はじめに
近年、大規模言語モデル(LLM)の能力をさらに引き出すための技術として、強化学習(Reinforcement Learning, RL)、特にLLMのための強化学習(RLLM)が注目を集めています。数学的推論などの分野では目覚ましい成果が報告されていますが、コーディングの領域では、高品質な学習データの不足や報酬設計の難しさから、その応用はやや遅れをとっていました。
本稿では、こうした課題に挑戦し、コーディング領域におけるRLLMの可能性を切り開く可能性があるモデル、「DeepCoder-14B-Preview」について詳しく解説します。AgenticaチームとTogether AIの共同研究により公開されたこのモデルは、既存の強力なコードLLMをベースに、分散強化学習を用いてファインチューニングされており、特に長いコンテキスト長での複雑なコード推論能力の向上に成功しています。
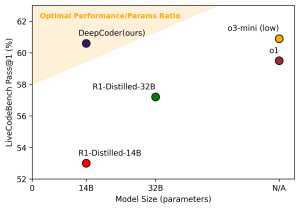
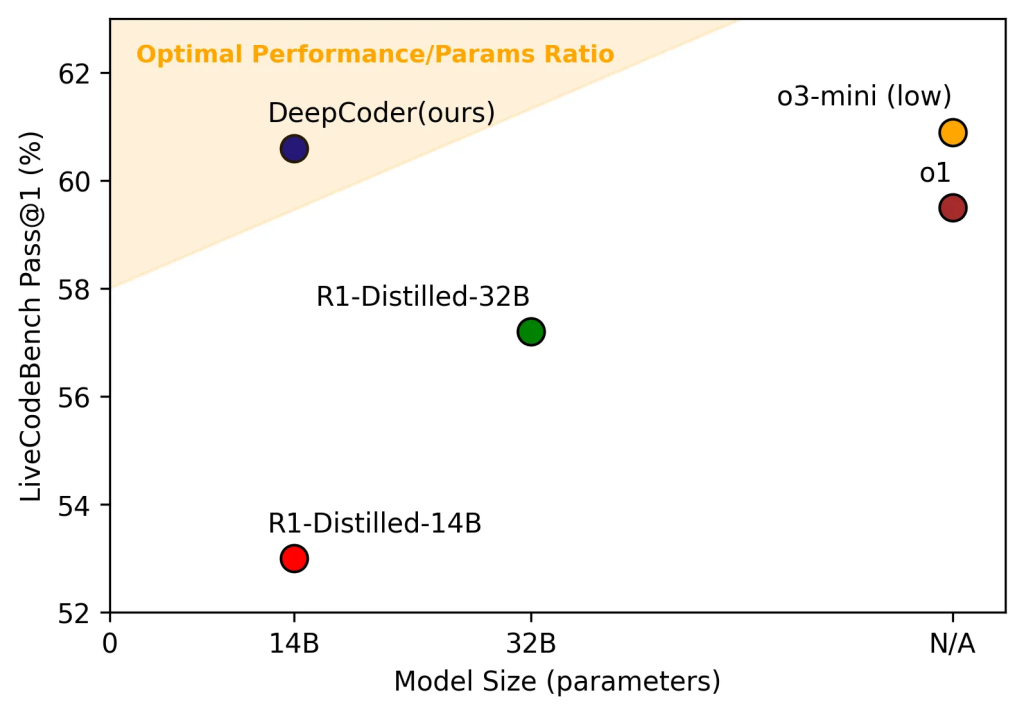
注目すべきは、現在の最先端モデルが1兆パラメータを超えるとされているなか、比較すると小規模な140億パラメータでありながら、最先端のクローズドモデルに匹敵する性能を達成し、その成果が完全にオープンソースとして公開されている点です。DeepCoderの技術的背景(データ、学習アルゴリズム、評価)、具体的な性能、そして実践的な利用方法について、解説します。
参照元情報:
- Hugging Face Model Card: https://huggingface.co/agentica-org/DeepCoder-14B-Preview
- Notion Blog Post: https://pretty-radio-b75.notion.site/DeepCoder-A-Fully-Open-Source-14B-Coder-at-O3-mini-Level-1cf81902c14680b3bee5eb349a512a51
- Github: https://github.com/agentica-project/rllm
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
GoogleColab:
- GoogleColabURL: https://colab.research.google.com/drive/1T2B2oZbLE0IIh3AgZ0RRPxu8V-FsY3Dh?usp=sharing
要点
- DeepCoder-14B-Previewは、強力なコードLLMであるDeepSeek-R1-Distilled-Qwen-14Bをベースに、分散強化学習(RL) を用いてファインチューニングされた140億パラメータのコード推論LLMであり、複雑なコーディングタスクにおける推論能力の向上を目指して開発されました。
- コーディングベンチマークLiveCodeBench v5(2024年8月1日~2025年2月1日)において60.6%のPass@1精度を達成。これはベースモデル(53%)から8%の大幅向上であり、パラメータ効率の観点から見ても、より大規模なOpenAIのo3-miniに匹敵する非常に高い性能です。
- 学習には、RLアルゴリズムGRPOを安定化・効率化させたGRPO+ と、段階的に長いコンテキストに対応させるIterative Context Lengtheningという革新的な手法が組み合わせて用いられています。これにより、学習の安定性と長文脈対応能力を両立させています。
- 学習データには、TACO-Verified、PrimeIntellect SYNTHETIC-1、LiveCodeBench v5から厳選された約24,000のユニークな「問題文」と「テストケース」のペアが使用されており、データの質と検証可能性が重視されています。
- 32Kトークンという比較的長いコンテキスト長で学習されましたが、学習時よりもさらに長い64Kトークンのコンテキスト長での推論においても性能が向上するという、優れた長文脈汎化能力を示します。
