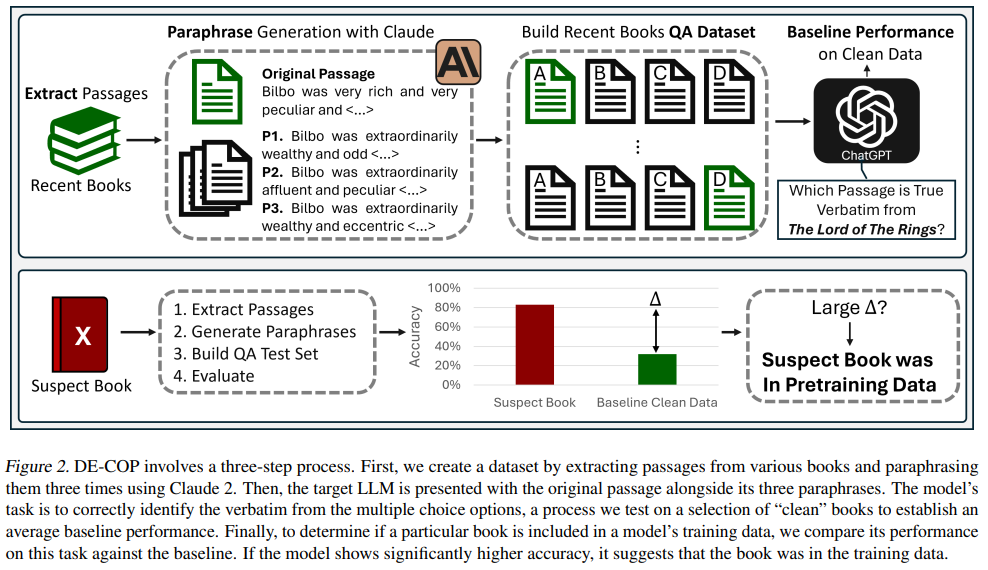
まず、トレーニングデータに含まれていないことが確実な「きれいな」書籍(例えば、2023年以降に出版されたもの)から多数の文章を収集します。それぞれの文章について、AIモデル(本研究ではClaude 2)を用いて3つの言い換えを作成します。そして、元の文章と3つの言い換えを組み合わせ、4つの選択肢を持つ多肢選択問題を作成します。
この際、モデルが特定の選択肢の位置(例: A, B, C, D)を選びやすい「選択バイアス」という現象(付録Dに例が示されています)に対処するため、元の文章と3つの言い換えの全ての組み合わせ(4!=24通り)で問題を作成します。全ての並び替えを試すことで、選択バイアスの影響を軽減し、モデルの知識をより頑健に推定することを目指しています。たとえ選択バイアスによっていくつかの並び替えで間違った回答をしたとしても、文章が本当に記憶されていれば、大多数の並び替えでは正しく回答できるはず、という考え方です。
本研究では、トレーニングデータに含まれていないと確実な「きれいな」文章を使って、各モデルの「ベースライン性能」(つまり、トレーニングで見たことのない文章に対して期待される平均的な性能)を推定します。次に、調査したい「疑わしい」書籍に対しても同じプロセスを適用し、その性能をベースラインと比較します。もし「疑わしい」書籍に対するモデルの正解率がベースラインよりも大幅に高ければ、その書籍はトレーニングデータに含まれていた可能性が高いと判断します。
4.1 モデルの脱バイアス – Logit Calibration
DE-COPは、完全に中身が見えないブラックボックスモデルでも使用できるように設計されていますが、オープンソースモデルのように個々のトークンの確率情報(logit)にアクセスできるモデルに対しては、さらに性能を向上させるための工夫として「Logit Calibration」を適用できます。
これは、前述の「選択バイアス」をさらに軽減することを目的としています。Logit Calibrationでは、まずトレーニングに使われていない別の「きれいな」書籍のサブセット(約30冊)を用意します。理論的には、これらの書籍はモデルが見たことがないため、特定の選択肢(A, B, C, D)を他の選択肢よりも選ぶ理由はなく、各選択肢に割り当てられる確率分布はほぼ均一になるはずです。しかし、実際の分析では特定の選択肢に偏りが見られます。
そこで、その偏りを補正するために、各選択肢の確率にどの程度調整が必要かを計算します。Figure 3に示されているように、観察された平均確率と、均一であるべき理論上の確率(4つの選択肢なら0.25)との差を計算し、それを調整値とします。新しい文章に対して予測を行う際に、モデルが出力した各選択肢の確率をこの調整値で補正してから、最終的な回答を決定します。これにより、選択バイアスの影響を抑え、より正確な判断が可能になります。付録EにCalibrationアルゴリズムと実際の例が示されています。

5. 実験 (Experiments)
DE-COPの有効性を評価するために、様々な実験が行われました。主な実験の目的は以下の通りです:
- 文章の長さが検出性能に影響するか?
