はじめに
近年注目されている大規模言語モデル(LLM)は、目覚ましい発展を遂げ、社会に変化をもたらしつつあります。
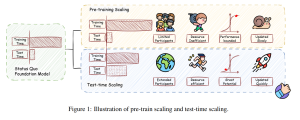
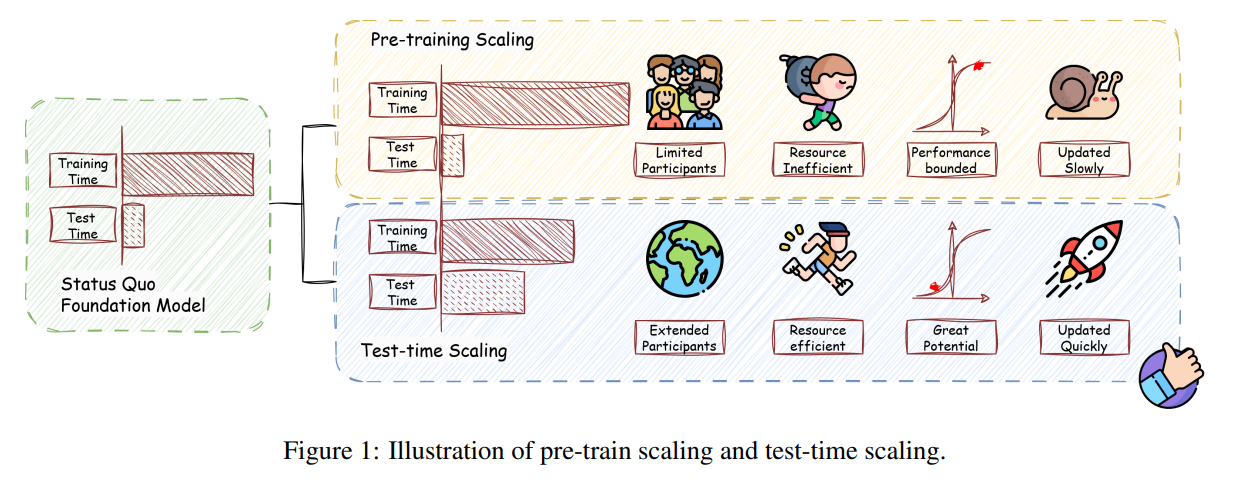
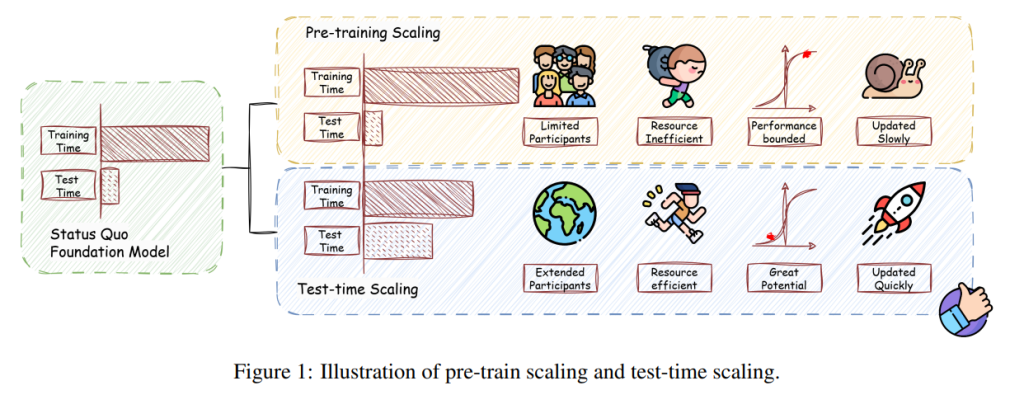
これらのモデルは、膨大なデータを事前学習することで汎用的な能力を獲得しますが、その潜在能力を最大限に発揮させるには、推論時(テスト時)の工夫が重要になります。そこで注目されているのが、「テストタイムスケーリング(TTS)」(または「テストタイムコンピューティング」)と呼ばれるアプローチです。
これは、LLMが与えられた問題に対し、推論時により多くの計算資源を投入することで、解答の質を高める技術群を指します。最近の研究では、TTSが数学やプログラミングのような専門的な推論タスクに加え、一般的な自由形式の質問応答においても有効性が示されています。
このようにTTSに関する研究は急速に進展していますが、その全体像を体系的に把握するための包括的な調査が求められていました。このニーズに応える形で発表されたのが、論文「What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models」です。この論文はTTSに関する包括的な調査を提供しています。
本稿では、上記論文を簡単にご紹介します。
引用論文
- 論文タイトル:What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models
- 論文URL:https://arxiv.org/abs/2503.24235
- 発表日:2025年3月31日
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
※より詳細を知りたい方は以下の詳細解説をした記事をご参考ください。
詳細説明
この論文は、「何を、どのように、どこで、そしてどれくらい良くスケールするのか?大規模言語モデルにおけるテスト時スケーリングに関する調査」と題されており、大規模言語モデル(LLM)の推論段階における計算資源の利用方法(テスト時スケーリング、TTS)について、包括的な調査を行っています。
テスト時スケーリング(TTS)とは何か?なぜ重要なのか?
