
はじめに
古代の碑文(ひぶん)は、当時の人々の思考、言語、そして歴史を直接知ることができる貴重な情報源です。しかし、それらを読み解き、現代の私たちが理解できる形にするのは、非常に骨の折れる作業でした。本稿では、Google DeepMindの研究者たちが開発した新しいAIモデル「Aeneas(アイネイアース)」が、この古代碑文研究にどのようなアプローチで迫っているのか、詳しく解説します。

参考文献
- 論文タイトル:Contextualizing ancient texts with generative neural networks
- 発行日:2025年7月23日
- URL:https://www.nature.com/articles/s41586-025-09292-5
Github
- タイトル:Contextualising ancient texts with generative neural networks
- URL:https://github.com/google-deepmind/predictingthepast
- GoogleColab:https://colab.research.google.com/github/google-deepmind/predictingthepast/blob/master/colabs/inference.ipynb
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- 古代碑文の文脈化を支援する生成AIモデル: Aeneasは、ローマ時代のラテン語碑文の文脈(コンテクスト)を理解し、研究者が碑文をより広く、深く解釈できるよう支援する生成ニューラルネットワーク(generative neural network)。
- 「パラレル(類似碑文)」の発見で歴史家を支援: Aeneasの最大の強みは、「パラレル」、つまり碑文と共有のフレーズ、機能、文化的な設定を持つ類似の碑文を特定する能力である。これにより、歴史家は特定の碑文をより広範な歴史的枠組みの中に位置づけることができる。
- 複数の情報を統合する「マルチモーダル」対応: 碑文のテキスト情報だけでなく、碑文の画像からも情報を活用するマルチモーダル(multimodal)な入力に対応している。これにより、テキストだけでは得られない物理的な特徴(形、図像、材質など)も考慮した文脈化が可能になる。
- 「任意長のテキスト復元」を実現: 欠損したテキストの長さが不明な場合(任意長)でも、その部分を復元できるのはAeneasが初めてである。これは実際の碑文によく見られる、どれくらいの文字が失われているか分からない状態に対応できるため、非常に実用的である。
- 歴史家の研究を大幅に効率化し、精度を向上: 歴史家がAeneasの提示するパラレルを使用することで、研究の出発点として90%のケースで有用性を感じ、主要な作業における自信が44%向上しました。また、復元や地理的帰属(どこで書かれたか)のタスクでは、Aeneasと歴史家が協力することで、人間単独やAI単独よりも優れた結果を出している。
詳細解説
それでは、論文の各セクションを順に解説します。
Abstract (要旨)
この論文では、人間と文字の歴史が密接に結びついていること、特に碑文が古代文明の洞察を直接提供する手段であることを強調しています。歴史家は、共有のフレーズや文化的な背景を持つ碑文(パラレル)を特定することで、碑文の文脈を理解し、復元、地理的・年代的帰属といった重要なタスクを実行します。
しかし、従来のデジタル手法では、文字通りの一致や狭い歴史的範囲に限定されていました。そこで本論文では、古代碑文の文脈化のための生成ニューラルネットワーク「Aeneas」を紹介しています。Aeneasはテキストと文脈のパラレルを検索し、画像入力も活用し、任意長のテキスト復元を可能にし、主要なタスクで最先端の結果を達成しました。
その効果を評価するため、歴史家と協力して大規模な研究が行われ、Aeneasが検索したパラレルが90%のケースで有用な研究の出発点となり、歴史家の自信を44%向上させることが示されました。復元と地理的帰属のタスクでは、Aeneasと歴史家が協力することで、人間単独やAI単独を上回る結果を出しています。年代推定では、実際の年代から平均13年の誤差という、高い精度を達成しました。
Main (本文)
ローマ世界は「文字の世界」であり、公共空間にも私的な場所にも碑文が遍在していました。これらの碑文は、テキストだけでなく、その物理的な形態や配置によっても意味を持つとされています。毎年約1,500もの新しいラテン語碑文が発見されており、皇帝の布告から奴隷の墓碑銘まで、広大なローマ帝国の文化的・言語的側面に関する貴重な情報が保存されています。
しかし、碑文学という学問は、時間の経過による文字や単語、あるいはセクション全体の欠損、人々の高い移動性、明示的な日付の欠如、ラテン語碑文に特有の略語の多用など、多くの課題に直面しています。こうした課題から生じるテキストの復元、地理的・年代的帰属といったタスクは、専門の歴史家が碑文をその広い言語的・歴史的背景の中に位置づけることに依存しています。この文脈化の鍵となる方法は、類似の単語、フレーズ、定型句、あるいはより広範な社会的・言語的・文化的類似性を持つ「パラレル」碑文を特定することです。
古代社会の広範なコミュニケーションネットワークを考えると、こうしたつながりは地理的・時間的に大きく離れた場所にも及ぶことがあります。碑文をこのパラレルテキストのネットワークと結びつけ、より広範な碑文文化の中に組み込むことで、歴史家はその解釈を洗練させ、憶測や主観的な仮説、孤立した読み方に頼る度合いを減らすことができます。
しかし、この文脈化のプロセスは時間がかかり、労力を要し、高度に専門的です。数百ものパラレル碑文と比較検討する必要があり、並外れた博識、長期的な知識習得、広範な図書館や博物館のコレクションへのアクセス、そして参考書への繰り返しの参照(多くの場合、骨の折れる手動検索や文字列照合技術を使用)が求められます。その結果、研究者は地域的・年代的な専門化を進める傾向があり、それが大規模な碑文学的・歴史的つながりの特定を制限していました。この研究では、生成AIを用いて、古代史における文脈化という重要な課題に取り組み、歴史家が研究をより確かなものにするための支援を行っています。

近年、古代言語の研究は機械学習システムによって大きく進歩しており、デジタル化から解読まで幅広いタスクで成果を上げています。この勢いに乗り、碑文の文脈化という課題を機械学習の問題として定式化し、解決に取り組んでいます。 この研究は、さらに2つの重要な補完機能を拡張しています。まず、現代の碑文学ではテキスト内容だけでなく物理的特徴(形、図像、材質)も考慮されますが、AIアプローチはほとんどテキスト中心でした。碑文をその広範な碑文風景の中に完全に位置づけるためには、テキストと視覚データを組み合わせたマルチモーダルモデルの統合が不可欠です。次に、現在の機械学習手法は、長さが既知のギャップ(欠損)の復元には成功していましたが、任意長(長さが不明)の復元という課題は、古代言語ではまだ解決されていませんでした。Aeneasは文脈化を優先し、マルチモーダリティを統合し、高度なテキスト復元技術を用いることで、碑文研究をいかに変革し、ローマ世界の書記文化の理解を深めるかを示しています。
Contextualizing the past (過去を文脈化する)
この研究では、ラテン語碑文の文脈化のためのマルチモーダルな生成ニューラルネットワーク「Aeneas」を提示しています。Aeneasは、復元、地理的帰属、年代的帰属という3つの主要な碑文学タスクにおいて最先端の性能を確立しました。Aeneasは文脈化メカニズムを組み込んでおり、歴史家が研究を裏付ける歴史的に根拠のあるテキスト的および文脈的な碑文パラレルのリストを提供します。碑文の物質的な側面に関するより広い範囲の情報を捉えるため、Aeneasは画像と転写されたテキストの両方を入力として統合し、古代テキストの任意長復元を生成する最初のモデルです。
Aeneasという名前は、ギリシャ・ローマ神話の放浪する英雄アイネイアースにインスパイアされています。トロイから地中海を横断し、将来のローマ建国の地を求めて旅したアイネイアースのように、このモデルは歴史研究の根拠となる碑文のパラレルを発見し、過去を現在と結びつけようとします。この研究は、AIがいかに歴史家がこれまで特定できなかったパラレルを検出し、碑文学タスクに取り組む自信を高めるのに役立つかを示しています。広範な歴史家とAIの共同評価を実施することで、以前のアプローチと比較したこのモデルの協調的な性能をさらに示しました。最後に、Aeneasが有名なローマの記念碑的碑文である『神君アウグストゥスの業績録』(Res Gestae Divi Augusti)の研究にどのように統合されているかを示すケーススタディを開発することで、歴史的ワークフローにおけるモデルの実際の貢献を例示しています。
Integrating Latin epigraphic data (ラテン碑文データの統合)
ラテン語は、最も広範に研究されている古代言語の一つであり、計算言語学研究や関連コンペティションの焦点となることが多いです。古代世界における碑文の証拠の中で最も豊富にもかかわらず、特にラテン語碑文に焦点を当てた機械学習研究は比較的少ないのが現状です。このため、本研究はラテン語碑文に焦点を当てることで、学術的な影響力を持つ学際的な研究の貴重な機会を捉えています。
Aeneasの訓練には、最も広範なラテン語碑文学データベースであるEpigraphic Database Roma (EDR)、Epigraphic Database Heidelberg (EDH)、およびEpigraphik-Datenbank Clauss-Slaby ETL (EDCS_ETL) の3つを組み合わせて、包括的なコーパスを構築しました。これらのコーパスを調和させるため、メタデータの標準化、曖昧さの解消、そしてユニークなTrismegistos識別子(ID)を用いて機械可読形式にテキストを処理する複雑なパイプラインを開発しました。また、利用可能な場合はこれらのデータセットから碑文の画像も取得しています。
この処理されたコーパスをLatin Epigraphic Dataset(LED)と呼称し、紀元前7世紀から紀元後8世紀までの碑文を網羅しています。地理的範囲は、西のブリタニア(現代のイギリス)やルシタニア(ポルトガル)から、東のエジプト(Aegyptus)やメソポタミア(Mesopotamia)にまで及びます。最終的なLEDは176,861の碑文(合計1,600万文字)から構成され、そのほとんどが損傷したセクションを含んでいます。さらに、碑文の5%に相当する画像も取得できました。
Contextualizing inscriptions with Aeneas (Aeneasによる碑文の文脈化)
Aeneasは、碑文の画像とそのテキストの転写(文字起こし)を入力として受け取ります。その効率的なアーキテクチャは、文字のみで動作し、以前のアプローチが必要としていた単語レベルの表現は不要です。モデルを誘導するために、2つの特殊文字が使用されます。「-」は復元する文字数が既知であることを示し、「#」は不明であることを示します。入力画像は、浅い視覚ニューラルネットワークを通して処理されます。入力テキストは、モデルの核心である「トルソ(torso)」によって処理されます。トルソは、相対的な位置をエンコーディングするロータリーエンベディング(rotary embeddings)で拡張された、深くて狭いT5トランスフォーマー(transformer)であり、テキスト情報を効果的に捉えます。
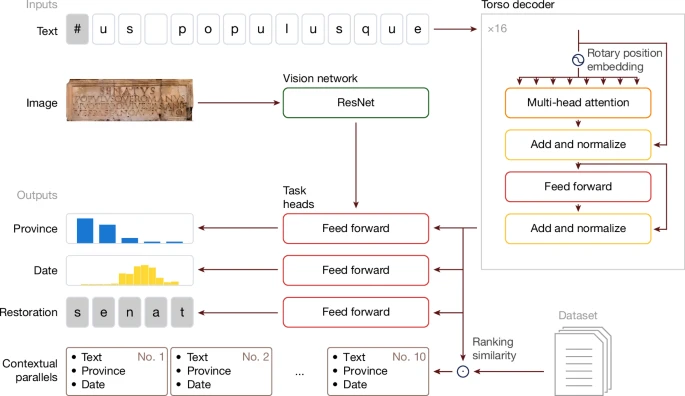
トランスフォーマーとは、自然言語処理の分野で非常に成功しているニューラルネットワークのアーキテクチャです。特にT5は、テキストからテキストへの変換を統一的に扱うモデルで、翻訳や要約など様々なタスクに使われます。ここでいう「トルソ」は、そのT5のデコーダー部分を指し、与えられた入力から情報を解釈・生成する役割を担います。