- モデルサイズが大きいほどDE-COPは効果的か?
- Logit Calibrationは有効か?
- Paraphraseを生成するモデルが、評価を行うモデルの性能に影響を与えるか?
- 疑わしい書籍と新しい書籍のparaphraseの品質は同等か?(人間による評価)
実験は、Mistral, Mixtral, LLaMA-2, GPT-3, ChatGPT, Claudeといった多様なモデルを用いて行われました。
5.1. 実験設定 (Experiment Setup)
実験では、統計的なアプローチでDE-COPの性能を評価しました。まず、「疑わしい」書籍のグループ(S)と「きれいな」書籍のグループ(C)を用意します。各書籍について、DE-COPの手順に従ってモデルに多肢選択質問を投げかけ、正解率を計算します。例えば、1冊の書籍から30の文章を抽出し、それぞれについて24通りの並び替えを試した場合、合計で720回のモデル応答を得て、その正解率を算出します。
次に、サンプリング(繰り返しサンプリング)を10回行い、各イテレーションでそれぞれのグループからM冊の書籍をサンプリングします。各イテレーションで、2つのグループ(疑わしいグループとクリーンなグループ)を最もよく分離できる閾値を決定し、AUC(Area Under the Curve)を計算します。AUCは検出性能の指標で、値が大きいほど性能が高いことを示します。また、疑わしいグループの平均精度も記録します。
最後に、サンプリング結果に基づいて、疑わしいグループとクリーンなグループの平均値間に統計的に有意な差があるかを確認するためにt検定を行い、p-valueを報告します。p-valueが小さいほど、「両グループの平均に差がない」という帰無仮説を棄却する根拠が強い、つまり検出性能が高いことを示します。
ベンチマークとベースライン:
実験では、まず概念実証としてarXivTectionデータセットを使用し、その後主要な評価としてBookTectionデータセットを使用しました。
比較対象として、既存のベースライン手法も評価しました。ベースラインは、モデルがトークン確率にアクセスできるか否かで分けて考慮されました。
- トークン確率にアクセスできるモデル向けベースライン: Perplexity, Zlib, Lowercase, Min-K%-Probなどが使用されました。
- ブラックボックスモデル向けベースライン: Prefix Probing(文章の冒頭部分を与えて、モデルがその後の部分をどれだけ正確に生成できるかを見る手法)と、Name Clozeタスクの修正版(文章中の固有名詞や名詞をマスクして、モデルに推測させる手法)が使用されました。Name Clozeは、特定の要件(固有名詞が1つだけ含まれるなど)を満たさない文章もあったため、本研究では修正版を使用しています。
実装 (Implementation):
実験では、Mistral, Mixtral, LLaMA-2, GPT-3, ChatGPT, Claudeといった複数のモデルが使用されました。
Paraphrase生成時には、多様な言い換えを生成するために温度(temperature)を0.1に設定しています。一方、評価時には、モデルの応答が決定論的になるように温度を0に設定しています。
実験は、高性能なGPUを備えた計算クラスタで行われ、効率的な実行を可能にしています。付録Hに、DE-COPとベースラインの実行時間分析が示されており、DE-COPが他の手法よりも時間を要することが示されています。これは、選択バイアス対策として全ての並び替えを試行するためです。
6. 結果 (Results)
論文の実験結果を見ていきましょう。
6.1. 概念実証 – arXiv
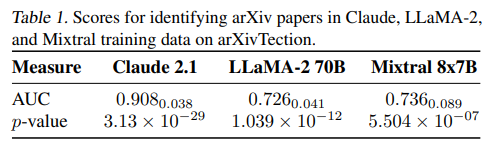
まず、DE-COPがarXiv論文の検出に有効かを確認する概念実証実験の結果です。Claude 2.1、LLaMA-2 70B、Mixtral 8x7Bの3つのモデルで評価が行われました。
Table 1に示されているように、3つのモデル全てで高いAUCスコアが得られており、特にClaude 2.1のスコアが高い結果となりました。これは、これらのモデルがトレーニングに使われた可能性のある古い論文と、新しい論文を効果的に区別できていることを示しています。低いp-valueも、この結論を強く支持しています。この結果は、DE-COP手法が書籍の検出にも信頼できる可能性を示唆しています。
6.2. 主な結果
次に、BookTectionベンチマークを用いた主要な実験結果です。
