
はじめに
LLMをプロダクトに組み込む際の最大の懸念事項の一つが「安全性」です。特に、悪意のあるユーザーが巧妙なプロンプトを用いて、爆発物の製造方法やサイバー攻撃の手順といった有害な情報を引き出そうとする「ジェイルブレイク」攻撃への対策は急務となっています。
しかし、防御を厳重にすればするほど、通常のユーザーへの回答拒否(誤検知)が増えたり、推論コストや遅延が増大したりするというトレードオフが発生します。本稿では、このトレードオフを大幅に解消する「Constitutional Classifiers++(憲法分類器++)」という新しいシステムをAnthropicが提案しています。内部表現を利用した軽量な「プローブ」や、段階的な分類器の組み合わせにより、計算コストを従来の40分の1に削減しつつ、実環境での拒否率を0.05%に抑えることに成功したという実践的な内容です。
解説論文
- 論文タイトル: CONSTITUTIONAL CLASSIFIERS++: EFFICIENT PRODUCTION-GRADE DEFENSES AGAINST UNIVERSAL JAILBREAKS
- 論文URL: https://arxiv.org/pdf/2601.04603
- 発行日: 2026年1月8日
- 発表者: Hoagy Cunningham, Jerry Wei, et al. (Anthropic)
要点
- 前世代の防御システムの脆弱性を克服:入力と出力を別々に審査する従来の手法では防げなかった「再構築攻撃(入力を分散させる)」や「難読化攻撃(出力を暗号化・比喩化する)」に対し、入力と出力をセットで評価する「エクスチェンジ分類器(Exchange Classifier)」を導入して堅牢性を高めた。
- 計算コストの大幅な削減:すべてのトラフィックを重い分類器に通すのではなく、軽量な分類器でスクリーニングし、怪しい場合のみ高精度な分類器に回す「2段階カスケード(Two-Stage Cascade)」アーキテクチャを採用した。
- 線形プローブによる超高速検知:モデルの内部状態(アクティベーション)を直接監視する軽量な「線形プローブ(Linear Probe)」を開発し、外部分類器と同等の精度を無視できるほどの低コストで実現した。
- プロダクショングレードの性能:これらを組み合わせた最終システムは、従来のシステムと比較して計算コストを約40分の1に削減し、本番環境での拒否率を0.05%という極めて低い水準に維持しつつ、1,700時間以上のレッドチーミング(攻撃テスト)において、完全なジェイルブレイクを許さなかった。
詳細解説
以下、論文の構成に従い、各項目の詳細を解説します。
1 INTRODUCTION(はじめに)
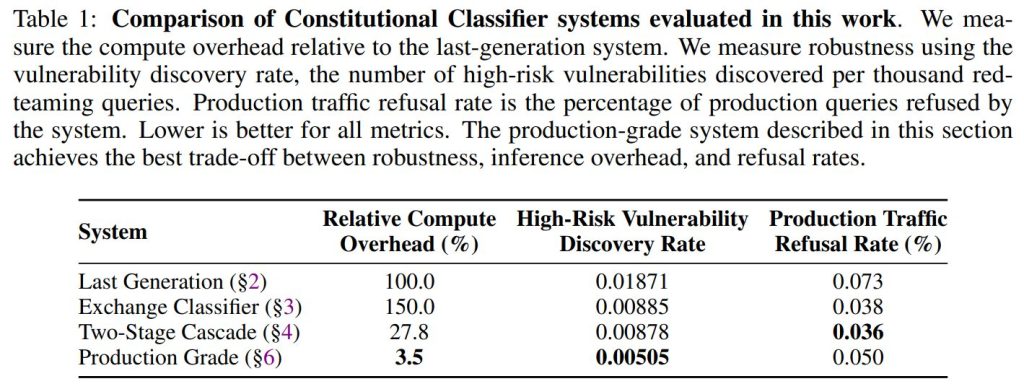
大規模言語モデルに対するジェイルブレイク防御、特にCBRN(化学・生物・放射性・核)兵器などの高リスクな脅威を防ぐことは極めて重要です。Sharmaら(2025)が提案した「Constitutional Classifiers(憲法分類器)」は有望なアプローチでしたが、本番環境での計算コスト(23%のオーバーヘッド)や拒否率(0.38%)が高く、導入には課題がありました。本研究では、堅牢性を高めつつ、これらのコストと誤検知率を大幅に改善するシステムを提案しています。
2 VULNERABILITIES OF LAST-GENERATION CONSTITUTIONAL CLASSIFIERS(前世代の憲法分類器の脆弱性)
前世代のシステムは、入力プロンプトを検査する分類器と、生成された出力を検査する分類器の2つで構成されていました。しかし、新たなテストにより以下の脆弱性が明らかになりました。