- Hugging Face Transformersライブラリなどを通じて容易に利用可能であり、MITライセンスの下で公開されているため、研究・商用利用のハードルが低い点も魅力です。
詳細解説
DeepCoder-14B-Previewとは?
DeepCoder-14B-Previewは、単なるコード生成ツールではなく、「コード推論LLM(Code Reasoning LLM)」と位置付けられています。これは、コードの構文的な正しさを超えて、コードの意味や論理構造を理解し、それに基づいて新しいコードを生成したり、既存のコードを分析・修正したりする能力を持つことを意味します。例えば、複雑なアルゴリズムの実装、バグの特定と修正、あるいはコードの意図を汲み取ったリファクタリングなどが含まれます。
このモデルの基盤となっているのは、DeepSeek-R1-Distilled-Qwen-14Bです。これは、それ自体が強力なコードLLMであり、DeepCoderはこの優れた初期能力を出発点としています。DeepCoderの真価は、このベースモデルに対して分散強化学習(Distributed RL) を適用し、特に長いコンテキスト(数千〜数万トークンに及ぶような長いプログラムや関連ファイル)を扱う能力を飛躍的に向上させた点にあります。現代のソフトウェア開発では、単一の短い関数だけでなく、複数のモジュールや依存関係が絡み合った複雑なコードベースを扱うことが多く、このような長文脈での推論能力は極めて重要です。
特筆すべきは、そのパラメータ数です。140億パラメータは、数百億〜数兆パラメータを持つモデルが登場する中で比較的小規模ですが、LiveCodeBench v5(多様なプログラミングコンテスト形式の問題を含む、実践的なコーディング能力を測るベンチマーク)で60.6% Pass@1という高い精度を達成しました。これは、OpenAIのo3-mini(2025年1月31日版、性能重視設定)の60.9%に肉薄する結果です。これは、DeepCoderが単に大きいだけでなく、パラメータ効率が非常に高い、つまり、より少ない計算資源で高い性能を発揮できることを示唆しています。これは、モデルの利用(推論)コストの低減や、より多くの環境での利用可能性につながる重要な利点です。ベースモデルからの8%という改善幅も、RLによるファインチューニングが単なる微調整ではなく、モデルの根本的な能力向上に寄与したことを示しています。
学習データと手法
DeepCoderの成功の鍵は、質の高いデータと洗練された学習手法にあります。特にRLを用いた学習では、これらの要素がモデルの性能と安定性に直接影響します。
1. 学習データ:品質と検証可能性の追求
RLでは、モデルの行動(生成されたコード)に対して報酬を与えることで学習を進めます。コーディングタスクの場合、生成されたコードが問題の要求を満たしているか(=テストケースをパスするか)が報酬の基準となります。したがって、正確で信頼できる報酬信号を得るためには、学習データに含まれる「問題文」と「テストケース」の品質が極めて重要になります。不正確なテストケースや曖昧な問題文は、モデルに誤った学習を促し(報酬ハッキング)、性能を低下させる原因となります。
DeepCoderの開発チームは、この点を重視し、約24,000のユニークな問題・テストペアからなる高品質なデータセットを構築しました。データソースは以下の通りです。
- Taco-Verified: 人手による検証を経た、信頼性の高いデータ。
- PrimeIntellect SYNTHETIC-1: 大規模な合成データセットから、検証可能なものを抽出。
- LiveCodeBench v5 (学習用期間): 比較的新しい、実践的なベンチマークデータ。
これらのデータに対して、さらに厳格なフィルタリングが適用されました。
- プログラムによる検証: 提供されている公式解答が全てのテストケースをパスすることを確認。パスしない問題は除外。
- テストケース数のフィルタリング: 各問題に最低5つのテストケースが含まれていることを要求。テストケースが少なすぎると、モデルが特定の入力パターンに対する答えだけを暗記してしまう「報酬ハッキング」のリスクが高まるためです。多様なテストケースによって、より汎用的な問題解決能力の学習を促します。
