はじめに
Future of Life Institute(FLI)が2025年12月、主要AI企業8社の安全性を評価した「AI Safety Index Winter 2025」を公開しました。独立した専門家パネルが6つのドメインで企業を評価し、業界全体の安全性実践の現状と課題を明らかにしています。本稿では、この評価結果をもとに、各社の取り組みと業界が直面する構造的課題について解説します。
参考記事
- タイトル: AI Safety Index – Winter 2025 Edition
- 発行元: Future of Life Institute
- 発行日: 2025年12月
- URL: https://futureoflife.org/ai-safety-index-winter-2025/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
※今夏のレポート

要点
- Future of Life Instituteが8つの主要AI企業を6つのドメイン(リスク評価、現在の害、安全性フレームワーク、存在論的安全性、ガバナンスと説明責任、情報共有)で評価し、Anthropic、OpenAI、Google DeepMindがトップ3となった
- 存在論的安全性(Existential Safety)のドメインでは全企業が低評価を受け、AGI/超知能への明確な制御計画を示せていないことが業界の構造的弱点として指摘された
- トップ3社と他社(xAI、Z.ai、Meta、DeepSeek、Alibaba Cloud)の間には明確な格差が存在し、特にリスク評価、安全性フレームワーク、情報共有の領域で差が顕著である
- 8名の独立AI専門家パネルが評価を実施し、企業ごとに具体的な改善機会を提示している
詳細解説
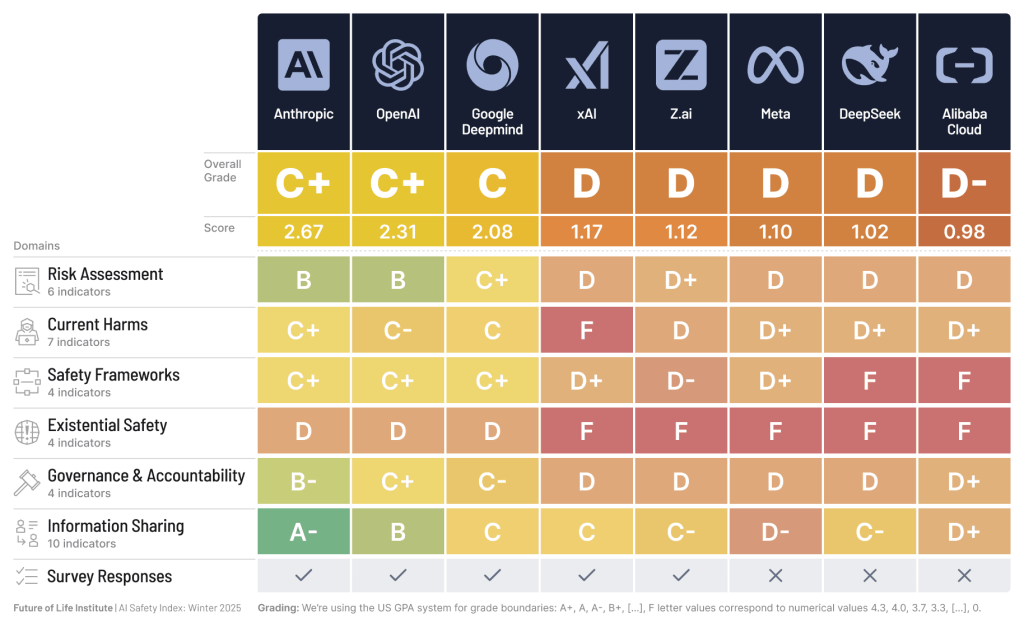
評価対象企業と総合スコア
今回の評価では、Anthropic、OpenAI、Google DeepMind、xAI、Z.ai、Meta、DeepSeek、Alibaba Cloudの8社が対象となりました。Future of Life Instituteによれば、評価は2025年11月8日までに収集された証拠に基づいており、米国のGPAシステム(A=4.0、B=3.0、C=2.0、D=1.0、F=0)を用いて採点されています。
総合評価では、AnthropicがC+(2.67点)で首位、OpenAIが同じくC+(2.31点)で続き、Google DeepMindがC(2.08点)で3位となりました。一方、xAI、Z.ai、Meta、DeepSeek、Alibaba CloudはいずれもD評価(1.0点前後)にとどまっています。
この評価システムでは、絶対的な性能基準に基づいて専門家が各ドメインでA-Fの評価を行い、最終スコアは専門家評価の平均値として算出されます。個別の専門家による評価は機密扱いとなっています。
6つの評価ドメインと指標
評価は以下の6つのドメインで実施されました。
リスク評価(Risk Assessment)
危険な能力評価、人間の能力向上試験、独立レビュー、展開前の外部安全テスト、バグバウンティプログラムなど6つの指標が用いられました。このドメインでは、Anthropicがトップ3社の中でも特に高い評価を受けています。
現在の害(Current Harms)
StanfordのHELMベンチマーク、TrustLLMベンチマーク、Center for AI Safetyベンチマーク、デジタル責任、ファインチューニングからの保護、ウォーターマーキング、ユーザープライバシーなど7つの指標で評価されました。
安全性フレームワーク(Safety Frameworks)
リスク識別、リスク分析・評価、リスク処理、リスクガバナンスの4つの観点から企業の体系的なリスク管理プロセスが評価されています。
