はじめに
近年、AI(人工知能)技術は目覚ましい進化を遂げ、私たちの生活やビジネスに大きな変化をもたらしています。特に、大規模言語モデル(LLM)に代表される生成AIは、文章作成、画像生成、翻訳など、これまで人間にしかできなかったようなタスクをこなせるようになり、その活用範囲は広がり続けています。
このようなAIの進化を支えているのが、AIの計算処理に特化した半導体、いわゆる「AIアクセラレーター」です。Googleは、長年にわたり独自のAIアクセラレーターであるTPU(Tensor Processing Unit)を開発・提供してきました。そして、Google Cloud Next ’25にて、最新世代となる「Ironwood」を発表しました。
本稿では、このIronwoodがどのような技術であり、AIの未来にどのような影響を与えるのか、公式ブログ「Ironwood: The first Google TPU for the age of inference」より解説します。
引用元:
- タイトル: Ironwood: The first Google TPU for the age of inference
- URL: https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/
- 発行日: 2025年4月9日 (記事本文記載に基づく)
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。

要点
- IronwoodはGoogleの第7世代TPUであり、推論処理に特化して設計された初のTPUです。
- 「推論時代」に対応: 単に情報を提供するだけでなく、AIが主体的に情報を収集・生成し、洞察や解釈を提供する「思考するAI」を大規模に動かすために開発されました。
- 圧倒的な性能と拡張性: 9,216個のチップを液体冷却で接続し、42.5 Exaflopsという驚異的な計算能力を実現します(これは世界最大のスパコンの24倍以上)。
- メモリとネットワークの強化: 大容量のHBM(High Bandwidth Memory)と高速なICI(Inter-Chip Interconnect)により、大規模モデルの処理を効率化します。
- 電力効率の大幅な向上: 前世代TPU(Trillium)と比較して電力効率が約2倍に向上し、より持続可能なAI運用を可能にします。
- 多様なワークロードに対応: SparseCoreの強化により、従来のAI領域だけでなく、金融や科学技術計算など、より広範な分野での活用が期待されます。
詳細解説
TPUとは? なぜ推論特化なのか?
まず、TPU(Tensor Processing Unit)について簡単にご説明します。TPUは、GoogleがAI、特に機械学習の計算を高速化するために独自に開発したプロセッサーです。AIの計算では、「テンソル」と呼ばれる多次元配列の演算が大量に発生しますが、TPUはこのテンソル演算に特化することで、汎用的なCPUやGPUよりも効率的に処理を行えます。