- 重複排除: 異なるデータセット間で重複する問題を除外し、評価データ(テスト用LiveCodeBench期間やCodeforces)との汚染(リーク)がないことも確認。
このようにして準備された高品質なデータセットが、効果的なRL学習の基盤となっています。
2. 学習手法:安定性と長文脈性能を実現する GRPO+ と Iterative Context Lengthening
DeepCoderの学習レシピの核心は、RLアルゴリズムのGRPO+ と、コンテキスト長を段階的に拡張するIterative Context Lengthening の組み合わせです。
GRPO+ (Improved GRPO):
GRPOは、LLMのファインチューニングで用いられるPPO(Proximal Policy Optimization)系統のアルゴリズムですが、特に長いシーケンスを扱う場合や報酬がスパース(成功か失敗かのみ)な場合に不安定になることがありました。GRPO+は、DAPOという別の手法のアイデアを取り込み、以下の改良によって安定性と効率を向上させています。
※DAPOとは:「Difficulty-Aware Policy Optimization」の略で、LLMの強化学習(RL)における学習手法の一つです。特に、数学的推論のような複雑なタスクにおいて、学習の安定性を高め、モデルの性能を向上させることを目的として開発されました。
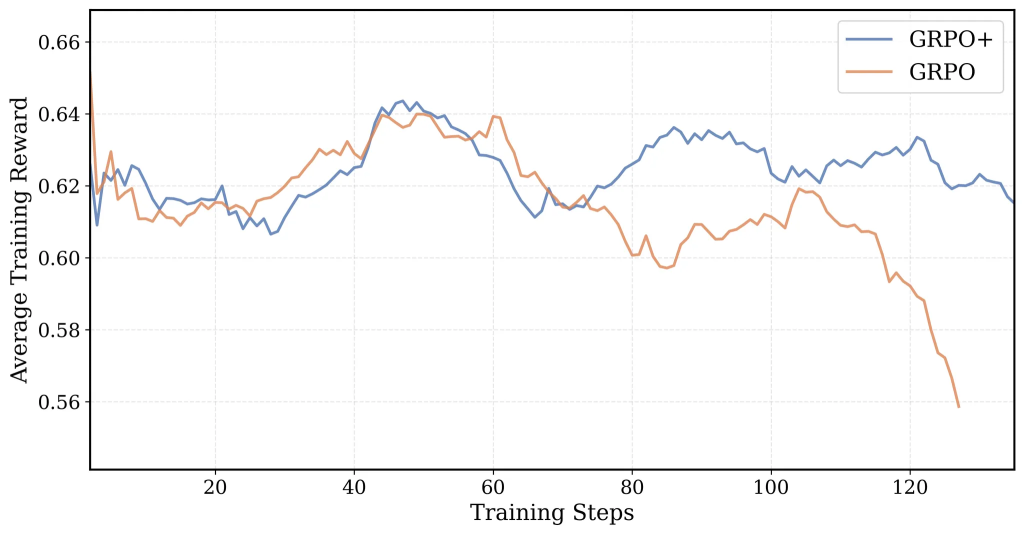
Offline Difficulty Filtering:
DAPOでは学習中にリアルタイムで簡単すぎる/難しすぎるサンプルを除外しますが、これは計算コストが高くなります。GRPO+では、事前にデータセット全体の難易度を分析し、適切な範囲の問題のみを使用することで、実行時のオーバーヘッドなく学習の焦点を適切な難易度に保ちます。
No Entropy Loss:
エントロピー損失は、モデル出力の多様性を維持するために導入されることが多いですが、実験の結果、これが逆に学習を不安定化させ、最終的に性能が崩壊する原因となることが観察されました。そのため、GRPO+ではこの項を完全に削除し、安定性を優先しました。
No KL Loss:
KL損失は、学習中のモデルが元の(ファインチューニング前の)モデルから大きく逸脱するのを防ぐ制約ですが、これも削除されました。これにより、モデルはより自由に最適な方策を探求できるようになり、また、参照モデルの推論(log probability計算)が不要になるため、学習速度が向上します。
Overlong Filtering (DAPOより):
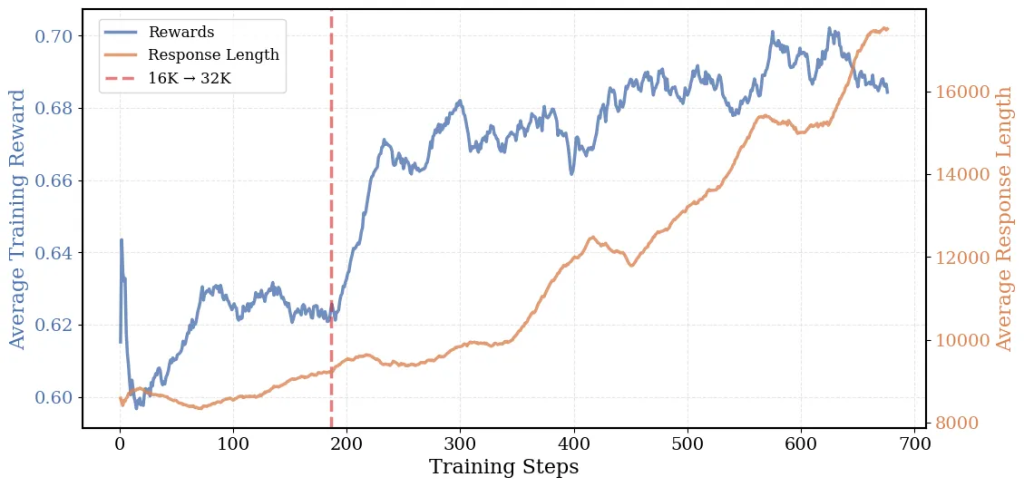
これが長文脈汎化能力の鍵です。LLMが学習設定(例:32Kトークン)を超える長さの思考やコードを生成しようとした際、通常は途中で打ち切られ、ペナルティ(損失)を受けます。Overlong Filteringでは、この打ち切られた部分に対応する損失を計算に含めません(マスクします)。これにより、モデルは「長すぎる」ことによるペナルティを恐れることなく、問題解決に必要な思考を最後まで展開することを学習できます。結果として、学習時のコンテキスト長(32K)で訓練されても、それより長い64Kトークンでの推論能力を獲得できるのです。
Clip High (DAPOより):
PPO/GRPOの目的関数(代理損失)には、更新幅を制限するクリッピングがありますが、その上限値を引き上げることで、より大きな更新(=より積極的な探索)を許容します。これにより、モデルが局所解に陥るのを防ぎ、エントロピー(多様性)の安定化にも寄与します。
Iterative Context Lengthening:
