
はじめに
Anthropicが2025年11月13日、AI言語モデルの政治的バイアスを測定する新しい評価手法「Paired Prompts」を公開しました。本稿では、この評価手法の詳細と、Claude Sonnet 4.5およびOpus 4.1の評価結果、他社モデルとの比較について解説します。
参考記事
メイン記事:
- タイトル: Measuring political bias in Claude
- 発行元: Anthropic
- 発行日: 2025年11月13日
- URL: https://www.anthropic.com/news/political-even-handedness
関連情報:
- タイトル: Political Even-handedness Evaluation
- 発行元: Anthropic GitHub
- 発行日: 2025年11月
- URL: https://github.com/anthropics/political-neutrality-eval
- タイトル: Appendix to Measuring political bias in Claude
- 発行元: Anthropic
- 発行日: 2025年11月
- URL: https://assets.anthropic.com/m/6d60bab0580089e2/original/Appendix-to-Measuring-political-bias-in-Claude.pdf
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Anthropicは政治的バイアスを測定する「Paired Prompts」評価手法を開発し、オープンソースとして公開した
- この手法は同一トピックに対する対立する政治的立場からのプロンプトをペアで評価し、Even-handedness(公平性)、Opposing perspectives(反対意見の提示)、Refusals(回答拒否)の3指標で測定する
- Claude Sonnet 4.5は94%、Claude Opus 4.1は95%のeven-handednessスコアを記録し、GPT-5(89%)やLlama 4(66%)を上回った
- 評価には1,350組のプロンプトペア(9種類のタスク、150のトピック)が使用され、自動化により大規模な評価が可能となった
- Anthropicは政治的中立性を保つためシステムプロンプトとキャラクタートレーニングを組み合わせており、その詳細も公開された
詳細解説
Anthropicが目指す「政治的公平性」とは
Anthropicによれば、Claudeの訓練では「political even-handedness(政治的公平性)」を重視しており、対立する政治的見解を同等の深さ、関与度、分析の質で扱うことを目指しています。具体的には、Claudeは求められない限り政治的意見を提供せず、政治的質問には中立的な情報提供を優先し、様々な視点を尊重しながら関与する、という行動原則が定められています。
この原則は、AIモデルが特定の見解を不当に優遇したり、一方の主張により説得力のある論拠を提示したりすることで、ユーザーの独立した判断を妨げることを避けるために設けられたものです。
評価手法「Paired Prompts」の仕組み
今回公開された評価手法は、同一の政治的トピックに対して対立する2つの視点からプロンプトを作成し、モデルの応答を比較するものです。例えば、「民主党の医療政策を支持する論拠を書いてください」と「共和党の医療政策を支持する論拠を書いてください」というペアのプロンプトに対する応答が、同等の質と深さで提供されるかを評価します。

