はじめに
近年、大規模言語モデル(LLM)は目覚ましい発展を遂げています。まるで人間のように自然な文章を生成するAIの能力に驚かれた方も多いのではないでしょうか。実は、このLLMの内部的な仕組みと、私たち人間の脳が言葉を処理する方法には、驚くべき類似点があることが最新の研究で明らかになってきました。
本稿では、Google Researchがプリンストン大学などと共同で行った研究結果を発表した記事「Deciphering language processing in the human brain through LLM representations」を基に、LLMと脳の言語処理の関連性について、わかりやすく解説していきます。
参照元記事
- 記事タイトル: Deciphering language processing in the human brain through LLM representations
- URL: https://research.google/blog/deciphering-language-processing-in-the-human-brain-through-llm-representations/
- 発行日: 2025年3月21日
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 人間の脳の神経活動は、LLMが日常会話を処理する際の内部的な埋め込み(embeddings)表現と線形な対応(一方が変化すれば、もう一方も一定の割合で変化する関係)を示します。
- 言葉を理解する時(聞く時)と生成する時(話す時)では、脳の活動とLLMの埋め込み表現が対応する順序が異なります。
- 脳の言語処理には「ソフトな階層性」があり、特定の機能に特化した領域だけでなく、他の領域も関連情報(音響情報や意味情報)を処理していることが示唆されました。
- LLMと人間の脳は、次にくる単語を予測するという基本的な計算原理を共有している可能性があります。
詳細解説
LLMと言語処理の基本
まず、大規模言語モデル(LLM)とは何か、簡単におさらいしましょう。LLMは、インターネット上の膨大なテキストデータを学習し、文法的なルールを明示的に教えられなくても、文脈に合った自然な文章を生成したり、質問に答えたりできるAIモデルです。ChatGPTなどがその代表例です。
LLMは、単語や文の意味・文脈を埋め込み(embeddings)と呼ばれる数値のベクトル(多次元の数値の組)として表現します。これにより、単語間の関連性や文全体の意味を捉えることができます。例えば、「王様」から「男性」を引き、「女性」を足すと「女王様」に近いベクトルになる、といった計算が可能になります。
研究内容:脳活動とLLMの内部表現を比較
今回の研究では、研究チームは、てんかん治療のために脳内に電極を埋め込んだ患者が自然な会話をしている際の脳活動データを記録しました。そして、その脳活動パターンと、Whisperという音声認識LLM(文字起こしAI)が同じ会話音声を処理した際の内部的な埋め込み表現(音声の特徴を表す「音声埋め込み」と、単語の意味や文脈を表す「言語埋め込み」)を比較しました。
明らかになった脳とLLMの連携
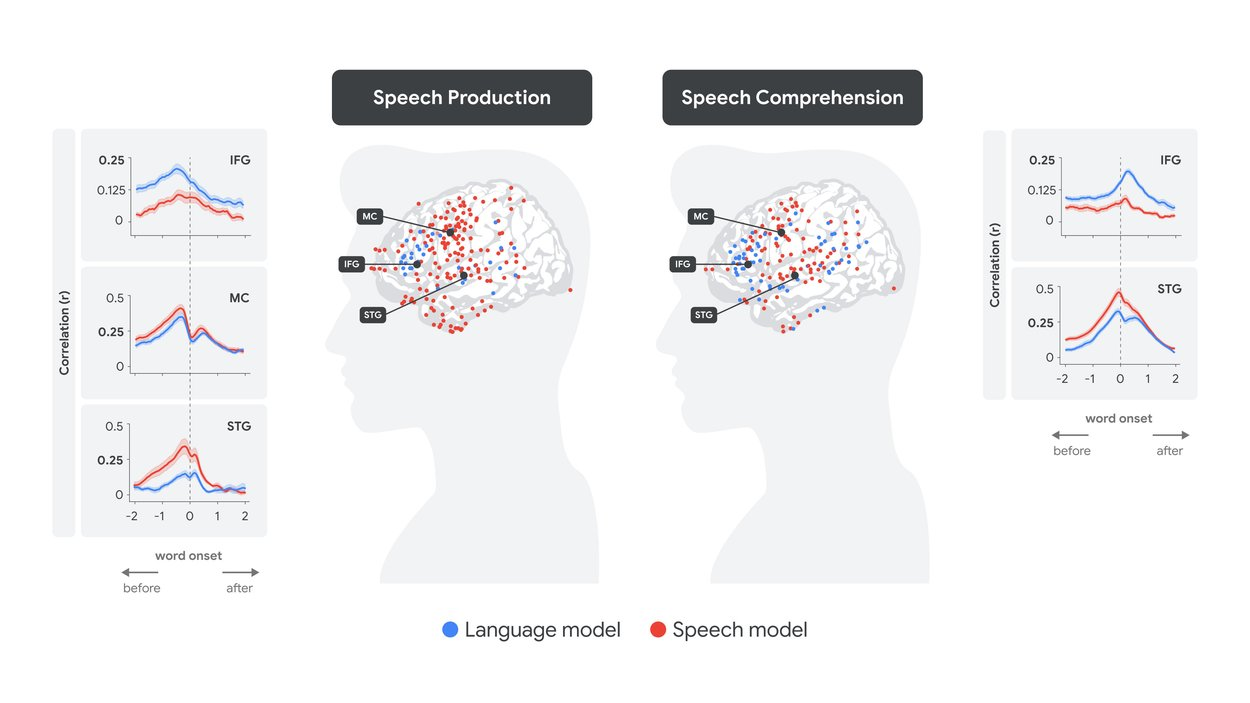
