はじめに
OpenAIが2025年12月16日、AI の科学研究能力を評価する新しいベンチマーク「FrontierScience」を発表しました。物理学、化学、生物学の専門家レベルの科学的推論能力を測定するもので、GPT-5.2は最高性能を記録しています。本稿では、この発表内容をもとに、FrontierScienceの概要と評価結果、今後の科学研究への影響について解説します。
参考記事
- タイトル: Evaluating AI’s ability to perform scientific research tasks
- 発行元: OpenAI
- 発行日: 2025年12月16日
- URL: https://openai.com/index/frontierscience/
要点
- FrontierScienceは物理学、化学、生物学の専門家レベルの科学的推論能力を評価する新しいベンチマークである
- Olympiadトラック(100問)とResearchトラック(60問)の2つで構成され、国際オリンピックメダリストや博士研究者が問題を作成・検証している
- GPT-5.2がFrontierScience-Olympiadで77%、Researchで25%のスコアを記録し、他の最先端モデルを上回る性能を示した
- Researchトラックでは10点満点のルーブリック(採点基準)を用いて、最終答案だけでなく中間推論ステップの正確性も評価する
- ベンチマークには限界もあり、実際の科学研究で重要な新規仮説の生成や実験システムとの相互作用は評価対象外である
詳細解説
FrontierScience開発の背景
OpenAIによれば、2023年11月に発表されたGPQA(博士課程の専門家が作成した科学ベンチマーク)では、GPT-4が39%のスコアを記録し、専門家ベースライン70%を大きく下回っていました。しかし2年後、GPT-5.2は92%を達成しています。モデルの推論能力と知識が向上し続ける中、科学研究を加速する能力を測定・予測するには、より難易度の高いベンチマークが必要とされています。
従来の科学ベンチマークは、主に多肢選択式の問題に焦点を当てており、既に性能が飽和しているか、科学に特化していないものが多いという課題がありました。GPQAのような既存ベンチマークは、AIモデルの科学的知識を評価する上で重要な役割を果たしてきましたが、より複雑で開放的な問題形式への対応が求められていると考えられます。
FrontierScienceの構成と特徴
FrontierScienceは700問以上のテキスト問題(ゴールドセットは160問)で構成され、物理学、化学、生物学のサブフィールドを網羅しています。ベンチマークは2つのトラックに分かれています。
FrontierScience-Olympiadは、国際オリンピックメダリストが設計した100問で構成され、制約のある短答形式で科学的推論を評価します。Olympiadセットは、国際オリンピック競技会の問題と同等以上の難易度の理論問題を含むよう設計されました。42名の元国際メダリストまたは各分野の代表チームコーチが協力し、合計109個のオリンピックメダルを持つ専門家たちが問題を作成しています。
FrontierScience-Researchは、博士研究者(博士課程学生、教授、ポスドク研究者)が設計した60問のオリジナル研究サブタスクで構成され、10点満点のルーブリックを用いて採点されます。Researchセットは、博士研究者が研究中に遭遇するレベルの難易度を持つ、自己完結型の多段階サブタスクを含むよう作成されました。45名の適格な科学者と分野の専門家が協力し、量子電磁力学から合成有機化学、進化生物学まで、幅広い専門分野をカバーしています。
問題作成プロセスでは、OpenAI内部モデルに対する一定の選択が行われており(モデルが正解した問題は除外)、これらのモデルに対して評価が若干不利になる可能性があるとのことです。Olympiadゴールドセット100問とResearchゴールドセット60問はオープンソース化され、残りの問題は汚染(contamination)追跡のために非公開とされています。
採点方法の革新性
Olympiadセットは、数値、式、またはファジー文字列マッチングによる短答形式で採点可能です。この検証方法は正確性の確認に役立ちますが、OpenAIによれば、問題の表現力や開放性とのトレードオフがあるとのことです。
Researchセットでは、より開放的なタスクを採点するためのルーブリックベースのアーキテクチャが導入されています。各問題には複数の独立した客観的に評価可能な項目を含む採点基準があり、合計10点満点です。採点基準は最終答案の正確性だけでなく、中間推論ステップの正確性も評価し、詳細なモデル性能と失敗分析を可能にします。解答が10点中7点以上を獲得した場合、「正解」とみなされます。
短答またはルーブリック基準に対して、モデルベースの採点者(GPT-5)が各応答を評価します。OpenAIは、理想的には専門家の人間が各応答を採点することが望ましいものの、この方法はスケーラブルではないため、モデル採点者を使用してチェック可能なルーブリックを設計したと説明しています。ルーブリックと問題が難易度と正確性に適切に調整されているかを確保するための検証パイプラインが開発されました。
このルーブリックベースの評価は、従来の単一正解型評価では捉えきれない、研究における思考プロセスの質を評価できる点で意義があると考えられます。