近年、LLMは訓練データの増大とパラメータ数の増加(訓練時スケーリング)によって、汎用的な知能を獲得する上で目覚ましい進歩を遂げてきました。しかし、訓練されたLLMの能力を推論時に最大限に引き出し、現実世界での有効性を高める方法が重要な課題として残っています。この課題に対処するために注目されているのが、テストタイムスケーリング(TTS)です。
TTSは、推論時に追加の計算資源を投入することで、LLMの持つ問題解決能力をさらに引き出すことを目指す研究分野です。論文では、TTSが数学やコーディングといった専門的な推論タスクだけでなく、オープンエンドの質問応答のような一般的なタスクにおいても、大きなブレークスルーを可能にすることが示されていると指摘しています。
TTSの統一的フレームワーク:「What, How, Where, and How Well?」
論文では、TTSの研究を体系的に理解するための統一的で多次元的なフレームワークが提案されています。このフレームワークは、以下の四つの主要な側面から構成されています。
- 何をスケールするのか (What to Scale): 推論時にどのような計算やプロセスをスケールさせるのかという側面です。これには、並列スケーリング、逐次スケーリング、ハイブリッドスケーリング、内部スケーリングの四つのカテゴリがあります。
- 並列スケーリング (Parallel Scaling):
複数の候補となる出力を並行して生成し、その中から最適なものを選び出す手法です。自己整合性(Self-Consistency)や、複数のエージェントを協調させるMulti-Agentsなどが含まれます。 - 逐次スケーリング (Sequential Scaling):
モデルが段階的に思考や出力を洗練させていく手法です。自己改善(Self-Refine)や、Reasoning and Acting (ReAct) のように思考と行動を交互に行う手法、予算制約を考慮したBudget-awareな手法などが挙げられます。 - ハイブリッドスケーリング (Hybrid Scaling):
並列スケーリングと逐次スケーリングの利点を組み合わせた手法です。Tree of Thoughts (ToT) やGraph of Thoughts (GoT) のように、思考の木やグラフ構造を探索する手法、モンテカルロ木探索(MCTS)などが含まれます。論文では、並列スケーリングが広い範囲の思考を捉えることで誤った推論経路を見逃すリスクを軽減し、逐次スケーリングが有望な推論経路を深く探求することを可能にすると説明されています。 - 内部スケーリング (Internal Scaling):
モデル内部の計算メカニズムを活用する手法です。DeepSeek-R1やOpenAIのモデル(o1, o3)、Gemini Flash Thinkingなどの具体的なモデル名が例として挙げられています。
- 並列スケーリング (Parallel Scaling):
- どのようにスケールするのか (How to Scale): 実際にどのように計算やプロセスをスケールさせるのかという側面です。これには、チューニングに基づくアプローチと、推論に基づくアプローチの二つがあります。
