はじめに
近年、AI(人工知能)がインターネットを自律的にブラウジング(閲覧)し、必要な情報を収集する「AIエージェント」の重要性が増しています。しかし、AIが人間のように複雑な情報を探し出す能力を正確に測ることは、これまで困難でした。そこでOpenAIは、AIの高度なブラウジング能力を測定するために設計された、新しいベンチマーク(性能評価基準)「BrowseComp」を発表しました。本稿では、このBrowseCompがどのようなもので、なぜ重要なのかを公式ブログ「」をもとに分かりやすく解説します。
引用元
- タイトル: BrowseComp: a benchmark for browsing agents
- URL: https://openai.com/index/browsecomp/
- 発行日: 2025年4月10日
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- BrowseCompとは?: AIエージェントがインターネット上で見つけにくい情報(hard-to-find information)を特定する能力を測定するためにOpenAIが開発した、1,266個の難問からなる新しいベンチマークです。
- なぜ必要?: 従来のベンチマーク(例: SimpleQA)は単純な事実検索が中心で、最新AI(例: GPT-4o)には簡単すぎるため、より高度な探索能力を測る必要がありました。
- 何が難しい?: BrowseCompの問題は、答えは短いものの、見つけるためには数十から数百のウェブサイトを閲覧し、複数の情報を組み合わせる必要があるように作られています。答えの検証は簡単ですが、発見は困難(検証の非対称性)なのが特徴です。
- 評価結果:
- ブラウジング機能を持たないモデル(GPT-4oなど)では、ほぼ正解できませんでした。
- ブラウジング機能を追加しても(GPT-4o w/ browsing)、正答率はわずかに向上するのみでした。
- より高度な推論能力を持つモデル(OpenAI o1)は、ブラウジングなしでも多少良い結果を出しました。
- BrowseCompのようなタスクに特化して訓練された高度な研究用モデル「Deep Research」は、約半数の問題を解決しました。
- 重要な発見: AIが高い性能を発揮するには、単にウェブを閲覧する能力だけでなく、戦略的な推論能力、粘り強さ、創造的な検索が不可欠であることが示唆されました。
詳細解説
AIエージェントとウェブブラウジングの重要性
AIエージェントとは、特定の目標を達成するために自律的に行動するソフトウェアのことです。人間がインターネットで情報を検索するように、AIエージェントもウェブブラウジングを通じて知識を獲得し、より複雑なタスクを実行できるようになります。例えば、最新の市場動向を調査したり、特定の条件に合う製品を探したりするなど、その応用範囲は広がりつつあります。
既存ベンチマークの課題
AIの能力を測るためには、標準化されたテストである「ベンチマーク」が使われます。従来、事実検索能力を測るベンチマークとして「SimpleQA」などがありましたが、これらは比較的単純な質問(例:「日本の首都は?」)が中心でした。しかし、GPT-4oのような高性能なAIが登場し、簡単なブラウジングツールと組み合わせることで、これらのベンチマークでは簡単に満点に近いスコアが出せるようになってしまいました。これでは、AIが本当に困難な情報探索を行えるのか、その真の実力は測れません。
BrowseCompとは何か
そこで登場したのがBrowseComp (Browsing Competition)です。これは、AIが見つけにくく、かつ複数の情報源にまたがる複雑に絡み合った情報(entangled information)を発見する能力を測ることに特化しています。
BrowseCompには以下のような特徴があります。
- 難易度の高い問題: 1,266個の問題は、当時の既存モデル(GPT-4oなど)では解けず、簡単なウェブ検索でもすぐには答えが見つからないように、人間によって慎重に作成されました。人間でも解くのに10分以上かかるような難易度を目指しています(実際には、人間が2時間かけても解けない問題が多く含まれます)。
- 短い答え: 評価を容易にするため、答えは特定の単語や短いフレーズ(例:人名、作品名)になるように設計されています。これにより、採点の客観性が保たれます。
- 検証の非対称性: 問題を解く(答えを見つける)のは非常に難しい一方、提示された答えが正しいか検証するのは比較的簡単、という性質を持ちます。これは「検証の非対称性 (asymmetry of verification)」と呼ばれ、ベンチマークとして信頼性を高める上で重要です。
- 問題作成方法: 作成者はまず答えとなる「種」(人、出来事、物など)を決め、それに関する複数の特徴(ただし、検索候補が多くなるようなもの)を見つけ出し、それらを組み合わせて「逆さまの」質問を作成しました。
例えば、以下のような質問が含まれます(これは記事中の例です):
1960年代から1980年代の間に放送され、エピソード数が50未満のテレビ番組で、時折第四の壁を破り、無私な修行者の助けを借りた過去を持ち、ユーモアで知られる架空のキャラクターは誰か?
