
はじめに
Google DeepMindが2025年11月6日、Gemini APIに「File Search Tool」を追加したと発表しました。File Search Toolは、RAG(Retrieval Augmented Generation)システムを完全に自動化するツールで、ファイルの保存・分割・埋め込み生成・検索までを一括して処理します。本稿では、この発表内容とAPIドキュメントをもとに、File Search Toolの機能、仕組み、料金体系、実装方法について解説します。
参考記事
メイン記事:
- タイトル: Introducing the File Search Tool in Gemini API
- 著者: Ivan Solovyev (Product Manager), Animesh Chatterji (Software Engineer)
- 発行元: Google DeepMind / Google Blog
- 発行日: 2025年11月6日
- URL: https://blog.google/technology/developers/file-search-gemini-api/
関連情報:
- タイトル: File Search (APIドキュメント)
- 発行元: Google AI for Developers
- URL: https://ai.google.dev/gemini-api/docs/file-search
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- File Search Toolは、Gemini API内で完結する完全管理型のRAGシステムであり、ファイル保存・チャンク分割・埋め込み生成・検索を自動化する
- 保存とクエリ時の埋め込み生成が無料で、インデックス作成時のみ100万トークンあたり0.15ドルの料金が発生する
- Gemini Embedding modelによるベクトル検索を採用し、完全一致しない文言でも意味的に関連する情報を検索できる
- PDF、DOCX、TXT、JSON、主要なプログラミング言語ファイルなど幅広い形式に対応し、回答には自動的に引用が付与される
- Gemini 2.5 ProとGemini 2.5 Flashで利用可能で、既存のgenerateContent APIに統合されている
詳細解説
File Search Toolとは
File Search Toolは、Gemini API内で動作する完全管理型のRAGシステムです。Googleによれば、開発者がファイルをアップロードすると、システムが自動的にファイル保存、最適なチャンク分割戦略の適用、埋め込み生成、検索用コンテキストの動的な注入までを処理します。既存のgenerateContent API内で動作するため、導入が容易である点が特徴です。
RAGは、外部知識を言語モデルに統合する技術として広く活用されていますが、従来は開発者自身がベクトルデータベースの構築、チャンク分割戦略の設計、埋め込みモデルの選定などを個別に実装する必要がありました。File Search Toolは、これらの処理をAPI側で一括して提供することで、開発者の実装負担を大幅に軽減します。
主要機能
Googleの発表では、File Search Toolの主要機能として以下が挙げられています。
統合された開発者体験として、RAGプロセス全体が自動化されています。ファイル保存、チャンク分割、埋め込み生成、コンテキスト注入がすべてAPI側で処理されるため、開発者はファイルをアップロードしてクエリを送信するだけで済みます。
強力なベクトル検索機能では、最新のGemini Embedding modelを使用しています。このモデルはベクトル検索を実行し、ユーザーのクエリの意味と文脈を理解するため、完全一致しない文言でも関連情報を見つけることができます。従来のキーワードベースの検索では、検索語句がドキュメント内に正確に存在しない場合、結果を取得できないことがありましたが、セマンティック検索ではこの制約が緩和されます。
