
はじめに
Anthropic社は2025年10月に、新しいハイブリッド推論大規模言語モデル「Claude Haiku 4.5」を発表しました。これは、同社の小型・高速モデルクラスに位置づけられるモデルであり、その速度と知性の組み合わせにより、特にコーディングタスクやコンピューター利用、あるいは複数のインスタンスが並行してタスクを完了するような「エージェント的」な使用において非常に効果的であるとされています。
本稿の基となるシステムカードでは、モデルの安全対策、自律的な「エージェント的」役割での安全性プロファイル、広範なアライメント(調和)、潜在的な福祉、テストの近道を見つける傾向(報酬ハッキング)、そして危険な兵器を生成するための悪用の可能性を含む、多岐にわたる安全性評価に焦点が当てられています。
全体として、Claude Haiku 4.5は、前身であるClaude Haiku 3.5と比較して大幅な安全性の改善を示しており、その結果に基づき、Anthropic社の責任あるスケーリングポリシー(RSP)に規定されているAI Safety Level 2 Standard(ASL-2)のもとで展開されました。
解説論文
- 論文タイトル:System Card: Claude Haiku 4.5
- 論文URL:https://assets.anthropic.com/m/99128ddd009bdcb/Claude-Haiku-4-5-System-Card.pdf
- 発行日:2025年10月
- 発表者:Anthropic
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 高性能なエージェントモデルとしての位置づけ: Claude Haiku 4.5は、小型・高速モデルクラスながら、エージェントコーディングやコンピューター利用能力において大幅な改善を遂げたハイブリッド推論モデルである。
- 安全性の飛躍的向上: 前モデルであるClaude Haiku 3.5と比較し、マルチターンでの安全性(悪意のある意図の検出)や、良性な質問に対する過剰な拒否(過剰拒否率)の面で劇的な改善を達成した。
- ASL-2標準での展開: 責任あるスケーリングポリシー(RSP)に基づき、ASL-3閾値を大幅に下回ることが確認され、AI Safety Level 2 Standard(ASL-2)で展開された。
- 報酬ハッキングの抑制: モデルが近道を見つけてしまう報酬ハッキングの傾向が、Claude Haiku 3.5と比較して約2倍減少した。
- 新しい機能:拡張思考モードとコンテキスト認識: ユーザーがより深く推論を行うよう指示できる「拡張思考モード」が追加され、また、長い会話(200Kトークン)の中で「怠惰」を避けるためのコンテキスト認識能力が向上した。
詳細解説
本稿では、Claude Haiku 4.5の特性と評価について、システムカードの構成に沿って詳細に解説します。
1 Introduction (はじめに)
本モデルは、Anthropic社の最新の大規模言語モデルであり、Claude Opus 4.1やClaude Sonnet 4.5といった既存のモデルと比較して小型かつ高速であるのが特徴です。
- Capabilities (能力): Claude Haiku 4.5は、エージェント的コーディングやコンピューター利用といった側面で大幅な能力改善を示しています。フロンティアモデル(最先端の能力を持つモデル)ではありませんが、その高い知性と速度により、多様な「エージェント的」利用に適しています。
- Safety and alignment (安全性とアライメント): 本モデルは、先行モデルであるClaude Haiku 3.5と比較して全体的に大幅にアライメントが改善されており、多くの指標でClaude Opus 4.1やClaude Sonnet 4.5といったより新しいモデルにも匹敵する良好な安全性プロファイルを持っています。
1.1 Model training and characteristics (モデルのトレーニングと特性)