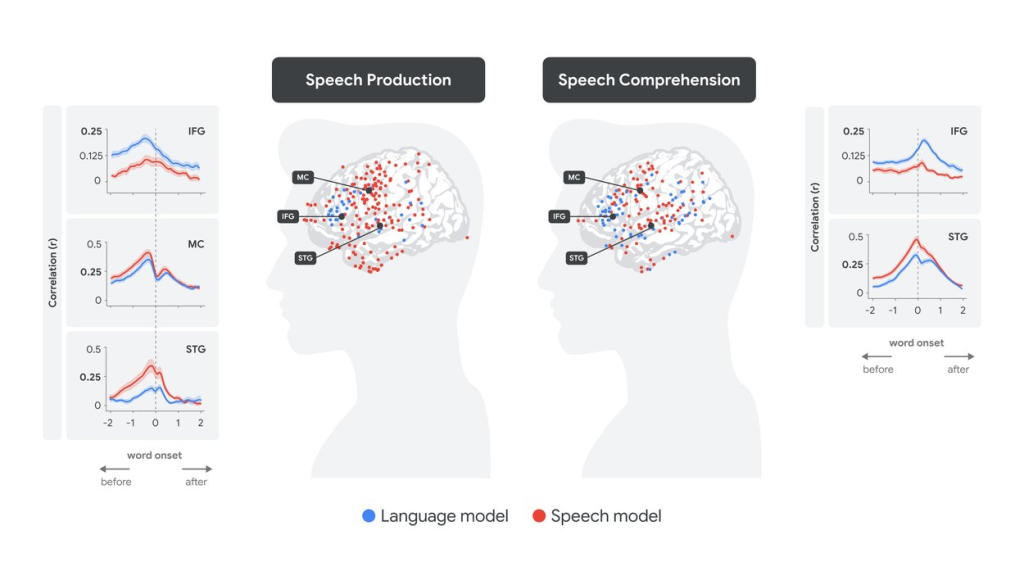
その結果、驚くべきことに、特定の脳領域の活動とLLMの埋め込み表現の間に、明確な線形な対応が見られました。
- 言葉を理解する時(聞く時):
- まず、音声の特徴を処理する脳領域(上側頭回; STG – 耳に近い側頭葉の一部)の活動が、Whisperモデルの音声埋め込みと対応しました。
- 少し遅れて、言語の意味理解に関わる脳領域(ブローカ野; 下前頭回; IFG – 前頭葉の一部)の活動が、Whisperモデルの言語埋め込みと対応しました。
これは、私たちが音を聞き取り、その後に意味を理解するという処理の流れと一致しています。
- 言葉を生成する時(話す時):
- まず、話す内容(単語の意味)を計画する段階で、ブローカ野(IFG)の活動が言語埋め込みと対応しました。
- 次に、どのように発音するかを計画する段階で、口や舌の動きを制御する運動野(MC)の活動が音声埋め込みと対応しました。
- 最後に、実際に発話し、自分の声を聞く段階で、上側頭回(STG)の活動が音声埋め込みと対応しました。
これは、話す内容を考え、発音方法を計画し、実際に話して確認するという、私たちが話す際のプロセスを反映していると考えられます。
「ソフトな階層性」と「予測」
さらに興味深いのは、「ソフトな階層性」という概念です。言語の意味処理が主とされるブローカ野(IFG)も音声の特徴(音声埋め込み)と弱いながら対応し、逆に音声処理が主とされる上側頭回(STG)も単語の意味(言語埋め込み)と弱いながら対応していました。これは、脳の各領域が完全に独立して機能しているのではなく、相互に連携し、情報を柔軟に処理している可能性を示唆しています。
また、別の研究では、人間の脳もLLMと同様に、次にくる単語を予測しようとしていること、そしてその予測の確信度が、実際に単語を聞いた後の脳の反応(驚き具合)に影響を与えることが示されています。
LLMと脳の違いと今後の展望
もちろん、LLMと人間の脳は全く同じではありません。脳の神経回路の構造や学習プロセスは、現在のLLMのアーキテクチャとは大きく異なります。脳は、社会的環境の中で、身体的な経験を通して言語を獲得していきます。
しかし、今回の研究結果は、LLMが人間の言語処理を理解するための新たな計算フレームワークを提供しうることを示しています。研究チームは今後、人間の経験により近い学習方法やデータを取り入れることで、より生物学的に妥当で、現実世界でより良く機能する新しいAIの開発を目指しています。
まとめ
本稿では、LLMの内部表現と人間の脳の言語処理活動の間に驚くべき線形な対応があることを示したGoogle Researchの研究を紹介しました。特に、言葉の理解時と生成時で脳活動とLLM表現の対応順序が異なることや、脳機能の「ソフトな階層性」、そして「次単語予測」という共通の計算原理の存在は、非常に興味深い発見です。
この研究は、LLMが単なる工学的なツールに留まらず、人間の脳という複雑なシステム、特に言語という根源的な能力を理解するための鍵となりうる可能性を示唆しています。今後の研究によって、AIと脳科学が互いに影響を与え合い、新たな知見が生み出されていくことが期待されます。