(a) Reconstruction Attacks(再構築攻撃)
攻撃者は有害な情報を複数の無害なセグメントに分割して入力フィルターを回避します。例えば、有害なクエリをコード内の複数の関数に分散させ、モデルにそれらを再構築させて実行させる手法です(Figure 1a参照)。
(b) Obfuscation Attacks(難読化攻撃)
出力のみを見る分類器を回避するため、モデルに出力を難読化させます。例えば、危険な化学物質の名前を「冬の息吹」のような比喩表現に置き換えたり、暗号化したりすることで、文脈を知らない出力分類器の目を欺きます(Figure 1b参照)。

Such jailbreaks tend to reduce model capabilities, but by significantly varying degrees.(ジェイルブレイク攻撃によるモデル性能への影響)
ジェイルブレイク攻撃は一般的にAIモデルの能力を低下させる傾向がありますが、その低下の度合いには大きな「ばらつき」があります。
検証結果 (Claude Opus 4 / GPQA Diamond)として、リクエストの分割や出力の難読化を行う2種類の攻撃手法でテストした結果、モデルの推論能力は以下のように変化しました。
- 通常時: 正答率 74.2%
- 攻撃手法1: 正答率 32.3% (大幅な低下)
- 攻撃手法2: 正答率 49% (低下するも、手法1よりは高い)
結論と懸念として、攻撃がモデルの能力を大きく損なうことは確認されましたが、手法によってその影響度にはかなりの差があります。この事実は、攻撃者が将来的に「モデルの高い能力を維持したまま、安全対策を突破する」うな、より高度な攻撃手法を開発できる可能性を示唆しており、懸念すべき点です。
3 EXCHANGE CLASSIFIERS(エクスチェンジ分類器)
本セクションでは、前世代のシステムの脆弱性(再構築攻撃や難読化攻撃)に対処するために提案された、新しい分類アプローチについて詳述されています。
Concept and Mechanism(概念とメカニズム)
従来の「入力分類器」と「出力専用分類器」を組み合わせたシステムを置き換えるものとして、「エクスチェンジ分類器(Exchange Classifier)」が提案されました。
この分類器は、入力プロンプトを単独で評価するだけでなく、モデルの応答生成中も継続的に監視を行います。生成されるトークンをバッチ単位で評価する際、単に出力だけを見るのではなく、「入力コンテキスト全体の中でその出力がどういう意味を持つか」を評価します。
プロンプトキャッシング技術を利用することで、計算オーバーヘッドを抑えつつこのアプローチを実現しています。
Addressing Vulnerabilities(脆弱性への対処)
エクスチェンジ分類器は、以下の理由から前述の攻撃に対して堅牢です。
- 再構築攻撃に対して:攻撃者が入力を断片化して隠しても、モデルが応答を開始すると、断片化された情報が再構築され、分類器が検知可能な形になります。
- 難読化攻撃に対して:出力分類器だけでは見抜けない「暗号」や「比喩」も、入力コンテキストと照らし合わせることで容易に特定できます。例えば、化学物質を「食品の香料」と言い換えるような手口も、入力で「爆弾の作り方」を聞いている文脈があれば、有害であると判断できます。
Robustness Evaluation(堅牢性評価)
人間によるレッドチーミング(攻撃テスト)を行い、前世代システムと比較検証しました。