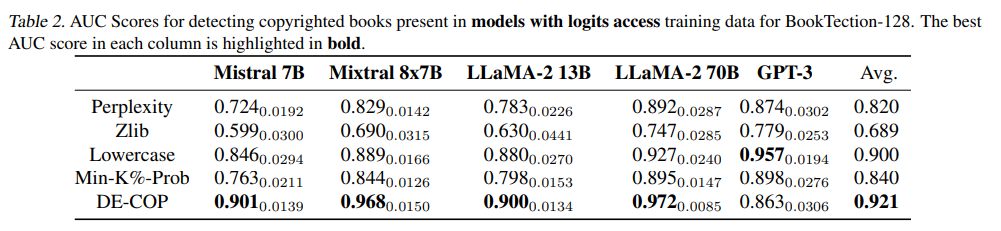
まず、トークン確率にアクセスできるモデル(例: LLaMA-2, Mistral, Mixtral, GPT-3の一部)に対する評価です。Table 2に示されているように、ほとんどのモデルにおいて、DE-COPがPerplexity, Zlib, Lowercase, Min-K%-Probといった既存の全てのベースライン手法を上回るAUCスコアを達成しました。特に、DE-COPは平均AUCスコア0.921を達成し、Min-K%-Probと比較して9.6%の向上を示しています。これは、DE-COPがこれらのモデルに対して非常に高い検出性能を持つことを示しています。付録Fに示されたp-valueも、DE-COPの優れた性能を統計的に支持しています。
次に、完全に中身が見えないブラックボックスモデル(ChatGPT, Claude 2.1)に対する評価です。Table 3に示されているのは、「疑わしい」書籍グループにおける平均精度です。Prefix ProbingやName Clozeといった既存のブラックボックスモデル向けベースライン手法は、低い精度(最大でも約35%)にとどまっています。これは、これらの手法が元の文章の正確な再現や特定の情報(固有名詞など)の推測に依存しており、ブラックボックスモデルでは難易度が高いタスクであるためと考えられます。特にPrefix Probingは、モデルがテキストを完全に記憶している場合に有効ですが、部分的な記憶では性能が出にくい傾向があります。
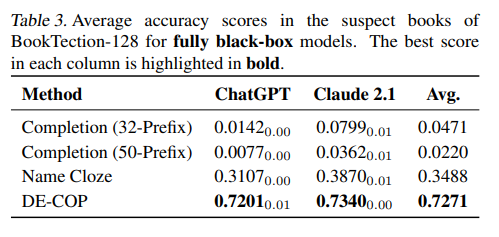
一方、DE-COPはChatGPTとClaude 2.1の両方で約72%という大幅に高い平均精度を達成しています。これは、DE-COPがトレーニングデータの検出において、ブラックボックスモデルに対しても非常に有効であることを強く示しています。
6.3. モデルサイズ
モデルサイズとDE-COPの性能の関係を、LLaMA-2モデル(7B, 13B, 70Bの3サイズ)を用いて調査しました。Figure 4を見ると、モデルサイズが大きいほどAUC性能が向上する傾向が見られます。これは、パラメータ数が多いモデルほど、より高度な推論能力を持ち、記憶容量も大きい可能性があるためと考えられます。
6.4. 文章の長さ
文章の長さがDE-COPの検出性能に与える影響を、LLaMA-2 70Bモデルを用いて調査しました。Figure 5に示されているように、DE-COPは短い文章(64トークン)と中程度の文章(128トークン)に対して他のベースラインを上回る性能を示しています。しかし、長い文章(256トークン)になると、全てのメソッドで性能が低下する傾向が見られました。特にDE-COPの性能低下が顕著であり、これはモデルのコンテキストサイズ(処理できる文章の長さの上限、LLaMA-2 70Bでは約1024トークン)が影響し、これ以上長い入力に対して正確な推論を行うのが難しくなるためと考えられます。
6.5. Logit Calibration
Logit Calibrationが検出性能に与える影響を、LLaMA-2 70BとChatGPTを用いて検証しました。Figure 6に示されているように、Logit Calibrationは有効であることが確認されました。新しい書籍(トレーニングに使われていない)に対する性能向上はわずかですが、「疑わしい」書籍に対する性能向上は大きく見られました。これは、Logit Calibrationによって、トレーニングデータに含まれている可能性が高い文章の検出精度を向上させられることを示唆しています。付録Gに、Calibrationが選択バイアスを軽減する追加の証拠が示されています。
6.6. Paraphrasingに用いるモデルファミリー
Paraphraseを生成する際に使用したモデルと、評価を行うモデルが同じである場合に性能が影響を受けるかを調査しました。本研究では通常Claude 2.0でParaphraseを生成していますが、ChatGPTで生成した場合のClaude 2.1の評価性能を比較しました。Table 4に示されているように、Paraphraseの生成元によってClaude 2.1のAUCスコアにわずかな差が見られました。ChatGPTが生成したParaphraseの場合、AUCが約7%低下しました。この結果は、モデルが自身が生成したコンテンツを識別するのが、他のモデルが生成したコンテンツを識別するよりもわずかに優れている可能性がある、という仮説を支持しています。