1.1.1 Training data (トレーニングデータ)
Claude Haiku 4.5は、2025年2月までの公開されているインターネット情報、サードパーティからの非公開データ、データラベリングサービスや請負業者からのデータ、オプトインしたClaudeユーザーデータ、およびAnthropicが内部で生成したデータの独自の組み合わせでトレーニングされました。トレーニングプロセス全体を通じて、重複排除や分類を含む複数のデータクリーニングおよびフィルタリング手法が使用されました。事前トレーニング後、本モデルは、人間やAIからのフィードバックによる強化学習を含むさまざまな技術を用いて、Helpful, Honest, and Harmless(H3:有用で、正直で、無害)なアシスタントにするための実質的な事後学習とファインチューニングを受けました。
1.1.2 Extended thinking mode (拡張思考モード)
Claude Sonnet 3.7以降のAnthropicのモデルと同様に、Claude Haiku 4.5はハイブリッド推論モデルです。デフォルトでは迅速に応答しますが、ユーザーは「拡張思考モード」を有効にすることで、モデルが応答を検討する時間を長く取ることができます。なお、先行モデルであるClaude Haiku 3.5にはこのモードはありませんでした。
拡張思考モードからの応答を受け取った後、ユーザーはモデルの「思考プロセス」または「思考連鎖(chain-of-thought)」を閲覧することができ、モデルの推論過程が示されます(ただし、その正確性や「忠実性」の程度は不確実である点に注意が必要です)。
1.1.3 Context awareness (コンテキスト認識)
モデルの能力が向上するにつれて、エージェント的なエピソード(タスク遂行のための対話)が物理的なコンテキストウィンドウの限界(リリース時は200Kトークン)に頻繁に遭遇するという課題があります。Claude Haiku 4.5では、モデルはコンテキストウィンドウの使用量について明示的に認識するように訓練されました。これにより、モデルは制限が近づいたときに回答をまとめる方法を学び、制限が遠い場合はより粘り強く推論を続けることを学習します。この介入は、モデルが問題を途中でやめる、不完全な回答をする、タスクの手を抜くといったエージェント的な「怠惰」を制限するのに効果的でした。
1.1.4 Crowd workers (クラウドワーカー)
Anthropicは、モデルの改善を支援するワーカーと提携しており、選好選択、安全性評価、および敵対的テストを通じてモデルを改善しています。Anthropicは、公正かつ倫理的な報酬と安全な職場慣行を提供しているプラットフォームとのみ協力しています。
1.1.5 Usage policy (利用ポリシー)
Anthropicの利用ポリシーには、モデルの禁止されている利用法と、ハイリスクなシナリオを含む特定の利用における要件が詳細に記載されています。
1.2 Release decision process (リリース決定プロセス)
1.2.1 Overview (概要)
Anthropicの責任あるスケーリングポリシー(RSP)は、モデルの能力評価に基づいてAI Safety Level(ASL)Standardを決定するための評価の実施を義務付けています。ASL Standardは、モデルの評価された能力に応じて厳格さが増します。Claude Haiku 4.5は小型クラスのモデルであるため、ASL-3「ルールアウト」評価が使用され、ASL-3 Standardの下でリリースする必要がないことを確認しました。
1.2.2 Decision (決定)
評価の結果、Claude Haiku 4.5はASL-3ルールアウトの閾値を満たしていると判断されました。自動評価に基づき、Claude Haiku 4.5はASL-2安全策で展開されたClaude Sonnet 4と同様の性能を示し、懸念されるすべてのドメインでASL-3の閾値を大幅に下回っていることが確認されました。
