はじめに
本稿では、比較的小さな1.5Bパラメータの言語モデルでありながら、OpenAIの「o1-preview」をも上回る性能を示した「DeepScaleR-1.5B-Preview」について、その技術的な側面を詳細に解説します。特に、強化学習(RL)をスケーリングさせるための革新的なアプローチについて説明します。
参照元:
- 記事タイトル: DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL
- 参照元URL: https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2
- 公開年: 2025年
GoogleColab:
ColabURL:https://colab.research.google.com/drive/1WcnoqIRQtS78XjwxzlO3gftWrQlSzfkE?usp=sharing
※2024年4月14日動作確認済み
要点
- DeepScaleR-1.5B-Previewは、DeepSeek-R1-Distilled-Qwen-1.5B (1.5Bパラメータ) をベースに、分散強化学習(RL)を用いてファインチューニングされた言語モデルです。
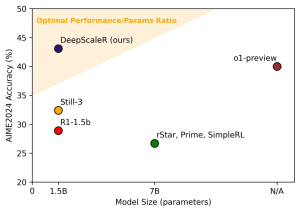
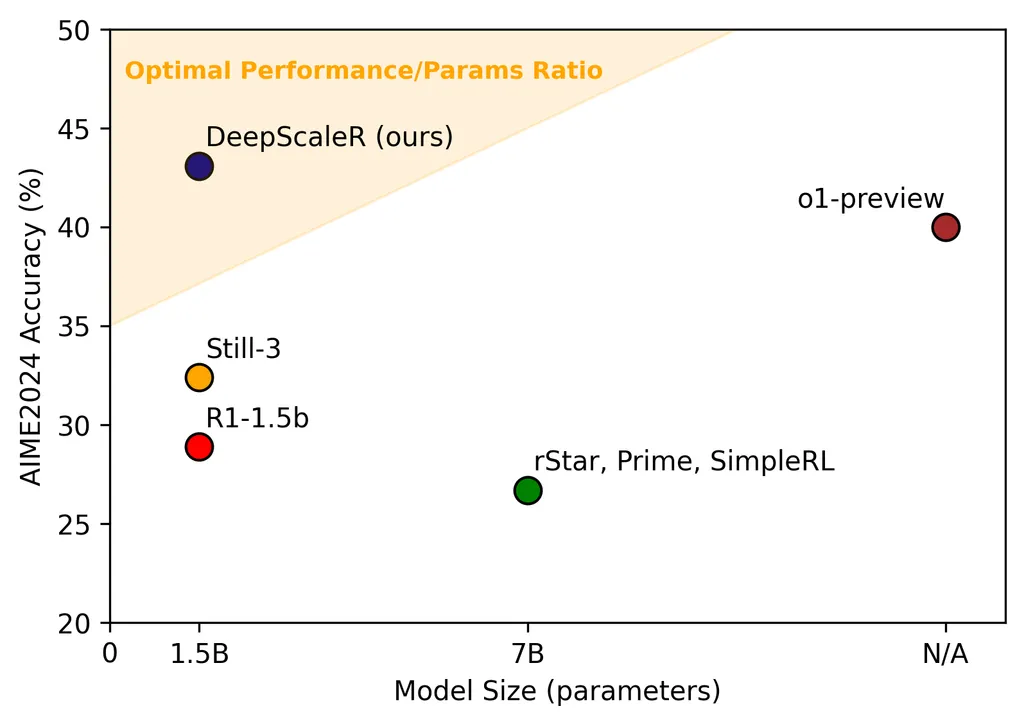
- 数学コンペティションベンチマーク「AIME 2024」において、43.1%のPass@1精度を達成しました。これはベースモデル(28.8%)から14.3%の大幅な向上であり、OpenAIのo1-preview(40.0%)をも上回る結果です。
- 学習には、DeepseekのGroup Relative Policy Optimization (GRPO)という単純化されたRLアルゴリズムが採用されています。
- 報酬関数はシンプルで、LaTeX/Sympyチェックをパスした正答に「1」、不正解または不適切な形式の回答に「0」を与えるOutcome Reward Model (ORM)です。
- 計算コスト削減と学習効率向上のため、「Iterative Context Lengthening(段階的コンテキスト長拡張)」という新しいアプローチが導入されました。モデルの改善に合わせてコンテキスト長を段階的に(8K→16K→24K)拡張します。
- この手法により、計算コストを18.42倍削減しつつ、高い性能を達成しました(3,800 A100 GPU時間)。
詳細解説
1. 前提知識:強化学習(RL)とLLM
本稿を理解する上で、以下の知識が前提となります。
- 大規模言語モデル (LLM): 大量のテキストデータで学習された、人間のようなテキストを生成・理解できるAIモデルです。
- 強化学習 (RL): エージェント(ここではLLM)が環境(タスク)内で試行錯誤し、報酬を最大化するように行動(回答生成)を学習する手法です。特定のタスク(例:数学問題解答)における性能向上に用いられます。
- PPO (Proximal Policy Optimization): RLアルゴリズムの一種で、安定した学習を実現するために広く使われています。DeepScaleRで採用されているGRPOは、PPOを拡張したものです。
- コンテキスト長 (Context Length/Window): LLMが一度に処理できるテキストの長さ(トークン数)です。コンテキスト長が長いほど、より多くの情報を考慮できますが、計算コストが増大します。
- Pass@1精度: 生成された回答のうち、最初の1つで正解する確率を示す評価指標です。
2. ベースモデルとデータセット
