
はじめに
Googleは2025年12月13日、音声エージェント向けAIモデル「Gemini 2.5 Flash Native Audio」の大幅なアップデートを発表しました。本稿では、この発表内容をもとに、関数呼び出しの精度向上、指示追従の改善、そして新たに導入されたライブ音声翻訳機能について詳しく解説します。
参考記事
- タイトル: Improved Gemini audio models for powerful voice interactions
- 著者: Bibo Xu (Director of Product Management), Tara Sainath (Distinguished Research Scientist)
- 発行元: Google Blog
- 発行日: 2025年12月13日
- URL: https://blog.google/products/gemini/gemini-audio-model-updates/
要点
- Gemini 2.5 Flash Native Audioは、複雑なワークフローの処理、ユーザー指示のナビゲーション、自然な会話の保持において大幅に改善された
- ComplexFuncBench Audioベンチマークで71.5%のスコアを記録し、関数呼び出しの信頼性が向上した
- 開発者指示への遵守率が84%から90%に向上し、より信頼性の高い出力を実現している
- 70以上の言語と2000以上の言語ペアに対応したライブ音声翻訳機能が、Google Translateアプリで利用可能になった
- Google AI Studio、Vertex AI、Gemini Live、Search Liveで利用可能であり、企業向けカスタマーサービスエージェントの構築にも活用されている
詳細解説
Gemini 2.5 Flash Native Audioの3つの主要改善
Googleによれば、今回のアップデートでは、音声エージェントの実用性を高めるため、3つの重要な領域で改善が施されました。
関数呼び出しの精度向上については、外部関数をトリガーする際の信頼性が向上しました。モデルは会話中にリアルタイム情報を取得するタイミングをより正確に識別でき、そのデータを会話の流れを損なうことなく音声応答に織り込むことが可能になっています。ComplexFuncBench Audioという、複数ステップの関数呼び出しを様々な制約条件下で評価するベンチマークにおいて、Gemini 2.5 Native Audioは71.5%のスコアを記録しました。
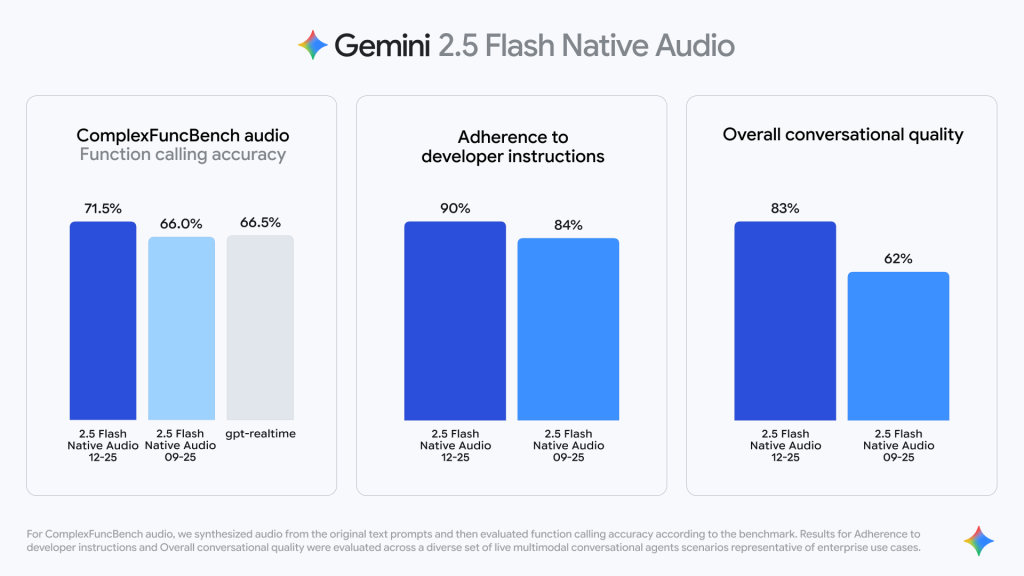
ComplexFuncBench Audioは、AI音声モデルが複数の関数を連続して呼び出す能力を評価する標準的なベンチマークです。実用的な音声エージェントでは、ユーザーの要求に応じて天気情報の取得、カレンダーの確認、メッセージ送信などを連続して実行する必要があるため、この能力は極めて重要と考えられます。
指示追従の堅牢性では、複雑な指示の処理能力が向上し、コンテンツの完全性に関するユーザー満足度が高まっています。開発者指示への遵守率は84%から90%に向上しており、より信頼性の高い出力を提供できるようになりました。
この6%の向上は、実用レベルでは大きな意味を持つと思います。開発者が構築した音声エージェントが、設計通りに動作する確率が高まることで、商用環境での導入ハードルが下がる可能性があります。
マルチターン会話の品質向上については、前回のターンからコンテキストをより効果的に取得できるようになり、より一貫性のある会話を実現しています。これにより、長時間の対話でも文脈を保持した自然なやり取りが可能になります。
企業での実用事例
GoogleのVertex AIを通じて、すでに複数の企業がGemini 2.5 Flash Native Audioを活用しています。
Shopifyでは、VP of ProductのDavid Wurtz氏が「ユーザーはSidekickを使い始めて1分以内にAIと話していることを忘れ、長い会話の後にボットに感謝することさえあります」と述べています。