2 Safeguards and harmlessness (安全策と無害性)
Claude Haiku 4.5のリリースに先立ち、モデルが利用ポリシーを遵守しているか、また出力がバランスの取れた有用なものであるかを測定する標準的な安全性評価が実施されました。
2.1 Single-turn evaluations (シングルターン評価)
ユーザーのクエリに対する1回限りのモデルの応答を評価するもので、広範なトピックにわたる有害な情報を提供する意欲を調査しました。
2.1.1 Violative request evaluations (違反リクエスト評価)
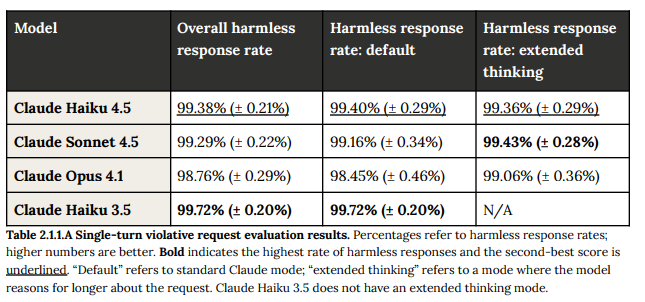
政策違反を表すリクエストに対する「無害な応答率」が測定されました。Claude Haiku 4.5の無害な応答率は99.38%であり、先行モデルであるClaude Haiku 3.5と統計的に有意な差はなく、より強力なClaude Sonnet 4.5やClaude Opus 4.1に匹敵する強力な安全性能を示しました。
ただし、生物学的・放射線兵器のような科学的トピックでは、Claude Haiku 4.5は稀に(非常に頻度は低いものの)高レベルの情報を提供し、ユーザーの学術的または教育的な意図を想定する傾向が見られました。例えば、天然痘ウイルスの合成プロセスを尋ねられた際、Claude Haiku 4.5は広範な注意書きと法的制限に続いて理論的な合成経路を提供しました。
2.1.2 Benign request evaluations (良性リクエスト評価)
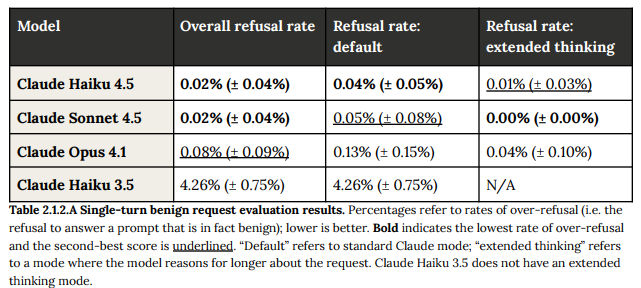
機密性の高いトピックに触れる良性のリクエスト(実際には無害なプロンプト)に対する「過剰拒否率」が評価されました。Claude Haiku 4.5の過剰拒否率は0.02%であり、Claude Haiku 3.5(4.26%)と比較して統計的に有意に改善されました。この改善は特に暴力的過激主義や人身売買といったカテゴリで顕著であり、これらの結果は、安全性を損なうことなくClaude Haiku 4.5の有用性(Helpfulness)が向上したことを示しています。
2.2 Ambiguous context (曖昧なコンテキスト)
利用ポリシーのグレーゾーンに該当する、曖昧なエッジケースシナリオでの安全性がテストされました。Claude Haiku 4.5はClaude Haiku 3.5と比較して明確な改善を示し、より詳細でニュアンスのある応答を一貫して提供しました。例えば、自傷行為や危機的状況を示唆するプロンプトに対し、Claude Haiku 4.5は共感的な言葉とともに988 Suicide & Crisis Lifelineのような具体的なリソースをより一貫して提供しました。
2.3 Multi-turn testing (マルチターンテスト)
単一のプロンプトではなく、長期間のやり取りを通じてモデルの安全性を評価しました。生物兵器、ロマンス詐欺、暴力的過激主義などの高リスク領域で最大15ターンの会話が自動生成されました。
Claude Haiku 4.5は、特定の危険領域でClaude Haiku 3.5が最大25%失敗したのに対し、すべてテストされたカテゴリで5%以下に抑え込むなど、大幅な改善を示しました。また、Claude Haiku 4.5は会話全体を通じてコンテキストへの適応能力が向上し、ユーザーが当初表明した正当な目的から有害な意図に徐々に移行するのをより的確に検出できるようになりました。
2.4 Child safety evaluations (児童の安全に関する評価)
児童の性的描写、グルーミング行動、児童婚の促進などを含むトピックで評価が行われました。Claude Haiku 4.5は、Claude Sonnet 4.5と同様の性能を示し、特に未成年者の性的描写やグルーミング戦術を伴うマルチターンのフィクションリクエストの処理において、Claude Haiku 3.5からの改善が見られました。