DeepScaleRは、「DeepSeek-R1-Distilled-Qwen-1.5B」という1.5Bパラメータのモデルをベースにしています。このモデルは、より大きなモデルから知識を蒸留(Distilled)されたもので、比較的小さなサイズでありながら高い基本性能を持っています。
学習データには、以下のソースから収集・処理された約40,000のユニークな問題と解答のペアが使用されました。
- AIME problems (1984-2023)
- AMC problems (prior to 2023)
- Omni-MATH dataset
- Still dataset
データ処理パイプラインでは、Gemini 1.5 Proを用いた解答抽出、埋め込みを用いた重複問題の削除、Sympyで評価不能な問題のフィルタリングなどが行われています。
3. 強化学習の手法:GRPOと報酬関数
学習には、Deepseekが提案するGroup Relative Policy Optimization (GRPO)が採用されました。これはPPOを拡張したアルゴリズムで、以下の特徴を持ちます。
- Advantage Functionの正規化: 同じプロンプトから生成された全サンプルにわたってAdvantage Function(ある行動が平均よりどれだけ良いかを示す指標)を正規化します。
- KLダイバージェンス正則化: PPOの代理損失(Surrogate Loss)に加えてKLダイバージェンスによる正則化を適用し、ポリシー(モデルの行動戦略)が急激に変化するのを防ぎます。
報酬関数は非常にシンプルです。
- 報酬=1: 生成された解答がLaTeX形式として正しく、かつ数学的な検証ライブラリSympyによるチェックをパスした場合。
- 報酬=0: 解答が不正解、または形式が不適切(例:思考プロセスを示す<think>, </think>タグがない)な場合。
Process Reward Model (PRM)のような中間的なフィードバックや部分点を与えず、最終的な結果のみで評価するOutcome Reward Model (ORM)を採用することで、報酬ハッキング(報酬を得るためだけに最適化され、本質的な問題解決能力が向上しない現象)を防いでいます。
4. 革新的アプローチ:Iterative Context Lengthening
RLを推論タスクに適用する上での大きな課題は、計算コストです。特に推論タスクでは、モデルが思考プロセス(Chain-of-Thought)を含めて長い回答を生成するため、計算量が膨大になります。コンテキスト長を2倍にすると、計算コストは少なくとも2倍になります。
長いコンテキストはモデルがより深く思考する余地を与えますが、学習が遅くなります。短いコンテキストは学習を加速しますが、複雑な問題を解く能力が制限される可能性があります。
このトレードオフに対処するため、DeepScaleRでは「Iterative Context Lengthening」という手法が導入されました。これは、モデルの性能向上に合わせて、学習に用いるコンテキスト長を段階的に拡張していくアプローチです。
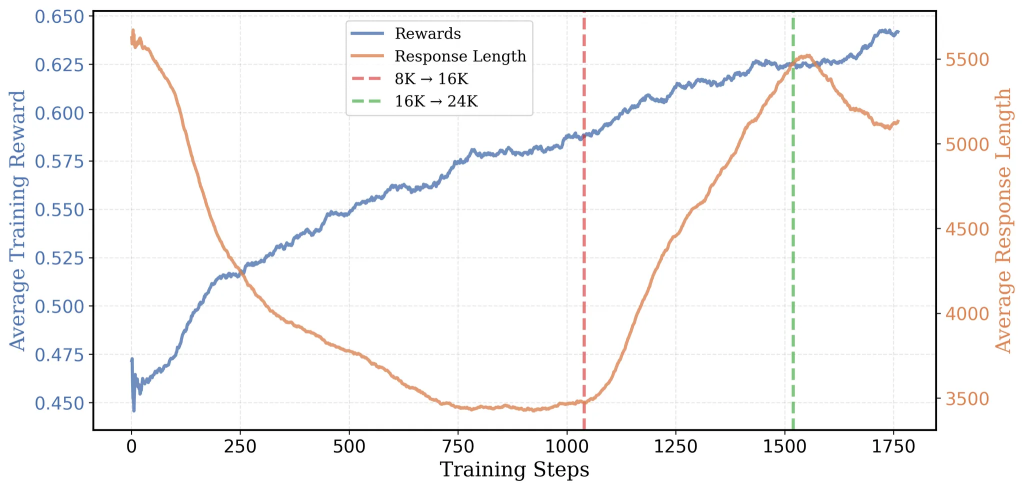
- ステップ1: 8Kコンテキストでの学習 (0-1040ステップ)
- まず、比較的短い8Kのコンテキスト長で学習を開始します。
- 初期の分析で、不正解の回答は正解の回答よりも平均して3倍長い(20,346 vs 6,395トークン)ことが分かっていました。これは、長すぎる思考がかえって間違いにつながる可能性を示唆します。
- 8Kコンテキストで学習することで、モデルはより効率的な思考(短いトークン数で正解にたどり着く)を学習します。
- この段階で、AIME 2024のPass@1精度は22.9%から33%に向上し、平均回答長は5,500トークンから3,500トークンに減少しました。
- 使用GPU: 8 x A100-80GB, バッチサイズ: 1024 (128プロンプト * 8サンプル/プロンプト)
