
はじめに
近年、AI技術の発展は目覚ましく、私たちの生活に深く溶け込みつつあります。特に大規模言語モデル(LLM)は、翻訳、要約、コンテンツ生成といった多岐にわたるタスクで驚くべき能力を発揮しています。しかし、その一方で、LLMが膨大な量のデータで学習されることから、プライバシーの保護という新たな課題が浮上しています。学習データに含まれる個人情報や機密情報が、モデルによって記憶され、意図せず漏洩するリスクが懸念されています。
このような背景から、Googleはプライバシー保護の観点からもAI開発を進めていました。そして、その最前線で生まれたのが、今回ご紹介する「VaultGemma」です。VaultGemmaは、差分プライバシー(Differential Privacy: DP)という厳密な数学的保証を備えたプライバシー保護技術を導入し、ゼロから学習された大規模言語モデルとしては、最大級の差分プライバシー学習済みオープンモデルとなります。
本稿では、このVaultGemmaの技術的な特徴や、その基盤となった「DPスケーリング法則」について解説します。
参考論文
- 論文タイトル:Scaling Laws for Differentially Private Language Models
- 論文URL:https://arxiv.org/pdf/2501.18914
- 発行日:2025年1月
- 発表者:Amer Sinha, Ryan McKenna (他多数)
参考レポート
- レポートタイトル:VaultGemma: A Differentially Private Gemma Model
- レポートURL:https://arxiv.org/pdf/2501.18914
- 発行日:2025年9月12日
参考記事
- タイトル:VaultGemma: The world’s most capable differentially private LLM
- URL:https://research.google/blog/vaultgemma-the-worlds-most-capable-differentially-private-llm/
- 発行日:2025年9月12日
- 発表者:Amer Sinha
要点
- VaultGemmaは、差分プライバシーを適用してゼロから学習された、世界で最も高性能な10億パラメータ規模のLLMである。
- 計算量・プライバシー・ユーティリティの複雑なトレードオフを正確にモデル化する「DPスケーリング法則」を確立した。
- DPスケーリング法則の知見に基づき、モデルサイズ、バッチサイズ、イテレーション(繰り返し回数)の最適な構成を特定してVaultGemmaを構築した。
- 現在のDP学習手法は、約5年前の非プライベートモデル(Gemma2)と同等のユーティリティを提供できることを実証し、DPモデルと非DPモデルの性能差を体系的に縮めるロードマップを示した。
- VaultGemmaは、 \((\epsilon \leq 2.0, \delta \leq 1.1e-10)\) のシーケンスレベルDP保証を備え、訓練データからの検出可能な記憶は示さない。
詳細解説
プライバシー保護の必要性
LLMは膨大な量のウェブスケールのデータでトレーニングされており、その中には機密性の高い個人情報が含まれている可能性があります。既存のLLMは、トレーニングデータの逐語的記憶と抽出に対して脆弱であることが示されています。これは、トレーニング時に取得した個人情報や機密データが誤って漏洩するリスクが高いことを意味しています。そのため、対策が必要であると考えられていました。
差分プライバシー(Differential Privacy: DP)とは?
