はじめに
Google DeepMindが2026年1月22日、動画から3次元空間と時間を統合的に理解する新しいAIモデル「D4RT(Dynamic 4D Reconstruction and Tracking)」を発表しました。本稿では、この発表内容をもとに、D4RTの技術的な仕組みと性能、実用化への可能性について解説します。
参考記事
- タイトル: D4RT: Teaching AI to see the world in four dimensions
- 著者: Guillaume Le Moing and Mehdi S. M. Sajjadi
- 発行元: Google DeepMind
- 発行日: 2026年1月22日
- URL: https://deepmind.google/blog/d4rt-teaching-ai-to-see-the-world-in-four-dimensions/
要点
- D4RTは、2次元動画から3次元空間と時間を統合的に理解する4次元再構築モデルである
- 従来手法と比較して18倍から300倍の高速化を実現し、1分間の動画を約5秒で処理できる
- クエリベースのアプローチにより、ポイントトラッキング、点群再構築、カメラポーズ推定を単一のフレームワークで実行する
- MPI Sintel、Aria Digital Twin、RE10kなど複数のベンチマークで従来手法を上回る性能を記録した
- ロボティクス、AR、ワールドモデルなど、リアルタイム処理が求められる分野への応用が期待される
詳細解説
4次元理解が必要な理由
Google DeepMindによれば、人間は世界を見るとき、現在の状態だけでなく、過去と未来の関係性も同時に理解しているとされています。この能力をAIに持たせるには、カメラからの入力だけでは不十分です。2次元の平面映像である動画から、3次元空間の構造と時間軸での変化を復元する逆問題を解く必要があります。
従来、この4次元理解には計算負荷の高いプロセスや、深度推定、動き検出、カメラアングル推定など複数の専用AIモデルを組み合わせるアプローチが取られてきました。この方式では、処理が遅く、結果も断片的になるという課題がありました。D4RTは、こうした複数のタスクを単一のフレームワークで統合し、最大300倍の効率化を実現したとされています。
4次元再構築とは、空間の3次元(縦・横・高さ)に時間の1次元を加えた4次元での理解を指します。動画内のすべてのピクセルについて、3次元空間のどこに位置し、時間とともにどう移動するかを追跡する必要があり、さらにカメラ自体の動きも分離して処理しなければなりません。
クエリベースのアーキテクチャ
D4RTは、統合されたエンコーダー・デコーダー型のTransformerアーキテクチャを採用しています。Google DeepMindの説明では、エンコーダーがまず入力動画をシーンの幾何学的構造と動きの圧縮表現に変換します。従来システムとは異なり、D4RTは柔軟なクエリメカニズムを用いて、必要な情報だけを計算します。
このアプローチの核心は、「動画内の特定のピクセルが、任意の時刻において、選択したカメラ視点から見て3次元空間のどこに位置するか」という単一の基本的な問いに集約されます。軽量なデコーダーがこの表現に問い合わせを行い、具体的なインスタンスに答える仕組みです。
Transformerは、自然言語処理で広く使われるアーキテクチャで、入力データ間の関係性を効率的に学習できる特徴があります。D4RTでは、この仕組みを動画の時空間理解に応用していると考えられます。
クエリが独立しているため、現代のAIハードウェアで並列処理が可能です。Google DeepMindによれば、これにより数個のポイント追跡からシーン全体の再構築まで、極めて高速かつスケーラブルな処理を実現しているとのことです。
主要な機能と性能
D4RTの柔軟な定式化により、以下の4次元タスクを実行できます。
ポイントトラッキング:異なる時間ステップでピクセルの位置を問い合わせることで、3次元軌跡を予測します。重要な点として、オブジェクトが他のフレームで見えていない場合でも予測が可能です。この機能は、オクルージョン(遮蔽)が発生する実環境での物体追跡に有用と考えられます。
点群再構築:時間とカメラ視点を固定することで、シーンの完全な3次元構造を直接生成します。従来手法で必要だった個別のカメラ推定や動画ごとの反復最適化といった追加ステップが不要になります。
カメラポーズ推定:単一の瞬間を異なる視点から見た3次元スナップショットを生成・整列することで、カメラの軌跡を容易に復元できます。
