
はじめに
OpenAIが2025年11月13日、GPT-5シリーズの新モデル「GPT-5.1」をAPI platform経由で開発者向けに公開しました。本稿では、この発表内容をもとに、GPT-5.1の適応的推論機能、新しい「no reasoning」モード、コーディング性能の向上、そして新たに導入された2つのツールについて解説します。
参考記事
- タイトル: Introducing GPT-5.1 for developers
- 発行元: OpenAI
- 発行日: 2025年11月13日
- URL: https://openai.com/index/gpt-5-1-for-developers/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- GPT-5.1は、タスクの複雑さに応じて思考時間を動的に調整する適応的推論を実装し、簡単なタスクでは大幅に高速化した
- 新しい「no reasoning」モードでは、推論を省略して低レイテンシーを実現しながら、GPT-5.1の高い知能を維持する
- 最大24時間のプロンプトキャッシング保持により、フォローアップクエリの応答速度が向上し、コストが削減される
- SWE-bench Verifiedで76.3%の精度を達成し、コーディングタスクにおける性能が向上した
- apply_patchとshellという2つの新ツールが導入され、より信頼性の高いコード編集とシェルコマンド実行が可能になった
詳細解説
適応的推論による効率化
OpenAIによれば、GPT-5.1は「適応的推論(Adaptive reasoning)」という新しいアプローチを採用しています。この仕組みでは、簡単なタスクでは思考に使用するトークン数を減らし、より迅速な応答を実現します。一方、複雑なタスクでは十分な時間をかけて選択肢を探索し、作業を検証することで信頼性を最大化します。
具体的な性能改善として、資産運用会社Balyasny Asset Managementの評価では、GPT-5.1はGPT-5と比較して2-3倍高速に動作し、ツールを多用する推論タスクにおいて、競合モデルの約半分のトークン数で同等以上の品質を達成したとされています。また、AI保険BPO企業のPaceも、GPT-5.1上でエージェントが50%高速に動作し、GPT-5や他の主要モデルを上回る精度を示したと報告しています。
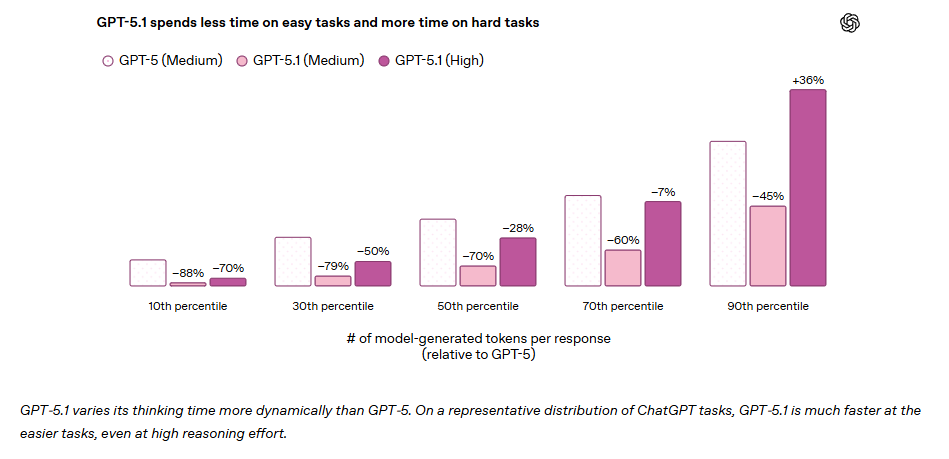
適応的推論は、モデルの学習方法を根本的に見直すことで実現されました。OpenAIが公開したデータによれば、簡単なタスク(10パーセンタイル)ではGPT-5比で88%のトークン削減を達成する一方、難しいタスク(90パーセンタイル)では36%のトークン増加を許容することで、より慎重な推論を可能にしています。
実用例として、「グローバルにインストールされたnpmパッケージをリストするコマンドを教えて」という質問に対し、GPT-5では約250トークン(約10秒)を要していたのに対し、GPT-5.1では約50トークン(約2秒)で回答できるとされています。この種の日常的なタスクにおける高速化は、開発者の作業フローにおいて体感的な改善をもたらすと考えられます。
「no reasoning」モードの導入
GPT-5.1では、reasoning_effortパラメータに’none’を設定することで、推論プロセスを完全に省略できる新しいモードが導入されました。このモードでは、レイテンシーが重要なユースケースにおいて、GPT-5.1の高い知能を維持しながら、非推論モデルのような動作を実現します。