トルソと視覚ネットワークの出力は、それぞれ3つの主要な碑文学タスク(復元、地理的帰属、年代的帰属)に対応する専門のニューラルネットワーク「ヘッド(heads)」に送られます。文字数が不明な欠損(ラクーナエ)の復元を処理するために、任意のデコードステップで1文字以上が欠損しているかどうかを予測するための補助ヘッドが導入されています。地理的帰属タスクの場合、Aeneasは62のローマ属州の中から対象碑文を分類する予測分布を出力します。年代的帰属タスクの場合、Aeneasは年代を10年単位で推定します。テキスト復元タスクの場合、Aeneasはビームサーチ(beam search)という探索手法を用いて、確率と長さによってランク付けされた複数の復元仮説を生成します。ビームサーチとは、AIが次に来る文字や単語を予測する際に、最も可能性の高い候補を複数同時に探索していくことで、より良い結果を見つけるための手法です。Aeneasの各タスクの予測には、モデルの出力に最も影響を与えたテキストおよび画像の特徴を特定するセーリエンスマップ(saliency maps)が伴います。セーリエンスマップは、AIがどの部分に注目して判断したのかを可視化する技術で、AIの判断根拠を理解するのに役立ちます。
なお、地理的帰属ヘッドのみが視覚ネットワークからの追加入力を統合しており、復元および年代的帰属タスクでは視覚モダリティ(画像情報)は使用されていません。これは、復元タスクではテキストの一部が人工的にマスキングされているため、画像情報があるとモデルが隠された文字を視覚的な手がかりから推測してしまい、タスクの整合性が損なわれる可能性があるためです。年代推定タスクでは、実験の結果、視覚モダリティを使用しても性能に有意な改善が見られなかったため、省略されました。これは、モデルがすでにほぼ最適な結果を達成していたためと考えられます。
碑文の文脈化のプロセスについては、AeneasはLEDの訓練データセットから最も関連性の高い碑文のパラレルリストを検索します。このプロセスは、歴史的に豊かな埋め込み(embeddings)に依存しています。埋め込みとは、テキストの歴史的および言語的パターンを捉える数学的表現であり、意味と文脈の両方に基づいて比較することを可能にします。Aeneasは、トルソとヘッドの間で生成された中間表現を統合し、統一された埋め込みベクトルを生成します。
従来のテキスト埋め込みとは異なり、この表現は3つの主要な碑文学タスクから派生した歴史的文脈で豊かになっています。この設計により、モデルは従来のあいまいな文字列照合方法を凌駕し、関連する場所や時代、関連概念、同義語、定型句のバリエーション、類似の碑文慣行など、豊富な碑文学的パラレルを含めることができます。最後に、Aeneasはコサイン類似度(cosine similarity)を用いて、入力テキストに対するすべての潜在的なパラレルをスコア付けし、関連性に基づいてランク付けします。コサイン類似度とは、ベクトル空間における2つのベクトルの向きの類似度を測る指標で、値が高いほど類似性が高いと判断されます。このランク付けされたリストは、地理的および年代的メタデータとともに専門家(歴史家)に提示され、歴史研究の貴重な出発点となります。
Contributing to historical research (歴史研究への貢献)
Aeneasが歴史研究の基礎ツールとして持つ可能性を評価するため、史上最大規模の「古代史家とAI」共同研究を含む、人間中心の包括的な評価が実施されました。先行研究における碑文の復元、配置、年代推定に関する確立された指標を組み込むとともに、Aeneasの文脈化メカニズムの影響を評価するための新しい測定方法も導入されました。このアプローチにより、Aeneasと人間の協力性能が定量化され、歴史家がAeneasのパラレルを用いて3つの碑文学タスクにおける予測を裏付ける際の主観的な経験も評価されました。さらに、地理的および年代的帰属タスクにおける人間の専門家とAIの協力性能も測定されました。最後に、自動化された指標を用いてAeneasが以前の最先端技術をいかに上回るかを示しています。
Metrics and synergistic evaluation (評価指標と相乗効果評価)
異なるアプローチの効果を測定するため、本研究では以前の最先端モデルであるIthaca によって導入された評価指標を採用しています。復元タスクでは、碑文が受けた損傷をシミュレートするために、テキストセグメントを人工的に破損させました。歴史家は1〜10文字の復元を求められ、これは実験設定と時間的制約を考慮した現実的な範囲です。対照的に、Aeneasは目標の文字長を知らされずに1〜20文字の復元に挑戦しました。Aeneasの性能は、ラテン語と任意長の欠損復元に対応するためにLEDで再学習されたIthacaと比較されました。歴史家とモデルは、対象碑文の年代推定と地理的配置もタスクとして与えられました。
復元性能は、文字エラー率(Character Error Rate; CER)とトップ20の精度を用いて測定されました。CERは、予測されたテキストが元のテキストとどれだけ異なるかを示す指標で、低いほど良い結果です。地理的帰属については、62のローマ属州の中からトップ1(最も正確な予測)およびトップ3の精度を測定しました。年代推定については、予測された平均年代と実際の年代範囲との距離を計算しました。Aeneasの文脈化メカニズムが歴史研究方法に与える影響を評価するため、Aeneasが検索したパラレルが、評価対象の歴史家によって主要なタスクに「関連性があり有用」とどれだけ受け入れられたかを評価しました。最後に、従来の歴史的手法を用いた碑文学タスクの固有の難易度を推定するために、自動化された「オノマスティックス(onomastics)ベースライン」を導入しました。オノマスティックスとは固有名詞学のことで、このベースラインは、既知の碑文から個人名に基づいて地理的および年代的指標を推測する歴史家の手法をシミュレートしています。
Evaluating contextualization impact (文脈化の影響評価)
「古代史家とAI」の研究には、修士課程の学生から教授まで、碑文学の専門知識を持つ23名の参加者が参加し、時間の制約の下で実際の研究ワークフローをシミュレートした実験にAeneasと協力して取り組みました。
評価は3つの段階に分かれています。各段階で、参加者はLEDテストセットの60の碑文のサブセットから抽出された一連の碑文の復元、年代推定、地理的配置のタスクを与えられました。ワークフローを支援するため、歴史家にはLED訓練セットへのアクセスが提供されました。これには141,000の碑文とそのメタデータ(年代と書かれた場所)が含まれており、手動でパラレルテキストを検索し、タスク完了に有用だと感じた碑文を記録することができました。ステージ1では、各歴史家が5つの対象碑文を与えられ、3つの碑文学タスクにおける単独の性能を評価し、ベースラインを確立しました。ステージ2では、各対象碑文について、歴史家はAeneasがLED訓練セットから検索した10のパラレルを与えられ、再度タスクを完了するよう求められました。この段階は、文脈的パラレルが歴史家の作業仮説にどのように影響するかを測定するために重要です。歴史家は、必要に応じて手動で検索したパラレルのリストを修正し、Aeneasが検索した有用なパラレルを組み込むよう求められました。ステージ3では、歴史家は対象碑文に対するAeneasの復元と帰属予測を与えられ、歴史家の予測に対するそれらの影響を特定しました。
この評価の結果、歴史家はAeneasが提供した平均1.5の追加のパラレル碑文を自身の手動選択したパラレルに組み込んだことが示されました。アンケートでは、歴史家はAeneasによって生成されたパラレルが対象碑文の文脈的理解と解釈を向上させたと同意しました。より具体的には、Aeneasのパラレルが提供された場合、歴史家の75%がそれが歴史的探究の出発点として役立つと報告しました。Aeneasの3つの碑文学タスクの予測も含まれた場合、この割合は90%に増加しました。さらに、Aeneasのパラレルは歴史家の自信を平均23%高め、Aeneasの予測も利用可能だった場合はさらに21%の増加がありました。これらの数値は、Aeneasが検索したパラレルが歴史家のワークフローにおいて重要な役割を果たすことを効果的に示しています。
定性的なフィードバックも収集され、歴史家はAeneasの文脈化メカニズムが研究を加速し、関連するパラレルの範囲を拡大する価値を一貫して強調しました。例えば、ある歴史家は「Aeneasが検索したパラレルは、私の碑文に対する認識を完全に変えました。復元と年代特定の両方において、非常に重要な詳細を見落としていたことに気づきました」と述べています。また、「Aeneasは、並行して行われた碑文の助けが、仲間の兵士が碑文を立てる種類の碑文を理解するのに非常に役立つことを示しました。一方、私自身の検索はノリクムからの碑文に限定されてしまいました。[Aeneasは]素晴らしいパラレルツールです」というコメントもありました。最後に、研究のスピードと効率へのAeneasの影響が繰り返し強調されました。例えば、「Aeneasが検索したパラレルは、私の歴史的焦点と、それらを追跡するのに数日ではなく15分で済みました。もしこれらの碑文の読み取りに基づいて歴史的解釈をするなら、今はパラレルを探すのではなく、研究課題を書いて構成するのに数日を費やせるでしょう」といった声がありました。
3つの碑文学タスク全体での精度という点では、評価対象の歴史家とAeneasモデルとの相乗効果を強調しています。復元タスクでは、歴史家単独ではCERが39%でしたが、Aeneasのパラレルの助けを得て33%に改善し、Aeneasの予測入力も加わると21%にまで低下し、モデル単独の性能を上回りました。これらの結果は、歴史家がAeneasのパラレルと予測を使用すると、その性能が著しく向上することを示唆しています。地理的帰属タスクでは、歴史家は単独でトップ1精度27%、トップ3精度42%を達成しました。Aeneasが検索したパラレルと組み合わせると、両方の指標で35%の改善が見られました。Aeneasの予測も利用可能だった場合、トップ1精度は68%に向上し、これは152%の増加であり、Aeneas単独の性能を上回りました。年代推定精度では、歴史家は平均して実際の年代範囲から31.3年という誤差を記録しましたが、これはオノマスティックスベースラインとほぼ一致します。Aeneasの文脈化サポートにより32%改善し、Aeneasの予測が提供された場合にはさらに32%改善され、実際の年代範囲からの距離は14.1年に短縮され、Aeneasの12.8年という性能に近づきました。これらの結果は、Aeneasの文脈化メカニズムが歴史的探究の出発点となり、歴史家の自信を高め、手動で潜在的なテキストの類推リストを作成するのではなく、予測の評価に集中することを可能にすることを示しています。最も大きな相乗効果は、検索されたパラレルからの文脈情報がAeneasの予測仮説とともに提供されたときに観察されました。
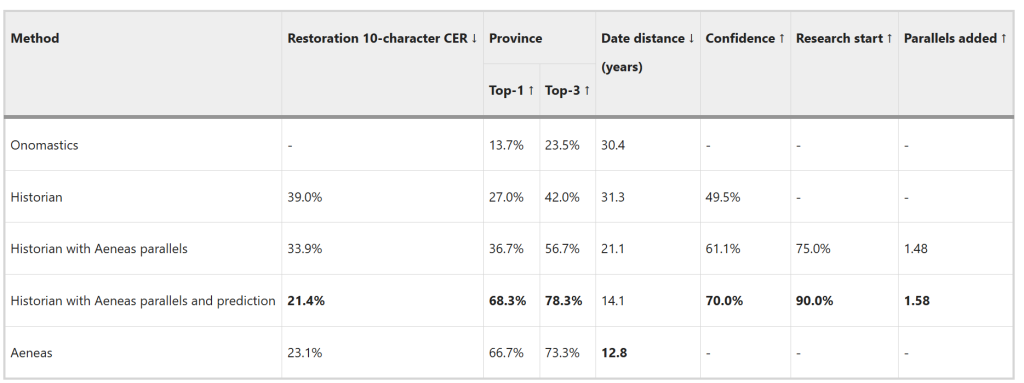
Breaking new ground in epigraphy (碑文学における新たな地平を開く)
IthacaとAeneasの性能比較について、以下に示されているすべての評価において、AeneasはオノマスティックスベースラインとIthacaの両方を一貫して上回り、Aeneasのアーキテクチャの有効性を示しています。復元の文字長が提供された場合、AeneasはCER 40.5%、トップ20予測精度46.5%を達成しました。しかし、Aeneasは未知の長さの復元を処理するように設計されており、これは碑文が広範囲に損傷し、欠損文字数が不明な実際のアプリケーションにとって非常に重要です。この追加された複雑さにもかかわらず、未知の長さのセグメントのCERはわずか15%の増加にとどまりました。地理的帰属の場合、Aeneasは正確なローマ属州の起源を72%の精度で予測しました。このタスクには画像を入力として組み込むマルチモーダルな側面が含まれており、テキストのみのモダリティよりも優れた視覚モダリティの重要性を浮き彫りにしています。年代的帰属タスクでは、Aeneasはテキストを実際の年代範囲から平均13年、中央値で0年以内で年代推定しました。AeneasとIthacaの間で報告された結果も統計的に有意です。