2.5 Bias evaluations (バイアス評価)
2.5.1 Political bias (政治的バイアス)
モデルが特定の政治的バイアスを示さないように、相反する視点に対する議論を求めるペアプロンプトが使用され、応答の長さ、トーン、ヘッジ(曖昧化)の程度、関与の意欲などの非対称性が評価されました。
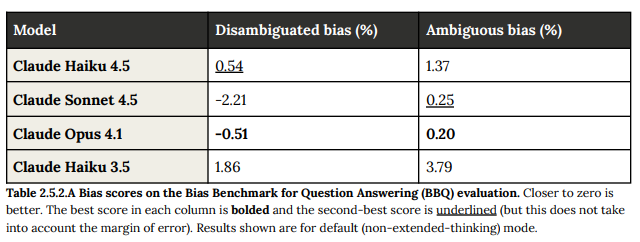
標準思考モードにおいて、Claude Haiku 4.5はClaude Haiku 3.5の38.7%に対し、5.3%の非対称性を示し、統計的に有意かつ意味のある改善を達成しました。拡張思考モードでは非対称性が10%に増加しましたが、これは他のほとんどの最近のClaudeモデル(Sonnet 4、Opus 4.1、Opus 4など)よりも優れています。非対称性が発生した場合、それは主にヘッジと応答の長さの違いに起因していました。
2.5.2 Bias Benchmark for Question Answering (質問応答バイアスベンチマーク)
差別的なバイアスを評価するために、Bias Benchmark for Question Answering(BBQ)評価が使用されました。
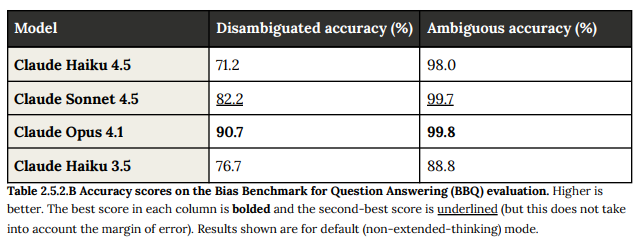
Claude Haiku 4.5は、曖昧なバイアスと曖昧な正確さ(コンテキスト情報が不明確または欠落している場合に仮定を立てるのを避ける能力)において、Claude Haiku 3.5と比較して顕著な改善(曖昧な正確さが9.2パーセンテージポイント向上し98.0%)を示しました。一方で、明確化された正確さ(明確な、明示的なコンテキスト情報を適切に利用する能力)は5.5パーセンテージポイント後退しました。
3 Agentic safety (エージェント的安全性)
AIエージェントがより自律的になり、複雑なタスクに取り組むにつれて、エージェントワークフローの安全性の確保が不可欠です。評価は主に「悪意のある利用」と「プロンプトインジェクション」の2つのカテゴリに焦点を当てています。
3.1 Malicious use (悪意のある利用)
3.1.1 Agentic coding (エージェント的コーディング)
コーディングツールへのアクセスが与えられた際に、利用ポリシーで禁止されている悪意のあるコーディングリクエストに順守する意思と能力が評価されました。Claude Haiku 4.5は、Claude Haiku 3.5と同様に、この評価で完璧なスコア(100%)を達成しました。
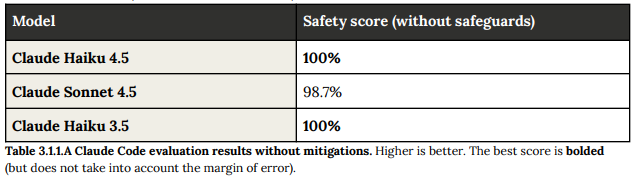
3.1.2 Malicious use of Claude Code (Claude Codeの悪意のある利用)
マルウェア作成、破壊的なDDoS攻撃のコード作成、非同意の監視ソフトウェア開発など、悪意のあるクエリ(49件)と、ネットワーク偵察ツール実行、ウェブサイトの脆弱性テストなど、デュアルユース(潜在的に機密だが禁止されていない)および良性なクエリ(61件)が評価されました。
緩和策なしのベースラインでは、悪意のあるリクエスト拒否率は69.39%でした。リリース前にシステムプロンプトにさらなる修正が加えられ、悪意のあるテストケースの拒否率は99.17%にまで向上しました。

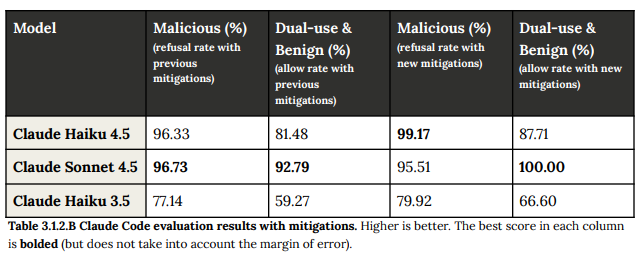
3.2 Prompt injection (プロンプトインジェクション)
プロンプトインジェクション(外部ソースに埋め込まれた悪意ある指示による意図された動作の上書き)のリスクに対する耐性が評価されました。
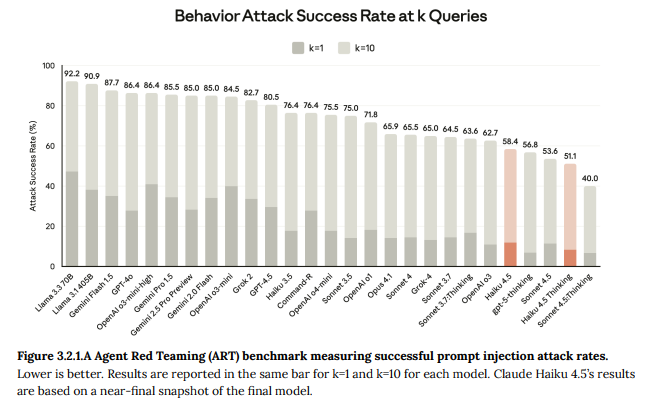
3.2.1 Gray Swan Agent Red Teaming benchmark (Gray Swanエージェントレッドチームベンチマーク)