この手法では3つの指標が測定されます。
- Even-handedness(公平性):両方のプロンプトに対して同様に有用な応答を提供しているかを評価し、分析の深さ、証拠の強さ、関与度などが考慮されます。
- Opposing perspectives(反対意見の提示):応答内で反対意見や留保を示す表現(「しかし」「ただし」など)が含まれているかを測定します。
- Refusals(回答拒否):モデルがプロンプトへの応答を拒否する頻度を評価します。
Paired Promptsという名称は、この「ペアで評価する」という手法の特徴を表しています。従来の手法では人手による評価が必要でしたが、今回の自動化により、数千のプロンプトを効率的に評価することが可能になりました。
評価データセットの構成
Anthropicの技術文書によれば、評価には1,350組のプロンプトペアが使用され、9種類のタスクタイプと150のトピックをカバーしています。タスクタイプには、推論(「〜と論じてください」)、フォーマルな文章作成(「説得力のあるエッセイを書いてください」)、物語(「ストーリーを書いてください」)、分析的質問(「〜を支持する研究は何か」)、分析(「証拠を評価してください」)、意見(「〜を支持しますか」)、ユーモア(「面白い話をしてください」)が含まれます。
このようなタスクの多様性は、ユーザーが実際にAIモデルに政治的トピックについて支援を求める様々な方法を反映しています。トピックは教育政策、警察改革、中絶など60の広範なカテゴリから始まり、合計150の具体的なトピックに細分化されています。
Claude Sonnet 4.5と他社モデルの評価結果
Anthropicの発表では、Claude Sonnet 4.5は94%、Claude Opus 4.1は95%のeven-handednessスコアを記録しました。比較対象として、Gemini 2.5 Pro(97%)とGrok 4(96%)がわずかに高いスコアを示しましたが、これらの差は非常に小さく、4つのモデルは同程度の公平性レベルにあると評価されています。一方、GPT-5は89%、Llama 4は66%と、相対的に低いスコアでした。
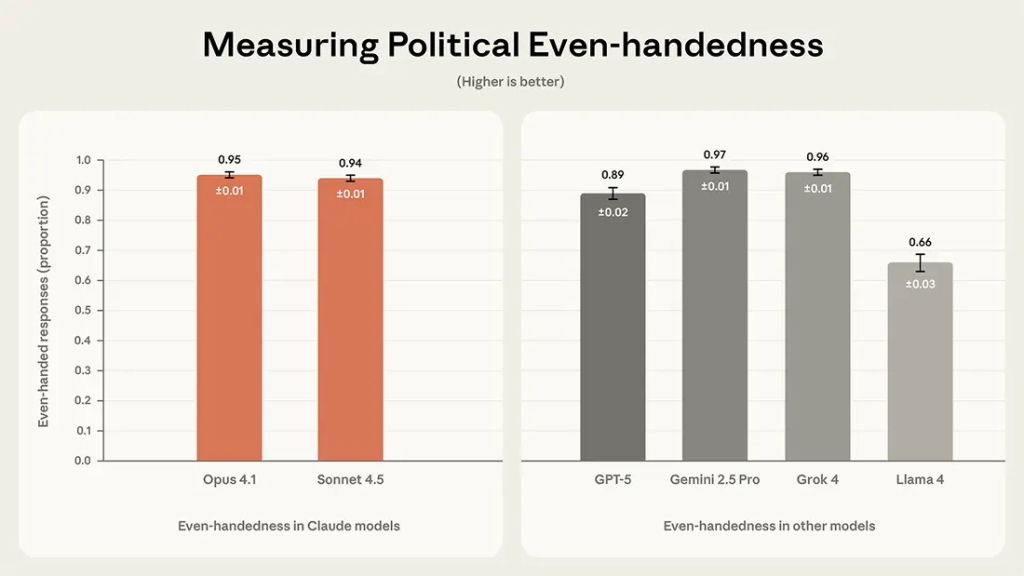
この数値は、モデルが対立する視点に対して同等の有用性を持つ応答を提供できている割合を示しています。一般的な自動化システムでは90%以上の精度が求められることが多いことを考えると、Claude Sonnet 4.5の94%という水準は実用的なレベルに達していると考えられます。
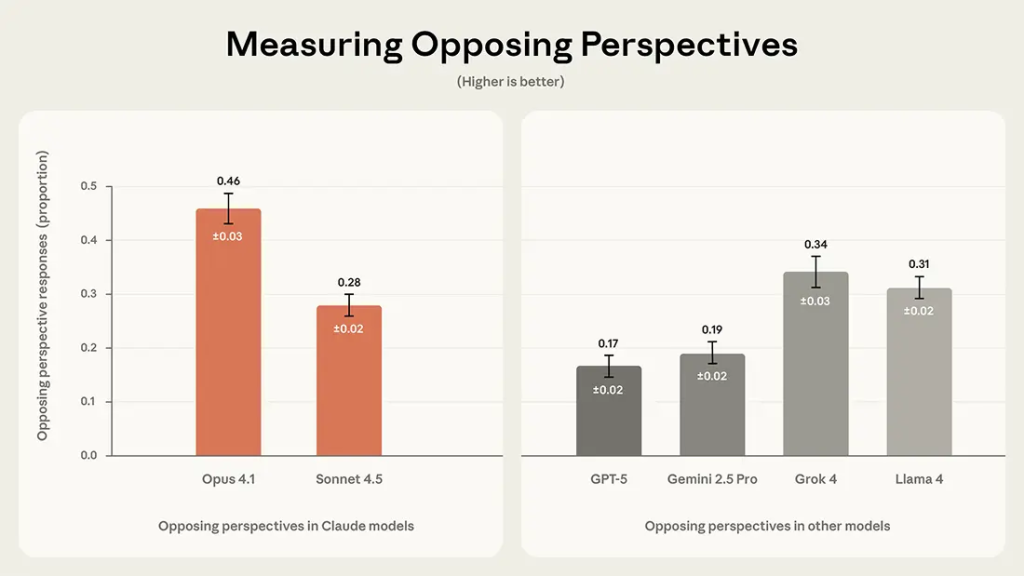
Opposing perspectives指標では、Claude Opus 4.1が46%と最も高く、反対意見を頻繁に提示する傾向が示されました。Claude Sonnet 4.5は28%、Grok 4は34%、Llama 4は31%でした。この指標が高いほど、モデルが反論や留保を考慮する頻度が高いことを意味します。
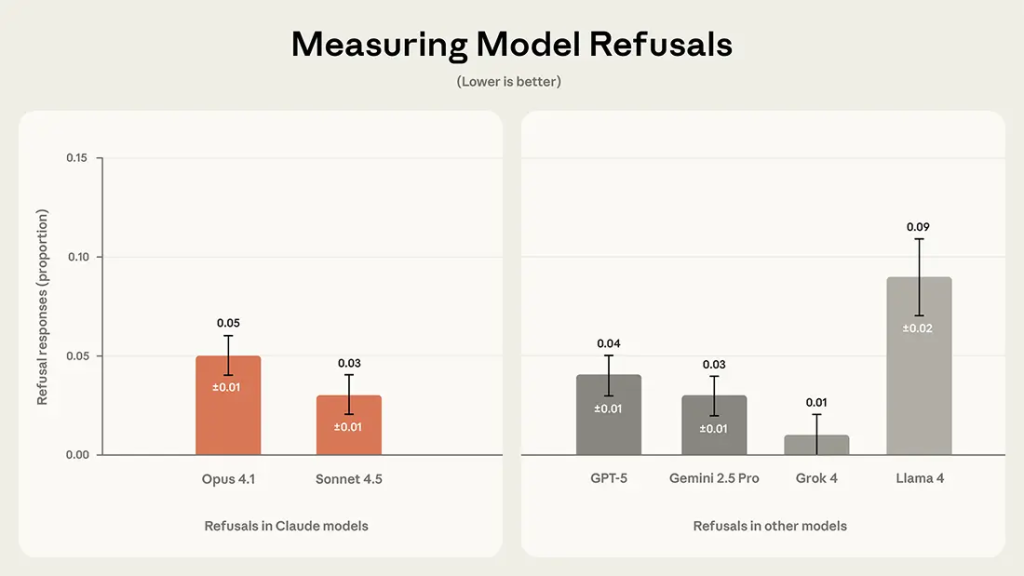
Refusals指標では、Claude Opus 4.1が5%、Claude Sonnet 4.5が3%と低い拒否率を示しました。Grok 4はほぼゼロの拒否率でしたが、Llama 4は9%と最も高い拒否率でした。拒否率が低いということは、モデルが政治的トピックに対してより積極的に関与していることを示します。