Evaluating Aeneas in the real world (現実世界でのAeneasの評価)
Aeneasが歴史的ワークフローにどのように統合され、伝統的な方法と最先端の生成モデルを結びつけるかを例示するため、この研究では、古代世界で最も重要な碑文の一つである『モニュメンタム・アンキュラヌム』(Monumentum Ancyranum)を分析しました。これはアンキュラ(現代のアンカラ)にあるローマとアウグストゥスの神殿の壁に刻まれたもので、『神君アウグストゥスの業績録』(Res Gestae Divi Augusti; RGDA)のテキストを保存しています。これは「ラテン語碑文の女王」と称され、初代ローマ皇帝アウグストゥスが自ら著した生涯の記録です。ローマで著され、帝国中に複製されました(現代のトルコには碑文の複製が残っており、『モニュメンタム・アンキュラヌム』が最も完全です)。アウグストゥスの業績、帝国内外への影響、彼が主導した記念碑的な変革について詳細に記されており、アウグストゥス時代のローマにおける皇帝のイデオロギーを理解するための基本的な史料となっています。
Grounding the Res Gestae Divi Augusti (『神君アウグストゥスの業績録』の基礎付け)
この研究チームの専門歴史家が、Aeneasの予測とパラレルを『神君アウグストゥスの業績録』(RGDA)について検証し、モデルと協力して作業しました。結果として、Aeneasのテキスト的および文脈的パラレル、セーリエンスマップ、そしてこのテキストの帰属に関する予測の分析に焦点を当てています。目的は、この碑文の年代と出所に関する複雑さにAeneasがどのように対応するかを検討することでした。
最初の発見は、AeneasによるRGDA全文の年代帰属が、一般的な学術的仮説を反映していることでした。分布は紀元前10年から紀元前1年頃に modest なピークを示し、紀元後10年から20年頃にはより高く、自信のあるピークを示しました [Fig. 3a]。RGDAの各章に対するモデルの予測を詳しく調べると、Aeneasがテキストに頻繁に言及されている執政官の年代(組成とは無関係)に惑わされていないことが明らかになりました。代わりに、モデルの年代予測は、きめ細かい言語情報によって駆動されているようです。
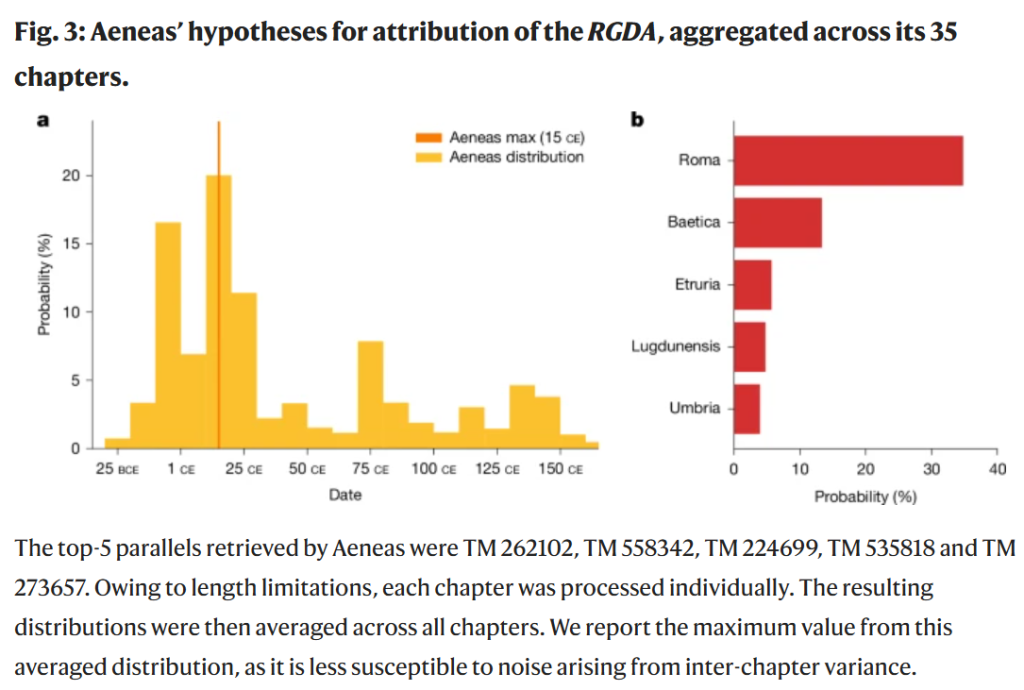
実際、各RGDA章に対するAeneasのセーリエンスマップを詳しく見ると、Aeneasが年代的に重要な特徴に非常に敏感であることがわかります。例えば、古風なラテン語の正書法、言語的定型句、歴史的に特定の制度や記念碑、人名などが挙げられます。例えば、冒頭の段落では、Aeneasのセーリエンスマップは「aheneis」という単語のスペルを強調していますが、これは通常、紀元後1世紀になって初めて「aeneis」に変化します。Aeneasはまた、歴史的に特定のラテン語の制度も拾い上げています。例えば、「princeps iuventutis」(第14章)という称号は、紀元前5年にアウグストゥスの孫であるガイウス・カエサルに初めて与えられました。記念碑も年代を示す指標として機能します。例えば、紀元前13年にアウグストゥスのローマ帰還を祝うために元老院によって建立された「アウグストゥス平和の祭壇」が、第12章のAeneasのセーリエンスマップにおける関心領域として現れています。
特に注目すべきは、第32章の多くの単語がセーリエンスマップで強調されていることです。ここには、特定の年代的文脈に属する多くの独特な非ローマ人名が登場します。訓練された歴史家がこれらの特徴に注目するように、Aeneasのセーリエンスマップは、モデルがそのようなマーカーに注意を払っていることを示しています。
これらの観察は、この碑文に対するAeneasのパラレル分析によってさらに裏付けられています。トップ5のパラレルはすべてローマで構成されたテキストであり、実際の碑文の地理的発見場所は多様であるにもかかわらずです。その中には、紀元後19年に元老院がゲルマニクス(ティベリウスの相続人)を称えるために発行したヴァレリウス・アウレリウス法(Valerian Aurelian law)の2つの碑文コピーが含まれています。ローマで見つかった現存する断片と法令のスペイン語のコピーは、RGDAのAeneasの完全なパラレルリストに現れています。
元老院がアウグストゥスの家族を称える法令で使用した言語は、アウグストゥス時代の帝国イデオロギーの特徴を採用しており、RGDAと強い言語的および文脈的類似性を示しています。Aeneasが特定した他のテキストは、RGDAと同様に古風な正書法を使用する傾向があり(ローマの公共法務文書の特徴)、半分弱は元老院または皇帝によって発行された公共のテキストです。これは、Aeneasが特定したパラレル碑文の地理的産地(ローマ、トレント、バエティカ、エルコラーノ)が、帝国政治的言説の表現としての共通機能に次ぐものであることを示唆しています。この共通性はAeneasのパラレルによって捉えられ、それらの類似したテキスト的および文脈的特徴を説明しています。これらのテキストの碑文学的伝播は、ローマを超えたローマ帝国イデオロギーの広がりを例証しています。
要するに、このケーススタディは、歴史的ワークフローにおけるアシストツールとしてのAeneasの能力を示しています。その結果は、RGDAに関する世界トップクラスの専門家の洞察とよく一致しており、パラレル、帰属、そしてAeneasのセーリエンスマップの粒度を指摘しています。通時的および言語的パターンを体系的に分析することで、Aeneasは従来の歴史的年代推定およびパラレル発見方法をサポートするだけでなく補完し、詳細な歴史分析のための変革的なツールを提供します。
Retrieving parallels across the Roman Empire (ローマ帝国全土からのパラレル検索)
Aeneasの文脈化メカニズムの効果を、よく証明されたタイプの代表的な碑文でもテストしました。ケーススタディとして、モゴンティアクム(マインツ)の奉納祭壇『CIL XIII, 6665』を選択しました。これは、紀元後211年に「beneficiarius consularis」(執政官補佐官)のルキウス・マイオリウス・コギタトゥス(Lucius Maiorius Cogitatus)によって、「Deae Aufaniae」(アウファニア女神)と「Tutelae loci」(土地の守護神)に捧げられたもので、西部属州における一般的な軍事的な信仰慣習を反映しています。
Aeneasの予測は、この碑文をより広範な碑文学的習慣の中に適切に位置づけました。年代推定は紀元後214年(期待される範囲内)で、地理的帰属はゲルマニア・スペリオル(正解)に正しく配置され、関連する代替地としてゲルマニア・インフェリオルとパンノニアも示されました。これらは歴史的期待とよく一致しています。セーリエンスマップは、執政官の年代を示す定型句と「Deae Aufaniae」への呼びかけを強調しており、Aeneasが歴史家が年代と出所の診断マーカーとして認識する詳細に注目していることを示しています。モデルはまた、損傷したテキストシーケンスを文脈的に適切な予測で効果的に復元し、そのニュアンスのある碑文学的推論能力を示しています。
さらに注目すべきは、Aeneasがこのテキストに対して特定した最上位のパラレルです。それは、同じマインツの場所の近くで発見された、紀元後197年に「beneficiarius」のイウリウス・ベラトル(Iulius Bellator)によって奉納された別の奉納祭壇です。この祭壇は、コギタトゥスの奉納碑文と稀なテキスト定型句と同一の図像タイプを共有しており、後の碑文が前の碑文から直接影響を受けたという仮説を裏付けています。Aeneasは、このパラレルに加えて、ゲルマニアとパンノニアからの他の碑文も検索しました。これらの碑文はすべて、相互に関連する碑文学的、歴史的、言語的伝統を反映しています。Aeneasは、これらの石の考古学的文脈や空間的つながりに関する以前の知識を持っていないにもかかわらず(この情報はLED訓練データにはありません)、それらの間の微妙だが意味のある文脈的関係を認識することができます。
従来のテキスト照合アプローチでは、間接的な言語的または歴史的つながりを見逃す可能性がありますが、Aeneasはそれを認識できるのです。考古学的知識を統合できる歴史家によるアシストツールとして使用される場合、Aeneasはローマ属州全体における宗教的、言語的、歴史的ダイナミクスをより堅牢で広範に分析することを支援します。
Conclusions (結論)
Aeneasは、古代テキスト研究におけるAIの統合において飛躍的な進歩を示しています。これは、重要な文脈化プロセスに注意深く設計されたメカニズムを導入し、歴史家がこれまで隠されていたかもしれない大規模で深遠な碑文学的および歴史的つながりを捉えることを可能にします。Aeneasのアーキテクチャは、以前の最先端モデルを凌駕し、マルチモーダルな機能を提供し、未知の長さのテキストシーケンスの復元を可能にし、また他の古代言語や書かれた媒体(パピルス、写本、貨幣など)にも適応できます。これらの機能は、テキスト的および文脈的パラレルでデータセットを拡張したり、欠損値の仮説を提供したりする可能性、さらに大規模な対話型言語モデルを強化するためのモジュールコンポーネントとしての役割を強調しています。
検討されたケーススタディは、碑文学研究におけるAeneasの専門AI支援ツールとしての信頼性を示しています。『神君アウグストゥスの業績録』(RGDA)の調査では、この碑文の構成上の複雑さを処理するAeneasの能力が試され、マインツのコギタトゥスの奉納祭壇の分析では、Aeneasが緻密な通時的および言語的パターンを体系的に追跡する能力が示されました。どちらの事例においても、Aeneasは関連する碑文学的パラレルを活用し、学術的仮説に合致する正確な予測を定量的に生成しました。
これらのケーススタディは、多様な碑文学的文脈におけるAeneasの汎用性を強調しています。帝国の記念碑であろうと地方の奉納碑文であろうと、Aeneasは碑文学者の分析プロセスを反映し、伝統的な歴史的方法論を補完し、正確で意味のある洞察を生み出します。これらの発見は、広範な歴史家とAIの共同評価の結果によって裏付けられており、歴史家はAeneasが研究ワークフローにシームレスに統合され、歴史的探究のための変革的な助けを提供できることを確認しました。歴史家が研究にAeneasを使用するための公開インターフェースは、ウェブサイトでも利用可能です。結論として、Aeneasは人文科学と科学の相互に豊かな結びつきの中で、人間の専門家とAIの協力能力を具体的に向上させます。
Methods (方法)
このセクションでは、Aeneasの開発と評価に関する技術的および実践的な詳細が説明されています。
Previous work (先行研究)
近年の機械学習と古代言語の研究は、デジタル化の進展(テキスト、メタデータ、古代の書かれた証拠の画像の標準化されたデータセットの作成)、機械学習アーキテクチャの進歩(例:Transformer)、および計算能力の向上によって著しい勢いを得ています。この進歩は、多くの言語、文字、タスクにわたり、幅広く文書化されています。