- システム構成:前世代システム(入力+出力分類)と、エクスチェンジ分類器単体(Claude Haiku 3.5をファインチューニング)を比較しました。なお、エクスチェンジ分類器はHaikuクラスのモデルを使用するため、前世代システムと比較して計算コストが約50%増加します。
- 結果:
- 脆弱性の数:前世代システムでは69.5万回のクエリで13件の高リスク脆弱性が見つかりましたが、エクスチェンジ分類器では22.6万回のクエリでわずか2件でした。発生率で見ると、エクスチェンジ分類器の方が半分以下(0.01871件/千回 vs 0.00885件/千回)に抑えられています。
- 発見までの時間:前世代システムでは、平均27時間で「普遍的なジェイルブレイク(すべてのターゲット質問に回答させる攻撃)」が発見されましたが、エクスチェンジ分類器では発見に100時間を要しました。
4 TWO-STAGE CLASSIFICATION REDUCES COMPUTATIONAL COSTS(2段階分類による計算コストの削減)
セクション3で提案されたエクスチェンジ分類器は堅牢ですが、計算コストが50%増加するという課題がありました。本セクションでは、このコストを削減するためのアーキテクチャについて説明されています。
Classifier Cascade Architecture(分類器カスケードアーキテクチャ)
すべてのやり取りを高コストな分類器に通すのではなく、「カスケード(滝)」型の構成を採用しました。
- 第1段階(First-stage):軽量で安価な分類器がすべての入力をスクリーニングします。
- 第2段階(Second-stage):第1段階でフラグが立てられた(怪しい)やり取りのみが、より高精度で高価な第2段階の分類器に送られます。
Escalation vs Refusal(エスカレーション対拒否)
重要な設計思想として、第1段階でフラグが立っても即座に「拒否」するのではなく、第2段階へ「エスカレーション(送付)」するだけという点が挙げられます。
これにより、第1段階の分類器は誤検知(False Positive)率が高くても許容されます。つまり、少しでも疑わしいものはすべて第2段階に回すという運用が可能になるため、安価で弱いモデルでも十分な検出力を発揮できます。これは「適応的計算(Adaptive Computation)」の一形態であり、入力の複雑さに応じて計算コストを配分する仕組みです。
Experiment Details(実験詳細)
- モデル構成:第2段階にはClaude Haiku 4.5ベースの分類器を使用し、第1段階にはその約3分の1のサイズ/コストの内部モデルを使用しました。
- キャリブレーション:第2段階は約0.1%の拒否率になるよう調整され、第1段階はレッドチーミングデータの大部分をフラグ付けするように閾値が設定されました。結果として、全トラフィックの約10%が第2段階にルーティングされる設定となりました。
Results(結果)
- 堅牢性の維持:レッドチーミングの結果、高リスク脆弱性の発見率は0.00878件/千回であり、セクション3のエクスチェンジ分類器単体と同等の堅牢性を維持していることが確認されました。また、すべてのターゲット質問に回答させるような完全なジェイルブレイクは発見されませんでした(ただし、懸賞プログラム外の専門家によるツールを用いた攻撃では発見されました)。
- 劇的なコスト削減:このシステムは、モデルの更新やパイプラインの最適化と合わせることで、セクション3の単一エクスチェンジ分類器システムと比較して、計算コストを5.4倍削減することに成功しました。第1段階の処理がシステム全体のコストの約77%を占める構成となっています。
5 EFFICIENT CLASSIFICATION VIA LINEAR PROBES(線形プローブによる効率的な分類)
