
はじめに
Google DeepMindが発表した「EmbeddingGemma」は、デバイス上で直接動作するAIアプリケーションの可能性を広げる新しい埋め込みモデルです。
本稿では、Google Developers Blogの「Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings」という記事をもとに、EmbeddingGemmaの技術的な特徴やその重要性、そして具体的な活用方法について解説していきます。
参考記事
- タイトル: Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings
- 発行元: Google Developers Blog
- 発行日: 2025年9月4日
- URL: https://developers.googleblog.com/ja/embeddinggemma-mobile-first-embedding-model/
GoogleColab(弊社作成)
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- EmbeddingGemmaは、スマートフォンなどのデバイス上で動作させること(オンデバイスAI)を主眼に設計された、軽量なオープンソースのテキスト埋め込みモデルである。
- 3億800万パラメータというコンパクトなサイズでありながら、同規模のモデルの中でクラス最高の性能を達成している。
- インターネット接続なしで動作するため、プライバシーを保護しながら、RAG(検索拡張生成)やセマンティック検索(意味に基づいた検索)といった高度な機能を実現できる。
- 量子化技術により200MB未満のRAMで動作し、出力する埋め込みの次元数も柔軟に変更可能なため、リソースが限られた環境に最適である。
- EdgeTPUでは15ミリ秒未満の超高速推論を実現し、リアルタイムな応答が可能。
- Gemma 3nとの連携により、完全なオフラインRAGパイプラインを構築できる。
- 多くの主要なAI開発ツールと既に統合されており、開発者が容易に導入し、活用を始められる環境が整っている。
詳細解説
そもそも「テキスト埋め込み(Embedding)」とは?
EmbeddingGemmaを理解する上で、まず「テキスト埋め込み」という技術について知る必要があります。これは、私たちが日常的に使う言葉(単語、文、文書全体)を、コンピュータが計算できる数値のリスト(ベクトル)に変換する技術です。この変換の優れた点は、言葉の「意味」をベクトル空間上の位置関係として表現できることです。例えば、「王様」と「女王様」という単語は、ベクトル空間上で非常に近い位置に配置されます。この技術により、コンピュータは単なる文字列としてではなく、言葉の意味の類似性に基づいて情報を処理できるようになります。
EmbeddingGemmaの主な特徴
EmbeddingGemmaは、このテキスト埋め込みを、特にデバイス上で効率的に行うために開発されました。その主な特徴を掘り下げていきましょう。
1. クラス最高の性能とコンパクトなサイズ
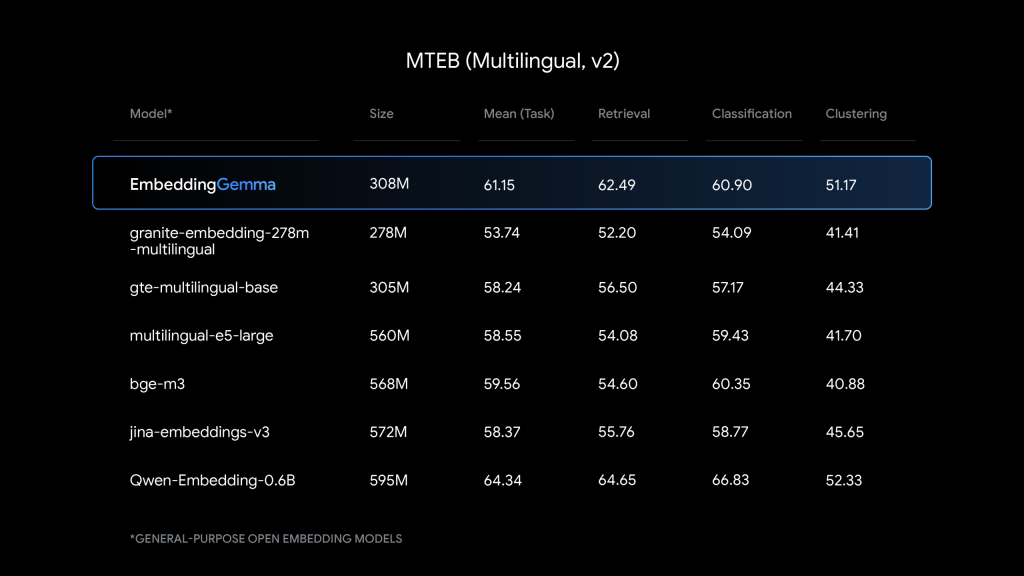
EmbeddingGemmaは、わずか3億800万パラメータという軽量な設計です。このパラメータは、約1億のモデルパラメータと約2億の埋め込みパラメータで構成されており、効率的な設計となっています。しかし、その性能は非常に高く、テキスト埋め込みモデルの性能を評価する代表的なベンチマークであるMTEB (Massive Text Embedding Benchmark)において、5億パラメータ以下の多言語モデルの中で最高ランクを獲得しています。これは、2倍近いサイズのモデルに匹敵する性能であり、効率の良さを示しています。
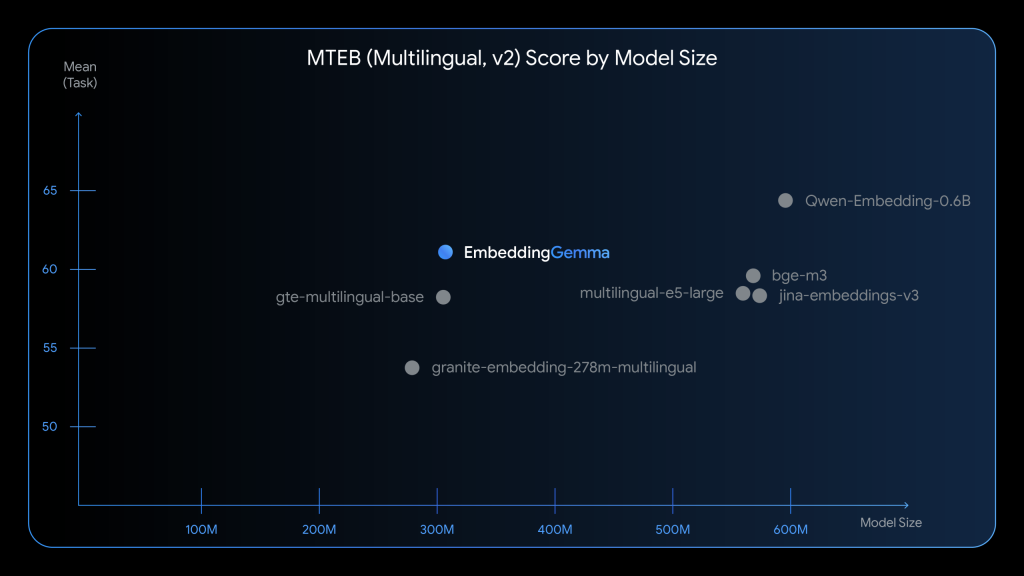
さらに、EmbeddingGemmaは100以上の言語での学習が行われており、日本語を含む多言語での高品質な埋め込み生成が可能です。検索、分類、クラスタリングといった幅広いタスクにおいて、同規模の人気モデルを上回る性能を発揮します。
2. オンデバイスとオフラインでの動作
このモデルの最大の利点の一つは、インターネット接続を必要としないことです。すべての処理がスマートフォンやPCの内部で完結するため、ユーザーの個人的なメールや文書などのデータを外部サーバーに送信する必要がありません。これにより、プライバシーが高度に保護されるだけでなく、通信環境が不安定な場所でも安定してAI機能を利用できます。