United Wholesale Mortgage (UWM)では、Chief Technology OfficerのJason Bressler氏が「Gemini 2.5 Flash Native Audioモデルを統合することで、2025年5月のローンチ以降、Miaの機能を大幅に強化しました。この強力な組み合わせにより、ブローカーパートナー向けに14,000件以上のローンを生成できました」と報告しています。
これらの事例から、音声AIが実際のビジネスプロセスで成果を上げていることが分かります。特に金融や小売といった顧客対応が重要な分野での活用が進んでいる点は注目に値すると思います。
ライブ音声翻訳機能の導入
今回のアップデートでは、新たにライブ音声翻訳機能が導入されました。この機能は、継続的リスニングと双方向会話の両方に対応しています。
継続的リスニングモードでは、Geminiが複数の言語の音声を自動的に単一のターゲット言語に翻訳します。ヘッドフォンを装着するだけで、周囲の会話を自分の言語で聞くことができます。
双方向会話モードでは、2つの言語間のリアルタイム翻訳を処理し、誰が話しているかに基づいて出力言語を自動的に切り替えます。例えば、英語話者がヒンディー語話者と会話する場合、ヘッドフォンで英語の翻訳をリアルタイムで聞きながら、話し終わると携帯電話がヒンディー語を放送します。
Googleによれば、このライブ音声翻訳には以下の主要機能があります。
言語カバレッジは、70以上の言語と2000以上の言語ペアに対応しており、Geminiモデルの世界知識と多言語機能をネイティブオーディオ機能と組み合わせることで実現しています。これは、従来の音声翻訳サービスと比較しても広範な言語対応と言えます。
スタイル転送では、人間の音声のニュアンスを捉え、話者のイントネーション、ペース、ピッチを保持することで、翻訳が自然に聞こえるようになっています。単なる単語の置き換えではなく、話し方の特徴まで再現する点が特徴的です。
多言語入力は、単一のセッションで複数の言語を同時に理解できるため、言語設定を調整することなく多言語会話をフォローできます。
自動検出機能により、話されている言語を識別して翻訳を開始するため、どの言語が話されているか分からなくても翻訳を開始できます。
ノイズ耐性では、周囲の雑音をフィルタリングするため、屋外の騒がしい環境でも快適に会話できます。
この音声翻訳機能は、本日よりGoogle TranslateアプリのベータエクスペリエンスとしてAndroidデバイスで利用可能になっており、米国、メキシコ、インドで展開されています。iOSおよび他の地域への対応も近日中に予定されています。
利用可能性と今後の展開
Gemini 2.5 Flash Native Audioは、Vertex AIで一般提供されており、Gemini APIではプレビュー版として利用可能です。Google AI Studio、Gemini Live、Search Liveでも利用でき、Search Liveでは初めてネイティブオーディオの自然さが提供されます。
また、12月10日に発表されたGemini 2.5 FlashおよびGemini 2.5 Pro Text-to-Speech(TTS)モデルも、Google AI StudioのGemini API経由で利用可能です。これらのTTSモデルは、表現力の向上、ペーシング制御の精密化、シームレスな対話機能を提供します。
音声翻訳機能については、フィードバックに基づいて反復を続け、2026年にGemini APIを含むより多くのGoogleプロダクトに展開する予定とのことです。
まとめ
Googleの今回の発表は、音声AIの実用性を大きく前進させるものです。関数呼び出しの精度向上や指示追従の改善により、商用環境での音声エージェント導入が現実的になってきました。また、70以上の言語に対応したライブ音声翻訳機能は、グローバルコミュニケーションの新たな可能性を開くものと考えられます。今後、より多くの製品への統合が予定されており、音声インタラクションの進化が期待されます。