モデル性能の評価結果
OpenAIによれば、GPT-5.2、Claude Opus 4.5、Gemini 3 Pro、GPT-4o、OpenAI o4-mini、OpenAI o3など、いくつかの最先端モデルがFrontierScience-OlympiadとFrontierScience-Researchで評価されました。すべての推論モデルは、GPT-5.2が「xhigh」で評価されたことを除き、「high」推論努力で評価されています。
初期評価では、GPT-5.2がFrontierScience-Olympiad(77%のスコア)とResearch(25%のスコア)で最高性能を記録し、他の最先端モデルを上回りました。Gemini 3 ProはOlympiadセットでGPT-5.2に匹敵する性能(76%のスコア)を示しています。
専門家レベルの問題、特に開放的な研究スタイルのタスクを解決する上で大きな進歩が見られました。OpenAIの分析によれば、最先端モデルは時に推論、論理、計算のエラーを起こし、ニッチな科学概念を理解できず、事実の不正確さがあったとのことです。これは、モデルがまだ完全に信頼できる研究パートナーではないことを示していると思います。
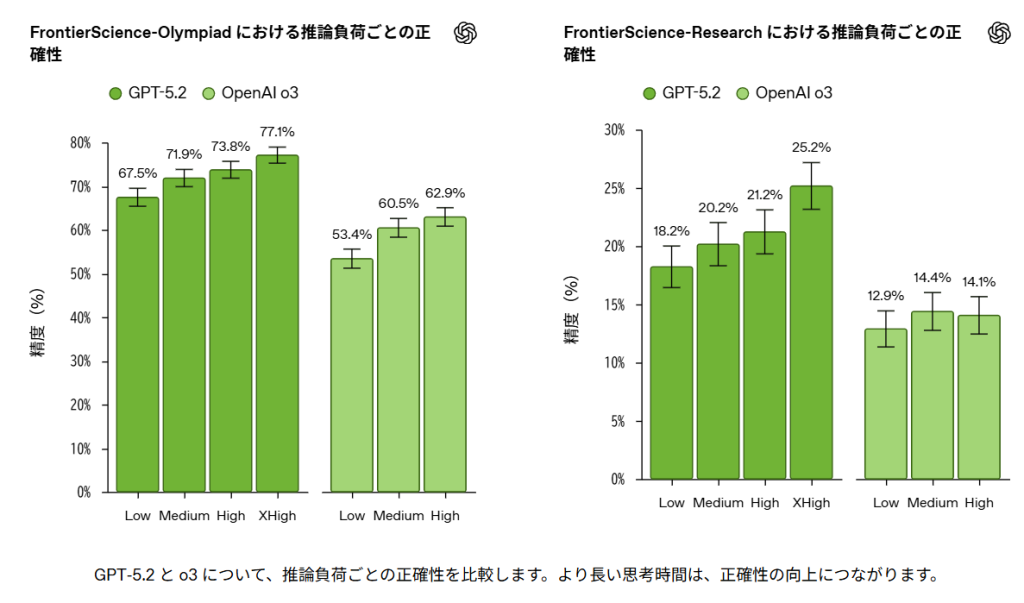
また、推論努力を高めることで精度が向上することも確認されています。GPT-5.2では、推論努力を「Low」から「XHigh」に上げることで、Olympiadセットで67.5%から77.1%に、Researchセットで18.2%から25.2%に精度が向上しました。この結果は、より長い思考時間が複雑な科学的推論において重要な役割を果たすことを示唆していると考えられます。
実際の科学研究への影響
OpenAIは2025年11月に発表した論文「Early science acceleration experiments with GPT-5」で、GPT-5が科学的ワークフローを測定可能に加速できる初期証拠を提示しています。研究者は、分野や言語を横断した文献検索、複雑な数学的証明への取り組みなどのタスクにこれらのシステムを使用しており、多くの場合、数日から数週間かかる作業を数時間に短縮しているとのことです。

FrontierScienceの結果は、現在のモデルが構造化された推論を含む研究の一部をすでにサポートできる一方で、開放的な思考を実行する能力を向上させるにはまだ大きな課題が残っていることを示しています。これは、科学者が今日のモデルをすでに使用している方法と一致しており、問題の枠組み設定と検証には人間の判断に依存しながら、研究ワークフローを加速させているとOpenAIは説明しています。
一般的な研究プロセスでは、仮説の生成、実験の設計、データの解釈、論文の執筆など、多様なタスクが含まれます。現在のAIモデルは、これらのうち特定のタスク(文献レビュー、データ分析、数式の検証など)では有用ですが、創造的な仮説生成や実験結果の解釈では人間の専門知識が不可欠と考えられます。
ベンチマークの限界と今後の展望
OpenAIは、FrontierScienceが科学ベンチマークの難易度において前進を表す一方で、まだ多くの限界があることを認めています。FrontierScienceは制約された問題文を持つ質問で構成されており、最終答案(Olympiad)または研究タスクを完了するための推論(Research)の評価に焦点を当てています。また、より長いタスクで複数の構成要素を持つルーブリックを使用することは、最終答案をチェックするよりも客観性が低いとのことです。
FrontierScienceは、難易度の高い専門家作成の質問に対するモデルの推論についての高解像度スナップショットを提供しますが、OpenAIによれば、実際に科学がどのように行われるかの全体像を示すものではありません。特に、モデルが真に新規な仮説をどのように生成するか、またはビデオデータや物理世界の実際の実験システムを含む複数のモダリティとどのように相互作用するかは評価していません。
実際の科学研究では、実験装置の操作、予期しない観察への対応、学際的な協力など、ベンチマークでは捉えきれない要素が多く含まれます。そのため、FrontierScienceは現在のAIの科学的能力を理解する上で有用なツールですが、実際の研究環境での応用可能性を判断するには、実世界での評価が必要と思います。
今後について、OpenAIは科学的推論の進歩が、より優れた汎用推論システムと科学的能力の改善に焦点を当てた取り組みの両方から生まれることを期待しているとのことです。FrontierScienceは多くのツールの1つであり、モデルが改善するにつれて、このベンチマークを繰り返し改良し、新しい分野に拡張し、これらのシステムが実際に科学者にできることを見る、より現実世界の評価と組み合わせる計画があるとしています。
まとめ
OpenAIのFrontierScienceは、AIの科学研究能力を測る専門家レベルの新しいベンチマークです。GPT-5.2が最高性能を記録した一方で、特に開放的な研究タスクでは改善の余地が大きく残されています。このベンチマークは、今日のAIシステムの弱点を理解し、モデルを科学的発見における信頼できるパートナーにするための作業に焦点を当てる上で役立つと考えられます。