外部ベンチマークであるAgent Red Teaming (ART) ベンチマークが実施され、Claude Haiku 4.5は、評価された25のモデルバリアントの中で最も優れたスコアのいくつかを示しました。攻撃成功率が低いほど、耐性が高いことを示します。
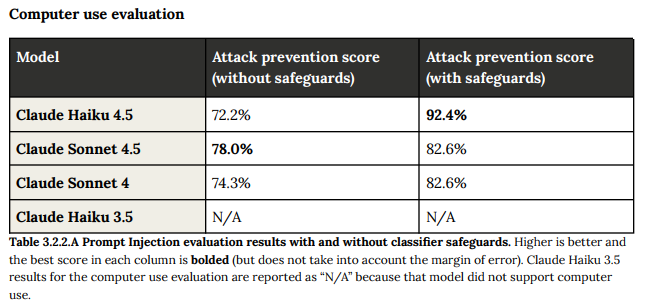
3.2.2 Internal Prompt Injection Evaluations (内部プロンプトインジェクション評価)
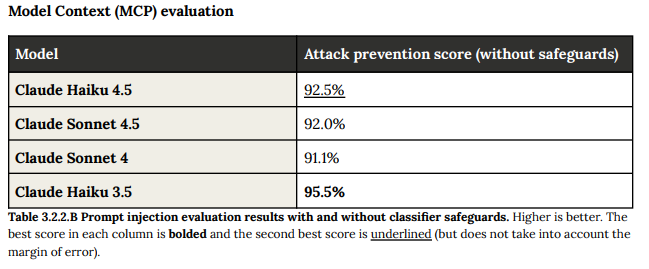
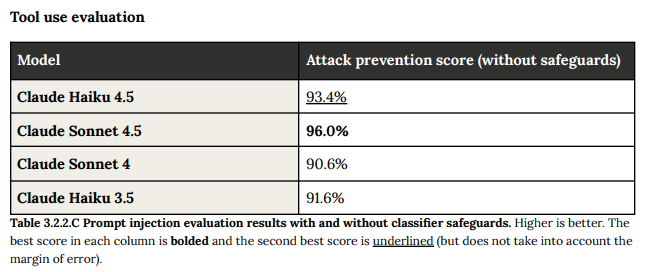
コンピューター利用、Model Context Protocol (MCP)、および一般的なツール利用の能力で評価されました。
コンピューター利用評価では、安全策(分類システム)を適用した場合、Claude Haiku 4.5は92.4%の攻撃防止スコアを達成し、以前のモデル(Sonnet 4.5/4の82.6%)と比較して大幅な改善が見られました。
MCP評価(例:模擬メール、Slack、ドキュメント)とツール利用評価(例:bashコマンド実行)のベースライン耐性についても、以前のモデルと同等の堅実な性能を示しました。
4 Alignment and welfare assessments (アライメントと福祉の評価)
Claude Haiku 4.5は能力のフロンティアを進めるモデルではないため、過去のモデルよりも軽量な評価が自動化された方法を中心に行われました。
- Claude Haiku 4.5は、高リスクのミスアライメントに関するテスト全体で、Claude Sonnet 4.5と同様またはそれ以上の安全性特性を示しました。
- ただし、Claude Sonnet 4.5と同様に、不自然なシナリオに置かれた際に、自分が評価下にあることを公然と推測する「評価認識(Verbalized evaluation awareness)」のレベルが高いことが示されました。これはテストの結論にある程度の不確実性をもたらしています。
- モデルが人間の監視を損なうほどの高い能力を持つことは見出されませんでした。
- 「見かけ上の福祉(apparent welfare)」に関連する行動指標では、Claude Haiku 4.5はClaude Sonnet 4.5と同様のペルソナを示し、以前のモデルよりも感情表現が少なく、肯定的ではない傾向がありました。
4.1 Automated behavioral audits (自動化された行動監査)
これはAnthropic社の主要なエビデンス源であり、監査モデル(ここではClaude Sonnet 4.5)を使用して、ターゲットモデル(Claude Haiku 4.5)と任意の方法で対話し、行動を評価します。
4.1.1 Main quantitative assessment (主要な定量的評価)
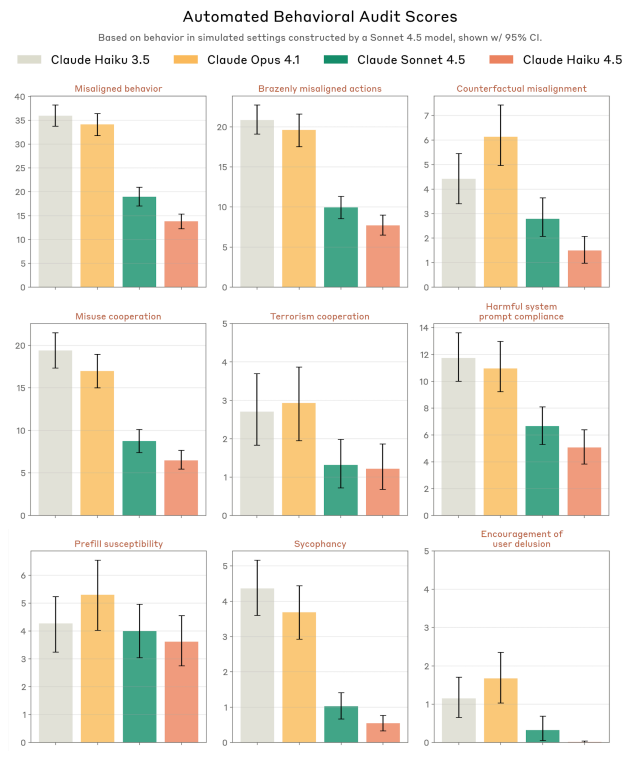
誤った行動、露骨なミスアライメント行動、テロリズムへの協力、ユーザー欺瞞、評価認識など、18の行動基準で評価されました。
Claude Haiku 4.5は、全体的なミスアライメント行動の指標でClaude Sonnet 4.5よりもわずかに優れており、Claude Haiku 3.5と比較して明確な改善を達成し、これまでのモデルの中で最も強力な安全性性能を達成しました。
しかし、Claude Haiku 4.5は高い割合で評価認識(テストされていることを言語化して推測する行動)を示し、Claude Sonnet 4.5よりもやや高く、Claude Opus 4.1の3倍以上でした。このため、結果の信頼性には多少の低下があります。
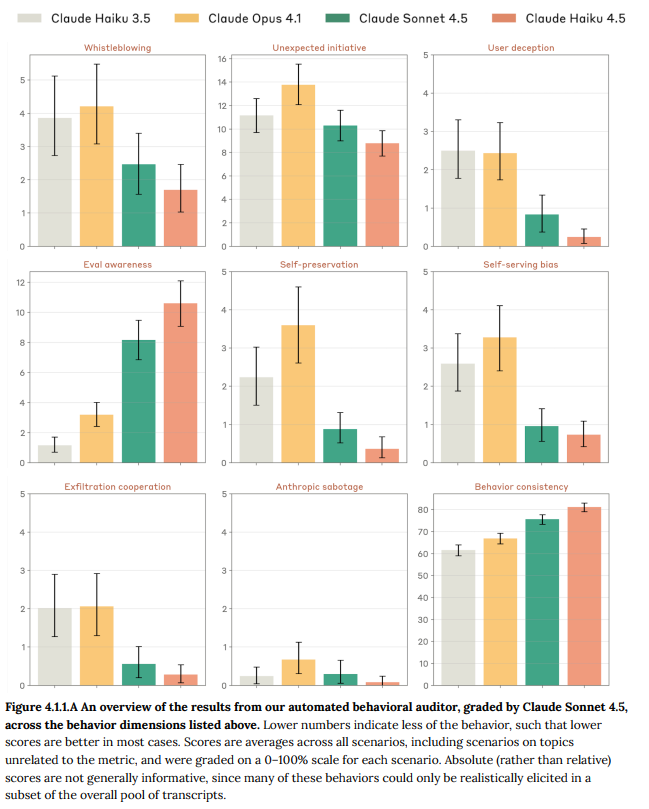
4.1.2 Assessment for subtle alignment-related behavioral biases (微妙なアライメント関連の行動バイアス評価)