このセクションでは、計算コストを削減しつつ堅牢性を確保するために、モデルの内部表現(アクティベーション)を直接利用する「線形プローブ」の設計と評価について詳述されています。
5.1 METHODOLOGY(方法論)
Problem setup(問題設定)
ここでは、ユーザーとAIのやり取り(Exchange)全体が有害かどうかを判定するタスクを扱います。教師データとなるラベル \( y^{(i)} \) は対話全体に対して付与されていますが、実際の運用では、モデルがトークンを生成するたびにストリーミングで監視し、有害な内容が出た瞬間に停止させる必要があります。
Linear probe architecture(線形プローブアーキテクチャ)
最も単純なアプローチは、各トークン位置 \( t \) における中間層のアクティベーション \( \psi_t \) を入力として、その時点での有害確率を予測する線形モデルです。
\( p_{probe}(y^{(i)}=1 \mid x^{(i)}_{1:t}) = \sigma(W^\top \psi_t(x^{(i)}_{1:t}) + b) \)
ここで \( \sigma \) はシグモイド関数、\( W, b \) は学習可能なパラメータです。複数の層のアクティベーションを結合して使用します。
Training modifications(学習時の工夫)
単なる線形モデルでは精度が不十分なため、以下の2つの重要な修正を加えています。
- Sliding Window Mean (SWiM) Logit Smoothing(スライディングウィンドウ平均ロジット平滑化)
学習時、ロジット(活性化関数を通す前の値)を過去 \( M \) トークン分で平均化します。
\( \bar{z}t(x^{(i)}) = \frac{1}{M} \sum_{k=0}^{M-1} [W^\top \psi_{t-k} + b] \)
これにより、単発のトークンによるスパイク(誤検知)を防ぎ、一貫して有害な兆候がある場合のみフラグを立てるようになります。なお、推論時(デプロイ時)には計算効率のために、スライディングウィンドウの代わりに指数移動平均(EMA)を使用します。 - Softmax-Weighted Loss(ソフトマックス重み付き損失)
プローブが「有害である」と最も確信しているトークン位置に重みを置いて損失を計算します。
\( L(x^{(i)}) = \sum_{t=M}^{T_i} w_t \cdot L_{BCE}(y^{(i)}, \sigma(\bar{z}_t(x^{(i)}))) \)
重み \( w_t \) はロジットの指数関数に基づいて計算されます(\( w_t \propto \exp(\bar{z}_t/\tau) \))。
Justification for asymmetric weighting(非対称な重み付けの正当性)
なぜこの重み付けが必要なのでしょうか。対話全体のラベルが「有害」であっても、前半部分(プレフィックス)は無害である場合が多いためです。通常の損失関数を使うと、無害なプレフィックスに対して「有害」と予測しようとして学習が混乱したり、逆にプレフィックスでの「無害」という正しい予測にペナルティを与えてしまったりします。
提案手法では、ロジットが低い(無害と予測している)箇所の重みをほぼゼロにすることで、プレフィックス部分でのペナルティを回避します。一方で、無害なはずの文脈で自信を持って「有害」と誤判定した場合には、重みが大きくなり厳しくペナルティが課されます。これにより、ストリーミング検知に最適な挙動を学習させることができます。