OpenAIの説明では、このモードは並列ツール呼び出し、コーディングタスク、指示の追従、検索ツールの使用において優れた性能を発揮し、API platformでのウェブ検索もサポートしています。カスタマーエクスペリエンスプラットフォームのSierraによる実世界評価では、「no reasoning」モードがGPT-5の最小推論モードと比較して、低レイテンシーツール呼び出し性能で20%の改善を示したとされています。
reasoning_effortパラメータには、’none’、’low’、’medium’、’high’の4つの値が用意されており、GPT-5.1ではデフォルトが’none’に設定されています。OpenAIは、レイテンシーが重要なワークロードでは’none’を、より複雑なタスクでは’low’または’medium’を、速度よりも知能と信頼性が重要な場合は’high’を選択することを推奨しています。この柔軟な設定により、開発者は用途に応じて速度、コスト、知能のバランスを細かく調整できるようになりました。
拡張プロンプトキャッシング
GPT-5.1では、プロンプトキャッシングの保持時間が従来の数分間から最大24時間に延長されました。この拡張キャッシングにより、長時間にわたる対話、コーディングセッション、知識検索ワークフローなどにおいて、より多くのフォローアップリクエストがキャッシュされたコンテキストを活用できるようになります。
キャッシングの価格体系は変更されず、キャッシュされた入力トークンは非キャッシュトークンより90%安価で、キャッシュの書き込みやストレージに追加料金は発生しません。拡張キャッシングを利用するには、Responses APIまたはChat Completions APIで”prompt_cache_retention=’24h'”パラメータを追加します。
この機能により、特にマルチターンの対話や継続的なコーディング作業において、応答速度の向上とコスト削減が期待できます。従来は短時間でキャッシュが失効していたため、わずかな間隔を空けただけでも再度コンテキストを送信する必要がありましたが、24時間の保持により、1日を通じた作業セッションでキャッシュを有効活用できると考えられます。
コーディング性能の向上
GPT-5.1は、GPT-5のコーディング能力をベースに、より制御可能なコーディング性格、過度な思考の削減、改善されたコード品質、ツール呼び出しシーケンス中のユーザー向け更新メッセージ(プリアンブル)の改善、そして特に低推論努力レベルでのより機能的なフロントエンドデザインを実現しています。
OpenAIによれば、簡単なコード編集のようなタスクでは、GPT-5.1の高速化により反復作業がより容易になります。重要なのは、簡単なタスクでの高速化が難しいタスクでの性能を損なわない点で、SWE-bench Verifiedでは76.3%の精度を達成し、GPT-5の72.8%を上回りました。
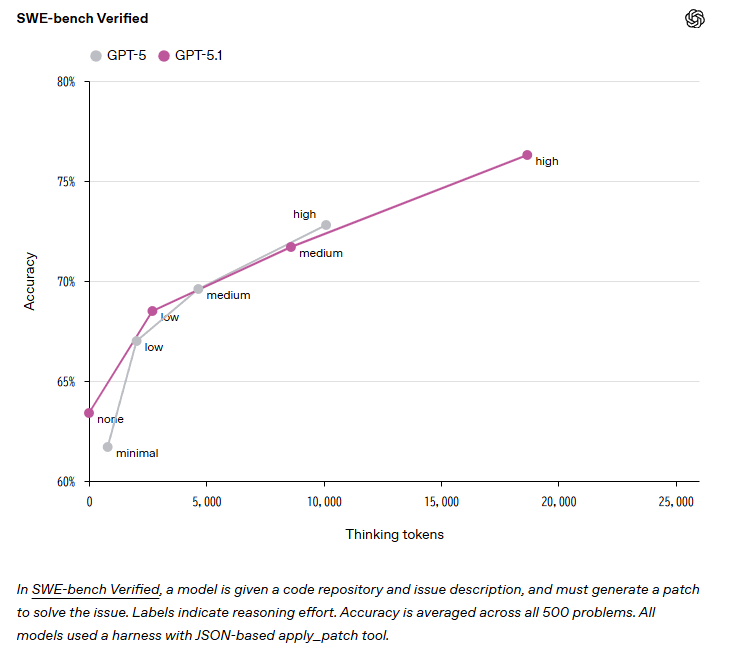
SWE-bench Verifiedは、モデルにコードリポジトリと問題説明を与え、その問題を解決するパッチを生成させる評価基準です。このベンチマークは、実世界のソフトウェア開発タスクに近い複雑性を持つため、実用的なコーディング能力を測る指標として業界で広く認識されています。
複数のコーディング企業からの初期フィードバックも公開されています:
- Augment Codeは、GPT-5.1を「より慎重で無駄な行動が少なく、推論が効率的で、タスクフォーカスが向上している」と評価し、「より正確な変更、スムーズなプルリクエスト、マルチファイルプロジェクト全体でのより速い反復」を実現していると述べています
- Clineは、差分編集ベンチマークで7%の改善を達成し、最先端(SOTA)の性能を記録したと報告しています
- CodeRabbitは、GPT-5.1を「PRレビューの第一選択モデル」と評価しています
- Cognitionは、GPT-5.1が「要求内容の理解と協力的な作業完遂において著しく優れている」としています