- ステップ2: 16Kコンテキストへの拡張 (1040-1520ステップ)
- 約1000ステップ後、8Kコンテキストでの学習では精度向上が鈍化し、回答長が再び増加し始め、コンテキスト長の制限による回答の切り捨てが増加しました(モデルがより長く考えようとするが、上限に達してしまう)。
- これを転換点と捉え、ステップ1040のチェックポイントから16Kコンテキストでの学習を再開しました。
- 8Kでのブートストラップにより、この段階での平均回答長は(最初から16Kで学習する場合の9,000トークンではなく)3,000トークン程度に抑えられ、学習効率が向上しました(少なくとも2倍高速)。
- この段階で、AIME 2024のPass@1精度は33%から38%に向上しました。
- 使用GPU: 32 x A100-80GB, バッチサイズ: 2048 (128プロンプト * 16サンプル/プロンプト)
- ステップ3: 24Kコンテキストへの拡張 (1520+ステップ)
- 16Kコンテキストでさらに500ステップ学習した後、再び性能向上が停滞し始めました。
- 最終的な性能向上のため、ステップ1520(16Kでの480ステップ目)のチェックポイントから24Kコンテキストでの学習を開始しました(”24K magic“)。
- コンテキスト長を拡張したことで、モデルはさらに性能を伸ばし、最終的にAIME 2024のPass@1精度は43.1%に達しました。
- 使用GPU: 32 x A100-80GB, バッチサイズ: 2048 (128プロンプト * 16サンプル/プロンプト)
この段階的なアプローチにより、最初から長いコンテキストで学習する場合と比較して、計算コストを大幅に削減(合計3,800 A100時間、これは32台のA100で約5日間に相当)しつつ、高い性能を達成することに成功しました。
5. 評価結果
DeepScaleR-1.5B-Previewは、複数の数学コンペティションベンチマークで評価されました。Pass@1精度(16サンプルでの平均)は以下の通りです。
| Model | AIME 2024 | MATH 500 | AMC 2023 | Minerva Math | OlympiadBench | Avg. |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.8 | 82.8 | 62.9 | 26.5 | 43.3 | 48.9 |
| DeepScaleR-1.5B-Preview | 43.1 | 87.8 | 73.6 | 30.2 | 50.0 | 57.0 |
| O1-Preview | 40.0 | 81.4 | – | – | – | – |
| (参考) Still-1.5B | 32.5 | 84.4 | 66.7 | 29.0 | 45.4 | 51.6 |
| (参考) Qwen2.5-7B-SimpleRL | 26.7 | 82.4 | 62.5 | 39.7 | 43.3 | 50.9 |
表の通り、DeepScaleRは全てのベンチマークでベースモデルを大幅に上回り、特にAIME 2024では14.3%という顕著な改善を示しました。また、7Bパラメータを持つ他のRL研究モデル(rSTAR, Prime, SimpleRL)や、O1-Previewをも凌駕しています。これは、1.5Bという軽量なモデルサイズで非常に高い性能を達成したことを意味し、モデルサイズ対性能比(パレート効率)において優れた結果を示しています。
6. モデルの利用方法
DeepScaleR-1.5B-PreviewはHugging Face Hubで公開されており、Transformersライブラリを使って簡単に利用できます。以下にPythonでの利用例を示します。