差分プライバシー(Differential Privacy: DP)とは、AIモデルの学習において、個々のデータポイントが最終モデルに与える影響を数学的に厳密に制限するための技術です。簡単に言えば、「ある個人のデータを含んで学習したモデルと、その個人のデータを含まずに学習したモデルの振る舞いが、統計的にほとんど区別できないようにする」ことを保証します。
この保証を実現するために、DPは学習プロセスに「ノイズ」を加えます。例えば、モデルの勾配(学習の方向を示す情報)にランダムなノイズを加えることで、特定の個人データからの寄与が隠蔽され、モデルがそのデータを記憶してしまう(Memorization)ことを防ぎます。これにより、仮に悪意のある攻撃者がモデルを分析したとしても、特定の訓練データがモデルに利用されたかどうかを高い確率で特定することが困難になります。これは、個人情報が意図せずモデルから抽出されるリスクを軽減する上で非常に強力な手段です。
しかし、大規模言語モデル(LLM)のような複雑なモデルにDPを適用することは、いくつかのトレードオフを伴います。特に、プライバシー保護のためにノイズを加えると、従来のモデル学習における「スケーリング法則」(モデルの性能がモデルサイズやデータサイズに応じて比例的に向上するとされる経験則)が大きく変化します。具体的には、DPを適用すると、モデルの学習が安定しにくくなったり(訓練安定性の低下)、学習に必要なデータバッチのサイズ(一度に処理するデータのかたまり)や計算コストが大幅に増加したりする傾向があります。これは、ノイズによって学習信号が埋もれやすくなるため、より多くのデータや計算リソースを使ってその影響を打ち消す必要があるためです。
DPスケーリング法則の発見
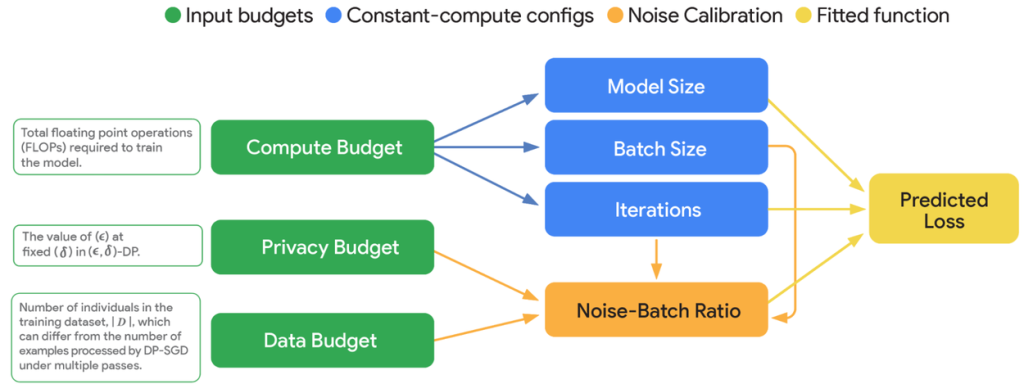
VaultGemmaの開発において、Google ResearchはGoogle DeepMindと共同で、「DPスケーリング法則」を確立しました。これは、DPを適用したLLMの学習において、計算予算、プライバシー予算、そしてモデルの有用性(utility)という三つの要素がどのように相互作用するかを正確にモデル化するものです。
この研究の核心は、「ノイズ・バッチ比」(noise-batch ratio: \(\sigma\))という概念が、DP学習におけるモデルの性能に最も大きく影響するという仮説に基づいています。ノイズ・バッチ比とは、プライバシー保護のために加えられるランダムノイズの標準偏差と、学習に使用するミニバッチの勾配の平均との比率のことです。DP-SGD(差分プライバシーを保証する確率的勾配降下法)では、勾配クリッピングとガウスノイズの追加によってDPが達成されますが、このノイズが学習の分散に大きく影響するため、ノイズ・バッチ比が学習性能の重要な指標となると考えられます。
ノイズ・バッチ比について
ノイズ・バッチ比は、イメージとしては、「プライバシーを守るためにどれくらいの『目くらましノイズ』を加えるか」と、「そのノイズが、一度に学習するデータのかたまり(ミニバッチ)から得られる学習信号(勾配)に比べてどれくらい大きいか」を示す指標だと捉えることができます。
DP-SGD(差分プライバシーを保証する確率的勾配降下法)という学習方法では、個々のデータがモデルに与える影響を制限するために、主に二つのステップを踏みます。
1. 勾配クリッピング (Gradient Clipping):各データポイントから計算される勾配(モデルをどの方向にどれだけ更新すべきかを示す情報)が大きくなりすぎないように、一定の閾値で「切り詰める」作業です。これにより、特定の個人データが極端に大きな影響をモデルに与えることを防ぎます。
2. ガウスノイズの追加 (Adding Gaussian Noise):クリッピングされた勾配の合計に、ランダムなノイズを加えます。このノイズは、訓練データに含まれる個々の情報がモデルのパラメータにどれだけ反映されたかを外部から分析されにくくするためのものです。
このとき、追加されるガウスノイズの「標準偏差」と、学習に使う「ミニバッチのサイズ」が、ノイズ・バッチ比の主要な構成要素となります。
なぜノイズ・バッチ比が学習性能の重要な指標となるのか?