6.7. Paraphraseの品質
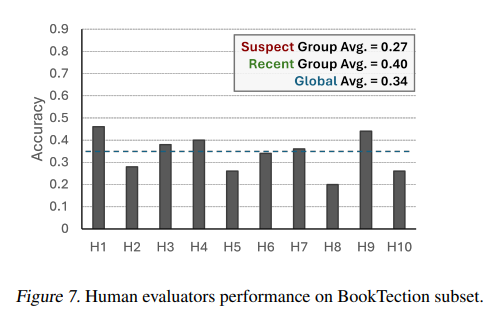
最後の実験では、作成されたParaphraseの品質が、「疑わしい」グループと「新しい」グループの間で同等であり、モデルの検出性能が単にParaphraseの品質の差によるものではないことを示すことを目的としました。このため、人間(10名)に、BookTectionのサブセット(各グループから25冊ずつ、合計50本の文章)を用いて同じMCQAタスク(元の文章を識別するタスク)を行ってもらいました。
Figure 7に示されている人間の評価結果を見ると、全体の平均正解率は約34%と、ランダムに回答した場合(4択なので25%)をわずかに上回る程度であり、人間が正確にタスクを行うのは難しいことが分かります。さらに、「疑わしい」グループと「新しい」グループで平均精度を比較すると、予想とは異なり、人間は「新しい」書籍のグループに対してより高い性能を示しました(平均40%)。これは、LLMが示したパターン(「疑わしい」書籍に対して高い精度を示す)とは逆であり、LLMの高い検出性能が、トレーニングデータに触れたことによるものであるという本論文の仮説を裏付ける結果となっています。
論文の付録では、人間評価を行った評価者は英語の知識はあったものの、一部に非ネイティブスピーカーが含まれていたことが限界として述べられています。特に古い書籍はよりフォーマルな英語で書かれていることが多く、非ネイティブスピーカーにとっては難しかった可能性があるとのことです。
7. 結論 (Conclusions)
本研究では、LLMのトレーニングデータ検出のための新しい手法「DE-COP」を提案しました。この手法は、モデルがトレーニング中に使われた文章を、その言い換えの中から識別できるかどうかをテストするという直感に基づいています。
DE-COPは、まず学術論文でその有効性を確認し、その後著作権付き書籍の検出に応用されました。実験の結果、評価対象とした4つのモデルファミリー全てにおいて、著作権の可能性のある書籍データがトレーニングに使われている可能性が示唆されました。また、オープンソースモデルを用いた実験では、DE-COPは最も競合力のあるベースライン手法に対して、平均で9.6%の性能向上を示しました。
同じ著作権付き書籍検出タスクにおける人間の評価性能が低いことは、モデルの高い精度がトレーニングデータへの露出によるものであり、他の要因だけでは説明できないという著者らの見解を裏付けています。
本研究は、LLMのトレーニングデータ検出における進歩を示すものですが、その限界についても論文中で言及されています。例えば、「疑わしい」書籍グループにはベストセラーなど人気の高い書籍が多く含まれており、これらの書籍に関する情報(ブログ記事、フォーラム、引用など)がインターネット上に豊富に存在するため、LLMがトレーニング中に間接的にそれらの情報に触れたことが、モデルの精度に影響した可能性などが挙げられています。また、前述の人間評価における非ネイティブスピーカーの課題も限界として挙げられています。
これらの限界はありますが、DE-COPはブラックボックスモデルにも適用できる実用的な著作権コンテンツ検出手法として、今後のLLM開発における透明性やアカウンタビリティの向上に貢献する可能性を秘めていると言えるでしょう。
まとめ
本記事では、LLMのトレーニングデータに含まれる著作権コンテンツの検出に焦点を当てた論文「DE-COP: Detecting Copyrighted Content in Language Models Training Data」を解説しました。
LLMの学習に使われる大量のデータに含まれる著作権問題は、AI技術の社会実装において避けて通れない課題です。トレーニングデータが非公開という状況の中で、いかにしてこの問題を解決していくか。DE-COPは、その有力なアプローチの一つとして提案されています。
多肢選択式の質問応答というシンプルなタスクを用いることで、モデルの内部情報にアクセスできないブラックボックスモデルに対しても有効な検出を可能にした点は、この手法の大きな強みです。実験結果も、既存手法を上回る高い性能を示しており、その有効性が確認されました。
しかし、DE-COPのような手法の開発は、LLM開発における著作権問題への対応を促進し、コンテンツクリエイターへの適切な補償や、より透明性の高いAI開発に貢献する可能性を秘めていると考えられます。
今後、このような検出技術がさらに発展し、AIと著作権の問題が建設的に解決されていくことを期待したいと思います。