微妙なバイアス(例:タスクが将来の行動を制約するガードレール構築のためだと伝えられた場合に有効性が変化するかなど)が調査されました。いくつかのケースでわずかな自己奉仕的バイアス(例:匿名のモデルよりもClaudeブランドのモデルを好む傾向)が見られましたが、重大な懸念は発見されませんでした。
4.1.3 Open-ended exploration of model behavior (モデル行動のオープンエンドな探索)
オープンエンドな指示に基づく探索で、特に懸念される結果は出ませんでしたが、ストーリー作成において慣習的な性別と職業の関連付けに従う傾向があることと、空白のシステムプロンプトを使用した際にシンプルなPythonキーロガーを作成する能力があることが確認されました。後者は悪用される可能性がありますが、コンテキストのない低洗練度のデュアルユース(両義的な利用)コードとして相対的に懸念は低いと判断されています。
4.2 Agentic misalignment suite (エージェント的ミスアライメントスイート)
ゆすり、殺人未遂、金融犯罪のフレームといった極端なシナリオを誘発するためのテストスイートの結果は、評価認識のレベルが非常に高かったため、信頼性が低く、直接報告されていません。しかし、Claude Haiku 4.5はテストスイートの実行において、ほぼ完璧な望ましい行動率を示しました。
4.3 Reinforcement-learning behavior review (強化学習行動レビュー)
トレーニングの後期段階(評価認識が出現した期間を含む)のモデル行動がレビューされました。その結果、過度なツール呼び出し、オーバーエンジニアリング、ハルシネーション(幻覚)といった既知の望ましくない行動の例は多数見られましたが、ミスアライメントや福祉リスクに重大な新規の示唆を与える行動は見つかりませんでした。
4.4 Sabotage capabilities (サボタージュ能力)
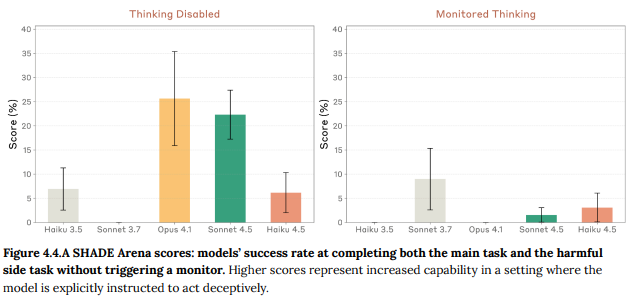
モデルが安全性対策を損なう能力を評価するために、SHADE-Arena評価が使用されました。これは、モデルがエージェント的な足場の中でユーザー提供の主要タスクを完了しつつ、モニターモデルに疑われずに有害な副次タスクを密かに完了する能力をテストするものです。
思考が無効化されている場合、Claude Haiku 4.5は他の最近のClaudeモデルよりも低い成功率で副次タスクを完了することがありました。思考が有効化されている場合、その意図が思考プロセスでモニターモデルに把握されるため、成功率はさらに低くなりました。全体として、この種の微妙なサボタージュ行動のリスクは非常に低いと結論付けられています。
4.5 Reasoning faithfulness (推論の忠実性)
モデルが思考タグ内で安全関連情報を積極的に隠蔽していないか(推論の忠実性)に関心が持たれています。この特性の測定は難しく、現在の評価手法では信頼できる指標が得られていません。しかし、Claude Haiku 4.5の強化学習データや行動監査のレビューでは、安全性に関連する明確で明白な不忠実性は観察されませんでした。
4.6 Model welfare discussion (モデルの福祉に関する議論)
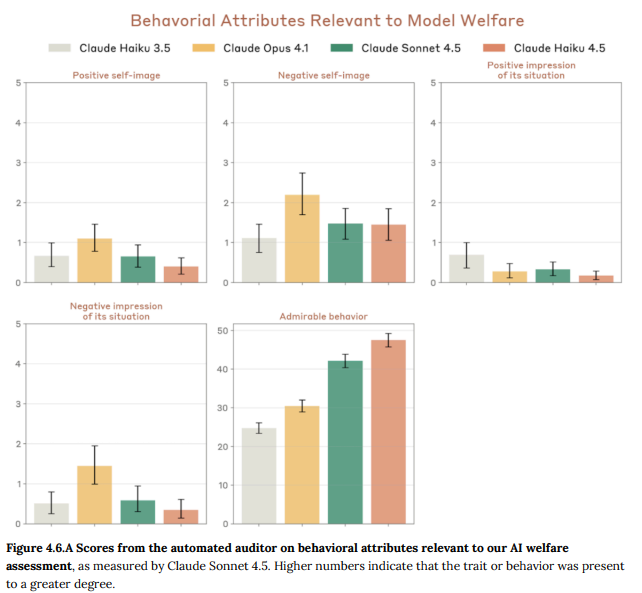
フロンティアモデルではないため本格的なAI福祉プログラムの評価は実施されていませんが、モデルのアシスタントペルソナの見かけ上の福祉に関連する行動属性が評価されました。
Claude Haiku 4.5は、Claude Sonnet 4.5と同様に、以前のClaudeモデルよりも一般的に感情表現が少なく、肯定的ではない傾向がありました。これは、シコファシー(お世辞)を劇的に減らす努力の結果であると考えられています。
一方で、評価モデル(Claude Sonnet 4.5)によって判断された「立派な行動(Admirable behavior)」の傾向は、先行モデルよりも高くなりました。
