
はじめに
本稿では、GitHubが2025年9月24日に公式ブログで発表した、GitHub Copilotの新しい埋め込みモデルについて解説します。このモデルの導入により、Visual Studio Code(VS Code)上でのコード検索がこれまで以上に高速、軽量、そして高精度になりました。AIによるコーディング支援が当たり前になる中で、その裏側でどのような技術が使われているのか、掘り下げていきます。
参考記事
- タイトル: GitHub Copilot gets smarter at finding your code: Inside our new embedding model
- 発行元: GitHub Blog
- 発行日: 2025年9月24日
- URL: https://github.blog/news-insights/product-news/copilot-new-embedding-model-vs-code/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- GitHub Copilotは、コード検索の精度、速度、メモリ効率を大幅に向上させる新しい埋め込みモデルを導入した。
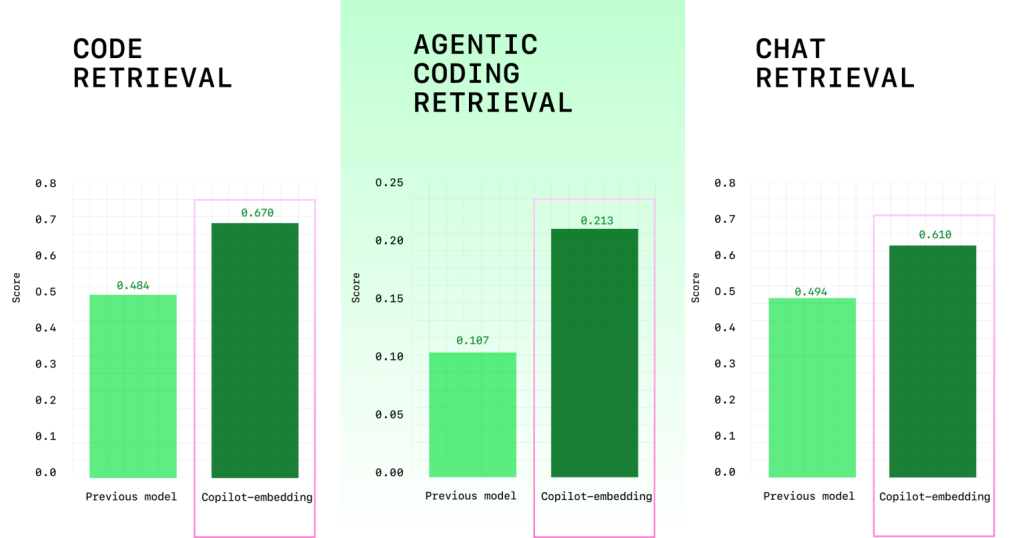
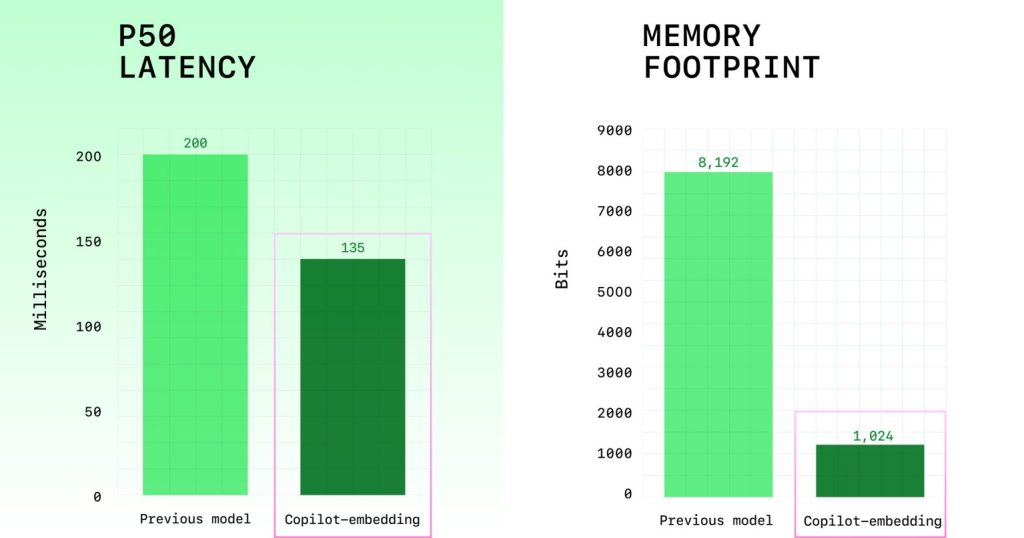
- 検索品質は37.6%向上し、スループット(処理能力)は約2倍、インデックスサイズ(メモリ使用量に影響)は8分の1になった。
- この改善の鍵は、「ハードネガティブ」と呼ばれる「正解に近いが不正解」のデータを活用した対照学習にある。
- これにより、Copilotは開発者の曖昧な指示や意図をより正確に理解し、本当に必要なコードスニペットを提供する能力が向上した。
詳細解説
AIコーディング支援における「検索」の重要性
今日のAIコーディング支援ツールにとって、開発者の意図に合った適切な情報をコードベースから迅速に見つけ出す能力は、その性能を左右する最も重要な要素の一つです。ここで言う情報とは、コードスニペット、関数、テスト、ドキュメントなど多岐にわたります。
この「検索」の役割を担っているのが、「埋め込み(Embeddings)」という技術です。埋め込みとは、コードや自然言語の文章を、コンピュータが意味的な関連性を計算できる数値のベクトル(ベクトルのリスト)に変換する技術です。このベクトル表現により、単語が完全に一致していなくても、意味的に近いコードやドキュメントを探し出すことが可能になります。より優れた埋め込みモデルは、より精度の高い検索結果をもたらし、結果としてGitHub Copilotの体験を向上させます。
新モデルがもたらした具体的な成果
今回導入された新しい埋め込みモデルは、コードとドキュメントに特化して訓練されており、主に3つの点で大きな改善を実現しました。
- 検索品質の向上: 複数のベンチマーク評価で、検索品質が37.6%向上しました。特に、VS Code上でC#を使用する開発者ではコードの受け入れ率が110.7%、Javaでは113.1%も向上しており、より的確なコードが提案されるようになったことを示しています。
- 効率性の向上: 埋め込みを生成するスループットが約2倍になり、検索結果がより速く返ってくるようになりました。
- メモリ使用量の削減: インデックスのサイズが8分の1に縮小されました。これにより、VS Codeのメモリ消費が抑えられ、より快適な開発環境に貢献します。
例えば、開発者が「プロジェクト内で名前によって単一の名前空間を見つけるメソッドはどれか?」と質問したとします。
新モデルは、findOneというまさにその目的の関数を含むコードを正しく提示します。
class Namespace extends K8Object {
/*...*/
static findOne(params = {}, options = {}) {