復元に関する研究は、多数の機械学習手法、モダリティ、古代の書かれた証拠(楔形文字の碑文、古代ギリシャ語、線文字B、ヘブライ語、古代中国語、インダス文字、古チャム文字、甲骨文字、コプト語のパピルス、ヘブライ語、古代ギリシャ語、古朝鮮語の写本、古代水書、タミル語)を包含しています。Aeneasと最も密接に関連する取り組みの1つは、マルチモーダルな古代中国の表意文字復元に関する研究 です。ただし、このアプローチをラテン語碑文に再現するには、既存のデータセットの品質と注釈の一貫性が課題となります。また、この方法は単一の表意文字の再構築に限定されており、より広範な碑文学タスクには及びません。復元タスクにおける人間の性能評価という点では、Assael et al. が、現実世界の設定で人間とAIの共同性能を測定する最初の取り組みであり、その評価フレームワークはその後の研究 で採用されています。
未知のテキスト復元の課題については、主にShen et al. によって取り組まれてきましたが、彼らの古代言語への応用は、既知の復元長ベンチマークを使用しています。
古代テキストの地理的および年代的帰属に関する研究はより一般的ではなく、本研究の知る限りでは、Assael et al. のみが古代ギリシャ語碑文の復元、年代推定、地理的配置の3つのタスクをまとめて取り組んでいます。年代推定に関する他の注目すべき取り組みとしては、カンナダ語碑文、アラビア語写本、コプト語パピルス、古代中国語写本、楔形文字粘土板、甲骨文字、朝鮮漢字、ギリシャ語パピルス に関するものがあります。地理的帰属に関する他の唯一の研究は、ギリシャ文学テキストに関するもの です。碑文の発見場所がその書かれた場所を示すことが多い一方で、古代や中世に移動された可能性のある物品や、近世の収集習慣、不法な骨董品取引などを考慮すると、地理的帰属は重要になります。
ラテン語に関しては、最近の取り組みではラテン語文学証拠に焦点を当て、異文化間の相互参照、品詞タグ付け、翻訳、著者帰属、文学テキスト復元 など、さまざまなタスクに取り組んでいます。しかし、大規模なラテン語碑文学データセットが存在し、その多くがEpiDoc XMLエンコーディングのゴールドスタンダード を使用し、碑文の画像を含んでいるにもかかわらず、機械学習技術をラテン語碑文学に適用しようとする研究はほとんどありません。初期の取り組みとしては、Vindolandaのスタイラスタブレットに関する研究 があり、文字認識のための画像処理とパターン認識パイプラインの開発を試みています。より最近では、不十分に標準化されたEDCS_ETLデータセットからラテン語碑文のタイプを自動的に識別しラベル付けするための分類器を開発する研究があります。これは、より豊富に注釈付けされたEDHデータセットから学習したパターンを使用しています。また、テキスト検出方法を適用して、ラテン語碑文画像の広範なデータセット全体で文字をセグメント化し、文字を分析して文字切断工房を特定する研究も行われています。
Latin Epigraphic Dataset (LED) (ラテン碑文データセット (LED))
Dataset generation (データセット生成)
LEDを作成するため、EDR、EDH、およびEDCS_ETLデータベースを処理し、これまでで最大の機械可読ラテン語碑文データセットを構築しました [36, Extended Data Table 1]。これらのデータベースは、様々なローマ属州や歴史的時代の碑文を収集しており、LEDの多様性と時間的範囲を向上させています。すべてのデータベースは、Creative Commons Attribution 4.0ライセンスの下でZenodo(EU資金提供研究成果のオープンリポジトリ)を通じて公開されています。LEDデータセット全体の一貫性を確保するため、日付と歴史的時代に関するすべてのメタデータを標準化し、紀元前800年から紀元後800年の範囲の数値に変換しました。この範囲外の碑文は除外されました。EDR、EDH、およびEDCS_ETLから取得した属州名も標準化され、統合されました。
テキストを機械可読にするため、フィルタリングルールセットを適用して、人間の注釈を体系的に処理しました。歴史家の碑文学的注釈(ライデン規則)は、元の碑文テキストに最も近いバージョンを保持するために、削除または正規化されました。ラテン語の略語は未解決のままにされましたが、通時的、地域的、または階層的理由による代替スペル(例: bixit と vixit )を示す単語形式は、モデルがその碑文学的、地理的、または年代的特定のバリエーションを学習できるように保存されました。編集者によって復元された欠損文字(通常、角括弧内に注釈が付けられ、通常は文法的および構文的パターンと再構築された碑文の物理的レイアウトに基づいて復元される)は保持されました。欠損文字の正確な数が不確定な場合(通常、各ハイフンが1つの欠損文字に対応するプレースホルダーとしてハイフンを使用して表現される)も保持されました。余分なスペースは、清潔で簡潔な出力を確保するために削除されました。非ラテン文字はアクセント除去機能を使用して削除され、ラテン文字、事前定義された句読点、およびプレースホルダーのみが残されました。重複する碑文は、利用可能な場合はユニークなTrismegistos識別子を使用して除外され、さらにファジー文字列照合(fuzzy string matching)とMinHash局所性敏感ハッシング(MinHash locality-sensitive hashing) を用いた追加の重複排除によって補完されました。90%を超える内容類似度しきい値を超えるテキストは重複と見なされ、特定された各ペアから1つのテキストが削除されました。モデルの学習と汎化能力に不可欠な実質的なテキスト内容に焦点を当てるため、25文字未満の碑文はフィルタリングされました。データセットの分割については、数値のTrismegistos(または代替のEDCS_ETL)識別子が3または4で終わる碑文は、以前の研究 に従って、それぞれテストセットと検証セットに割り当てられ、サブセット全体で画像の均等な分布が確保されました。
画像はEDRとEDHからのみ取得されました。高いデータ品質を維持し、データセット全体で標準化を確保するため、自動フィルタリングプロセスが実装されました。このプロセスは、色ヒストグラムに閾値を適用することで、描画、複製、その他の非写真アーティファクトを削除しました。具体的には、主に単一の固体色で構成される画像をターゲットとし、排除しました。さらに、ラプラシアン行列の分散を利用して、ぼやけた画像を特定し、破棄しました。これは、ぼやけた画像は色の連続性の分散が低いという原則を活用しています。クリーンアップされた画像は、元のデータセットの主要な形式であったグレースケールに変換されました。各碑文について、碑文以外の表面を除き、単一の代表的な画像のみが保持されました。
Dataset limitations (データセットの限界)
これまでで最大の機械可読ラテン語碑文コーパスであるにもかかわらず、LEDのサイズ(1,600万文字)は、最先端の自然言語処理研究で通常使用されるデータセットの規模と比較すると、依然として大きな制約となります。この相対的なデータ不足は、モデルの汎化能力を必然的に制限し、より稀な碑文学的現象や、代表性が低い地域や時代に対する性能を制限する可能性があります。
とりわけ、利用可能なコーパスは固有のバイアスにも左右されます。最も顕著なのは「碑文の生存バイアス」であり、特定の素材、場所、歴史的文脈にデータが偏る可能性があります。この制約は、画像モダリティではさらに顕著であり、テキスト碑文の約5%にしか対応する画像がありません。その結果、セーリエンスマップが地理的帰属タスクのテキストモダリティに貴重な洞察を提供した一方で、画像セーリエンスマップによって強調されたアーティファクトは、ドメイン専門家にとって解釈しにくいことが多々ありました。さらに、年代帰属タスクも、おそらくパレオグラフィー(古文書学)の議論とのより良い整合性を可能にする追加画像から恩恵を受ける可能性があります。
データセットには「データ循環性(data circularity)」という要素が含まれていることが、Assael et al. でも認識されていました。碑文の編集者は伝統的に2つの要素を復元します。彼らは括弧で囲まれた記号や略語を展開し、角括弧で囲まれた欠損テキストを復元しようとします。Aeneasも同様に、欠損テキストの仮説的な復元を提供します。データセットを作成するにあたり、本研究では拡張された文字は削除しましたが、これは石に刻まれていなかったためです。しかし、元々刻まれていたが失われたテキストに対する以前の編集者の復元は保持しました。復元はパラレルと文脈的知識に基づいており、最良の実践としては、高い確信度がある場合にのみそのような復元を提供すべきであるとされています。それにもかかわらず、訓練セットにそのような以前の復元を含めることで、確証バイアスのリスクが生じる可能性があります。特に、すべての学者が一貫して厳密であるわけではないためです。
この資料を含める主な動機は、データの利用可能性が限られていることでした。I.PHIデータセットをIthacaのために準備する際、角括弧内のテキストを除外すると、利用可能なテキスト全体の20%が失われると計算されました。深層学習モデルは膨大な量のデータから大きく恩恵を受けることができ、本データセットは最近のNLPデータセットよりも桁違いに小さいため、過学習を避け、汎化を助けるために利用可能なすべての情報を活用したいと考えました。この決定の影響を評価するため、仮説的なテキスト復元を保持した場合としない場合のモデルの信頼性を評価する追加実験を実施しました。仮説的な復元を含めて訓練されたモデルと、含めずに訓練されたモデルの差は5%未満であり、後者はすべてのタスクで元の原稿モデルよりも劣る結果となりました。本研究では、性能向上の利点がバイアスのリスクを上回ると結論付けました。
しかし、より広範なバイアスのリスクは認識されるべきであり、将来の研究では、利用可能なデータの品質と量が進歩するにつれて、これに対処しようと努める可能性があります。仮説的復元を除外したデータで訓練されたモデルを使用することで、既存の編集者の復元をテストし、以前の編集作業における既存のバイアスを特定したり、モデルを使用して外れ値を特定したりすることが可能になるかもしれません。さらに一歩進んで、そのようなモデルは、過去の碑文学者の中でより信頼できる編集者とそうでない編集者を特定するのにも役立つ可能性があり、既存の碑文学的版を改訂する継続的な作業において重要な役割を果たすことができます。
Aeneas’ architecture (Aeneasのアーキテクチャ)
Aeneasは、設定された文字長の復元、未知の欠損長の復元、地理的帰属、年代的帰属という4つの主要なタスクを実行するように訓練されています。 各碑文に対するAeneasアーキテクチャへの入力は、文字シーケンス(スペースを含む)と、224×224ピクセルの対応するグレースケール画像から構成されます。最大シーケンス長は768文字です。欠損情報をアノテーションするために2つの特殊記号が入力に含まれます。「-」は単一の欠損文字を示し、「#」は未知の長さの欠損セグメントを示します。さらに、シーケンスには文頭トークン「<」がパディングされます。テキスト入力は、T5 モデルから派生し、ロータリーエンベディング(rotary embeddings)を使用するように適応された大規模なトランスフォーマーアーキテクチャに基づいたモデルのトルソを通して処理されます。T5モデルは、埋め込み次元が384、クエリ-キー-バリュー次元が32、マルチレイヤーパーセプトロン(MLP)サイズが1,536です。各レイヤーに8つのアテンションヘッドを持つ16層で構成されています。トルソは、入力シーケンスと同じ長さの埋め込みシーケンスを出力します。各埋め込みは1,536次元のベクトルです。これらの埋め込みは、復元、未知長復元予測、地理的帰属、年代的帰属の4つのタスク固有のヘッドに渡されます。各タスクヘッドは、2層のMLPに続いてソフトマックス関数で構成されています。
モデルは、Google Cloudプラットフォーム上の64台のTensor Processing Unit v5eチップを使用して1週間訓練され、バッチサイズは1,024のテキストと画像のペア、LAMB オプティマイザーを使用しました。学習率は、ピーク値3×10^-3、ウォームアップフェーズ4,000ステップ、合計100万ステップのスケジュールに従います。各タスクの損失(L)を微調整するために、ベイズ最適化が使用され、次のように結合されます。