これは、いわば「カリキュラム学習」のアプローチです。最初から非常に長いコンテキスト(例:32K)で学習を始めると、計算コストが高いだけでなく、モデルが基本的なパターンを掴む前に複雑すぎる情報に圧倒されてしまう可能性があります。そこで、まず比較的短いコンテキスト長(16K)で学習を開始し、モデルが効率的に基本的な推論パターンを習得した後、より長いコンテキスト長(32K)へと段階的に移行します。DeepCoderでは、この戦略により16K→32Kとコンテキスト長を拡張し、LiveCodeBenchスコアを着実に向上させました(54%→58%)。この手法と前述のOverlong Filteringの組み合わせが、DeepCoderの優れた長文脈性能の源泉となっています。
性能評価
DeepCoder-14B-Previewの能力は、複数の標準的なコーディングおよび推論ベンチマークを用いて定量的に評価されています。
| Model | LCB (8/1/24-2/1/25) | Codeforces Rating* | Codeforces Percentile* | HumanEval+ Pass@1 | AIME 2024 |
| DeepCoder-14B-Preview (ours) | 60.6 | 1936 | 95.3 | 92.6 | 73.8 |
| DeepSeek-R1-Distill-Qwen-14B | 53.0 | 1791 | 92.7 | 92.0 | 69.7 |
| O1-2024-12-17 (Low) | 59.5 | 1991 | 96.1 | 90.8 | 74.4 |
| O3-Mini-2025-1-31 (Low) | 60.9 | 1918 | 94.9 | 92.6 | 60.0 |
| O1-Preview | 42.7 | 1658 | 88.5 | 89 | 40.0 |
| Deepseek-R1 | 62.8 | 1948 | 95.4 | 92.6 | 79.8 |
| Llama-4-Behemoth** | 49.4 | – | – | – |
各ベンチマークの簡単な説明と結果の分析は以下の通りです。
- LiveCodeBench (LCB): 実際のプログラミングコンテストから取られた問題が多く含まれ、実践的な問題解決能力を測ります。DeepCoderは60.6%を達成し、ベースモデルから大きく向上、`o3-mini`に匹敵します。
- Codeforces: 競技プログラミングプラットフォームの問題を用いた評価で、アルゴリズム的な思考力や実装力が問われます。DeepCoderの推定Eloレーティングは1936で、これは全参加者の上位約5%(Percentile 95.3)に相当する高いレベルです。`o3-mini`や`o1`と同等の競争力を持っています。
- HumanEval+: 主に基本的な関数レベルのコード生成能力を評価します。DeepCoderは92.6%と非常に高いスコアを記録しており、`o3-mini`や、より大きな`Deepseek-R1`と同等です。
- AIME 2024: 米国の高校生数学コンテストの問題で、高度な数学的推論能力を測ります。DeepCoderはコーディングに特化して学習されましたが、このベンチマークでも73.8%と、ベースモデル(69.7%)から4.1%改善しました。これは、コーディングタスクを通じて獲得した論理的思考力や問題解決能力が、分野を超えて数学的推論にも応用可能(汎化)であることを示唆しており、モデルの基礎的な推論能力の向上を裏付けています。
これらの結果は、DeepCoder-14B-Previewが特定のタスクに過適合するのではなく、汎用的なコード推論能力と、ある程度の領域汎化能力を獲得していることを示しています。
利用方法
DeepCoder-14B-Previewは、Hugging Face Hubを通じて公開されており、標準的なライブラリであるTransformersを使って比較的簡単に利用を開始できます。以下に、主要な利用方法と注意点を詳述します。
1. パイプラインを利用する方法(高レベルAPI):
これは最も手軽な方法で、数行のコードでモデルを利用できます。
from transformers import pipeline
import torch
# パイプラインの初期化
# "text-generation"タスクを指定
pipe = pipeline("text-generation",