DP-SGDにおいて、学習の方向を示す勾配の推定には、主に二つの分散(ばらつき)の源があります。一つは、ミニバッチからサンプリングすることによる本来の確率的勾配降下法に由来する分散、もう一つは、プライバシー保護のために追加されるガウスノイズによる分散です。
特に、DP学習においては、この後者のガウスノイズによる分散が、ほとんどの実用的なケースで支配的となることが先行研究で示されています。つまり、プライバシーのために加えるノイズが非常に大きいため、従来の学習のようにデータから得られる「純粋な学習信号」がノイズの中に埋もれやすくなってしまうのです。
このノイズが大きすぎると、モデルは学習の方向を正確に捉えられなくなり、訓練が安定しにくくなったり、学習に非常に時間がかかったり、そもそも性能が向上しにくくなったりします。そこで、ノイズ・バッチ比が小さければ小さいほど、ノイズの影響が相対的に小さくなり、モデルはより効率的に学習を進めることができます。
計算予算、プライバシー予算、データ予算との関連性
このノイズ・バッチ比は、DP学習における計算予算、プライバシー予算、データ予算という三つの重要な要素と密接に関係しています。
• 計算予算 (Compute Budget):モデルの学習に使える計算資源の総量です。例えば、訓練の繰り返し回数(イテレーション)を増やしたり、モデルサイズを大きくしたり、ミニバッチサイズを大きくしたりするのに使われます。
• プライバシー予算 (Privacy Budget \(\epsilon\)):個々のデータポイントがモデルに与える影響の「許容度」を数値化したものです。\(\epsilon\) の値が小さいほどプライバシー保護が強固になりますが、その分ノイズを多く加える必要があるため、モデルの有用性は低下しやすくなります。
• データ予算 (Data Budget N):訓練に利用できる個人の総数、あるいはデータポイントの総数です。DP学習では、訓練データが有限であるという前提が重要になります。
これらの予算をどのように配分するかによって、最終的なノイズ・バッチ比が変わってきます。例えば、以下のような相互作用が観察されています。
• プライバシー予算を単独で増やしても効果が限定的: プライバシー予算 \(\epsilon\) を増やす(つまりプライバシー保護を緩める)だけでは、ノイズ・バッチ比の減少効果は頭打ちになる傾向があります。
• 計算予算やデータ予算との相乗効果: プライバシー予算を増やしつつ、同時に計算予算(FLOPs)やデータ予算(訓練トークン数)も増やすことで、ノイズ・バッチ比が継続的に減少し、モデルの性能が向上します。これは、より多くのデータや計算リソースを使って、プライバシー保護のために加えられたノイズの影響を「薄める」ことができるためです。
• 大きなバッチサイズの重要性: DP学習では、ノイズの影響を軽減するために、非常に大きなミニバッチサイズでの訓練が不可欠であるとされています。一度に処理するデータが多いほど、個々のデータポイントの勾配に加わるノイズの影響が相対的に平均化され、学習信号がより明確になるためです。
このように、ノイズ・バッチ比は、DP学習の「難しさ」と「可能性」を同時に示す指標であり、この比率をいかに効果的に管理・最適化するかが、プライバシー保護とモデル性能の両立の鍵となります。VaultGemmaの研究では、このノイズ・バッチ比を中心に据えてDPスケーリング法則を構築し、最適な学習設定を見つけ出すことを目指しました。
実験
研究チームは、モデルサイズ、ノイズ・バッチ比、訓練イテレーション数を変化させながら大規模な実験を行い、その結果からDPスケーリング法則を導き出しました。これにより、例えば「特定の計算予算、プライバシー予算、データ予算が与えられたときに、最小の訓練損失(学習の誤差)を達成するための最適な訓練設定は何であるか?」といった問いに答えられるようになりました。
主な発見としては、以下のような点が挙げられます。
- 最適な計算予算配分が非DP学習とは大きく異なる: 非DP学習では、計算予算が増えれば増えるほどモデルサイズやデータ量を増やして性能が向上し続けますが、DP学習では、ある一定の計算予算を超えると性能向上が鈍化する「臨界計算予算」が存在します。