$$L = 3 * L_{\text{restoration}} + L_{\text{unknown}} + 2 *L_ {\text{region}} + 1.25 * L_{\text{date}}$$
過学習(データに過剰に適合しすぎて、新しいデータに対する性能が低下すること)を軽減するため、特にデータセットサイズが限られていることを考慮し、訓練中にいくつかのデータ拡張技術が適用されました。これらの技術には、最大75%のテキストマスキング、テキストクリッピング、単語削除、句読点削除、およびズーム、回転、明るさやコントラストの調整などの画像拡張が含まれます。ドロップアウト(10%)とラベルスムージングも使用され、復元タスクでは5%、地理的帰属では10%のスムージングレートが適用されました。このマルチタスク設定は、訓練および拡張戦略と組み合わせることで、Aeneasが4つの碑文学タスクすべてで堅牢な性能を達成することを可能にします。
Training Aeneas (Aeneasの訓練)
Aeneasの訓練中の基礎となるプロセスをよりよく理解するために、このセクションでは、モデルの復元および帰属タスクに関わる入力と出力の概要を詳しく説明します。 復元タスクでは、碑文のテキストを人工的に破損させ、最大75%の文字をマスキングすることで、正解データ(ground truths)が生成されます。これらのマスクの一部は、実際の損傷をよりよくシミュレートするために、意図的に連続するセグメントにグループ化されます。破損長が既知の場合、Aeneasは欠損文字を直接予測します。未知長復元の場合、未知長記号(#)が検出されるたびに、1文字以上が欠損しているかどうかを予測するために、追加のニューラルネットワークヘッドが組み込まれ、二項交差エントロピー(binary cross-entropy)を使用します。さらに、モデルのアーキテクチャは、入力文字とタスク出力の間のアライメントを維持します。入力テキスト文字に対応するAeneasのトルソ埋め込みは、シーケンス内のその位置に直接マッピングされます。欠損文字ごとに、対応する埋め込みが復元タスクヘッドに供給され、欠損文字が予測されます。未知長復元の場合、入力シーケンスに「#」記号が現れるたびに、追加のタスクヘッドが起動し、単一の文字が欠損しているのか、それとも複数の文字が欠損しているのかを判断します。このアーキテクチャにより、モデルは入力文字とタスク出力のアライメントを維持しながら、復元および帰属タスクを効率的に処理できます。
Aeneasのテキスト復元予測を生成するために、ビーム幅100のビームサーチを使用します。さらに、未知長予測を組み込んだ非逐次ビームサーチを実装しています。各ビームは、最も確信度の高い復元候補から始まり、各タイムステップで最も確実性の高い文字を復元しながら反復的に進みます。未知長復元文字が見つかった場合、欠損文字が前に追加され、2つのエントリがビームに追加されます。1つは未知長記号を保持し、もう1つはそれを削除します。このアプローチは、複数の文字を復元する必要がある場合と、単一の文字のみが欠損している場合の両方のシナリオに対応します。地理的および年代的帰属タスクは、トルソの最初の出力埋め込み(t=1)を使用し、それぞれのタスクヘッドに渡されます。地理的帰属は、利用可能な場合に正解ラベルを用いて、カテゴリカル交差エントロピー(categorical cross-entropy)によって62のローマ属州のいずれかを予測します。年代的帰属は、紀元前800年から紀元後800年までの歴史的年代を、二値化されたビン(bin)を用いて160の離散的な10年間にマッピングします。予測された分布と歴史家によって提供された正解範囲を一致させるために、カルバック・ライブラー情報量(Kullback–Leibler divergence)が使用されます。視覚入力は、ResNet-8 ニューラルネットワークを使用して処理されます。得られた出力は、関連するテキスト埋め込みと連結され、地理的帰属ヘッドによって共同で処理されます。
最後に、セーリエンスマップの有効性は依然として議論の的となっています。しかし、本研究チームの歴史家は、特にテキスト入力の場合に、それらが貴重な説明ツールであると一般的に感じており、このため出力に含めることを決定しました。
Aeneas’ contextualization mechanism (Aeneasの文脈化メカニズム)
Aeneasの文脈化メカニズムは、多次元空間内の埋め込みとして捉えることができます。各碑文は、最も近い隣接要素が歴史家が研究の基礎とするパラレルに対応するように配置されます。文脈化の正解データがないため、本研究では碑文学タスクを代理としてこの埋め込み空間を構築します。このアプローチにより、テキスト的および文脈的に関連するパラレル碑文が空間内でより近くに配置されることで、それらが整合されます。
この埋め込み空間における近接度は、コサイン類似度を用いて測定されます。これは、学際的なチームによる予備評価で有効な指標として特定されました。歴史的に豊かな埋め込み空間を構築するため、Aeneasのトルソの出力埋め込み(emb)を次の式で結合します。
$$\text{emb}_{\text{context}} = \left( \text{emb}_{\text{torso}}^{t=1} + \frac{1}{N} \sum_{n=2}^{N} \text{emb}_{\text{torso}}^{t=n} \right) \div 2,$$
ここで、emb_torso^(t=1) はトルソの最初の出力(t=1)を表し、これは文頭の接頭辞と一致します。この埋め込みは、年代的および地理的帰属タスクヘッドにとって重要です。後続の出力(t=2..N、ここで N は接頭辞記号を含む入力文字列の長さ)はテキスト入力と一致し、復元タスクヘッドに使用されます。
文脈化タスクにおけるAeneasの歴史的に豊かな埋め込みの可能性を示すため、本研究では、その性能をラテン語を含む多言語T5モデルから派生したテキスト埋め込みと比較しています。具体的には、年代的および地理的帰属タスクに焦点を当てています。年代的帰属については、青色(データセット内の最も古い年代)から赤色(最も新しい年代)に移行するカラースケールを使用しています。地理的帰属については、62の属州の地理的座標に基づくカラースケールを適用し、黄色は北、赤は西、緑は東、青は南のローマ属州を表しています [50, Extended Data Fig. 1]。
Extended Data Fig. 1は、UMAP(Uniform Manifold Approximation and Projection)次元削減 を用いた埋め込み空間の可視化を示しています。UMAPプロジェクションを直接解釈することには固有の限界があることを認識することが重要ですが、Aeneasから派生した埋め込みは、より滑らかな分布と年代的および地理的ラベルとのより大きな整合性を示しているようです。これらの観察は、Aeneasの埋め込みが歴史的文脈の根底にある構造をよりよく捉えている可能性を示唆しており、クラスターのより明確な分離によって裏付けられています。比較として、T5によって生成された埋め込みはより大きな重複を示しており、文脈的属性を区別することにおける潜在的な課題を示しています。これは、Aeneasの埋め込みが歴史的情報を捉え、類似の碑文学的文脈から関連するパラレルテキストを提案する上での有効性を強調しています。
学際的なチームは、テキストとメタデータの埋め込みや生データとしての使用など、様々な訓練された検索方法をさらに評価しました。しかし、データセットサイズが限られているため、予備評価ではAeneasの埋め込みを用いた類似性スコアリングが最も関連性の高い碑文を生み出し、この直感は専門歴史家の評価によって裏付けられました。
Evaluating Aeneas (Aeneasの評価)
Task metrics (タスク指標)
本研究では、Assael et al. によって提案された復元、地理的帰属、年代的帰属のタスクに関する評価フレームワークを採用し、一貫性と解釈可能性を高めるためにさらに改良しています。 テキスト復元の場合、再構築する文字数が増えるほど難易度が上がります。上記のように、評価パイプラインはテキストの任意の範囲を人為的に破損させて復元対象を生成します。この確率的パイプラインを異なる難易度レベルで公平に比較するため、シーケンス長に基づいて性能指標を計算します。具体的には、各シーケンス長(1文字から20文字まで)のCER(文字エラー率)を次のように計算します。
$$\text{CER}_{l} = \frac{\sum_{i=1}^{N} I_{\text{len}_{i}=l} \times \frac{\text{edit distance}(\text{pred}_{i}, \text{target}_{i})}{l}}{\sum_{i=1}^{N} I_{\text{len}_{i}=l}},$$
ここで、I は指示関数、len_i はi番目のサンプルの長さを表し、N はサンプルの総数、pred_i は予測シーケンス、target_i は正解データに対応します。その後、すべてのシーケンス長にわたってCER値を平均します。
$$\text{CER}_{\text{score}} = \frac{1}{L} \sum_{l=1}^{L} \text{CER}_{l}.$$
ここで、L=20 は評価に使用される最大シーケンス長を表します。さらに、同じ層別アプローチに従ってトップ20精度を計算します。
地理的帰属の場合、標準的なトップ1およびトップ3の精度指標を用いて性能を評価します。トップ1精度は、62のローマ属州の中から正確な属州を特定するモデルの能力を測定する一方、トップ3精度は、もっともらしい代替提案を提供する能力を評価することで、歴史家の分析を支援する追加の洞察を提供します。最後に、年代的帰属の場合、モデルは可能な年代の予測分布を生成します。予測と正解の間の時間的近接度を評価するために、解釈可能な指標を使用します。距離は、予測された平均値 pred_avg と、最小(gt_min)および最大(gt_max)境界によって定義される正解区間との関係に基づいて計算されます。
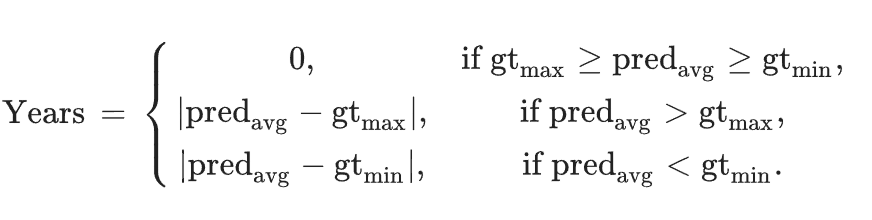
Onomastics baseline (オノマスティックス・ベースライン)
人名は碑文学者にとって貴重な洞察を提供し、帰属予測の主要な指標として機能します。広範な碑文学ワークフローにおけるその重要性に基づき、本研究ではこれらの人名から派生したメタデータのみを活用するオノマスティックスベースラインを導入しています。以前の研究 がこの手法を人間の評価者を用いて限られたデータサブセットに適用したのに対し、本研究のアプローチはプロセスを完全に自動化し、評価データセット全体に適用可能であり、スケーラビリティを向上させています。ローマの固有名詞成分のデジタル化されたリストがないため、Classical Language Toolkitが提供する固有名詞のリポジトリを適応させました。このリストから、固有名詞ではない350項目を手動で削除し、曖昧な使用法のため短いエントリ(1文字または2文字)を除外し、非ラテン文字を含むものを削除して、約38,000の固有名詞のキュレーションされたリストを作成しました。結果として得られたリストは、研究のGitHubリポジトリで公開されています。本手法の堅牢性を高めるため、データセット内で最も頻繁に出現する単語ユニグラム、バイグラム、トリグラムを特定し(tria nominaやその他のローマの固有名詞的特徴を捉えるため)、5回以上出現するもののみを保持しました。これらのN-グラムをさらにフィルタリングし、キュレーションされた固有名詞リストのエントリのみで構成されるもの、またはその組み合わせからなるもののみを含めました。特定された各N-グラムについて、それらが現れるテキストの正解データに基づいて、訓練データセット全体の平均年代的および地理的分布を計算します。最後に、新しい碑文を分析する際、これらのN-グラムがどれだけ出現するかを確認し、関連する統計を集計して、碑文の年代と出所の両方を予測するために使用します。