組み込みの引用機能により、モデルの回答には自動的に引用が含まれます。引用には、回答生成に使用されたドキュメントの該当箇所が明示されるため、事実確認が容易になります。
幅広いファイル形式のサポートも特徴の一つです。APIドキュメントによれば、PDF、DOCX、TXT、JSON、および主要なプログラミング言語のファイル(Python、JavaScript、Java、C++など)に対応しています。これにより、コードベース、ビジネスドキュメントなど、多様なデータソースを統合した知識ベースを構築できます。
セマンティック検索の仕組み
File Searchは、セマンティック検索と呼ばれる技術を使用して、ユーザーのプロンプトに関連する情報を検索します。APIドキュメントでは、この仕組みが以下のように説明されています。
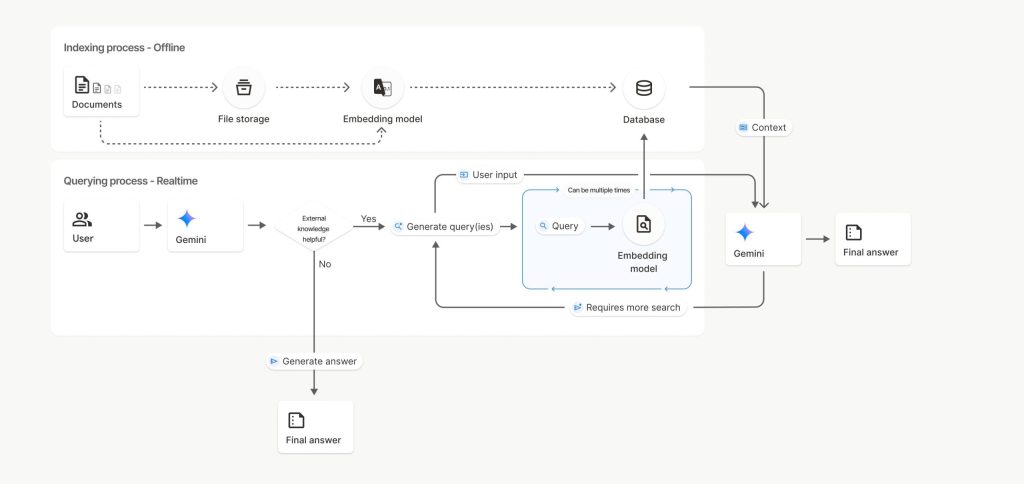
ファイルをインポートすると、テキストが数値表現である埋め込み(embedding)に変換されます。埋め込みは、テキストの意味的な内容を数値ベクトルとして表現したもので、類似した意味を持つテキストは、ベクトル空間上で近い位置に配置されます。これらの埋め込みは、専用のファイル検索データベースに保存されます。
クエリが送信されると、クエリも同様に埋め込みに変換されます。システムはファイル検索を実行し、ファイル検索ストアから最も類似した関連性の高いドキュメントチャンクを見つけ出します。この方式により、キーワードが完全一致しない場合でも、意味的に関連する情報を取得できるようになります。
APIドキュメントによれば、プロセスは以下の3段階で構成されます。まず、ファイル検索ストアを作成します。次に、ファイルをアップロードしてファイル検索ストアにインポートすると、一時的なFileオブジェクトが作成され、データがチャンク分割、埋め込みに変換、インデックス化されます。最後に、generateContent呼び出しでFileSearchツールを使用し、ツール設定でFileSearchStoreを指定することで、そのストアに対してセマンティック検索を実行し、回答を生成します。
実装方法とファイル管理
APIドキュメントでは、2つの実装方法が示されています。
直接アップロード方式では、uploadToFileSearchStore APIを使用して、ファイルを直接ファイル検索ストアにアップロードします。この方式では、ファイルのアップロードとインポートが同時に行われるため、実装が簡潔になります。
分離アップロード方式では、Files APIでファイルをアップロードした後、importFile APIでファイル検索ストアにインポートします。この方式は、同じファイルを複数のストアで使用する場合や、ファイルのメタデータを細かく制御したい場合に有用と考えられます。
ファイル検索ストアは、ドキュメント埋め込みの永続的なコンテナです。APIドキュメントによれば、Files APIでアップロードされた生ファイルは48時間後に削除されますが、ファイル検索ストアにインポートされたデータは手動で削除するまで無期限に保存されます。複数のファイル検索ストアを作成してドキュメントを整理することも可能で、FileSearchStore APIを使用してストアの作成、一覧表示、取得、削除を管理できます。
チャンク分割の制御も可能です。APIドキュメントでは、chunking_config設定により、チャンクあたりの最大トークン数と重複トークン数を指定できると説明されています。これにより、特定のユースケースに最適なチャンク分割戦略を実装できます。
また、カスタムメタデータ機能により、ファイルにキー・バリューペアのメタデータを追加できます。これは、複数のドキュメントを含むファイル検索ストア内でサブセットのみを検索したい場合に有用です。例えば、著者や年度でフィルタリングする際に使用できます。
料金体系とストレージ制限