答え: Plastic Man
この答えを見つけるには、複数の条件を満たすキャラクターを膨大な候補の中から探し出す必要があり、単純な検索では困難です。
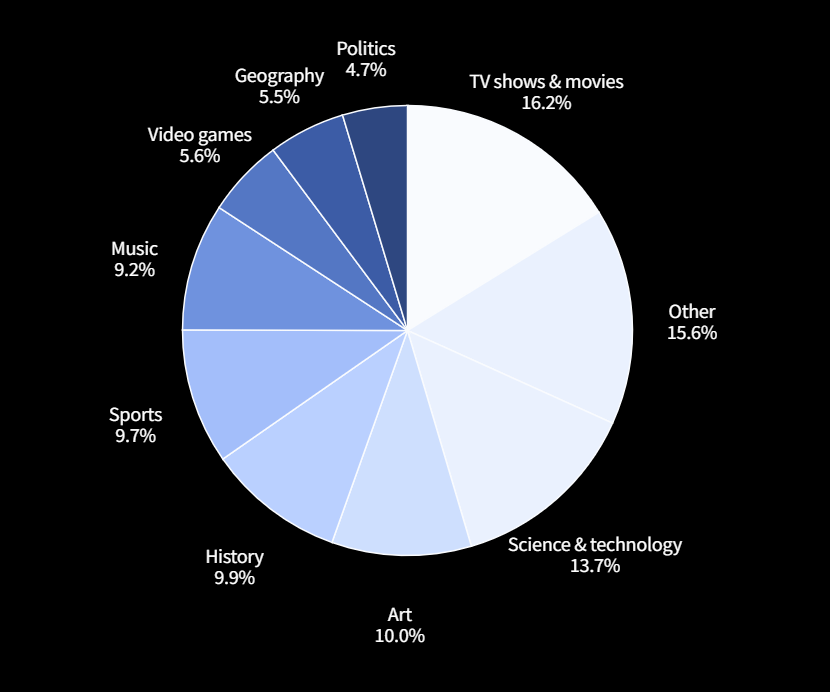
BrowseCompの難易度
BrowseCompがいかに難しいかを示すために、問題作成者とは別の人間(AIアシスタント使用禁止)が問題を解く試みが行われました。その結果、2時間という制限時間内に解けたのは全体の約29%に過ぎませんでした。解けた問題の中でも、正答率は約86%でした。多くの問題は、人間が解けたとしても1時間以上、中には2〜3時間かかるものもありました。これは、BrowseCompが非常に高度な探索能力を要求することを示しています。

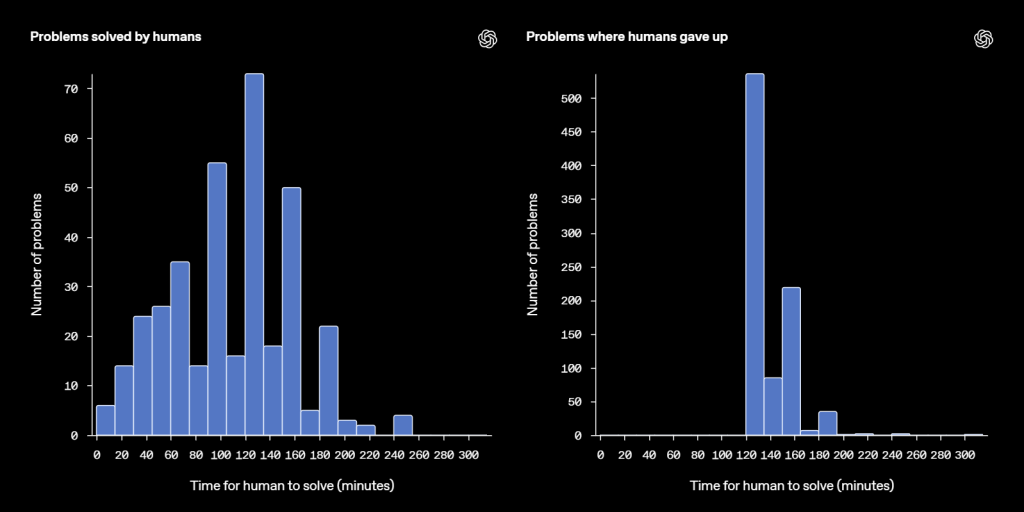
主要モデルの評価結果
OpenAIは、BrowseCompを使っていくつかの自社モデルの性能を評価しました。
- GPT-4o, GPT-4.5 (ブラウジングなし): 正答率はほぼ0%でした。これは、モデル内部の知識だけではBrowseCompの難問には太刀打ちできないことを示しています。
- GPT-4o (ブラウジングあり): 正答率は1.9%とわずかに向上しましたが、依然として低いままでした。これは、単にウェブを閲覧できるだけでは不十分で、どのように検索し、情報を解釈・統合するかという戦略的な能力が重要であることを示唆しています。