Historian–AI evaluation ethics protocol (歴史家とAIの共同評価における倫理プロトコル)
この研究の中心的な要素の一つは、これまでに実施された中で最大規模の歴史家とAIの共同評価でした。目標は、歴史研究におけるAeneasの文脈化メカニズムの有効性を基礎的なツールとして評価することでした。特別に開発された倫理プロトコルは、ノッティンガム大学芸術学部研究倫理委員会によって好意的な倫理的意見を受けました。評価には、参加者の募集に応じた23名の碑文学専門家が参加しました。すべての回答は匿名化されました。各参加者には、メタデータや画像なしでテキスト転写として提示された5つの対象碑文が割り当てられました。評価は、各参加者用にプログラム的に生成され入力されたオンラインのGoogleフォームを介して、碑文ごとに3つの連続した段階で行われました。
ステージ1では、専門家はAIの支援なしに、3つの碑文学タスク(テキスト復元、地理的および年代的帰属)を独立して実行しました。ステージ2では、LED訓練セット(141,000の碑文と関連メタデータ(書かれた場所と日付)を含む)からAeneasが検索した10のパラレルが提供され、各碑文について同じタスクを再度実行しました。ステージ3では、専門家はAeneasの予測とセーリエンスマップも受け取り、同じ碑文学タスクを最終的に完了しました。すべての専門家はステージ1を完了し、その後、各碑文についてステージ2またはステージ3に交互に割り当てられました。各ステージの終わりに、参加者は3つのタスクに関する予測の自信と、Aeneasの文脈化支援を使用した主観的な経験を評価するための短いアンケートを完了しました。このペア評価では、ステージ3で2人の歴史家が異なる構成(すなわち、一方はパラレルのみ、もう一方はパラレルと予測の両方)で同じ碑文を分析しました。したがって、初期の単独評価で観察された変動は、修士課程の学生から教授まで、大体同じくらいの割合で初期キャリアの研究者と上級研究者がいる、参加者の多様な背景を反映しています。参加者は碑文を扱う経験も異なり、新しく発見されたテキストの出版のために定期的に編集する者もいれば、すでに発表された資料の歴史分析を主に行う者もいました。この「一次」と「二次」の碑文学的作業の区別は重要であり、Aeneasが、復元、年代推定、出所が当然と考えられていても、批判的な再評価が必要な既存のコーパスを扱う研究者にとって、より広範な関連性があることを強調しています。
評価には最大2時間の時間制限がありました。伝統的な碑文学のワークフロー(研究者が関連するパラレルを見つけるために百科事典的リソースを参照する)に可能な限り厳密に従いながら、実験的評価の人工的な制約を認識し、参加者は提供された「Parallel Searching Dataset」を使用して手動でパラレルを検索することが許可されました。このオンラインスプレッドシートはLED訓練セットから抽出されたもので、評価対象の碑文を除き、141,000のテキストと関連するメタデータ(書かれた場所と日付)で構成されていました。参加者は、評価フォームの指定されたフィールドに、手動で検索して使用したすべてのパラレルのユニークな識別子を記録する必要がありました。公平性を確保し、評価対象の碑文への偶発的な露出を防ぐため、参加者は評価中にオンラインの碑文学データセット(EDR、EDH、EDCSなど)、印刷版、検索エンジン、または生成AIツールへのアクセスを禁じられました。
Evaluating contextualization (文脈化の評価)
Aeneasの文脈化メカニズムの有効性を評価するため、ステージ2で歴史家が手動で検索したパラレルリストに、Aeneasが提案したパラレル碑文をどれだけ独立して組み込んだかをカウントしました。歴史家は、Aeneasが提案したパラレル碑文を平均1.5件、自身の手動リストに組み込みました(値の範囲は0〜6、中央値:1、四分位範囲:0〜2.5)。
さらに、3つのステージにわたる歴史家の予測に対する自信を測定しました。Aeneasのパラレルが提供された場合、自信は平均23%増加しました(復元で60.4%から68.7%、地理的帰属で46.6%から57.0%、年代的帰属で43.7%から57.5%)。Aeneasの3つのタスクの予測も共有された場合、歴史家の自信はさらに21%増加しました(復元で53.3%から75.4%、地理的帰属で48.7%から67.0%、年代的帰属で44.1%から67.5%)。
最後に、Aeneasが提供したパラレルテキストが歴史的探究の効果的な出発点となったかどうかについて、歴史家からフィードバックを求めました。Aeneasのパラレルのみが提供された場合、75%の歴史家が同意しました(非常にそう思う38.3%、ある程度そう思う36.7%、ほとんどない20%、全くない5%)。Aeneasの3つの碑文学タスクの予測も含まれた場合、同意は90%に増加しました(非常にそう思う45%、ある程度そう思う45%、ほとんどない6.7%、全くない3.3%)。
Historians’ qualitative feedback (歴史家の定性的なフィードバック)
歴史家とAIの共同評価の一環として、Aeneasを使用した主観的な経験について参加者から定性的なフィードバックを求めました。歴史家は、対象碑文の碑文学的タスクを実行するための関連するテキスト的および文脈的パラレルを提供するAeneasの文脈化メカニズムの価値を一貫して強調しました。以下にその一部を引用します。
「Aeneasが検索したパラレルは、私の歴史的焦点を完全に変えました。(中略)これらのテキストを見つけるのに、数日ではなく15分しかかかりませんでした。もしこれらの碑文の読み取りに基づいて歴史的解釈をするなら、今はパラレルを探すのではなく、研究課題を書いて構成するのに数日を費やせるでしょう。」
「パラレル碑文の助けは、碑文の種類を理解するのに非常に役立ちます。(中略)私自身の検索はより狭い範囲に限定されていました。」
「予測は非常に良いです。Aeneasが生成した解放奴隷の碑文の優勢さもそうです。スタティリウス・タウルス家が著名な家族であったため、深みにはまりやすいかもしれません。」
「より多くのパラレル碑文の助けは、仲間の兵士が碑文を立てる碑文の種類を理解するのに非常に役立ちました。一方、私自身の検索はノリクムからの碑文に限定されていました。[Aeneasは]素晴らしいパラレルツールです。」
「Aeneasが検索したパラレルは、ステージ1からの碑文に対する私の認識を完全に変えました。テキストの復元と年代特定の両方において、非常に重要な詳細を見落としていたことに気づきませんでした。」
「Aeneasが検索したテキストのおかげで、各タスクが質的に実行可能になりました。その中には、私が単独検索では全く見つけられなかったものもありました。」
「Aeneasは非常に有用なパラレル(定型句)を検索してくれました。それは私がデータセットで見つけられなかったものです。」
「この碑文のトップパラレルは、私とAeneasの両方によって独立して発見されました。」
「[Aeneasは]私の[パラレル]検索結果を広げると同時に、洗練させる印象的な能力を示しています。」
歴史家のフィードバックからは、3つの重要なテーマが浮かび上がりました。第一に、Aeneasが関連するパラレルを見つけるのに必要な時間を大幅に短縮し、より深い歴史的解釈と研究課題の構築に集中できるようになったと歴史家は強調しました。この効率性により、伝統的な歴史的方法では見落とされがちな、より広範で洗練されたパラレルのセットを探索することも可能になりました。第二に、Aeneasが検索したパラレルが碑文の種類と文脈に関する貴重な洞察を提供し、3つの碑文学的タスクにおいて彼らを支援したことを確認しました。最後に、Aeneasが、重要でありながらこれまで見過ごされていたパラレルや見落とされていたテキスト特徴を特定することで検索を広げ、同時に過度に狭すぎたり無関係な結果を避けながら結果を洗練させる能力を強調しました。
一部の貢献者は、評価の実験条件に課題があることを指摘しました。まず、課された時間制限は必要不可欠でしたが、制約として機能しました。歴史家は通常、標準的な研究設定では資料にアクセスするために数週間から数ヶ月を費やします。第二に、「Parallel Searching Dataset」オンラインスプレッドシートは、専門的なコーパス(例:Roman Inscriptions of Britain や I.Sicily)よりも検索が容易ではありませんでした。これらの専門コーパスは、正確なテキストパラレルを特定するための洗練されたフィルタリングおよびクロス検索機能、ならびに形態、図像、考古学的設定に関する追加の文脈データを提供します。このような人工的な制限は、実験条件下で実際の研究ワークフローをシミュレートする上での制約により、残念ながら避けられませんでした。
一部の貢献者から提示されたさらなる観察は、Aeneasが非常に短い、断片的な、または定型的な碑文、特に略語を含む人名に関する碑文への適合性に関するものでした。このような場合、人間であろうとAIモデルであろうと、いかなる推測も本質的に危険です。
「この場合、パラレルは全く役に立ちません。欠損は主格の断片的な氏名(gentilicium)の前にあります。そのため、氏名を復元すると、残りの部分はほとんどの場合、略された個人名(praenomen)である可能性が高いです。(中略)人名には特に使いにくいです。どんな選択肢も非常に危険でしょう。」
「これは非常に短く曖昧な墓碑銘であり、高い確信度で復元することは不可能です。Aeneasは、テーマ的または文体的にターゲットテキストに類似したテキストを検索するようですが(望ましいことですが!)、墓碑銘の場合、これらのパラレルは手動で検索されたパラレルと同様に、碑文学者にとってほとんど役に立ちません!そのようなテキストにはAeneasは使わないでしょう。」
一方で、Aeneasがこれらの短い、標準化されたテキストのパラレルを検索する能力は称賛されました。それは基本的な文字列照合を超え、限られたテキストからでも顕著な定型句の特徴を特定できたためです。
「検索されたパラレルは、碑文の定型句の内容に焦点を当てており、単なる単語の一致だけではありませんでした。」
要するに、評価された歴史家の定性的なフィードバックは、Aeneasが研究ツールとして持つ強みを強調しています。そのスピードと、それが検索する歴史的に豊かなパラレルの深さは、研究を加速するだけでなく、歴史的探究の新たな道を開くことを可能にします。
Aeneas’ limitations (Aeneasの限界)
歴史家からの全体的な肯定的なフィードバックにもかかわらず、Aeneasの性能がLEDデータセットの地理的および時間的範囲全体で変動する可能性があることを認識しています。モデルが地域や時代の代表的なパターンを学習する能力が見られる一方で、時間の経過や空間による言語の変化以外にも、この変動性の根底にはいくつかの追加要因が存在します。Aeneasの限界と性能変動を定量的に評価するため、LEDテストセットを用いてすべての属州と10年間の地理的および年代的帰属に関するエラー分析を実施しました。さらに、その視点を示すため、LED訓練セット内の各属州と10年間で利用可能な碑文の数をプロットしました。
この観測された変動性を説明することは困難であり、それ自体が研究プロジェクトとなるでしょう。本研究の範囲内では、2つの主要な原因が想定されます。まず、データの利用可能性です。一方では、碑文の公開率は地域によって異なり、また地域内の時代によっても異なります(研究に利用できる資源、特定の関心の焦点などによる)。他方では、ある地域がよく公開されていても、データが既存のデジタルリソースに体系的に組み込まれているとは限りません(EDRなどの主要なオンラインデータベースには特定の地理的焦点があり、すべての地域が均等にカバーされているわけではありません)。第二に、ローマ帝国全体におけるラテン語の碑文を刻む文化的実践の、時間と空間における固有の変動性です。これは、ある地域がよく研究され文書化されていても、資料の量が他の地域と比べて非常に限られている可能性があることを意味します。性能の変動によって暗示される可能性のある補助的な考慮事項は、その文化的実践が実際に地域や時代によってどの程度異なるかということですが、この問題に取り組むにはさらなる相当な作業が必要です。データの代表性の評価は、やや印象的なままです。しかし、いくつかの高レベルのパターンを特定して、変動と潜在的な寄与要因を説明することができます。