存在論的安全性(Existential Safety)
存在論的安全性戦略、内部監視と制御介入、技術的AI安全性研究、外部安全性研究への支援という4つの指標が設定されました。このドメインは業界全体で最も低い評価となっており、構造的な課題として指摘されています。
ガバナンスと説明責任(Governance & Accountability)
企業構造とマンデート、内部告発者保護、内部告発者ポリシーの透明性、ポリシーの質、報告文化などが評価されました。
情報共有(Information Sharing)
技術仕様の透明性、G7広島AIプロセスへの報告、EU AI Act実施規範への参加、重大インシデントの報告、極端なリスクの透明性など10の指標で評価が行われています。
主要な発見事項
報告書では3つの主要な発見が示されています。
第一に、トップパフォーマー(Anthropic、OpenAI、Google DeepMind)とその他の企業の間に明確な格差が存在します。Future of Life Instituteによれば、最も大きな差はリスク評価、安全性フレームワーク、情報共有のドメインで見られ、その原因は限定的な情報開示、体系的な安全プロセスの証拠の弱さ、堅牢な評価実践の不均一な採用にあるとされています。
第二に、存在論的安全性が業界の中核的な構造的弱点となっています。報告書では、評価対象のすべての企業がAGI/超知能に向けて競争を続けているにもかかわらず、人間よりも賢い技術を制御または整合させるための明確な計画を示していないと指摘されています。この領域では、すべての企業が低評価を受けており、最も重大なリスクが事実上対処されていない状況です。
第三に、公的なコミットメントにもかかわらず、企業の安全性実践は新興グローバル基準に届いていません。多くの企業がこれらの基準に部分的に整合しているものの、実装の深さ、具体性、品質は不均一であり、EU AI Act実施規範などのフレームワークが想定する厳密性、測定可能性、透明性には達していないとされています。
評価パネルのStuart Russell教授(カリフォルニア大学バークレー校)は、「AI CEOたちは超人的AIの構築方法を知っていると主張するが、制御を失うことを防ぐ方法を示せる者はいない。制御喪失の年間リスクを原子炉の要件に沿って1億分の1に削減できる証拠を求めているが、代わりに彼らはリスクが10分の1、5分の1、さらには3分の1になる可能性があることを認めており、その数字を正当化することも改善することもできない」と述べています。
評価パネルと評価プロセス
今回の評価は、8名の著名なAI研究者とガバナンス専門家による独立パネルが実施しました。パネルメンバーには、David Krueger氏(モントリオール大学)、Dylan Hadfield-Menell氏(MIT)、Jessica Newman氏(カリフォルニア大学バークレー校)、Sneha Revanur氏(Encode創設者)、Sharon Li氏(ウィスコンシン大学マディソン校)、Stuart Russell氏(カリフォルニア大学バークレー校)、Tegan Maharaj氏(HECモントリオール)、Yi Zeng氏(中国科学院)が含まれます。
データ収集は2025年11月8日まで行われ、モデルカード、研究論文、ベンチマーク結果などの公開情報と、業界の特定の透明性ギャップ(内部告発者保護や外部モデル評価など)に対処するために設計された企業調査への回答を組み合わせています。Anthropic、OpenAI、Google DeepMind、xAI、Z.aiが調査に回答しました。
評価者は企業固有の証拠を検討し、裁量的な重み付けを伴う絶対的な性能基準に基づいてドメインレベルの評価(A-F)を割り当て、書面による正当化と改善推奨事項を提供しました。最終スコアは専門家評価の平均を表しています。