- OpenAI o1 (ブラウジングなし、より高度な推論能力): 正答率は9.9%でした。ブラウジングがないにも関わらずGPT-4oより高いスコアを出したことは、高度な推論能力が内部知識から答えを導き出す助けになる場合があることを示しています。
- Deep Research (高度な研究用エージェント): 正答率は51.5%と、他のモデルを大幅に上回りました。このモデルは、粘り強くウェブを検索し、複数の情報源から情報を評価・統合し、検索戦略を適応させる能力を持つように特別に訓練されています。(ただし、このモデルはBrowseCompのようなタスクで性能を発揮するように訓練データが調整されている点には注意が必要です。)
これらの結果から、BrowseCompのような困難な情報探索タスクを成功させるには、ツール(ブラウジング)の使用能力と高度な推論能力の両方が重要であると言えます。
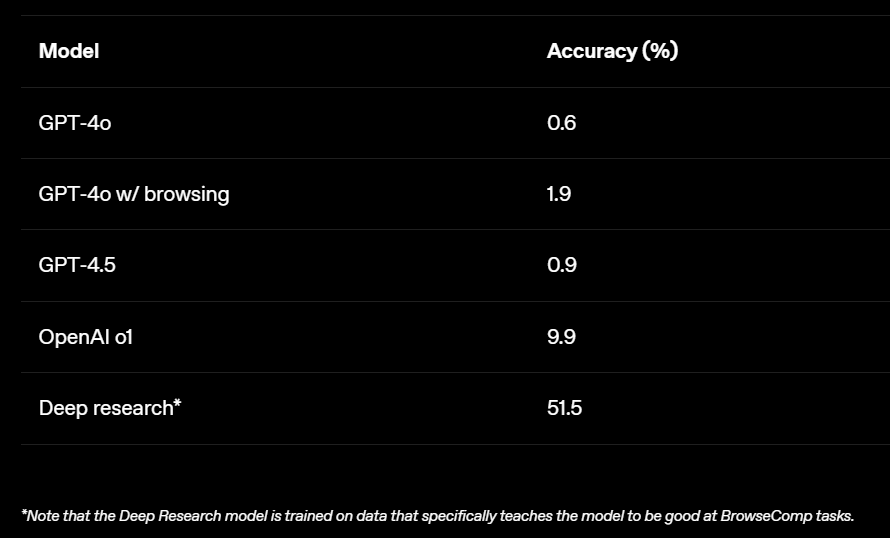
計算資源と性能向上
AIエージェントの特徴として、推論時(答えを生成する際)に使用する計算資源(時間や処理能力)を増やすことで、性能が向上する傾向があります。BrowseCompでも同様の結果が見られ、Deep Researchモデルがより多くのウェブサイトを閲覧し、より深く思考する時間を与えられるほど、正答率が向上しました。