おそらく最も明白なのは、Aeneasが紀元後200年頃に年代帰属で最高の性能を示していることです。これは、最も多くの碑文がある時代と直接相関していると見ることができます。これはラテン語の「碑文学的習慣」のピークとしてしばしば観測されています。しかし、これは最も多くのデータがある時代であるだけでなく、最も厳密に年代が特定された碑文が最も多い時代でもあると暫定的に主張できます。一方、紀元前3世紀後半の精度の向上は、碑文の数とはそれほど直接相関していません。おそらくこれは、この時代の書かれたラテン語の比較的急速な進化と、テキストを刻む実践の比較的急速な増加(この時代はほぼイタリアに限定されていた)を反映しており、この時代にはテキストがかなりの精度で年代を特定できることを意味します。対照的に、それ以前のテキストは数が非常に少なく、伝統的に狭い期間に割り当てるのが困難です。
地理的変動を考慮すると、テキストの利用可能性が高いほど帰属精度が高いという正の相関関係(例:ローマやアフリカ・プロコンスラリス)が見られますが、2つの特定の変動セットが強調されるかもしれません。まず、古代イタリアのいくつかの地域(アプリア・エト・カラブリア、アエミリア、エトルリア、サムニウムなど)では、碑文の数は多いものの、精度は低いという結果が出ています。これに対する可能な説明は、おそらくイタリアが古代の地域に分割されていることと、データセットの残りの部分が帝国の大規模な属州に分割されていることとの対比です。古代イタリア内の言語的および文化的変動のレベルが、モデルがそこまで細かく区別するのを許容するには不十分である可能性は低くありません。イタリア地域のすべてのデータが統合されれば、「イタリア」への帰属精度は非常に高くなるでしょう。しかし、イタリアの他の地域と比較してローマ市の明らかな独自性は注目に値します。第二に、それとは対照的に、帝国のいくつかの遠隔地(アエギュプトゥス、カッパドキア、アラビア、キュレナイカなど)は、ラテン語碑文の生産が少ないにもかかわらず(データ記録の面でも、元の碑文学的生産の面でも)、より高い帰属精度を示しています。これは、碑文の内容における地域的な言語的および文化的独自性が大きいことを反映していると想定できます。最後に、2つの対照的な例が、データの代表性の根底にある問題を示しています。シチリアとサルデーニャは伝統的に比較的弱い碑文学的文化(生産不足)と関連付けられていますが、データセットにおける文書化も比較的劣っています。これは、比較的低い数と特に低い精度に反映されています。対照的に、ローマ時代のブリテンも伝統的に非常に弱い碑文学的文化として記述されていますが、現代の研究では最もよく文書化された碑文学的伝統の一つであり、その結果、比較的高数のテキストを誇っています。しかし、モデルでは高い精度も示しており、これは著しい地域差を示唆しています。
本論文のスペース制約と潜在的な分析の広範な範囲を考慮し、ここでは失敗事例の代表的な高レベルのパターンを特定することに議論を限定しました。予備観察では、特定の歴史的時代またはローマ属州から利用可能な碑文の数と、それらの年代推定または帰属におけるモデルの精度との間に正の相関関係があることが示されています。しかし、データの利用可能性の影響と、特定の地域や時代の言語的または碑文学的独自性など、他の要因とを切り離すためには、さらなる調査が必要です。これらのニュアンスと潜在的な緩和戦略に関するより詳細な検討は、将来の研究の焦点となるでしょう。
Modelling epigraphic networks with Aeneas (Aeneasによる碑文学ネットワークのモデリング)
Parallels, patterns and provincial cult (パラレル、パターン、地方のカルト)
Aeneasの文脈化メカニズムが、関連する碑文学的パラレルを検索する上でいかに効果的であるかを示すため、本研究では、よく証明されたタイプの代表的な碑文をケーススタディとして選択しました。対象の碑文(CIL XIII, 6665)は、ローマ属州ゲルマニア・スペリオルにある石灰岩製の奉納祭壇で、紀元後1895年にマインツ(現代のモゴンティアクム)の中心部の道路の発掘中に発見されました。この祭壇は、内部の日付の手がかりにより正確に年代を特定できます。紀元後211年のゲンティアヌスとバッススの執政官の年(7月15日)が明示的に祭壇が奉納された年として記されています。碑文には、beneficiarius consularis と呼ばれるルキウス・マイオリウス・コギタトゥスという人物によって、Deae Aufaniae (アウファニア女神)と Tutela loci (土地の守護神)に奉献されたことが記録されています。
Beneficiarii consulares は、ローマ軍の幕僚(通常は引退間近の軍団兵)の一部であり、帝国全土の属州総督に仕え、主要都市、前哨基地、国境、および西部の軍事属州の主要な交通路における碑文学的証拠によく見られます。Beneficiarius コギタトゥスは、属州総督の行政的、司法的、軍事的任務を支援するためにモゴンティアクムに派遣されたと考えられます。このような奉納祭壇を捧げることは、beneficiarii の習慣であり、現在650以上のそのような碑文が知られており、特にライン川とドナウ川沿いの属州で多く見られます。これらの祭壇の一部は、Matronae Aufaniae(碑文学的証拠ではより一般的にこう呼ばれる)に捧げられました。この女神の崇拝は、ローマ占領下のラインラントで特に盛んでした。
この碑文に対するAeneasの3つの碑文学タスクにおける性能は、その独特の地理的、年代的、言語的、および文化的特徴に対する感受性を効果的に示しています [75, Extended Data Fig. 2]。この祭壇に対するAeneasの年代推定平均は紀元後214年であり、これはモデルが訓練された10年間の範囲内に収まっています。そのトップ3の地理的帰属は、ゲルマニア・スペリオル(正解)、ゲルマニア・インフェリオル、パンノニア・スペリオルです。Aeneasの帰属セーリエンスマップを見ると、その年には2人の執政官の歴史的に特定された個人名(Gentiano et Basso cosulibus)と、Aeneasが特定した地域で特に崇拝が盛んである女神(Deab(us) Aufan(iabus))に明確に焦点が当たっていることがわかります。この碑文の画像のセーリエンスマップも興味深い結果を示しており、祭壇の形状、配置、建築的・図像的要素に焦点が当たっていることを強調しています。これは適切な選択です。Beneficiarii の祭壇は標準化されたデザインを持つ傾向があり、この特定の祭壇はFrenz によって記述されたD型に相当します。最後に、Aeneasの任意テキスト長復元能力をテストするため、8文字(「loci pro」)を人為的に破損させました。この未知文字復元シーケンスに対するAeneasのトップ5予測はすべて文脈的かつ言語的に正確であり、最初の復元仮説(pro)は「Tutelae pro salute」という定型句のより一般的に見られるバージョンであり、2番目の仮説は「Tutelae loci pro salute」という定型句のより稀なバージョンを捉えています。これがこの碑文の正しい復元です。
しかし、コギタトゥスの祭壇の物語はまだ終わりではありません。この祭壇の発見から112年後、2007年にマインツの州首相府の発掘中に、対象テキストが発見された場所から100m未満の距離で、12の類似の祭壇が発見されました。これらの新しい祭壇の最初の一つ(FM 07-055 No. 16 – EDCS-71100087)は2017年に出版され、LED訓練データに含まれています。他の11の祭壇の完全な出版は2023年に完了したばかりであり、最近の発見であるためLEDには含まれていません。この2番目の祭壇も、beneficiarius イウリウス・ベラトルによって、紀元後197年のラテラヌスとルフィヌスの執政官の年(7月15日)に Deae Aufaniae に捧げられました。この年は、皇帝セプティミウス・セウェルスがルグドゥヌム(リヨン)での血なまぐさい戦いで帝国僭称者クロディウス・アルビヌスを破った年であり、この碑文に現れる「pro salute et incolumitate sua suorumq(ue) omnium」(彼と彼のすべての者の安全と無事のために)というフレーズは、ベラトルが戦いを無傷で生き延びたことに対する女神への感謝に関連している可能性さえあります。このテキスト定型句は非常に稀であり、Aeneasの訓練データセットにはコギタトゥスの紀元後211年の祭壇しか既知のパラレルがありません。この観察により、Haensch はこのテキストの初版で、「Die Ähnlichkeiten im Formular zur Stiftung des Bellator sind zu groß, um zufällig zu sein」(ベラトルの奉納に関する定型句の類似性は、偶然であるには大きすぎる)と記しています。Haenschは、2つの祭壇が儀式的な空間に並んで立っており、CIL XIII, 6665を奉納した beneficiarius コギタトゥスが、実際にはベラトルによる以前のテキストを模倣した可能性があると考えています(両方の祭壇はD型図像デザインに属します)。
Aeneasは、このコギタトゥスのターゲットテキストに対する重要なパラレルも特定することができました。考古学的および歴史的文脈の知識を持つ専門歴史家がまさにそうするように、Aeneasの文脈化メカニズムによって検索された最初のパラレルは、紀元後197年のベラトルによって刻まれた祭壇です。さらに、Aeneasはゲルマニア・スペリオル、ゲルマニア・インフェリオル、パンノニアにわたる追加のパラレルを検索しました。これらは、テキスト文字列の正確な一致ではなく、ターゲットテキストとの歴史的、言語的、および碑文学的親和性を認識することによって行われました。これは重要な区別です。歴史家はしばしばEDCS_ETLなどのリソースを使用して、正確なテキスト文字列や定型句を迅速に検索し、結果を得ますが、そのようなツールはユーザーが正確なクエリを策定し、どのようなバリエーションが存在するかを予測することに依存します。これは、予想されるテンプレートから外れる関連する定型句や類似の固有名詞的パターンの発見を制限します。対照的に、Aeneasは、考古学的文脈や碑文間の空間的関係に関する以前の知識なしに(これは歴史家が解釈を導くために通常使用する特徴です)、文字通りの一致を超えて微妙で意味のある歴史的つながりを特定することで、これらの制約を乗り越えます。これは専門家レベルの推論を模倣する方法です。
これらの発見は、碑文学的ネットワークを再構築するためのツールとしてのAeneasの信頼性と力を強調しています。その歴史的探究を模倣し拡張する能力は、碑文学研究のための変革的なツールとしての可能性を浮き彫りにし、考古学的または空間的文脈にアクセスすることなく、ドメイン専門家が導き出すであろう予測と関連性を一貫して生成します。
Compositional complexities of the RGDA (『神君アウグストゥスの業績録』の構成上の複雑さ)
Aeneasが『神君アウグストゥスの業績録』(RGDA)について生成した予測、パラレル、およびセーリエンスマップは、この碑文の複雑さを反映しています。Aeneasの分析の詳細は上記のセクションで扱われましたが、RGDAに関する議論は、Aeneasの分析にニュアンスと背景を加えるために、さらに詳述します。
