はじめに
Google DeepMindが2026年1月27日、Gemini 3 Flashに「Agentic Vision」という新機能を発表しました。これは、視覚的推論とコード実行を組み合わせ、画像を静的な一枚の情報として処理するのではなく、段階的に検査・操作しながら理解を深めていく仕組みです。本稿では、この発表内容をもとに、Agentic Visionの技術的特徴と実用例について解説します。
参考記事
- タイトル: Introducing Agentic Vision in Gemini 3 Flash
- 著者: Rohan Doshi
- 発行元: Google Blog
- 発行日: 2026年1月27日
- URL: https://blog.google/innovation-and-ai/technology/developers-tools/agentic-vision-gemini-3-flash/
要点
- Agentic Visionは、画像理解を静的な処理から「Think(思考)、Act(行動)、Observe(観察)」という段階的なプロセスに変換する新機能である
- コード実行を有効にすることで、ほとんどの視覚ベンチマークで5〜10%の品質向上を実現した
- ズームによる詳細検査、画像へのアノテーション、視覚的な数学計算など、複数の実用的なユースケースが確認されている
- Google AI StudioとVertex AI経由で開発者が利用可能で、Geminiアプリにも順次展開される予定である
詳細解説
Agentic Visionの基本的な仕組み
Googleによれば、従来のフロンティアAIモデルは画像を「一度の静的な視線」で処理していました。そのため、マイクロチップのシリアル番号や遠くの道路標識のような細かい詳細を見逃すと、推測に頼らざるを得ない状況がありました。
Agentic Visionは、この課題に対して「Think、Act、Observe」という3段階のループを導入しています。まず、モデルがユーザーの質問と初期画像を分析し、複数ステップの計画を立てます(Think)。次に、Pythonコードを生成・実行して、画像のクロッピング、回転、アノテーション、あるいは計算や境界ボックスのカウントといった操作を行います(Act)。最後に、変換された画像がモデルのコンテキストウィンドウに追加され、より良い文脈で新しいデータを検査してから最終的な回答を生成します(Observe)。
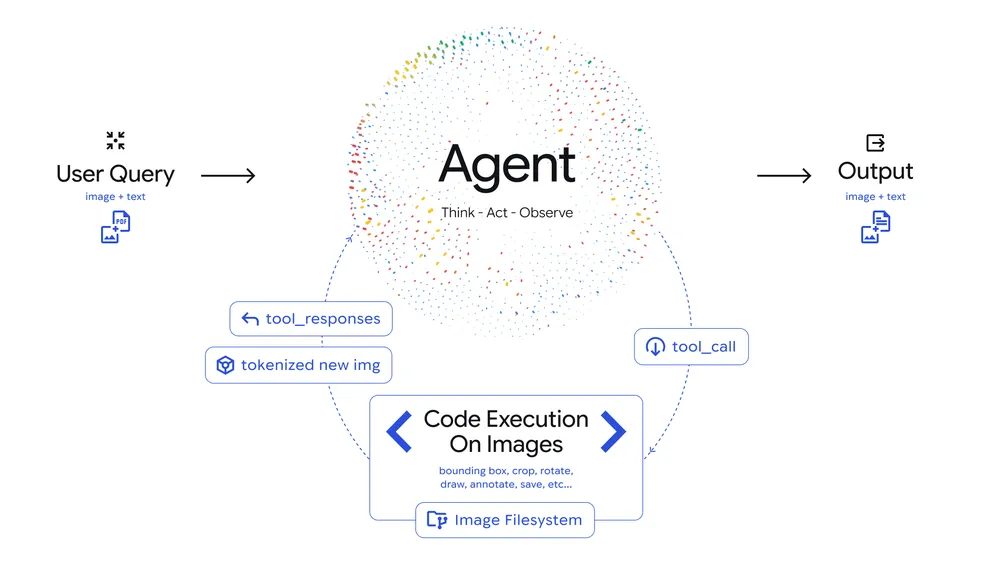
このアプローチは、従来の「一度見て判断する」方式から、「何度も見直して確認する」方式への転換と考えられます。人間が複雑な図面や地図を読む際に、全体を見た後に特定の箇所を拡大して確認するプロセスに似ています。
視覚ベンチマークでの性能向上
Googleの発表では、コード実行を有効にしたGemini 3 Flashが、ほとんどの視覚ベンチマークで一貫して5〜10%の品質向上を達成したとされています。この数値は、ベンチマークの種類によって変動すると思いますが、一般的なコンピュータビジョンタスクにおいて実用的な改善が見られたことを示していると言えます。
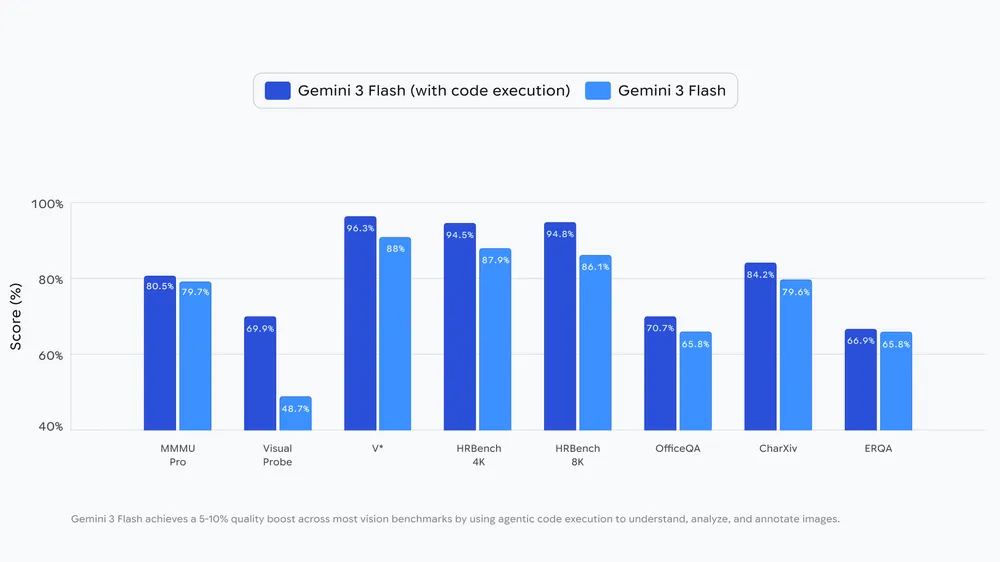
視覚ベンチマークは、物体検出、画像分類、視覚的推論など多様なタスクを含みます。5〜10%という向上幅は、特に高精度が求められる用途において、人間の監視やダブルチェックの負担を軽減できる水準と考えられます。
実用例1: ズームと検査
Agentic Visionの実用例として、Googleは複数のケースを紹介しています。
1つ目は、建築図面検証プラットフォーム「PlanCheckSolver.com」での活用です。同社によれば、Gemini 3 Flashでコード実行を有効にすることで、精度が5%向上しました。バックエンドログの動画では、モデルがPythonコードを生成して高解像度入力の特定パッチ(例えば屋根の端や建物のセクション)をクロッピング・分析し、これらのクロップ画像をコンテキストウィンドウに追加することで、複雑な建築基準への適合性を視覚的に根拠づけて確認する様子が示されています。
建築図面の検証は、細かい寸法や規格への適合が重要になる分野です。従来の画像認識では、全体を一度に見ることで細部を見落とす可能性がありましたが、Agentic Visionによる段階的な検査は、この課題に対する有効なアプローチと思います。
実用例2: 画像アノテーション