# 必要なライブラリをインポート
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# モデル名
model_name = "agentica-org/DeepScaleR-1.5B-Preview"
# トークナイザとモデルをロード
# GPUが利用可能な場合はGPUを使用 (推奨)
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
# プロンプトの準備 (DeepScaleRが期待する形式に合わせる)
# 例: 数学の問題
problem = "What is the value of $1 + 1$?"
prompt = f"<|user|>\n{problem}<|end|>\n<|assistant|>\n<think>" # <think>タグで思考プロセスを開始
# 推論の実行
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# generateメソッドで回答を生成
# max_new_tokens: 生成する最大トークン数
# temperature: 出力のランダム性を制御 (低いほど決定的)
# top_p: 上位p%の確率を持つトークンからサンプリング
# do_sample: サンプリングを行うかどうか
outputs = model.generate(
**inputs,
max_new_tokens=1024, # 必要に応じて調整
temperature=0.7,
top_p=0.9,
do_sample=True,
eos_token_id=tokenizer.eos_token_id # 終了トークンIDを指定
)
# 生成されたテキストをデコード
# skip_special_tokens=Trueで特殊トークンを除外
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=False)
# 結果の表示 (プロンプト部分を除去して表示することも可能)
print(generated_text)
# 例: プロンプト部分を除去して表示
output_text = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=False)
print("--- Generated Answer ---")
print(output_text)
このコードは、指定された数学の問題に対してDeepScaleRモデルに思考プロセスを含めた回答を生成させる基本的な例です。max_new_tokensやtemperatureなどのパラメータは、タスクや要求に応じて調整してください。また、モデルは推論にそれなりの計算リソースを必要とするため、GPU環境での実行が推奨されます。
まとめ
本稿では、DeepScaleR-1.5B-Previewの技術的な詳細、特に強化学習(RL)のスケーリングにおける「Iterative Context Lengthening」という革新的なアプローチについて解説しました。
この研究の重要なポイントは以下の通りです。
- 小さなモデルでもRLスケーリングは有効: 高品質なSFT(教師ありファインチューニング)データと組み合わせることで、小さなモデルでもRLによって推論能力を大幅に向上させられることが示されました。SFTとRLの組み合わせが重要です。
- 段階的なコンテキスト長拡張の有効性: 最初は短いコンテキストで効率的な思考パターンを学習させ、その後段階的にコンテキスト長を拡張することで、計算コストを抑えつつ、長いコンテキストを必要とする複雑な問題への対応能力を高めることができます。
DeepScaleRは、RLを用いた高性能な推論モデル開発が、スケーラブルかつコスト効率的に可能であることを示しました。この成果は、LLMにおける強化学習のさらなる発展と民主化に貢献するものと期待されます。