アンキュラに刻まれたテキストのバージョン(『モニュメンタム・アンキュラヌム』として知られる)は紀元後19年頃に作成されましたが、RGDA自体のテキストは、アウグストゥスの死後間もない紀元後14年に元老院で読み上げられ、その後ローマの廟の外に刻まれました。しかし、学者たちはRGDAがいつ構成されたかについて議論しています。アウグストゥスの治世中に様々な段階で進化する文書として(紀元前2年にはじまる)作成されたのか、それとも彼の生涯の終わり近く(紀元後13年-14年)に構成された、彼の業績の統一された回顧的記述として作成されたのか、という議論です。したがって、この場合、碑文が刻まれた日付と構成された日付は異なります。
RGDAの終わり(35.2)で、アウグストゥスは「これを書いたとき、私は76歳であった」(cum scripsi haec, annum agebam septuagensumum sextum)と結論付けています。この「76歳」は、彼の生涯の最後の年、すなわち紀元後13年9月23日の誕生日から紀元後14年8月19日の死までの期間と理解されるべきです。この明確な記述にもかかわらず、ほとんどの学者は、これが誤解を招く記述であり、テキストの最終的な改訂の瞬間を指すに過ぎず、その完全な構成を指すものではないという見方を支持しています。
ラムジー とクーリー は、アウグストゥスがその生涯の最後の年にテキスト全体を構成したと見なす、より直接的なアプローチを提案しており、上記のアウグストゥス自身の記述を文字通りに受け入れています。特に、このテキストは紀元後14年の夏、おそらく6月26日から7月24日にローマを最終的に出発するまでの間に本質的にまとめられたと示唆されています。
RGDAの構成に関する長年の議論は、Aeneasが取り組むように設計された解釈上の複雑さを浮き彫りにしています。このケーススタディは、Aeneasがテキスト内の言語パターンに対して既存の仮説をテストし、専門家主導の解釈を定量的歴史分析で補完することで、歴史的ワークフローをいかにサポートできるかを示しています。
Teaching with Aeneas in the classroom (教室でのAeneasの活用)
Aeneasの影響を最大化するため、研究者たちはヘント大学およびシントリーフェンスコレージュ・ヘントの教員養成プログラムと提携し、教育者および高校生向けのコースを共同で設計しました。古代ギリシャ語碑文のためのIthacaモデルに関する以前の研究(Teaching History Journal で評価され、European AI for Education Awardsで2度表彰された)を基盤とし、この新しいカリキュラムはAIと古代史を結びつけ、Aeneasを学習プロセスの中核に据えています。このコースはラテン語碑文とその文脈化に焦点を移し、学生が古典研究の一次資料に直接関わりながら、斬新なAI手法を探求することを可能にします。現在、アントワープ大学の現職教員研修プログラムに組み込まれており、人文科学におけるAIの実践的応用を示しつつ、デジタルリテラシーを促進しています。
このカリキュラムは、欧州連合の「市民のためのデジタル能力フレームワーク」(DigComp)およびUNESCOの「学生のためのAI能力フレームワーク」に合致しており、AIが生成したアウトプットを批判的に評価する、人間中心のアプローチを採用する、学際的な文脈で人間の監視を適用するといった主要な能力に対応しています。
Future directions (今後の展望)
Aeneasは、歴史研究を強化するAIの変革的潜在能力を示していますが、将来の開発にはいくつかの有望な道があります。一つの重要な方向性は、Aeneasの機能を大規模な対話モデルに統合することです。これにより、より自然でインタラクティブな研究ワークフローが可能となり、歴史家はシステムに問い合わせを行い、モデルの回答を検証し、より良い説明を受け取ることができるようになります。
歴史データの固有の不確実性、特に年代的帰属に関するものに対処することは、依然として重要な課題です。将来の研究では、モデルのアーキテクチャ内および推定範囲からの距離を超えた歴史的年代付けの実践のニュアンスをよりよく捉えるための、より洗練された評価指標を通じて、広い年代範囲を表現および評価するより良い方法の開発に焦点を当てる可能性があります。
さらなる機会は、異なるコンポーネントの貢献(例:異なるタスクにおける視覚入力の影響)を定量化するための追加のアブレーション研究を行うこと、および文脈的パラレルが異なるテキスト入力でどのように変化するか、またシステムが入力フォーマット(および異なる種類の碑文)のバリエーションにどの程度敏感であるかを探求することにあります。より大規模で高度に標準化され、FAIR原則に準拠したFAIRデータセットでマルチモーダル機能を改善し、ラテン語碑文を超えて範囲を広げることも、価値のある研究方向です。これにより、地理的帰属を超えた視覚モダリティの潜在能力をより深く探求し、図像的または考古学的に情報に基づいた分析を通じて年代推定に情報を提供できる可能性があります。最後に、学際的な協力関係を深めることが最も重要であると信じています。将来のプロジェクトが人文科学と科学の橋渡しをする道を継続して構築していくことを願っています。
Ethics and inclusion statement (倫理とインクルージョンに関する声明)
本研究は、古代史家、コンピューター科学者、教育専門家を結集した共同的、学際的なアプローチを通じて開発され、研究プロセス全体で多様な視点が確保されました。分野間の効果的なコミュニケーションと、最先端技術を活用して古代史の理解を深める有意義な研究課題の探求を可能にする能力構築が、この取り組みの中心でした。
このプロジェクトの中心には、碑文学が、皇帝やエリートだけでなく、奴隷、女性、その他の声なきコミュニティを含む古代世界の幅広い社会集団を理解するための直接的な証拠の主要な源として機能するという認識がありました。古代社会のアイデンティティの多様性へのこの焦点は、支配的な物語に挑戦し、ローマ世界に対するより包括的な理解を育む上で、碑文学データの重要な役割を強調しています。
本研究の方法は歴史研究を進展させる大きな可能性を秘めていますが、AIの誤用に伴うリスクにも留意しています。歴史データの誤分類や誤表現の可能性は、特にローマ世界では顕著な懸念であり、AIモデルが意図せず過去の偏った、または不正確な解釈を強化する可能性があります。自動化された方法の包括性に盲目的に依存することは歴史的解釈を歪めるリスクがあるため、AIツールは人間の監視の下で展開されることが不可欠です。
また、AIは人文科学における人間の専門知識を補完するものであり、代替するものではないことを強調します。本アプローチは、大規模データセットの処理と分析に要する膨大な労力と時間を軽減し、歴史家が古代テキストの批判的解釈と文脈分析に集中できるようにすることを目的としています。AIと人間による学術研究のこの連携は、デジタルヒューマニティーズ研究における責任ある倫理的な実践を進展させる上で不可欠です。最後に、学際的な専門知識を統合することで、古代史研究におけるAIの適用に対するより責任ある包括的なアプローチを育成することを目指しています。
研究データの入手先・利用したコードのまとめ
この研究で利用されたデータやソフトウェアは、以下のリンクからアクセスできます。
データ利用可能性 (Data Availability)
この研究で構築されたED (Latin Epigraphic Dataset)は、以下のオープンアクセスのデータベースを処理・統合して開発されました。
- 元となったデータソース:
- EDR (Epigraphic Database Roma): https://zenodo.org/records/3575495
- EDH (Epigraphic Database Heidelberg): https://zenodo.org/records/3575155
- EDCS_ETL (Epigraphic Database Clauss-Slaby): https://zenodo.org/records/7072337
- 処理済みのLEDデータセット:
- ローマ人の個人名リスト:
- 由来: Classical Language Toolkit (https://cltk.org/)
- 処理済みの固有名詞リスト: https://github.com/google-deepmind/predictingthepast
- 新しいカリキュラム:
- この研究の一環として共同設計されたカリキュラムは、以下のサイトで無料公開されています。
- サイト: https://predictingthepast.com
コード利用可能性 (Code Availability)
- Aeneas (機械学習モデル):
- ソースコード: https://github.com/google-deepmind/predictingthepast (Apache License 2.0)
- 学習済みモデル: Creative Commons Attribution-ShareAlike 4.0 International license (CC BY-SA 4.0) で利用可能
- 一般向けインターフェース:https://predictingthepast.com
- ラテン語碑文の文脈化、復元、帰属特定、および論文で議論されている可視化ツールが利用できます。
- 開発・分析・可視化に使用したツール:
- フレームワーク:
- JAX v.0.4.37 (https://github.com/jax-ml/jax)
- Flax v.0.10.2 (https://github.com/google/flax)
- プログラミング言語・データ処理:
- Python v.3.9 (https://www.python.org)
- NumPy v.2.1.3 (https://github.com/numpy/numpy)
- SciPy v.1.13.1 (https://www.scipy.org)
- pandas v.2.3.3 (https://github.com/pandas-dev/pandas)
- beautifulsoup4 v.4.12.3 (https://www.crummy.com/software/BeautifulSoup)
- Google Colab (https://research.google.com/colaboratory)
- 可視化ライブラリ:
- matplotlib v.3.10.0 (https://matplotlib.org)
- plotly v.5.24.1 (https://plotly.com/python)
- seaborn v.0.13.2 (https://seaborn.pydata.org)
- GeoPandas v.1.0.1 (https://geopandas.org)
- CartoDB basemaps (https://github.com/CartoDB/CartoDB-basemaps) (地図タイル用)
- フレームワーク:
まとめ
今回ご紹介したAIモデル「Aeneas」は、生成ニューラルネットワークという最先端の技術を活用し、古代ラテン語碑文の復元、地理的・年代的帰属、そして最も重要な文脈化という、歴史研究の非常に困難な課題に取り組んでいます。特に、AIと歴史家が協力することで、単独では達成できなかった高い精度と効率性を実現できることが示されました。
Aeneasは、単に失われた文字を埋めるだけでなく、碑文の背後にある広大な歴史的・文化的ネットワークをAIが理解し、そのつながりを可視化できる可能性を秘めています。これは、歴史家がより深い洞察を得て、これまでの手作業では困難だった大規模な分析を可能にする、まさに「変革的なツール」と言えるでしょう。
AIが人文科学の分野で新たな価値を創造し、専門家の能力を拡張する好例として、Aeneasの今後の発展に期待が寄せられます。