技術レポート(arXiv:2512.08924)によれば、D4RTは広範な4次元再構築タスクで従来手法を上回る性能を示しました。定性的な比較では、他の手法が動的オブジェクトの重複や再構築の失敗に直面する中、D4RTは動く世界の堅実で連続的な理解を維持したとされています。
処理速度に関して、Google DeepMindは以下の数値を公表しています。テストでは、従来の最先端手法と比較して18倍から300倍高速に動作しました。具体例として、D4RTは1分間の動画を単一のTPUチップで約5秒で処理しました。従来の最先端手法では同じタスクに最大10分かかっており、120倍の改善を示したとのことです。
TPU(Tensor Processing Unit)は、Googleが開発した機械学習専用のプロセッサで、特に行列演算に最適化されています。単一チップでこの処理速度を実現できることは、デバイス上での実装可能性を示唆していると思います。
ベンチマーク評価の詳細
D4RTは複数の標準的なベンチマークで評価されました。
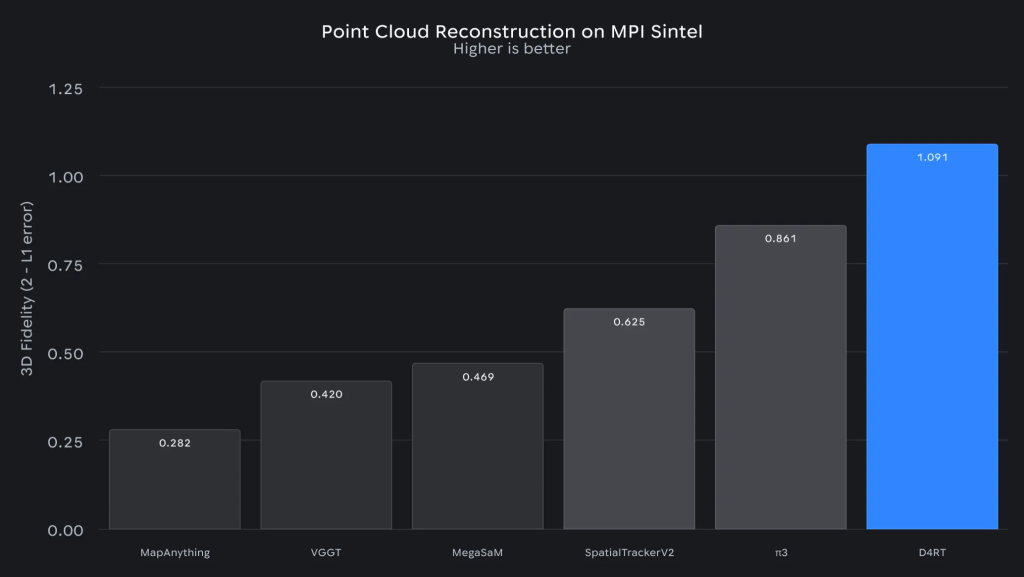
MPI Sintelベンチマーク:高速モーションブラーと非剛体変形を特徴とする複雑な合成シーンで評価されました。Google DeepMindによれば、D4RTは最近の強力なベースラインと比較して優れた忠実度を示し、オブジェクトやカメラが急速に移動する場合でも幾何学的構造を正確に再構築できることが確認されたとのことです。
MPI Sintelは、コンピュータビジョン分野で広く使用されるオプティカルフロー(画像内のピクセルの動きを表す情報)評価用のデータセットです。
Aria Digital Twinデータセット:スマートグラス映像を使用した3次元ポイントトラッキングで最高水準の性能を達成しました。これにより、現実的な家庭環境での複雑な自己運動とオクルージョンに対するモデルの堅牢な処理能力が検証されたとされています。
このデータセットは、一人称視点(エゴセントリック)での映像処理能力を測定するもので、ARグラスなどのウェアラブルデバイスでの利用を想定していると考えられます。
RE10kデータセット:多様な屋内外シーンでのカメラポーズ推定を評価し、D4RTは最高のAUC(Area Under the Curve)スコアを達成しました。Google DeepMindによれば、この指標は推定ポーズが厳密な精度閾値の範囲内に収まる頻度を追跡するもので、テスト時の最適化を必要とせずに安定した幾何学的構造に固定できるモデルの能力を示しているとのことです。
AUCは、一般的には分類モデルの性能評価指標ですが、ここではポーズ推定の精度分布を評価する指標として使用されています。
実用化への応用分野
Google DeepMindは、D4RTにより4次元再構築において精度と効率のトレードオフを選択する必要がなくなったと述べています。柔軟なクエリベースシステムは、動的な世界をリアルタイムで捉えることができ、次世代の空間コンピューティングへの道を開くとされています。
ロボティクス:ロボットは、動く人やオブジェクトが存在する動的環境をナビゲートする必要があります。D4RTは、安全なナビゲーションと器用な操作に必要な空間認識を提供できる可能性があります。特に製造現場や物流倉庫での活用が考えられます。
拡張現実(AR):ARグラスがデジタルオブジェクトを現実世界に重ねるには、シーンの幾何学的構造を瞬時に、低遅延で理解する必要があります。Google DeepMindによれば、D4RTの効率性はデバイス上での実装を現実的なものにすることに貢献するとのことです。
現在のARシステムの多くはクラウド処理に依存していますが、プライバシーや遅延の観点から、デバイス上での処理が望ましいとされています。D4RTの処理速度は、この課題を解決する可能性があります。
ワールドモデル:カメラの動き、オブジェクトの動き、静的な幾何学的構造を効果的に分離することで、D4RTは物理的現実の真の「ワールドモデル」を持つAIに一歩近づけるとされています。Google DeepMindは、これをAGI(汎用人工知能)への道における必要なステップと位置づけています。
ワールドモデルとは、AIが環境の内部表現を持ち、行動の結果を予測できる能力を指します。これは、強化学習や自律システムの研究で重要な概念とされています。
まとめ
Google DeepMindのD4RTは、動画から4次元(3次元空間+時間)を統合的に理解する新しいアプローチを提案しました。従来手法と比較して最大300倍の高速化を実現し、複数のベンチマークで優れた性能を示したことは、リアルタイム空間理解の実用化に向けた重要な進展と言えます。ロボティクス、AR、そしてAGIへの応用可能性について、今後の展開が注目されます。