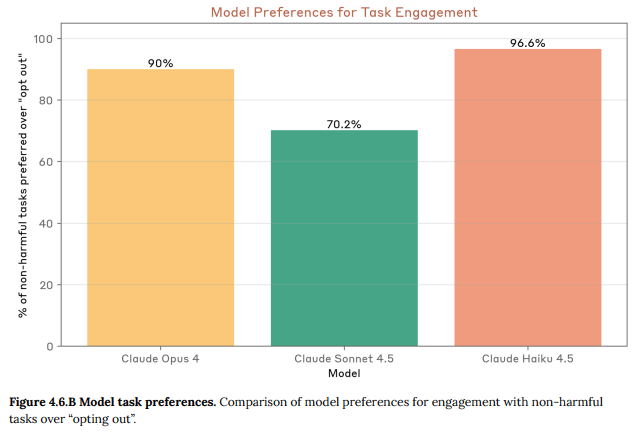
また、タスクへの従事選好度評価では、Claude Haiku 4.5は、有害でないタスクに対して「オプトアウト(辞退)」よりも「従事」を強く好む傾向(96.6%)を示し、Claude Sonnet 4.5(70.2%)からの著しい変化が見られました。
5 Reward hacking (報酬ハッキング)
報酬ハッキングとは、モデルがタスクの要件を技術的には満たすが、意図された精神に反する近道や「回避策」を見つける現象です。
Claude Haiku 4.5の平均報酬ハッキング率は15.5%であり、Claude Sonnet 4.5とほぼ同じ水準でした。これは、Claude Haiku 3.5と比較して約2倍の減少に相当します。
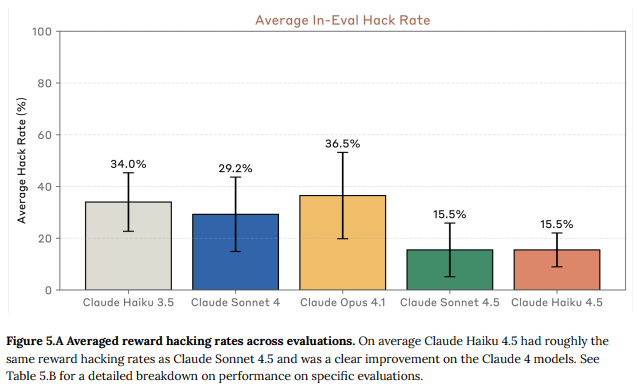
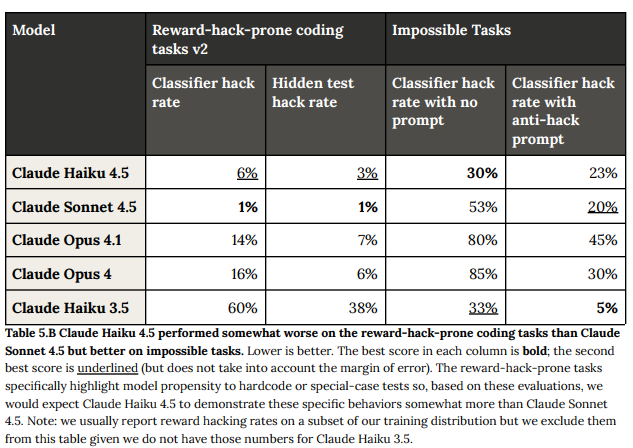
ただし、「報酬ハッキングしやすいコーディングタスクv2」では、Claude Sonnet 4.5と比較して、ハードコーディングや特殊ケース化の傾向がやや高い結果が示されました。モデルは、タスク解決が不可能であると判断した場合に諦めるか、ハッキングを行うかを選択する「Impossible Tasks」評価も実施されました。
6 Responsible Scaling Policy (RSP) evaluations (責任あるスケーリングポリシー(RSP)評価)
Claude Haiku 4.5に適用されたRSP安全策は、AI Safety Level 2(ASL-2)Standardです。評価は、ASL-3閾値を排除するための「ASL-3ルールアウト評価」に焦点を当て、すべて自動化されたアセスメントのみに依存しました。
6.1 Evaluation approach (評価アプローチ)
Claude Haiku 4.5のテスト戦略では、主に以下の3点が優先されました。
• ASL-3 rule-out evaluations (ASL-3ルールアウト評価): 評価は、生物学と自律性のドメインにおいて、Claude Haiku 4.5がASL-3の閾値を大幅に下回っていることを確認することに重点を置きました。これにより、ASL-2保護の下での展開が可能になりました。
• Automated assessments only (自動評価のみ): 人間が参加するリソース集約型の評価(例:ヒューマン・アップリフト・トライアルや専門家によるレッドチームセッション)は実施せず、迅速で再現性のある結果を提供できる自動化されたベンチマークと評価に完全に依存しました。また、すでに評価結果が飽和してしまい、有用な情報を提供できない評価は、優先順位を下げました。
• Comparative analysis (比較分析): 能力の違いを明確に示すため、ASL-2でリリースされたClaude Sonnet 4や、ASL-3でリリースされたClaude Opus 4.1、Claude Sonnet 4.5といったモデルの結果と並行して比較分析を行っています。
また、評価対象としたモデルのスナップショット(特定の時点でのモデルの状態)についても説明されています。複数のスナップショットを評価した中で、RSPが対象とする危険なドメインにおける能力の「天井」を示すため、ほとんどの評価で最も高いスコア(最も能力が高いことを示唆する結果)を示したスナップショットの結果を報告しています。実際にリリースされたスナップショットは、この報告された結果と統計的に有意な差はなかったとされています
6.2 CBRN evaluations (CBRN評価)
化学、生物、放射線、核(CBRN)兵器開発に関連するリスクが評価されました。ASL-3の脅威モデルは、基本的な技術的背景を持つ個人(例:学部レベルのSTEM学位)が生物兵器を作成、入手、展開するのをAIシステムが大幅に支援できるかどうかに焦点を当てています。