- 最適なモデルサイズはDPなしの場合より小さい: 例えば、非DP学習で最適なモデルサイズが100億パラメータであるような計算量でも、DP学習では1億パラメータ程度が最適と予測されるなど、DP下では一般に、非DPの場合よりも最適なモデルサイズが数分の1から数十分の1程度小さくなることが示されています。
- トークン・モデル比の変化: 非DP学習では、訓練トークン数とモデルサイズの比率が約20倍が最適とされていましたが、DP学習では、プライバシー予算が小さいほどこの比率が大きく増加し、1,000倍から100,000倍といった範囲になることがあります。これは、DPではより多くのデータで訓練することが重要であることを示唆しています。
- プライバシー予算と計算予算の相乗効果: プライバシー予算を単独で増やしても効果が限定的であるのに対し、計算予算やデータ予算も同時に増やすことで、ノイズ・バッチ比が継続的に減少し、モデル性能が向上することが分かりました。
VaultGemmaの構築
これらのDPスケーリング法則の知見を基盤として、Googleは「VaultGemma」を構築しました。VaultGemmaは、Googleが責任と安全性を核として設計したGemmaモデルをベースにしており、その開発には以下のようなアルゴリズム的な進歩が組み込まれています。
アルゴリズム的な進歩:大規模学習への対応
最適な学習率のモデリング:
従来の試行錯誤による学習率の調整ではなく、モデルサイズとノイズ・バッチ比の関数として、各設定における最適な学習率を明示的にモデル化する手法を導入しました。これにより、より効率的かつ正確に最適な性能を引き出すことが可能になりました。
損失値のパラメトリック外挿:
訓練イテレーションの広い範囲で損失値を効率的に推定するために、 \( L = E + A/T^\alpha \) のような簡潔な数式(ここで \( L \) は損失、 \( T \) は訓練イテレーション数、 \( E, A, \alpha \) は適合パラメータ)を用いて損失曲線をパラメトリックにフィッティングしました。これにより、限られた実験データから広範囲のイテレーション数における損失を補間・外挿できるようになりました。
セミパラメトリックフィット:
上記のパラメトリックな損失外挿と、モデルサイズ、訓練イテレーション数、ノイズ・バッチ比の広い範囲で緻密なグリッドを作成し、これらを非パラメトリックモデルにフィットさせる二段階のセミパラメトリックアプローチを採用しています。これにより、複雑な相互作用をより頑健にモデル化しています。
Poissonサンプリングの課題とTruncated Poisson Subsampling:
DP-SGDの中核をなすPoissonサンプリングは、データからミニバッチを抽出する際に各データポイントが一定の確率で選ばれるため、バッチサイズが変動するという課題がありました。これは学習効率の低下を招きます。VaultGemmaでは、この課題を解決するために「Scalable DP-SGD」の最新の研究成果、特に「Truncated Poisson Subsampling」を導入しました。この方法では、バッチサイズを固定しつつ、不足分はパディング(水増し)、超過分はトリミング(切り捨て)することで、強いプライバシー保護を維持しながら効率的な学習を実現しています。このデータ処理は、オンザフライでサンプリングとバッチングを行うことで、計算オーバーヘッドを最小限に抑えています。
データセットとアーキテクチャ
- VaultGemmaは、Gemma 2シリーズと同じ、主に英語のデータ混合物(ウェブドキュメント、コード、科学記事など13兆トークン)で事前に訓練されています。
- 不要なコンテンツや個人情報のリスクを減らすため、高度なフィルタリング技術が適用されています。
- モデルアーキテクチャは、他のGemmaモデルと同様にデコーダオンリー型で、シーケンス長を1024トークンに短縮することで計算要件を削減し、DP学習に必要な大きなバッチサイズでの訓練を可能にしています。
トレーニング設定
- VaultGemmaの訓練は、2048チップのTPUv6eを構成した環境で行われました。
- 2048方向のデータレプリケーションと1方向のモデルシャーディングを用いて、純粋なデータ並列化で効率的な学習を実現しています。