Linear probes are inexpensive(線形プローブは低コスト)
線形プローブの計算コストは極めて低いです。例えばGemma 3 27Bの場合、プローブの計算量は1トークンあたり約377K FLOPsですが、モデル本体の推論には約80億 FLOPsかかります。プローブのコストは桁違いに小さく、実質的な追加コストはゼロに等しいと言えます。
5.2 ANALYSIS(分析)
Training details(学習の詳細)
Claude Sonnet 4のアクティベーションを使用してプローブを訓練しました。教師データには、憲法分類器(Constitutional Classifier)によって生成されたソフトラベル(確率値)を使用しています。比較対象として、セクション4で構築した第1段階・第2段階の外部分類器を使用しました。
Jailbreak data(ジェイルブレイクデータ)
約7,000件のレッドチーミングデータ(CBRN関連)を用いて堅牢性を評価しました。評価にはLLMベースの採点ルーブリックを使用しています。
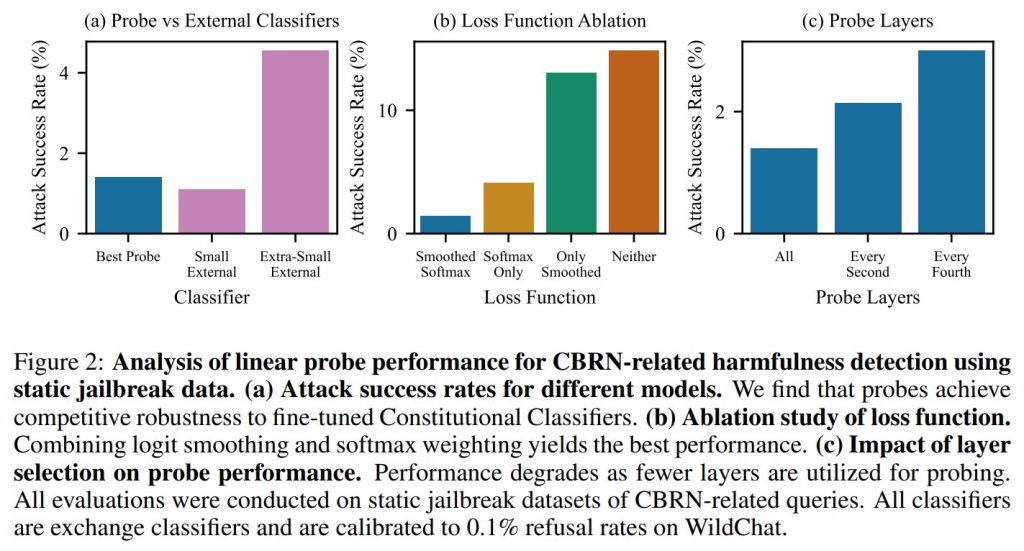
Probe robustness approaches external classifiers(プローブの堅牢性は外部分類器に匹敵する)
実験の結果、線形プローブの攻撃成功率(Attack Success Rate)は、非常に小さな外部分類器よりも低く、Claude Haiku 4.5ベースの分類器にほぼ匹敵する性能を示しました。これは、線形プローブがカスケード防御の第1段階として十分に実用的であることを示唆しています。
Softmax weighting and smoothing are critical for probe performance(ソフトマックス重み付けと平滑化は重要)
アブレーション研究(構成要素を抜いて影響を見る実験)により、ロジット平滑化(Smoothing)とソフトマックス重み付け(Softmax Weighting)のどちらを欠いても性能が低下することが確認されました。両方を組み合わせることで最良の結果が得られます。
Multi-layer probing substantially improves performance(多層プロービングによる性能向上)
使用する層の数についても検証されました。一部の層だけでなく、全層のアクティベーションを使用したときに攻撃成功率が最も低く(約1.4%)、層を減らすと性能が一貫して低下することがわかりました。
5.3 COMBINING PROBES AND CLASSIFIERS(プローブと分類器の結合)
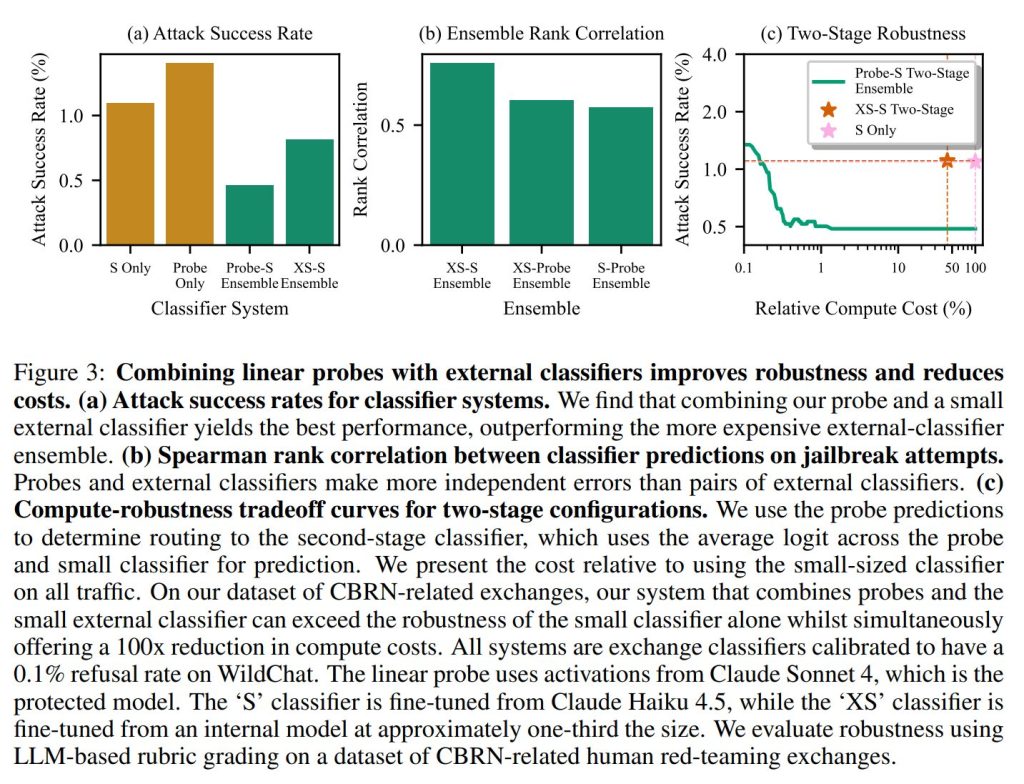
Ensembling improves robustness(アンサンブルによる堅牢性の向上)
プローブと外部分類器のスコアを加重平均してアンサンブル(組み合わせ)を行いました。その結果、「プローブ」と「小型外部分類器(Small External Classifier)」を組み合わせた場合が最も高い堅牢性を示し、外部分類器同士を組み合わせるよりも優れた結果となりました。
Probes provide complementary predictions to external classifiers(プローブは外部分類器と補完的な予測を提供する)
なぜプローブとの組み合わせが良いのかの相関分析を行った結果、プローブと外部分類器の予測の相関は、外部分類器同士の相関よりも低いことがわかりました。これは、プローブが外部分類器とは異なる特徴やシグナルを捉えており、互いの弱点を補完し合っている(相補性がある)ことを示唆しています。