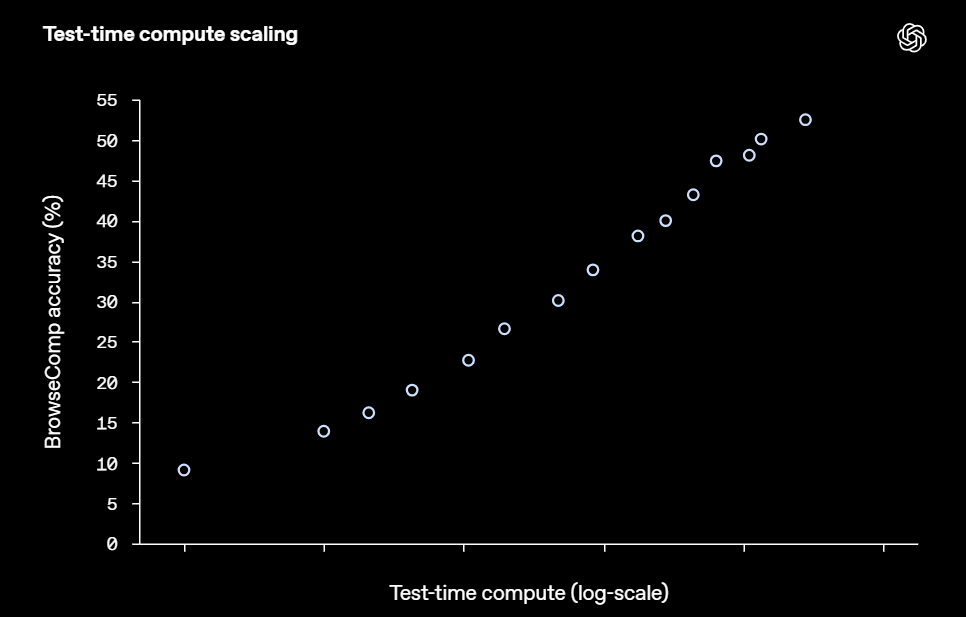
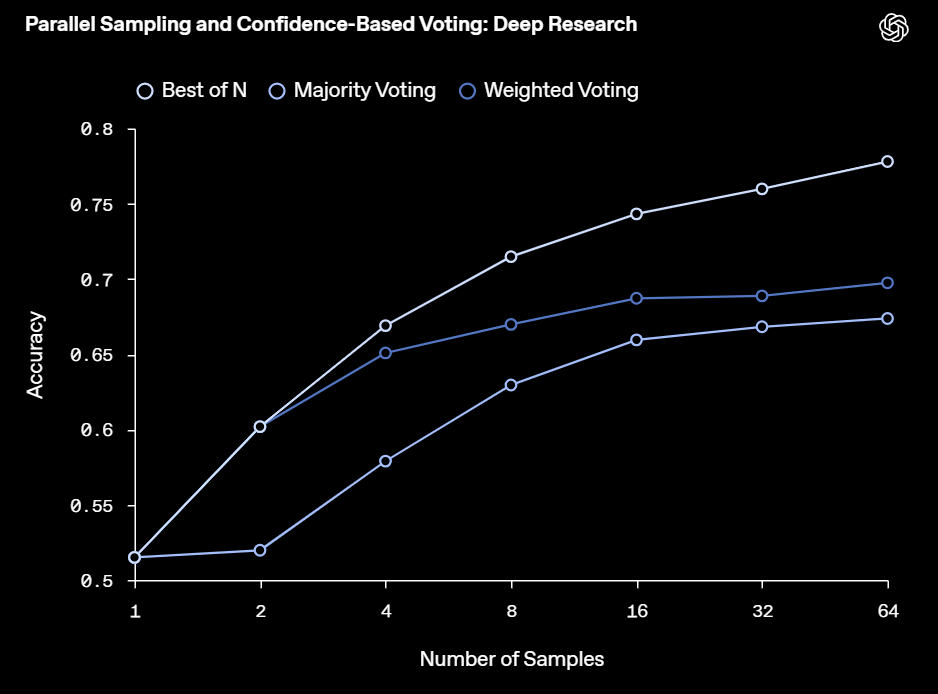
さらに、一つの問題に対して複数回試行させ、その結果を統合する戦略(アグリゲーション戦略)も有効でした。例えば、複数回の試行の中で最も多く出現した答えを選ぶ「多数決」や、各試行でモデル自身が出力した「自信度」に基づいて最適な答えを選ぶ「Best-of-N」などを用いることで、Deep Researchの正答率は15%から25%も向上しました。特にBest-of-Nの性能が高かったことは、モデルが「自分が正しい答えを出せているか」をある程度認識できている可能性を示唆しています。
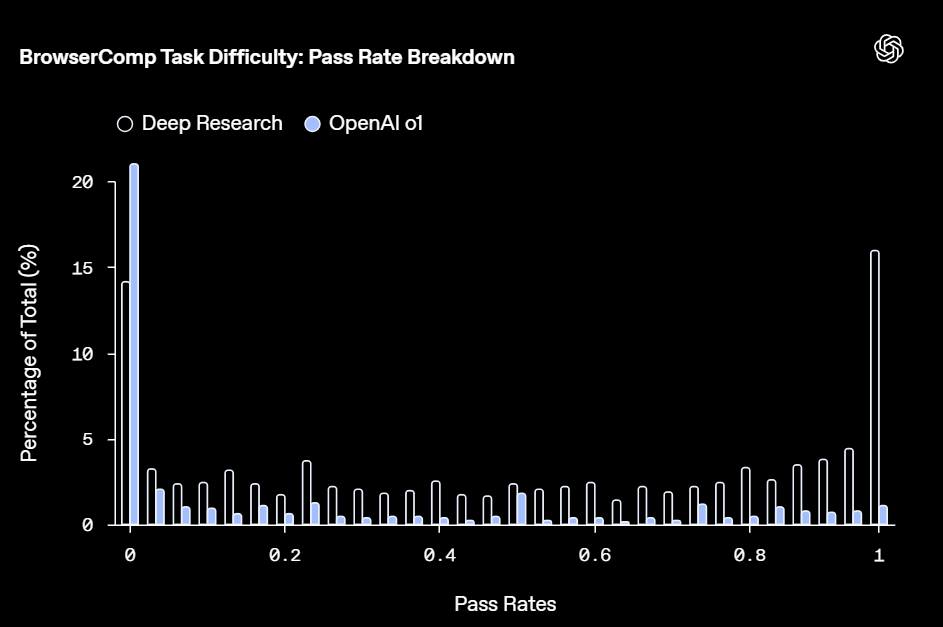
パス率の分布
Deep ResearchとOpenAI o1について、各問題に対するパス率(64回の試行中、正解できた割合)の分布を分析しました。Deep Researchは、16%の問題を完全に解き(パス率100%)、14%の問題は全く解けませんでした(パス率0%)。これは、BrowseComp内のタスクの難易度に大きなばらつきがあることを示しています。 多くの中間的な難易度のタスクが存在し、モデルがタスクの構造やドメインによって苦戦する場合があることも示唆されました。