- チューニングに基づくアプローチ (Tuning-based Approaches):
事前学習済みのLLMに追加の学習を行うことで、TTS能力を向上させる手法です。教師ありファインチューニング(SFT)や、強化学習(RL)が含まれます。特に強化学習においては、DeepSeek R1による検証可能な報酬を用いたRLや、誤差が生じやすい箇所を重点的に最適化する手法(cDPO, CPL, Focused-DPO, DAPO, RFTT)などが紹介されています。また、データの難易度をモデルの能力に合わせて調整するSelective DPOなども言及されています。 - 推論に基づくアプローチ (Inference-based Approaches):
モデルのパラメータは固定したまま、推論時の計算を動的に調整する手法です。これには、刺激(Stimulation)、検証(Verification)、探索(Search)、集約(Aggregation)の四つの主要なコンポーネントがあります。
- 刺激 (Stimulation):
モデルに、より長い出力や複数の候補出力を生成するように促す技術です。プロンプト戦略(段階的な思考を促す指示など)や、自己反復戦略(同じプロンプトを繰り返し与える)、複数のモデルを活用する混合モデル戦略などが含まれます。 - 検証 (Verification):
生成された出力の正しさや他の基準に基づいて、フィルタリングまたはスコアリングを行う技術です。プロセスの検証(中間ステップの評価)と結果の検証(最終的な答えの評価)の二つのタイプがあります。プロセスの検証では、Lightman et al. (2023) のように数学タスクでステップレベルの検証を行うPRM(Process Reward Model)を訓練する手法や、同じLMに以前のステップを踏まえて現在のステップを評価させる自己評価などが挙げられています。結果の検証では、外部の知識ベースを用いた事実確認などが紹介されています。 - 探索 (Search):
サンプル空間を体系的に探索する技術です。LLMが持つ知識をより深く活用するために、検索技術が応用されます。Tree Search、Graph Search、モンテカルロ木探索(MCTS)、ビームサーチなどが例として挙げられています。 - 集約 (Aggregation):
複数の出力を組み合わせて最終的な出力を決定する技術です。多数決(Majority Voting)、Best-of-N(複数の候補から最もスコアの高いものを選ぶ)、加重付きBest-of-N、合成(Synthesize)などが含まれます。
- 刺激 (Stimulation):
- チューニングに基づくアプローチ (Tuning-based Approaches):
- どこでスケールするのか (Where to Scale):