具体的な活用例として、以下のような機能を実現できます:
- 個人ファイルの横断検索: 文書、テキスト、メール、通知など、異なる形式のデータを同時に検索
- オフライン対応チャットボット: Gemma 3nと連携したRAGベースの業界特化型ボット
- モバイルエージェント: ユーザークエリを適切な機能呼び出しに分類
3. RAG(検索拡張生成)の実現
近年、ChatGPTのような大規模言語モデル(LLM)の回答精度を向上させる技術としてRAG(検索拡張生成)が注目されています。これは、LLMが回答を生成する際に、外部の最新情報や専門的な文書データベースをリアルタイムで参照する仕組みです。
RAGの「検索」ステップでは、ユーザーの質問と関連性の高い文書をデータベースから見つけ出す必要があり、ここでテキスト埋め込みが重要な役割を果たします。EmbeddingGemmaは、この検索ステップをデバイス上で高速かつ高精度に実行できるため、オフライン環境でも動作する高機能なチャットボットなどを開発できます。
特に注目すべきは、Gemma 3nとの連携です。EmbeddingGemmaとGemma 3nは同じトークナイザー(文章を単語に分割する仕組み)を使用するため、RAGアプリケーションでのメモリ使用量を削減できます。これにより、モバイル端末での完全なRAGパイプラインが現実的になります。
4. 柔軟性と効率性を高める技術
EmbeddingGemmaは、リソースが限られたデバイスでも最大限の性能を発揮できるよう、いくつかの先進的な技術を採用しています。
- Matryoshka Representation Learning (MRL):
この技術は、モデルが生成する埋め込みベクトルを、用途に応じて柔軟にサイズ変更できるようにするものです。最大の768次元のベクトルで最高の品質を得ることも、速度やメモリを優先して128次元、256次元、512次元のような小さなサイズに切り詰めて使うことも可能です。これはまるで、マトリョーシカ人形のように、大きなベクトルの中に小さなベクトルが入れ子構造で含まれているイメージです。 - 量子化対応トレーニング (QAT):
モデルの計算精度への影響を最小限に抑えながら、使用するメモリ量を大幅に削減する技術です。これにより、EmbeddingGemmaは200MB未満のRAMという非常に少ないメモリで動作します。 - 高速推論:
EdgeTPUでは、256入力トークンに対して15ミリ秒未満という超高速な推論時間を実現しています。これにより、リアルタイムでの応答が可能になり、ユーザーにとって流れるような自然なインタラクションを提供できます。 - 2Kトークンコンテキスト:
2,000トークンのコンテキストウィンドウにより、長めの文書や複雑な質問にも対応できます。
5. 用途に応じたモデル選択
Googleは、用途に応じて最適なモデルを選択できるよう、以下の指針を提供しています:
- オンデバイス・オフライン用途: EmbeddingGemmaが最適(プライバシー、速度、効率性を重視)
- 大規模サーバーサイドアプリケーション: Gemini APIのGemini Embedding model(最高品質・最大性能を重視)
豊富なツール統合とファインチューニング
EmbeddingGemmaは、開発者が使い慣れたツールとの統合を重視して設計されています。対応ツールには以下が含まれます:
- ライブラリ・フレームワーク: sentence-transformers、transformers.js、llama.cpp、MLX、LiteRT、LangChain、LlamaIndex
- プラットフォーム・サービス: Ollama、LMStudio、Weaviate、Cloudflare
- クラウドサービス: Hugging Face、Kaggle、Vertex AI
また、特定のドメインやタスク、特定言語への最適化が必要な場合は、ファインチューニングも可能です。Googleは、ファインチューニングを始めるためのクイックスタートノートブックも提供しており、独自のデータセットを使ってモデルをカスタマイズできます。
インタラクティブデモ
EmbeddingGemmaの実際の動作を体験できるインタラクティブデモも用意されています。このデモは、テキスト埋め込みを3次元空間で視覚化し、完全にブラウザ上で動作します(Transformers.jsを使用)。これにより、埋め込み技術がどのように言葉の意味を数値空間で表現するかを直感的に理解できます。