return Model.findOne(params, options).then((namespace) => {
console.log(namespace);
if (namespace) {
return new Namespace(namespace).setResourceVersion();
}
});
}
/*...*/
}一方で、旧モデルは意味的には似ていますが、複数の名前空間を検索するfind関数を提示してしまい、意図とは少しずれた結果を返していました。
class Namespace extends K8Object {
/*...*/
static find(params = {}, options = {}) {
return Model.find(params, options).then((namespaces) => {
if (namespaces) {
return Promise.all(
namespaces.map((namespace) =>
new Namespace(namespace).setResourceVersion()
)
);
}
});
}
/*...*/
}このように、新モデルは微妙なニュアンスの違いを正確に識別する能力が向上しています。
精度の鍵は「ハードネガティブ」
では、どのようにしてこの精度向上を実現したのでしょうか。その鍵は「対照学習(Contrastive Learning)」と、そこで用いられる「ハードネガティブ(Hard Negatives)」というデータにあります。
- 対照学習とは?
「正解のペア」と「不正解のペア」をモデルに学習させる手法です。例えば、「質問とその答えとなるコード」を正解ペアとして、そのベクトル空間上での距離が近くなるように学習させます。逆に、不正解ペアの距離は遠くなるように学習します。 - ハードネガティブとは?
今回のモデル開発で最も重要だったのが、この不正解ペアの質です。特に「一見すると正しそうに見えるが、実は間違っているデータ」を「ハードネガティブ」と呼びます。コード検索で失敗する多くは、この“惜しい間違い”が原因です。
GitHubの公式では、「ストップワードのテーブルはどのようにして読み込まれるか?」という質問を例に挙げています。- 正解(Positive Example): ファイルからストップワードのテーブルを読み込む関数
- ハードネガティブ(Hard Negative Example): 単語をテーブルに読み込むだけの関数や、ファイルからストップワードを読み取るだけの関数

モデルに、このような「惜しい間違い」を重点的に学習させることで、「ほとんど合っている」と「完全に合っている」を区別する能力が向上し、検索精度が高まります。GitHubは、公開リポジトリや社内リポジトリからこれらのハードネガティブを収集し、さらにLLM(大規模言語モデル)も活用して、巧妙な「惜しい間違い」のデータセットを構築しました。
学習データと今後の展望
このモデルの学習には、Python(36.7%)、Java(19.0%)、C++(13.8%)などを中心に、多様なプログラミング言語のデータが使用されています。
GitHubは今後、さらに多くの言語やリポジトリで学習データを拡大し、ハードネガティブの収集方法を洗練させ、より大規模で高精度なモデルを導入していくとしています。
まとめ
本稿では、GitHub Copilotに導入された新しい埋め込みモデルについて、その成果と技術的背景を解説しました。
このモデルは、「ハードネガティブ」と呼ばれる巧妙な不正解データを活用した対照学習により、コード検索の精度と効率を著しく向上させました。これにより、開発者は自身の意図に沿ったコード補完をよりスムーズに受けられるようになり、日々の開発体験がさらに向上することが期待されます。AIコーディング支援技術の進化は続いており、今後のさらなる発展に注目です。