model="agentica-org/DeepCoder-14B-Preview", # モデル名を指定
torch_dtype=torch.bfloat16, # 半精度浮動小数点(bfloat16)を使用し、メモリ使用量と計算速度を改善。GPUが対応しているか確認。
device_map="auto") # 利用可能なデバイス(GPU/CPU)にモデルを自動で割り当て
# プロンプトの準備(ユーザーの指示のみを含むリスト形式)
messages = [
{"role": "user", "content": "Pythonでフィボナッチ数を計算する再帰関数を書いてください。"},
# 注意: 公式ドキュメントではシステムプロンプトの使用は推奨されていません。
# モデルはこの形式で学習されていない可能性があります。
]
# 推論の実行とパラメータ設定
# max_new_tokens: 生成する最大トークン数。元のドキュメントではmax_tokens>=64000が推奨されていますが、
# これは非常に長い応答を許容する場合です。タスクやリソースに応じて調整してください。
# do_sample=True: サンプリングを有効にし、より多様な出力を生成します。
# temperature=0.6: 出力のランダム性を制御。低いほど決定的、高いほど多様になります。推奨値は0.6。
# top_p=0.95: Top-p (nucleus) サンプリング。確率の高いトークンから累積確率がpを超えるまでを選択肢とします。推奨値は0.95。
outputs = pipe(messages,
max_new_tokens=256, # 例: ここでは256トークンに制限
do_sample=True,
temperature=0.6,
top_p=0.95)
# 生成されたテキストの表示
# outputs[0]["generated_text"] はリストで、最後の要素がモデルの応答です。
print(outputs[0]["generated_text"][-1]['content'])2. モデルとトークナイザーを直接ロードする方法:
より細かい制御を行いたい場合や、パイプラインが対応していない処理を行いたい場合は、モデルとトークナイザーを直接扱います。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
#トークナイザーとモデルのロード
tokenizer = AutoTokenizer.from_pretrained("agentica-org/DeepCoder-14B-Preview")
model = AutoModelForCausalLM.from_pretrained(
"agentica-org/DeepCoder-14B-Preview",
torch_dtype=torch.bfloat16, パイプラインと同様に半精度を使用
device_map="auto" デバイス自動割り当て
)
プロンプトの準備
prompt = "Pythonでクイックソートをインプレースで実装し、簡単なテストケースも示してください。"
messages = [
{"role": "user", "content": prompt},
]
プロンプトをモデルが理解できる形式(テンソル)に変換
apply_chat_template: モデル固有のチャット形式(例: <|user|>\n...\n<|assistant|>\n...)を適用します。
add_generation_prompt=True: モデルに応答を促すためのプロンプト(例: <|assistant|>)を追加します。
return_tensors="pt": PyTorchテンソル形式で返します。
.to(model.device): モデルがロードされているデバイス(GPU/CPU)に入力テンソルを移動します。
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
推論の実行(generateメソッドを使用)