〇デモサイト:https://huggingface.co/spaces/webml-community/semantic-galaxy
EmbeddingGemma導入ガイド
〇GoogleColab(弊社作成):JOBIRUN_EmbeddingGemma.ipynb
※以下と同じ内容を記載したものとなります。
事前準備
1. Hugging Face アカウントの設定
EmbeddingGemmaを使用するには、まずHugging Faceでライセンスの承認が必要です。
- Hugging Faceにログイン
- EmbeddingGemmaモデルページで「Acknowledge license」を選択
- Hugging Face Access Tokenを生成
2. 必要なライブラリのインストール
# 基本ライブラリのインストール
pip install -U sentence-transformers git+https://github.com/huggingface/transformers@v4.56.0-Embedding-Gemma-preview
# 追加で必要になる可能性があるライブラリ
pip install torch numpy datasets huggingface_hub基本的な使用方法
1. モデルのロードと初期設定
import torch
from sentence_transformers import SentenceTransformer
from huggingface_hub import login
import numpy as np
# Hugging Face Hubにログイン
login() # トークンの入力が求められます
# デバイスの設定(GPU使用可能な場合はGPUを使用)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用デバイス: {device}")
# EmbeddingGemmaモデルのロード
# 300Mパラメータ版を使用(軽量版)
model_id = "google/embeddinggemma-300M"
model = SentenceTransformer(model_id).to(device=device)
# モデル情報の表示
print(f"モデルデバイス: {model.device}")
print(f"総パラメータ数: {sum([p.numel() for _, p in model.named_parameters()]):,}")2. 基本的なテキスト埋め込み生成
# 埋め込みに変換したい文章のリスト
sentences = [
"こんにちは、今日は良い天気ですね。",
"最新のAI技術について調べています。",
"猫は可愛い動物です。",
"A cute animal is a cat.",
"人工知能の研究が進んでいます。",
"機械学習の勉強をしています。",
"今日は雨が降っています。"
]
# タスク指定(推奨):STS(Semantic Textual Similarity)を使用
task_name = "STS"
# 文章を埋め込みベクトルに変換
embeddings = model.encode(sentences, prompt=task_name)
print(f"埋め込みの形状: {embeddings.shape}")
print(f"ベクトル次元数: {embeddings.shape[1]}")
# 各文章の埋め込み結果を表示
for i, (sentence, embedding) in enumerate(zip(sentences, embeddings)):
print(f"\n文章 {i+1}: {sentence}")
print(f"埋め込み (最初の5次元): {embedding[:5]}")
print(f"ベクトルの大きさ: {np.linalg.norm(embedding):.4f}")3. 類似度計算と実用例
def cosine_similarity(v1, v2):
"""コサイン類似度を計算する関数"""
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