AIモデルの開発には、大きく分けて「学習(Training)」と「推論(Inference)」の2つのフェーズがあります。
・学習: 大量のデータを使ってAIモデルのパターンやルールを学ばせるフェーズです。非常に大きな計算能力を長時間必要とします。
・推論: 学習済みのAIモデルを使って、新しいデータに対する予測や判断を行うフェーズです。例えば、ChatGPTに質問して回答を得たり、画像認識AIが画像の内容を識別したりするのが推論にあたります。リアルタイム性や応答速度が重要になります。
これまでのTPUは、主に学習と推論の両方に対応していましたが、Ironwoodは初めて推論処理に特化して設計されました。これは、AIの活用が広がるにつれて、学習済みモデルを使って実際にサービスを提供する「推論」の重要性が増していることを示しています。Googleは、AIが単に情報に応答するだけでなく、自ら考えて洞察を生み出す「推論時代(age of inference)」が到来すると予測しており、Ironwoodはこの新しい時代を支えるために開発されました。
Ironwoodの驚異的な性能
Ironwoodの最大の特徴は、その圧倒的な性能と拡張性です。
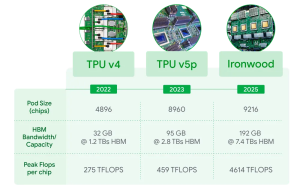
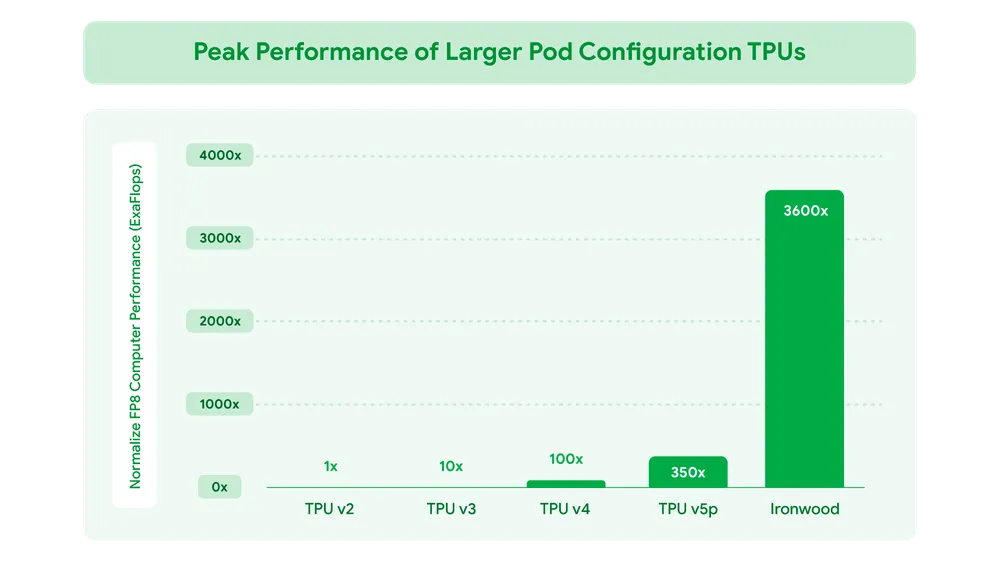
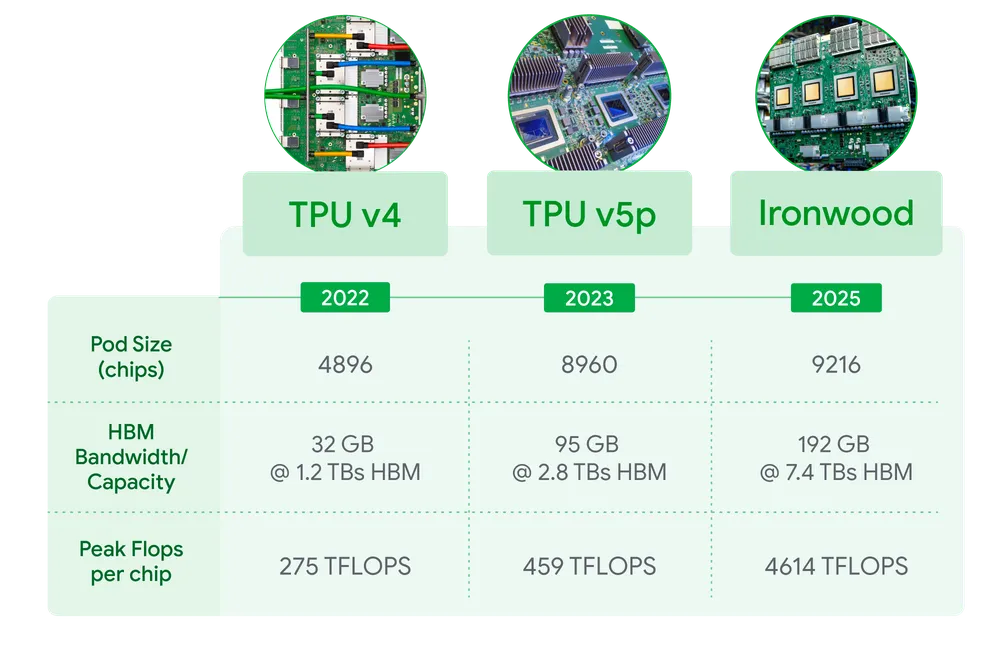
- 計算能力: 1チップあたり4,614 TFLOPs(1秒間に4,614兆回の浮動小数点演算)というピーク性能を持ちます。これを最大9,216チップまで連結することで、システム全体では42.5 Exaflops(1秒間に4京2500兆回の演算)という、想像を絶する計算能力を実現します。記事によれば、これは現存する世界最大のスーパーコンピューター「El Capitan」の24倍以上の性能に相当します。
- メモリ(HBM): AIモデル、特にLLMは巨大なサイズのものが多く、処理には大量のメモリが必要です。Ironwoodは1チップあたり192GBのHBM(High Bandwidth Memory)を搭載しています。これは前世代のTrilliumの6倍の容量であり、より大きなモデルやデータセットを効率的に扱えるようになります。メモリ帯域幅も7.2 TBpsとTrilliumの4.5倍に向上し、データへのアクセス速度が大幅に向上しました。
