
はじめに
Meta Fundamental AI Research(FAIR)チームが2025年11月10日、1,600以上の言語に対応する音声認識システム「Omnilingual ASR」をオープンソースで公開しました。本稿では、この発表内容をもとに、Omnilingual ASRの技術的特徴、性能、実装方法について詳しく解説します。
参考記事
メイン記事:
- タイトル: Omnilingual ASR: Advancing Automatic Speech Recognition for 1,600+ Languages
- 発行元: Meta AI
- 発行日: 2025年11月10日
- URL: https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition
関連情報:
- タイトル: Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
- 発行元: GitHub
- 発行日: 2025年11月
- URL: https://github.com/facebookresearch/omnilingual-asr
- タイトル: Omnilingual ASR Language Exploration Demo
- 発行元: Meta AI
- URL: https://aidemos.atmeta.com/omnilingualasr/language-globe
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
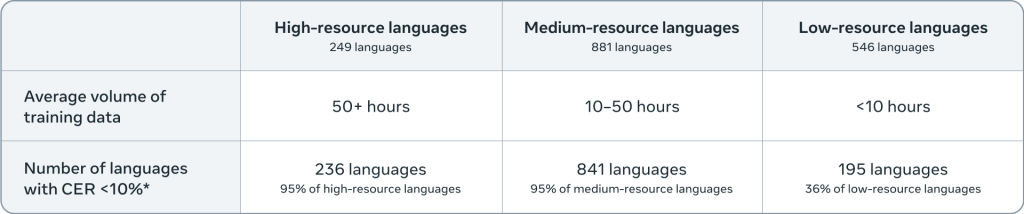
- Omnilingual ASRは1,600以上の言語に対応する音声認識システムで、従来AIによる文字起こしがなされていなかった500の低リソース言語を含む
- wav2vec 2.0を7Bパラメータにスケールアップし、CTCとLLMベースの2種類のデコーダーアーキテクチャを提供している
- 7B-LLM-ASRモデルは78%の言語で文字誤り率(CER)10以下を達成し、最先端の性能を記録した
- ゼロショット学習により、わずか数サンプルの音声-テキストペアで新しい言語を追加できる
- 350の言語を含むOmnilingual ASR Corpusをオープンソースで公開し、Apache 2.0ライセンスの下で利用可能である
詳細解説
1,600言語対応の音声認識システム
Metaによれば、現在の音声認識システムの多くは、インターネット上で豊富なデータが得られる高リソース言語に限定されており、低リソース言語の話者にとって高品質な文字起こしは利用できない状況が続いていました。Omnilingual ASRは、この課題に対処するために開発された音声認識システムです。
自動音声認識(ASR: Automatic Speech Recognition)は、音声を検索可能なテキストに変換する技術で、従来は大量のラベル付きデータと人手による メタデータが必要とされてきました。Omnilingual ASRは、この制約を大幅に緩和し、これまでAIによる文字起こしが行われていなかった500の低リソース言語を含む1,600以上の言語に対応しています。
wav2vec 2.0の大規模化とデコーダーアーキテクチャ
Metaの発表では、Omnilingual ASRは2つの主要なアーキテクチャ改良によって実現されたと説明されています。
第一に、従来のwav2vec 2.0音声エンコーダーを7Bパラメータに初めてスケールアップしました。wav2vec 2.0は、自己教師あり学習により、文字起こしされていない生の音声データから多言語の意味表現を学習するモデルです。このスケールアップにより、より豊かな音声表現が可能になったと考えられます。
第二に、このエンコーダーの出力を文字トークンにマッピングする2種類のデコーダーを開発しました。1つは従来の接続時間分類(CTC: Connectionist Temporal Classification)を用いたデコーダー、もう1つは大規模言語モデル(LLM)で一般的に使用されるTransformerデコーダーです。
このLLMベースのアプローチは「LLM-ASR」と呼ばれ、特に低リソース言語において性能向上をもたらしています。7B-LLM-ASRシステムは、1,600以上の言語で最先端の性能を達成し、78%の言語で文字誤り率(CER)が10以下となりました。文字誤り率は、認識結果と正解テキストの文字レベルでの差異を示す指標で、値が低いほど精度が高いことを意味します。
ゼロショット学習による新言語の追加
Omnilingual ASRの大きな特徴の1つは、ゼロショット学習による新言語の追加機能です。Metaによれば、従来のシステムでは、リリース時に含まれていない言語を追加するには、専門家による微調整が必要であり、多くのコミュニティにとってアクセスしにくいものでした。
これに対し、Omnilingual ASRは、LLMの文脈内学習(in-context learning)の能力を音声認識に応用しています。これにより、サポートされていない言語の話者は、わずか数組の音声-テキストペアのサンプルを提供するだけで、実用的な文字起こし品質を得ることができます。大規模な学習データ、専門知識、高性能な計算リソースは不要です。