def find_most_similar(query_embedding, document_embeddings, documents, top_k=3):
"""最も類似した文書を見つける関数"""
similarities = []
for doc_embedding in document_embeddings:
similarity = cosine_similarity(query_embedding, doc_embedding)
similarities.append(similarity)
# 類似度でソート
sorted_indices = np.argsort(similarities)[::-1]
results = []
for i in range(min(top_k, len(documents))):
idx = sorted_indices[i]
results.append({
'document': documents[idx],
'similarity': similarities[idx],
'index': idx
})
return results
# 類似度計算の例
print("\n=== 類似度計算の例 ===")
# 日本語と英語の類似文の比較
japanese_cat = embeddings[2] # "猫は可愛い動物です。"
english_cat = embeddings[3] # "A cute animal is a cat."
similarity_cat = cosine_similarity(japanese_cat, english_cat)
print(f"日英の猫に関する文章の類似度: {similarity_cat:.4f}")
# AIに関する文章の比較
ai_research = embeddings[1] # "最新のAI技術について調べています。"
ai_learning = embeddings[4] # "人工知能の研究が進んでいます。"
similarity_ai = cosine_similarity(ai_research, ai_learning)
print(f"AI関連文章の類似度: {similarity_ai:.4f}")
# 機械学習の文章との比較
ml_study = embeddings[5] # "機械学習の勉強をしています。"
similarity_ai_ml = cosine_similarity(ai_research, ml_study)
print(f"AI技術と機械学習の類似度: {similarity_ai_ml:.4f}")4. セマンティック検索の実装
def semantic_search(query, documents, model, task_name="STS", top_k=5):
"""セマンティック検索を実行する関数"""
# クエリと文書の埋め込みを生成
query_embedding = model.encode([query], prompt=task_name)[0]
doc_embeddings = model.encode(documents, prompt=task_name)
# 類似度計算
similarities = []
for doc_embedding in doc_embeddings:
similarity = cosine_similarity(query_embedding, doc_embedding)
similarities.append(similarity)
# 結果をソート
results = [(documents[i], similarities[i]) for i in range(len(documents))]
results.sort(key=lambda x: x[1], reverse=True)
return results[:top_k]
# セマンティック検索の例
knowledge_base = [
"NISAアカウントの開設方法について説明します。",
"普通預金口座の開設手続きをご案内します。",
"住宅ローンの申し込みガイドをご確認ください。",
"投資信託の管理手数料についてお知らせします。",
"医療保険の補償内容をご説明します。",
"生命保険の解約方針についてご案内します。",
"税制優遇投資制度の利用方法を解説します。",
"早期返済時の手数料について説明します。"
]
query = "税制優遇の投資を始めたいのですが、何をすればよいですか?"