- チップ間接続(ICI): 大規模なAIモデルの処理では、多数のチップが連携して計算を行う必要があります。そのため、チップ間の通信速度が重要になります。Ironwoodでは、チップ間を接続するICI(Inter-Chip Interconnect)の帯域幅が1.2 Tbps(双方向)に向上し、Trilliumの1.5倍の速度を実現しました。これにより、多数のチップを使った分散処理がより効率的に行えます。
- 液体冷却: これほどの性能を発揮するには、発生する熱を効率的に冷却する必要があります。Ironwoodでは液体冷却システムを採用し、高負荷時でも安定して高いパフォーマンスを維持できるようにしています。
電力効率の向上とSparseCore
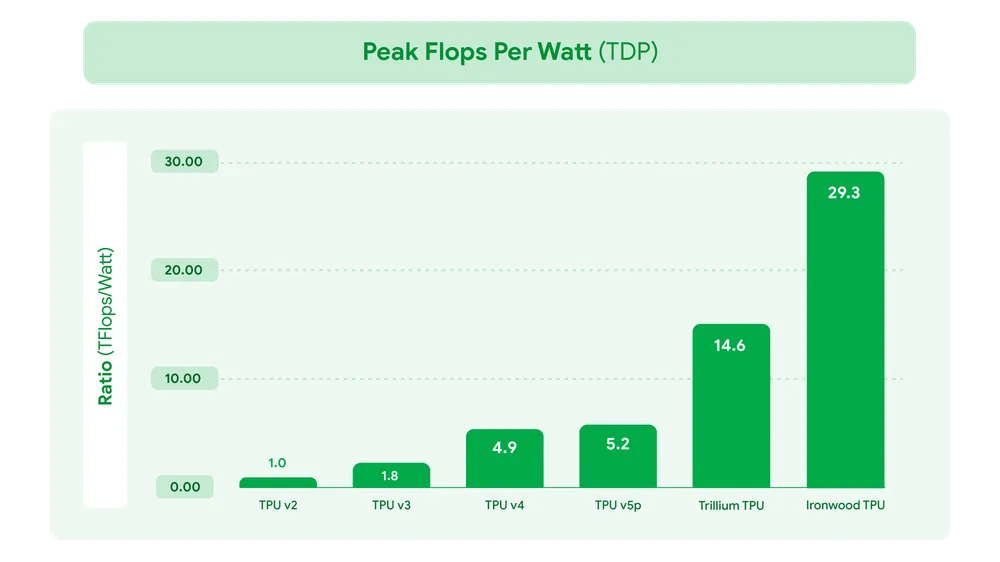
AIの計算には膨大な電力が必要であり、環境負荷や運用コストの観点から電力効率の改善は非常に重要です。Ironwoodは、性能向上だけでなく、電力効率にも注力しています。前世代のTrilliumと比較して、ワットあたりの性能(perf/watt)が約2倍に向上しました。これは、Google Cloud TPU v2(2018年)と比較すると約30倍の電力効率向上に相当します。
また、Ironwoodは「SparseCore」と呼ばれる、特定の種類のデータ処理に特化したアクセラレーターも強化されています。これは、特に検索ランキングやレコメンデーションシステムで使われる「埋め込み(embeddings)」と呼ばれる巨大なデータを効率的に処理するためのものです。IronwoodではこのSparseCoreの対応範囲が広がり、従来のAI領域だけでなく、金融モデリングや科学技術計算といった新しい分野への応用も期待されています。
Pathwaysソフトウェアスタック
どれだけハードウェアが強力でも、それを使いこなすソフトウェアがなければ意味がありません。Googleは、Pathwaysというソフトウェアスタックを提供しています。これはGoogle DeepMindによって開発された機械学習ランタイムであり、数万、数十万という規模のTPUチップを連携させて、効率的な分散コンピューティングを実現します。これにより、開発者はIronwoodの持つ膨大な計算能力を容易に、かつ信頼性高く活用することができます。
まとめ
本稿では、Googleが発表した最新TPU「Ironwood」について解説しました。Ironwoodは、推論処理に特化し、圧倒的な計算能力、大容量メモリ、高速なネットワーク、そして優れた電力効率を備えた、まさに「推論時代」をリードするためのAIアクセラレーターです。 Ironwoodのような高性能なインフラが登場することで、より賢く、より主体的に動作するAIの開発が加速し、これまで不可能だったようなAIアプリケーションやサービスが生まれる可能性があります。GoogleのGemini 2.5やAlphaFoldといった最先端のAIモデルもTPU上で動作しており、Ironwoodがもたらす今後のAIの進化に大いに期待が持てます。