2つ目の例は、画像へのアノテーション機能です。Agentic Visionにより、モデルは見たものを説明するだけでなく、Pythonコードを実行してキャンバスに直接描画し、推論を根拠づけることができます。
Googleが示した例では、Geminiアプリで手の指の数を数えるタスクがあります。カウントエラーを避けるため、モデルはPythonを使用して識別した各指に境界ボックスと数値ラベルを描画します。この「視覚的なスクラッチパッド」により、最終的な回答がピクセル単位の正確な理解に基づいていることが保証されます。
このアプローチは、医療画像の分析や品質検査など、視覚的な根拠を示すことが重要な分野で有用と考えられます。単に「3つあります」と答えるのではなく、「これとこれとこれの3つです」と視覚的に示すことで、信頼性が高まります。
実用例3: 視覚的な数学とプロット作成
3つ目の例は、高密度の表を解析し、Pythonコードを実行して結果を可視化する機能です。
Googleによれば、標準的なLLMは複数ステップの視覚的な算術処理で幻覚を起こすことがよくあります。Gemini 3 Flashは、計算を決定論的なPython環境にオフロードすることで、この問題を回避します。Google AI Studioのデモアプリの例では、モデルが生データを識別し、従来のSOTAを1.0に正規化するコードを書き、プロフェッショナルなMatplotlib棒グラフを生成しています。これにより、確率的な推測が検証可能な実行に置き換えられています。
データの可視化は、ビジネス分析やレポート作成で頻繁に必要とされる作業です。表からグラフへの変換を自動化し、かつ計算の正確性を保証できることは、実務上の大きな利点と言えます。
今後の展開
Googleは、Agentic Visionの今後の展開として3つの方向性を示しています。
1つ目は、より多くの暗黙的なコード駆動動作の実装です。現在、Gemini 3 Flashは小さな詳細にズームインする判断を暗黙的に行うことに優れていますが、画像の回転や視覚的な数学などの他の機能は、明示的なプロンプトが必要です。Googleは、これらの動作を今後のアップデートで完全に暗黙的にする取り組みを進めているとしています。
2つ目は、より多くのツールの提供です。Googleは、Webや逆画像検索を含む更なるツールでGeminiモデルを装備し、世界に対する理解をさらに根拠づける方法を模索しているとのことです。
3つ目は、より多くのモデルサイズへの拡大です。この機能をFlash以外のモデルサイズにも展開する計画があるとされています。
これらの展開により、Agentic Visionの適用範囲が広がり、より幅広いユースケースで活用できるようになると考えられます。
利用方法
Agentic Visionは、Google AI StudioとVertex AI経由のGemini APIで利用可能です。また、Geminiアプリでも順次展開されており、モデルドロップダウンから「Thinking」を選択することでアクセスできます。
開発者は、Google AI Studioのデモアプリを試すか、AI Studio Playgroundで「Tools」の下にある「Code Execution」をオンにすることで機能を実験できます。
サンプルコード
from google import genai
from google.genai import types
client = genai.Client()
image = types.Part.from_uri(
file_uri="https://goo.gle/instrument-img",
mime_type="image/jpeg",
)
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[image, "Zoom into the expression pedals and tell me how many pedals are there?"],
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
print(response.text)まとめ
Gemini 3 FlashのAgentic Visionは、画像理解を「一度見る」から「段階的に検査する」プロセスへと変換する新機能です。視覚的推論とコード実行を組み合わせることで、建築図面の検証、画像アノテーション、データ可視化など、多様な実用的ユースケースで精度向上が確認されています。今後、より多くの暗黙的動作、ツール、モデルサイズへの展開が予定されており、視覚的AIの実用性がさらに高まることが期待されます。