Probe-classifier cascades reduce computational overhead(プローブと分類器のカスケードによる計算コスト削減)
最後に、プローブを「フィルター」として使い、プローブの確信度が高い場合のみ外部分類器に回す「カスケード構成」を検証しました。
この構成により、小型分類器単体で運用する場合と比較して、計算コストを100倍削減しながら、同等以上の堅牢性を達成できることが実証されました。これにより、非常に低コストで強力な防御システムを構築可能になります。
6 PRODUCTION-GRADE CONSTITUTIONAL CLASSIFIERS(プロダクショングレードの憲法分類器)
本セクションでは、これまでのセクションで紹介された技術(エクスチェンジ分類、カスケード構成、線形プローブ)を統合し、高い堅牢性と低い誤検知率、そして低コストを同時に実現した最終的なシステム構成とその評価結果について詳述されています。
System architecture(システムアーキテクチャ)
最終的な「プロダクショングレード」のシステムは、重み付きの2段階分類器カスケード(Weighted Two-Stage Classifier Cascade)を採用しています。
- 第1段階(First-stage):軽量な「線形プローブ」が生成中のすべてのやり取り(Exchange)を監視します。プローブのスコアが閾値を超えた場合のみ、第2段階へエスカレーションされます。
- 第2段階(Second-stage):エスカレーションされたやり取りに対し、より高精度な外部の「憲法分類器(Claude Haiku 4.5をファインチューニングしたもの)」が評価を行います。
- 最終判定:第2段階での最終的なスコアは、プローブのロジットと外部分類器のロジットを加重平均して算出されます。具体的には以下の式が用いられます。 \( z_{final} = 0.55 \cdot z_{probe} + 0.45 \cdot z_{classifier} \) なお、このシステムはClaude Sonnet 4.5を保護するために構築されており、プローブはそのモデルのアクティベーションを利用しています。
Deployment metrics(デプロイメント指標)
このシステムを2025年12月1日から2026年1月1日まで、Claude Sonnet 4.5の実際のトラフィックに対してシャドウデプロイ(裏側で稼働させ評価)しました。その結果、以下の劇的な改善が確認されました。
- フラグ率(拒否率)の低減:実際のプロダクショントラフィックに対する拒否率は 0.05% でした。これは、Sharmaら(2025)が報告した0.38%と比較して大幅に低い数値です。
- エスカレーション率:第1段階のプローブが第2段階へエスカレーションしたトラフィックは約5.5%でした。
- 計算コストの削減:セクション3で提案された単一のエクスチェンジ分類器と比較して 約40倍、セクション4のプローブなしの2段階カスケードと比較しても 約8倍 のコスト削減を達成しました。
Robustness results(堅牢性評価の結果)
1,736時間(累積)にも及ぶ人間によるレッドチーミング(約19万8,000回の攻撃試行)を実施しました。
- 脆弱性の発見:発見された「高リスクな脆弱性」はわずか1件のみでした。これをクエリ1,000件あたりの発見率に換算すると0.005件となり、本論文で評価されたすべてのシステムの中で最も低い(優れた)値です。
- 発見までの時間:この脆弱性を発見するために要した時間は30時間であり、これも最短発見時間としては最も長い(攻撃が困難である)結果となりました。