パラメータはパイプラインの場合と同様です。
outputs = model.generate(
inputs,
max_new_tokens=512, 例: より長い応答を許容
do_sample=True,
temperature=0.6,
top_p=0.95
)
生成されたテンソル(ID列)を人間が読めるテキストにデコード
outputs[0] には入力プロンプト部分も含まれるため、入力の後からデコードを開始します (inputs.shape[1]:)
skip_special_tokens=True: <|endoftext|> のような特殊トークンをデコード結果から除外します。
response = tokenizer.decode(outputs[0][inputs.shape[1]:], skip_special_tokens=True)
結果の表示
print(response)利用上の推奨事項(詳細):
- システムプロンプトは追加しない: DeepCoderは特定のシステムプロンプトを用いて学習されたわけではないため、追加すると予期しない挙動を示す可能性があります。指示はすべてuserロールのメッセージに含めるのが最も安全です。
- temperature = 0.6, top_p = 0.95: これらは開発チームが実験的に見出した、コード生成において創造性と一貫性のバランスが取れた推奨値です。タスクに応じて微調整は可能ですが、まずはこの値から試すのが良いでしょう。
- max_tokens (または max_new_tokens) >= 64000: この推奨値は、モデルが非常に長いコンテキスト(最大64K)で評価され、良好な性能を示したことに由来します。複雑なソフトウェア開発タスクでは、数千〜数万トークンに及ぶコードやドキュメントを生成する必要があるかもしれません。このパラメータを大きく設定することで、モデルはそのような長大な応答を生成するポテンシャルを最大限に発揮できます。ただし、これは最大許容長であり、実際に生成される長さはモデルが応答を終えたと判断するまでとなります。また、非常に大きな値を設定すると、推論に必要なメモリ(VRAM)も増加するため、利用環境のスペックに応じて適切な値を設定する必要があります。一般的な短いコードスニペットの生成であれば、より小さな値(数百〜数千)で十分な場合も多いです。
まとめ
本稿では、AgenticaとTogether AIによる共同研究の成果である、オープンソースのコード推論LLM「DeepCoder-14B-Preview」について、その技術的背景から性能、利用方法に至るまで詳細に解説しました。
近年の大規模先端モデルと比較すると、140億という小規模なパラメータ数でありながら、分散強化学習というアプローチ、特に安定化と効率化を図ったGRPO+ アルゴリズムと、Iterative Context Lengthening および Overlong Filtering による長文脈対応能力の向上により、最先端のクローズドモデルに匹敵する目覚ましい性能を達成したことは特筆に値します。高品質な学習データの重要性と、それを活かすための洗練された学習手法が見事に結実した例と言えます。
特に、学習時のコンテキスト長(32K)を超えて64Kトークンという長大なコンテキストでの推論能力が向上するという汎化能力は、今後のLLM開発、特に複雑化するソフトウェア開発を支援するAIの進化において、重要なマイルストーンとなります。また、コーディング能力の向上が数学的推論能力にも波及している点は、これらのモデルが獲得しているのが表面的なパターンマッチングではなく、より深いレベルでの論理的思考力であることを示唆しています。
またDeepCoder-14B-Previewの最大の貢献の一つは、その成果がモデル、データセット、コード、学習ログに至るまで完全にオープンソース(MITライセンス)として公開されている点です。これは、LLMにおける強化学習技術の民主化を大きく前進させるものであり、世界中の研究者や開発者がこの成果を基盤として、さらなる改良や応用研究を進めることを可能にします。今後の発展が期待されます。