- Factoryは、「より迅速な応答と、タスクに応じた推論深度の調整により、過度な思考を削減し、開発者体験を向上させている」と述べています
- Warpは、新規ユーザーのデフォルトモデルとしてGPT-5.1を採用し、「GPT-5シリーズの優れた知能向上を基盤としながら、はるかに応答性の高いモデル」と評価しています
新ツール:apply_patchとshell
GPT-5.1では、Responses APIで開発者がモデルを最大限活用できるよう、2つの新しいツールが導入されました。
apply_patchツールは、構造化された差分を使用してコードベース内のファイルを作成、更新、削除できる自由形式のツールです。単なる編集提案ではなく、モデルがパッチ操作を出力し、アプリケーションがそれを適用して結果を報告することで、反復的なマルチステップのコード編集ワークフローを可能にします。
Responses APIでapply_patchツールを使用するには、toolsパラメータに{“type”: “apply_patch”}を含め、入力にファイルコンテンツを含めるか、ファイルシステムと対話するためのツールをモデルに提供します。モデルは、ファイルシステム上で適用する差分を含むapply_patch_call項目を生成します。
shellツールは、制御されたコマンドラインインターフェースを通じて、モデルがローカルコンピュータと対話できるようにします。モデルがシェルコマンドを提案し、開発者の統合がそれを実行して出力を返すという仕組みです。これにより、モデルがシステムを検査し、ユーティリティを実行し、タスクを完了するまでデータを収集する、シンプルな計画-実行ループが作成されます。
shellツールを使用するには、toolsパラメータに{“type”: “shell”}を含めます。APIは実行するシェルコマンドを含む”shell_call”項目を生成し、開発者はローカル環境でコマンドを実行し、次のAPIリクエストで”shell_call_output”項目として実行結果を返します。
これらのツールは、特にエージェント的なコーディングワークフローにおいて、モデルとローカル環境のより緊密な統合を実現します。ただし、shellツールの使用には、セキュリティ上の考慮が必要と考えられます。実行されるコマンドの検証や、適切なアクセス制御の実装が重要でしょう。
価格設定と可用性
GPT-5.1とgpt-5.1-chat-latestは、すべての有料ティアの開発者がAPI経由で利用可能です。価格設定とレート制限はGPT-5と同じとされています。また、gpt-5.1-codexとgpt-5.1-codex-miniもAPIで公開されました。
OpenAIによれば、GPT-5.1はほとんどのコーディングタスクで優れていますが、gpt-5.1-codexモデルは、CodexまたはCodex類似のハーネスにおける長時間実行されるエージェント的コーディングタスクに最適化されているとのことです。
OpenAIは現時点でAPIからGPT-5を非推奨にする計画はなく、非推奨にする決定をする場合は、開発者に事前通知を提供するとしています。この姿勢は、既存のGPT-5統合を持つ開発者にとって安心材料と言えるでしょう。
まとめ
GPT-5.1は、適応的推論により簡単なタスクでは大幅に高速化し、難しいタスクでは十分な思考時間を確保するという、実用性を重視した設計となっています。「no reasoning」モードや24時間のプロンプトキャッシング、そして新しいツールの導入により、開発者はより柔軟で効率的なAIアプリケーション開発が可能になりました。OpenAIは今後も、より高性能なエージェント型およびコーディングモデルへの投資を続けるとしており、今後数週間から数ヶ月の間にさらなる進展が期待されます。