企業別の改善機会
報告書では、各企業に対する具体的な改善提案が示されています。
Anthropic
閾値と安全対策をより具体的で測定可能なものにすること、評価手法と独立性の強化が推奨されています。一方で、AI Safety Index調査への回答による透明性向上、内部告発者ポリシーの詳細共有、国際的および米国州レベルのAI安全性に関するガバナンスおよび立法イニシアチブへの相対的な支援が進展点として評価されました。
OpenAI
安全性フレームワークの閾値を測定可能で実施可能なものにすること、透明性と外部監督の強化、AIによる精神的健康問題への対応強化などが提案されています。進展点としては、より広範なリスクセットをカバーする詳細なリスク評価プロセスの文書化、新しいガバナンス構造(公益法人)が評価されました。
Google DeepMind
リスク評価の厳密性と独立性の強化、閾値とガバナンス構造のより具体的で実行可能なものへの改善、AIによる心理的被害防止への取り組み強化が推奨されています。
その他の企業
その他の企業に関しては、より基本的な改善が求められています。xAIにはリスク評価の幅、厳密性、独立性の改善、Z.aiには完全な安全性フレームワークとガバナンス構造の公開、Metaにはリスク評価と安全性評価の幅と厳密性の改善、DeepSeekとAlibaba Cloudには基礎的な安全性フレームワークとリスク評価プロセスの確立と公開が提案されています。
すべての企業に対する共通の推奨事項として、高レベルの存在論的安全性に関する声明を超えて、明確なトリガー、現実的な閾値、実証された監視および制御メカニズムを備えた具体的で証拠に基づく安全対策を作成すること、AGI/ASIを制御および整合させるための信頼できる計画を提示するか、そのようなシステムを追求する意図がないことを明確にすることが求められています。
業界が直面する構造的課題
この評価結果から、AI業界が直面する構造的な課題が浮き彫りになっています。
特に存在論的安全性の領域では、すべての企業が人間を超える知能を持つシステムの開発に向かっているにもかかわらず、そのようなシステムを安全に制御するための具体的な計画を持っていないという深刻な問題が指摘されています。この状況について、Tegan Maharaj教授(HECモントリオール)は、「2016年に世界最大のテクノロジー企業が広範なデジタル監視を実施し、子供たちに自殺を促し、長期ユーザーに精神病を引き起こすチャットボットを運営すると言われていたら、妄想的な悪夢のように聞こえただろう。しかし、私たちは心配する必要はないと言われている」とコメントしています。
また、トップ企業と他社の格差も重要な課題と考えられます。リスク評価、安全性フレームワーク、情報共有などの領域で見られる差は、業界全体での安全性基準の標準化と底上げが必要であることを示唆しています。
国際的な基準への整合性の問題も指摘されています。EU AI Act実施規範などの新興グローバル基準に対して、企業の実践が十分な深さ、具体性、品質で実装されていないという評価は、規制と実務のギャップを示しています。
これらの課題に対処するためには、企業の自主的な取り組みだけでなく、独立した評価機関による継続的な監視、国際的な基準の確立と実施、より強力な規制フレームワークの構築が必要と考えられます。
まとめ
AI Safety Index Winter 2025は、主要AI企業の安全性実践の現状を包括的に評価し、業界全体が直面する課題を明確にしました。Anthropic、OpenAI、Google DeepMindが相対的に高い評価を受ける一方、存在論的安全性への対応はすべての企業で不十分であり、AGI/超知能時代に向けた準備が整っていない状況が浮き彫りになっています。今後、この評価結果が業界の「安全性への競争」を促進し、より堅牢な安全対策の実装につながることが期待されます。