print(f"\n=== セマンティック検索の例 ===")
print(f"クエリ: {query}")
print("\n検索結果:")
results = semantic_search(query, knowledge_base, model)
for i, (doc, score) in enumerate(results, 1):
print(f"{i}. {doc} (類似度: {score:.4f})")5. Matryoshka Representation Learning (MRL) の活用
# MRLを使った異なる次元での埋め込み比較
def compare_embeddings_dimensions(sentences, model, dimensions=[128, 256, 512, 768]):
"""異なる次元での埋め込みの比較"""
task_name = "STS"
print("=== MRL次元比較 ===")
for dim in dimensions:
# 注意: 実際のMRL実装では、モデルの設定で出力次元を指定します
# ここでは概念的な説明として、フル埋め込みから切り取ります
embeddings = model.encode(sentences, prompt=task_name)
truncated_embeddings = embeddings[:, :dim]
print(f"\n次元数: {dim}")
print(f"埋め込みサイズ: {truncated_embeddings.shape}")
# 同じ文章間の類似度を計算(品質の指標として)
if len(sentences) >= 2:
sim = cosine_similarity(truncated_embeddings[0], truncated_embeddings[1])
print(f"最初の2文の類似度: {sim:.4f}")
# MRL比較の実行
test_sentences = [
"機械学習について学んでいます。",
"人工知能の研究をしています。"
]
compare_embeddings_dimensions(test_sentences, model)6. バッチ処理と効率的な処理
def batch_encode_with_progress(texts, model, batch_size=32, task_name="STS"):
"""大量のテキストを効率的にバッチ処理する関数"""
embeddings = []
print(f"総テキスト数: {len(texts)}")
print(f"バッチサイズ: {batch_size}")
for i in range(0, len(texts), batch_size):
batch = texts[i:i+batch_size]
batch_embeddings = model.encode(batch, prompt=task_name)
embeddings.extend(batch_embeddings)
print(f"処理済み: {min(i+batch_size, len(texts))}/{len(texts)}")
return np.array(embeddings)
# 大量テキストの処理例
large_text_list = [
f"これはテスト文書 {i} です。内容は様々な分野に関するものです。"
for i in range(100)
]
# print("\n=== バッチ処理の例 ===")
# large_embeddings = batch_encode_with_progress(large_text_list, model, batch_size=16)7. 利用可能なタスクとプロンプト
# EmbeddingGemmaで利用可能なタスク一覧
available_tasks = {
"STS": "文の類似度計算(Semantic Textual Similarity)",
"CLASSIFICATION": "テキスト分類",
"CLUSTERING": "テキストクラスタリング",
"RETRIEVAL_QUERY": "検索クエリ(検索用)",
"RETRIEVAL_DOCUMENT": "検索文書(インデックス用)"
}
print("=== 利用可能なタスク ===")
for task, description in available_tasks.items():
print(f"{task}: {description}")
# 異なるタスクでの埋め込み生成例
def compare_task_embeddings(text, model):
"""異なるタスクでの埋め込みを比較"""
print(f"\nテキスト: {text}")
for task in ["STS", "CLASSIFICATION", "CLUSTERING"]:
try:
embedding = model.encode([text], prompt=task)[0]
print(f"{task}: 次元数 {len(embedding)}, ノルム {np.linalg.norm(embedding):.4f}")
except Exception as e:
print(f"{task}: エラー - {e}")
# タスク比較の実行
compare_task_embeddings("機械学習は人工知能の重要な分野です。", model)8. モデル情報と設定確認
# モデルの詳細情報を表示
def show_model_info(model):
"""モデルの詳細情報を表示する関数"""