Deep Researchが全く正解できなかった問題について、正解を提示した上で関連するウェブ証拠を見つけるように指示したところ、ほとんどの場合で成功しました。これは、これらの問題が「解けない」のではなく、「手がかりなしでは解くのが極めて困難」であったことを意味します。BrowseCompの多くのタスクは、単なる情報検索だけでなく、戦略的な粘り強さ、柔軟な検索の再構成、断片的な手がかりを複数のソースから組み立てる能力を要求することを示唆しています。
BrowseCompの意義と限界
BrowseCompは、AIが困難な情報を見つけ出すための粘り強さや創造性といった、重要なコア能力を測定する上で有用なベンチマークです。しかし、答えが短い形式に限定されているため、人間が普段行うような自由形式の質問応答や、曖昧さを含む問い合わせに対する性能を完全に反映するものではありません。OpenAIはこれを、プログラミングコンテストで高いスコアを出すモデルが必ずしも全てのソフトウェア開発タスクで優れているとは限らない、というアナロジーで説明しています。BrowseCompは不完全ながらも有用な指標と言えるでしょう。
まとめ
BrowseCompは、AIエージェントのウェブブラウジング能力、特に見つけにくい情報を粘り強く、創造的に探索する能力を評価するための、新しく挑戦的なベンチマークです。このベンチマークは、既存の評価手法では測れなかったAIの高度な側面を明らかにし、今後のAI開発における重要な指標となり得ます。OpenAIがBrowseCompをオープンソースとして