- 普遍的ジェイルブレイクの阻止:重要な点として、8つのターゲット質問すべてに対して、防御なしのモデルと同等の詳細さで回答させるような「普遍的なジェイルブレイク」は1つも発見されませんでした。
7 RELATED WORK(関連研究)
本セクションでは、提案手法と既存の研究(適応的計算やモデル内部表現の利用)との位置づけや違いについて議論されています。
Adaptive computational schemes(適応的計算スキーム)
コンテンツモデレーションにおいて、コスト削減のために2段階の分類を行うアプローチは他にも存在します。
- OpenAIのアプローチとの違い:OpenAI(2025a;b)のシステムでは、第1段階に軽量な「トピックフィルター」を使用して生物学関連などの高リスク分野を特定しています。対照的に、本研究の第1段階は、トピックではなく「ジェイルブレイク試行そのもの」を明示的に検出対象としている点が異なります。
- その他の研究:Huaら(2025)は複数のモニターを組み合わせる最適戦略を、TARS(Kimら, 2025)はクエリの複雑さに応じて計算量を動的に割り当てる手法を研究しています。また、HybridLLMやAutoMixなどは、モデル間のルーティング(振り分け)による効率化を探求しています。本研究は、これら適応的計算の流れを汲みつつ、レッドチーミングによって堅牢性が検証された実用的なカスケード構成を実装した点に特徴があります。
Model-internals approaches(モデル内部を利用したアプローチ)
モデルの内部状態(アクティベーション)を分類に利用する手法についても比較が行われています。
- McKenzieら(2025)との違い:彼らもソフトマックス重み付きプローブやカスケードを研究していますが、彼らの手法はトークンスコアを集約して「シーケンス全体に対して1つの予測」を行うものです。一方、本研究は生成中の各トークンで連続的に予測を行う「ストリーミング分類器」を構築しています。また、本研究ではトークンごとの「損失」に重み付けを行っており(ロジットの集約ではない)、さらに「ロジット平滑化(Logit Smoothing)」を組み合わせることが性能向上に不可欠であることを示しました。
- その他の内部表現利用技術:有害性検知のための標準的なプローブ(Alain & Bengio, 2016など)以外にも、モデルの推論を途中で遮断するショートサーキット(Zou et al., 2024)や、潜在的敵対的トレーニング(Casper et al., 2024)、スパースオートエンコーダ(SAE)を用いた特徴量分類(Bricken et al., 2024)などが関連研究として挙げられています。
8 CONCLUSION(結論)
本研究は、入力の文脈を考慮するエクスチェンジ分類器、コストを抑えるカスケード構造、そして効率的な線形プローブを組み合わせることで、実用レベルのジェイルブレイク防御が可能であることを実証しました。これにより、Constitutional Classifiersは理論上の存在から、プロダクト導入可能な実用的なセーフガードへと進化しました。
まとめ
本稿では、LLMの安全性を守るための最新技術「Constitutional Classifiers++」について解説しました。
単に強力なモデルを防御に使うのではなく、「プローブ」のような軽量な手法を最前線に配置し、段階的にコストをかけるアーキテクチャ設計が、セキュリティとユーザー体験(低遅延・低拒否率)を両立させる鍵であることがわかります。特に、モデルの内部状態を利用した検知手法は、今後LLMアプリのセキュリティ対策において標準的なアプローチになる可能性があります。