Googleによれば、File Search Toolの料金体系は以下のとおりです。
インデックス作成時の埋め込み生成には、既存の埋め込み料金が適用され、gemini-embedding-001モデルの場合、100万トークンあたり0.15ドルです。一方、ストレージとクエリ時の埋め込み生成は無料です。取得されたドキュメントトークンは、通常のコンテキストトークンとして課金されます。
この料金体系は、従来の自己管理型RAGシステムと比較すると、コスト構造が明確である点が特徴です。従来は、ベクトルデータベースのホスティング費用、クエリ時の埋め込み生成費用、ストレージ費用などが別々に発生することが一般的でしたが、File Search Toolではこれらが整理されています。
APIドキュメントによれば、ストレージ制限は以下のとおりです。ファイルあたりの最大サイズは100MBで、プロジェクト全体のファイル検索ストアサイズは、無料ティアで1GB、ティア1で10GB、ティア2で100GB、ティア3で1TBです。また、各ファイル検索ストアのサイズは20GB未満に制限することが推奨されており、これにより最適な検索レイテンシが確保されます。
なお、ファイル検索ストアのサイズは、入力データのサイズと生成・保存される埋め込みに基づいて計算され、通常は入力データの約3倍になると説明されています。
活用事例
Googleの発表では、早期アクセスプログラムでの活用事例として、Beamが紹介されています。
Beamは、Phaser Studioが開発したAI駆動のゲーム生成プラットフォームです。BeamはFile Searchをワークフローに統合し、3,000以上のファイルを含む6つのアクティブなコーパスに対して、1日に数千回の検索を実行しています。Phaser StudioのCTOであるRichard Davey氏によれば、File Searchは複数のコーパスにわたる並列クエリを処理し、2秒以内に結果を統合するとのことです。これは、以前は手動で数時間かかっていたクロスリファレンスと比較して、大幅な改善と言えるでしょう。
この事例は、大規模なドキュメントベースを持つプラットフォームでのFile Searchの実用性を示すものと考えられます。特に、複数のコーパスを横断して迅速に情報を取得する必要がある場合に、File Searchの自動化されたRAGシステムが有効である可能性があります。
対応モデルとファイル形式
APIドキュメントによれば、File Searchは現在、Gemini 2.5 ProとGemini 2.5 Flashでサポートされています。
対応するファイル形式は、アプリケーションファイルとしてPDF、DOCX、PPTX、XLSX、CSV、JSON、XML、RTF、EPUBなどがあります。テキストファイルとしては、TXT、HTML、CSS、JavaScript、TypeScript、Python、Java、C、C++、C#、Go、Ruby、PHP、Swift、Kotlin、Rust、Scala、Shell、YAML、Markdown、LaTeX、SQLなど、主要なプログラミング言語とマークアップ言語が含まれています。
この幅広い対応により、コードリポジトリ、ビジネスドキュメント、研究論文など、多様なデータソースを統合した知識ベースの構築が可能になります。
まとめ
Gemini APIのFile Search Toolは、RAGシステムの構築を完全に自動化し、開発者の実装負担を大幅に軽減するツールです。ストレージとクエリ時の埋め込み生成が無料という料金体系も、コスト面での予測可能性を高めています。セマンティック検索により、キーワードが完全一致しない場合でも関連情報を取得でき、自動引用機能により事実確認も容易になります。Beamの事例が示すように、大規模なドキュメントベースを持つアプリケーションでの実用性も期待できるでしょう。今後、RAGシステムを活用したアプリケーション開発において、File Search Toolがどのように活用されるか、注目されます。