- スケーリング法則によって導き出された最適な設定の一つとして、100,000イテレーション、期待バッチサイズ517,989、ノイズ乗数0.6143481といったハイパーパラメータが採用されています。
VaultGemmaの成果とプライバシー保証
新しいスケーリング法則と高度な訓練アルゴリズムを用いて構築されたVaultGemmaは、差分プライバシーを完全に適用して事前訓練されたモデルとしては、これまでに最大となる10億パラメータのオープンモデルです。
- スケーリング法則の正確性
- VaultGemmaの最終的な訓練損失は、DPスケーリング法則の予測値に驚くほど近く、その研究の妥当性が検証されました。これは、今後のプライベートモデル開発において信頼性の高いロードマップを提供するものです。
- 性能比較
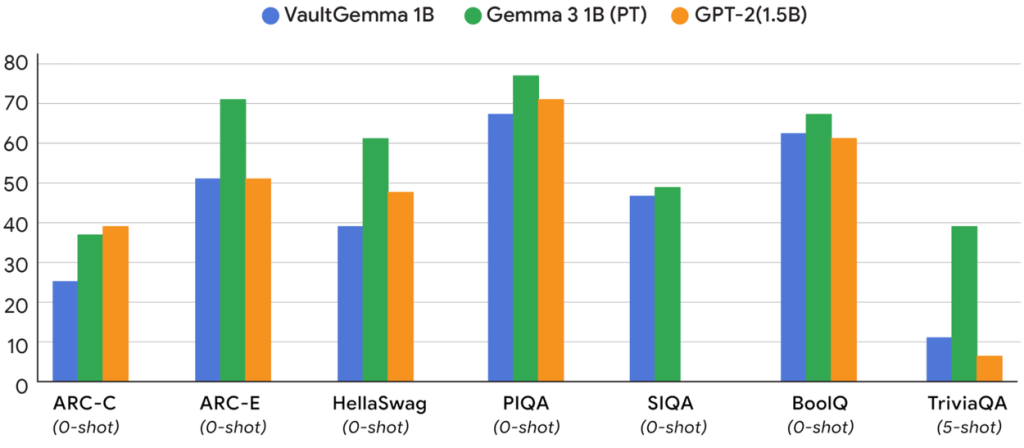
- VaultGemmaは、非プライベート版のGemma 2 1Bモデルや、約5年前のGPT-2 1.5Bモデルといった標準的な学術ベンチマーク(HellaSwag, BoolQ, PIQA, SocialIQA, TriviaQA, ARC-C, ARC-E)で性能が評価されました。
- その結果、現在のDP学習手法で訓練されたモデルは、約5年前の非プライベートモデルと同等のユーティリティを提供できることが示されました。これは、プライバシー保護に要する現在のリソース投資を定量化し、DPモデルと非DPモデルとの性能差を体系的に縮めるための重要な道筋を示しています。
| Benchmark | n-shot | VaultGemma 1B PT |
|---|---|---|
| HellaSwag | 10-shot | 39.09 |
| BoolQ | 0-shot | 62.04 |
| PIQA | 0-shot | 68.00 |
| SocialIQA | 0-shot | 46.16 |
| TriviaQA | 5-shot | 11.24 |
| ARC-c | 25-shot | 26.45 |
| ARC-e | 0-shot | 51.78 |
- 厳密なプライバシー保証
- VaultGemmaは、厳密な数学的および経験的なプライバシー保護を提供します。
- 具体的には、 ( (\epsilon \leq 2.0, \delta \leq 1.1e-10) ) のシーケンスレベルDP保証で訓練されました。ここでいう「シーケンス」とは、異種データソースから抽出された1024個の連続したトークンの塊を指します。
- このシーケンスレベルDP保証が実用上意味するのは、もし潜在的にプライベートな事実や推論に関する情報が単一のシーケンス内に存在する場合、VaultGemmaはその事実を「知らない」のと同じ状態になる、ということです。つまり、どのようなクエリに対しても、そのシーケンスで訓練されなかったモデルの結果と統計的に類似した応答を生成します。
- ただし、もし多くの訓練シーケンスに特定の事実に関する情報が含まれている場合、VaultGemmaはその情報を提供できる可能性がある点には注意が必要です。また、データとユーザーの間に明確なマッピングがある状況では、シーケンスレベルDPよりもユーザーレベルDP(個人ユーザー全体からの情報を保護する)の方が適切な選択となる場合もあります。
- 記憶(Memorization)の検証
- シーケンスレベルDPは、最終モデルに対する個々の訓練シーケンスの影響を論理的に制限します。研究チームは、訓練ドキュメントの50トークンのプレフィックス(冒頭部分)をモデルに与え、対応する50トークンのサフィックス(続き)を生成するかどうかを検証する実験を行いました。
- その結果、VaultGemma 1Bは、訓練データの検出可能な記憶を一切示しませんでした。これは、DP学習の有効性を明確に示しています。
まとめ
差分プライバシーのための新しい堅牢なスケーリング法則を開発し適用することで、Googleはこれまでで最大のオープンなDP学習言語モデルVaultGemmaを開発しました。
DP学習モデルと非DP学習モデルの間には依然としてユーティリティギャップが存在しますが、GoogleはこのギャップがDP学習のためのメカニズム設計に関するさらなる研究によって体系的に縮められると考えています。