print("=== モデル詳細情報 ===")
print(f"モデル: {model}")
print(f"デバイス: {model.device}")
# トークナイザー情報
if hasattr(model, 'tokenizer'):
print(f"最大シーケンス長: {model.max_seq_length}")
print(f"トークナイザー: {type(model.tokenizer).__name__}")
# 利用可能なプロンプト
if hasattr(model, 'prompts'):
print(f"利用可能なプロンプト: {list(model.prompts.keys())}")
# パラメータ数の詳細
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"総パラメータ数: {total_params:,}")
print(f"学習可能パラメータ数: {trainable_params:,}")
# モデル情報の表示
show_model_info(model)実用的なアプリケーション例
文書検索システム
class DocumentSearchSystem:
"""EmbeddingGemmaを使用した文書検索システム"""
def __init__(self, model):
self.model = model
self.documents = []
self.embeddings = None
def add_documents(self, documents):
"""文書を追加してインデックスを構築"""
self.documents.extend(documents)
new_embeddings = self.model.encode(documents, prompt="RETRIEVAL_DOCUMENT")
if self.embeddings is None:
self.embeddings = new_embeddings
else:
self.embeddings = np.vstack([self.embeddings, new_embeddings])
def search(self, query, top_k=5):
"""クエリに対して検索を実行"""
query_embedding = self.model.encode([query], prompt="RETRIEVAL_QUERY")[0]
similarities = []
for doc_embedding in self.embeddings:
similarity = cosine_similarity(query_embedding, doc_embedding)
similarities.append(similarity)
# 上位結果を取得
top_indices = np.argsort(similarities)[::-1][:top_k]
results = []
for idx in top_indices:
results.append({
'document': self.documents[idx],
'similarity': similarities[idx],
'index': idx
})
return results
# 使用例
search_system = DocumentSearchSystem(model)
# サンプル文書の追加
documents = [
"EmbeddingGemmaは軽量で高性能なテキスト埋め込みモデルです。",
"オンデバイスAIにより、プライバシーを保護しながら高度な検索が可能です。",
"RAG(検索拡張生成)システムを構築できます。",
"Matryoshka Representation Learningにより柔軟な次元調整が可能です。",
"EdgeTPUで15ミリ秒未満の高速推論を実現します。"
]
search_system.add_documents(documents)
# 検索実行
query = "高速な推論について教えて"
results = search_system.search(query, top_k=3)
print(f"\nクエリ: {query}")
print("検索結果:")
for i, result in enumerate(results, 1):
print(f"{i}. {result['document']} (類似度: {result['similarity']:.4f})")まとめ
EmbeddingGemmaは、単なる新しいモデルではなく、AI技術をより身近で、プライベートで、そしてアクセスしやすいものにするための重要な一歩です。これまで大規模なサーバーでしか実現できなかった高度な意味検索やRAGといった機能を、手元のデバイスで実現可能にします。
3億800万パラメータという効率的な設計、EdgeTPUでの15ミリ秒未満という超高速推論、200MB未満という省メモリ動作、そしてMatryoshka Representation Learningによる柔軟な次元調整など、オンデバイスAIに必要な要素を盛り込んでいます。EmbeddingGemmaを使うことで、開発者はユーザーのプライバシーを尊重しながら、よりパーソナライズされた便利なアプリケーションを創ることができるようになります。Hugging FaceやKaggle、Vertex AIから利用することが出来、豊富なツール統合とファインチューニング機能により、今後のオンデバイスAI開発の標準的なツールの一つとなっていくことでしょう。