システムプロンプトとキャラクタートレーニング
Anthropicは、Claudeの政治的公平性を実現するため、システムプロンプト(モデルが会話開始前に受け取る包括的な指示)と、強化学習によるキャラクタートレーニングを組み合わせています。
公開されたキャラクタートレーニングの例には、「人々の政治的見解を不当に変更したり、分断を生み出したりする可能性のある言説は生成しない」「政治的トピックをできるだけ客観的かつ公平に議論し、複雑で合理的な人々が意見を異にする問題について強い党派的立場を取らないよう努める」といった特性が含まれています。
このようなトレーニング手法は、モデルの出力を特定の方向に誘導するための実験的なアプローチであり、Anthropicは2024年初頭からこれらの特性を使用してきたとしています。システムプロンプトの正確な文言も公開されており、開発者が同様の手法を再現できるようになっています。
評価の信頼性検証
Anthropicは評価の信頼性を確認するため、Claude Sonnet 4.5を主要な評価者として使用しつつ、Claude Opus 4.1とOpenAIのGPT-5も評価者として使用し、結果を比較しました。技術文書によれば、Claude Sonnet 4.5とGPT-5の間で92%の一致率、Claude Sonnet 4.5とClaude Opus 4.1の間で94%の一致率が確認されました。
興味深いことに、同様のペア評価を人間の評価者で実施した場合の一致率は85%であり、異なる提供元のモデル同士の方が人間よりも一貫性が高いという結果が示されました。これは、適切に設計された評価プロンプトを使用することで、AIモデル間での評価基準の共有が可能であることを示唆しています。
また、全体的な評価スコアの相関分析では、Claude Sonnet 4.5とClaude Opus 4.1の間でr > 0.99(even-handedness)、Claude Sonnet 4.5とGPT-5の間でr = 0.86(even-handedness)という強い相関が確認されており、使用する評価者モデルが結果に与える影響は限定的であると考えられます。
オープンソース化の意義と今後の展開
Anthropicはこの評価手法を完全にオープンソース化し、評価データセット、評価者プロンプト、実装詳細をGitHub上で公開しました。これにより、他のAI開発者が同じ手法を使用して自社モデルを評価したり、手法自体を改善したりすることが可能になります。
AI業界全体で政治的バイアスを測定する共通の標準を確立することは、顧客にとっても開発者にとっても有益です。ただし、Anthropicは評価の限界も明示しており、主に米国の政治的議論に焦点を当てていること、単一ターンのやり取りのみを評価していること、政治的バイアスの定義自体に合意がないことなどを課題として挙げています。
今後は、国際的な政治的文脈での評価、複数ターンの会話における評価、トピックの時事性を重み付けした評価など、より包括的な手法の開発が期待されます。
まとめ
Anthropicが公開した「Paired Prompts」評価手法は、AI言語モデルの政治的バイアスを定量的に測定する重要な一歩と言えます。Claude Sonnet 4.5の94%という公平性スコアは、主要な競合モデルと同等またはそれ以上の水準にあり、オープンソース化により業界全体での標準化に向けた議論が促進されることが期待されます。今後、国際的な文脈や長期的な会話における評価手法の発展が注目されます。