TTSがどのようなタスクや応用シナリオで有効なのかという側面です。論文では、推論(数学、コーディング、ゲーム&戦略、医療など)、汎用目的(基礎、エージェント、知識など)、オープンエンド、マルチモーダルといったカテゴリが挙げられ、それぞれのカテゴリにおける具体的なタスクやベンチマーク(MATH, GSM8K, WebShop, SimpleQA, AlpacaEvalなど)が紹介されています。 - どれくらい良くスケールするのか (How Well to Scale):
TTSの効果や効率性をどのように評価するのかという側面です。これには、性能(正答率Pass@kなど)、効率性(FLOPsに基づく計算コスト分析)、制御可能性(計算予算や出力長の制約への準拠)、スケーラビリティといった評価軸があります。
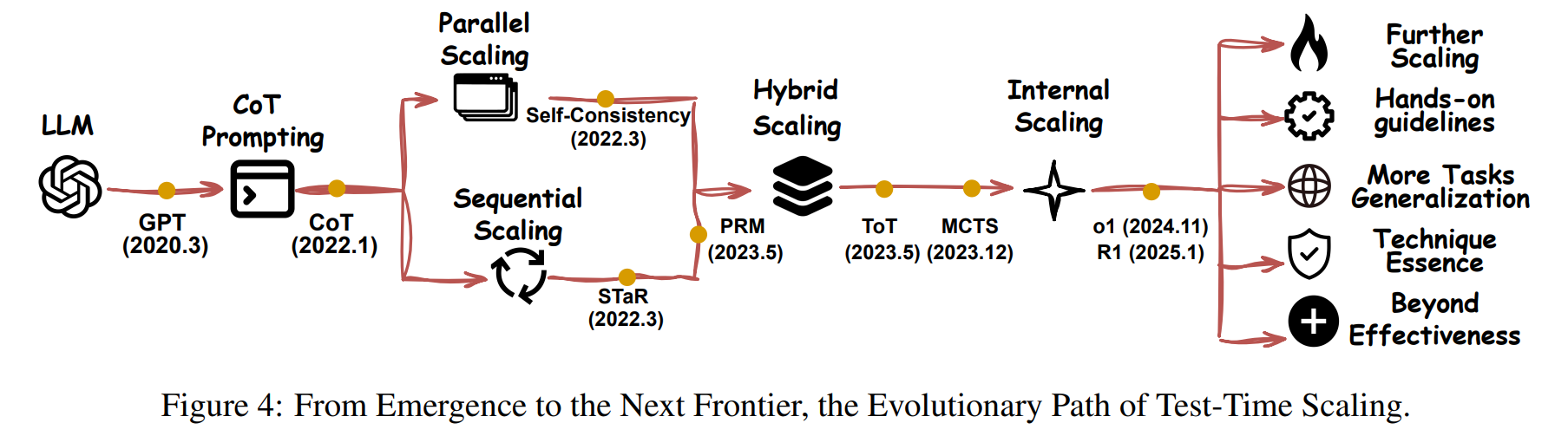
TSの発展の軌跡と実践的指針
論文では、LLMの登場からTTSの進化、そして今後の展望が図示されています。TTSは、単純なプロンプティングから始まり、Chain-of-Thought(CoT)プロンプティング、自己整合性、Tree of Thoughts、モンテカルロ木探索といったより複雑な手法へと発展してきました。論文では、様々なTTS手法が「What」「How」「Where」「How Well」の各側面でどのように分類されるかの概要表も提供されています。実践的な指針として、効果的なスケーリングには個々の技術を体系的に統合することが重要であると述べられています。例えば、DeepSeek-R1はSFTによるウォームアップとリジェクションサンプリングを必要としています。
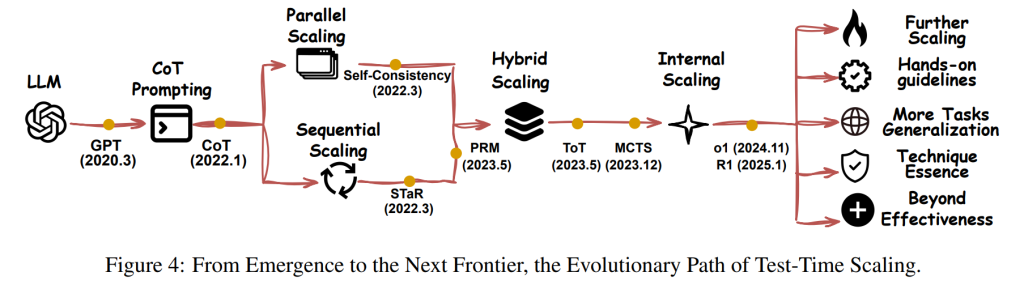
TTSのオープンな課題と将来の方向性
論文の結論では、TTSはポスト事前学習時代において最も有望な手法の一つであり、AGI(汎用人工知能)の実現に向けて重要な役割を果たすと述べられています。しかし、更なる発展のためには、いくつかのオープンな課題と有望な研究方向性が存在します。
- さらなるスケーリング: より複雑なタスクに対応するために、より効果的なスケーリング戦略が必要です。
- 技術の機能的本質の明確化: 各TTS技術がどのように効果を発揮するのか、その根本的なメカニズムをより深く理解する必要があります。
- より多くのタスクへの汎化: 現在のTTS技術は特定のタスクに特化している場合があるため、より幅広いタスクに適用できるように汎化する必要があります。
- より良い属性(Attributions): モデルの推論過程や意思決定の根拠をより明確に示すことができるようにする必要があります。
また、内部スケーリングは一度のプロンプトで済むため効率的ですが、チューニングに多大なリソースを必要とするため、すべての実践者が利用できるわけではないという効率性のトレードオフも指摘されています。
まとめ
この概要を把握することで、論文「What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models」の主要な内容と貢献を理解することができるでしょう。特に、TTSのフレームワーク、様々なスケーリング手法、評価軸、そして今後の課題と展望は、この分野の研究動向を把握する上で重要なポイントとなります。