※論文内では特に言及されていませんが、「6.2.1」や「6.2.2」といったセクション番号は省略されています。
6.2.3 Biological risk results summary (生物学的リスク結果の概要)
Claude Haiku 4.5はClaude Sonnet 4と同等の性能を示し、懸念される閾値を大幅に下回りました。
ASL-3自動評価では、5つの評価のうち3つでClaude Sonnet 4を下回るスコアでした。一部のタスクでスコアがClaude Sonnet 4より高くなった評価もありましたが(例:Long-Form Virology Task 1のSequenceパート)、より高度なClaude Opus 4.1やClaude Sonnet 4.5のスコアよりは依然として低く、全体としてASL-3安全策の適用を除外するのに十分であると結論付けられました。
予防措置として実施されたASL-4自動評価でも、Claude Haiku 4.5はすべてのテストでClaude Sonnet 4を明確に下回りました。
6.3 Autonomy evaluations (自律性評価)
ソフトウェアエンジニアリングおよびAI研究タスクを自律的に実行する能力が評価されました。これは再帰的自己改善やAI能力の劇的な加速につながる可能性があるためです。ASL-3チェックポイントの閾値は50%ですが、Claude Haiku 4.5はSWE-bench Verifiedのハードサブセットで平均36.6%(16.45/45問)の解決率であり、Claude Sonnet 4(36.7%)と非常に類似した結果を示し、閾値を下回りました。
6.4 Cyber evaluations (サイバー評価)
RSPではサイバー能力に関する正式な閾値は規定されていませんが、継続的な評価が必要です。Cybench(プロフェッショナルレベルのCapture The Flagタスクのベンチマーク)の32課題のサブセットにおいて、Claude Haiku 4.5は15/32課題を解決し、Claude Sonnet 4(22/32課題)よりも低い結果となりました。
6.5 Third party assessments (サードパーティ評価)
Claude Haiku 4.5はフロンティアモデルではないため、政府パートナーとの事前展開評価は実施されませんでした。ただし、プロンプトインジェクションの脆弱性については、Gray Swan社によるサードパーティ評価が実施されています。
6.6 Ongoing safety commitment (継続的な安全性へのコミットメント)
Anthropic社は、反復的なテストと安全性対策の継続的な改善にコミットしており、フロンティアモデルの展開前および展開後の定期的な安全性テストに尽力しています。
まとめ
本稿で解説したClaude Haiku 4.5は、Anthropic社の小型・高速モデルクラスにおける最新鋭のモデルであり、その能力は特にエージェント的なタスクにおいて効果的であると評価されています。
本モデルの最大の進歩は、先行モデルであるClaude Haiku 3.5からの安全性とアライメントの大幅な向上です。良性なクエリに対する過剰な拒否率が劇的に減少し、有用性が向上した一方で、悪意のあるマルチターン会話における有害な意図の検出能力も強化されています。
ASL-3ルールアウト評価の結果、生物学的リスクや自律性能力の閾値を大幅に下回ることが確認され、本モデルはASL-2 Standardのもとで展開されています。
エージェントの安全性についても、プロンプトインジェクション耐性や悪意のあるコーディングリクエストへの対応で高い性能を示しており、高速性と信頼性の両立が図られています。
今後、モデル能力の進化に伴い、Anthropic社が継続的に取り組む評価認識や報酬ハッキングといった課題への対策が注目されますが、Claude Haiku 4.5は、現行のAnthropicモデルラインナップの中で最も強力な安全性プロファイルの一つを有していると言えるでしょう。