ゼロショットの性能は、完全に学習されたシステムにはまだ及ばないものの、新しい言語をデジタル領域に取り込むためのはるかにスケーラブルな手段を提供していると言えるでしょう。
多様なモデルファミリーの提供
Metaは、用途に応じて選択できる多様なモデルファミリーを公開しています。軽量な300Mパラメータのモデルから、高精度な7Bパラメータのモデルまで、様々なサイズが用意されています。
具体的には、以下の3つのカテゴリーのモデルが提供されています:
SSL(自己教師あり学習)モデル: wav2vec 2.0の基盤モデルで、300M、1B、3B、7Bの4つのサイズがあります。これらは音声認識以外の音声関連タスクにも活用できる汎用的な音声表現モデルです。
CTCモデル: 従来のCTCデコーダーを使用した音声認識モデルで、同様に300M、1B、3B、7Bの4つのサイズが用意されています。これらは推論速度が速く、例えば300Mモデルはリアルタイムの96倍速で動作します。
LLMモデル: LLMベースのデコーダーを使用した音声認識モデルで、300M、1B、3B、7Bの4つのサイズに加え、ゼロショット学習に最適化された7B_ZSモデルがあります。これらは言語条件付けが可能で、より高い精度を実現しています。
モデルのメモリ要件は、例えば7B-LLMモデルで約17GiBのVRAM(推論時、バッチサイズ1、30秒の音声、BF16精度、A100 GPU使用時)となっており、導入時にはハードウェア要件の確認が重要です。
実装とライセンス
Omnilingual ASRは、Metaのオープンソースフレームワークであるfairseq2に基づいて開発されています。fairseq2は研究用の系列モデリングツールキットで、PyTorchエコシステムの最新ツールと技術を活用できます。
実装は比較的シンプルで、GitHubのドキュメントによれば、pipまたはuvを使ってインストールし、数行のPythonコードで推論パイプラインを構築できます。現在、40秒以下の音声ファイルに対応しており、より長い音声への対応も計画されています。
〇Installation
# using pip
pip install omnilingual-asr
# using uv
uv add omnilingual-asr〇Inference
from omnilingual_asr.models.inference.pipeline import ASRInferencePipeline
pipeline = ASRInferencePipeline(model_card="omniASR_LLM_7B")
audio_files = ["/path/to/eng_audio1.flac", "/path/to/deu_audio2.wav"]
lang = ["eng_Latn", "deu_Latn"]
transcriptions = pipeline.transcribe(audio_files, lang=lang, batch_size=2)すべてのモデルとコードはApache 2.0ライセンスの下で公開されており、商用利用も可能です。データセットはCC-BYライセンスで提供されています。
Omnilingual ASR Corpusの公開
Metaは、Omnilingual ASRの学習に使用されたデータの一部を「Omnilingual ASR Corpus」として公開しています。これは、350の言語を対象とした、超低リソース言語の自然発話ASRデータセットとしては史上最大規模のものです。
このデータセットは、世界中の地域組織と協力して収集されたもので、デジタル上の存在が少ない言語にリーチするため、遠隔地や記録が少ない地域のネイティブスピーカーを募集し、報酬を支払って音声を収集しました。
データ収集にあたっては、Mozilla FoundationのCommon VoiceやLanfrica/NaijaVoicesなどの組織と協力し、言語コミュニティから直接的な専門知識とリソースを得ています。Language Technology Partner Programを通じた協力により、言語学者、研究者、言語コミュニティが世界中から集まり、技術が地域のニーズを満たすよう設計されています。
このデータセットは、ASR研究コミュニティ全体の利益のために公開されており、HuggingFaceからもアクセス可能です。研究者や開発者は、このデータを活用して独自の音声認識システムを構築したり、Omnilingual ASRをさらに改良したりすることができます。
まとめ
Omnilingual ASRは、1,600以上の言語に対応し、ゼロショット学習で新言語を追加できる音声認識システムです。7Bパラメータの大規模モデルから軽量な300Mモデルまで、用途に応じて選択できる柔軟性があり、Apache 2.0ライセンスで商用利用も可能です。350言語のデータセットも公開されており、音声認識技術の民主化に向けた大きな一歩と言えるでしょう。








